
Matthew Carroll
on June 2, 2025
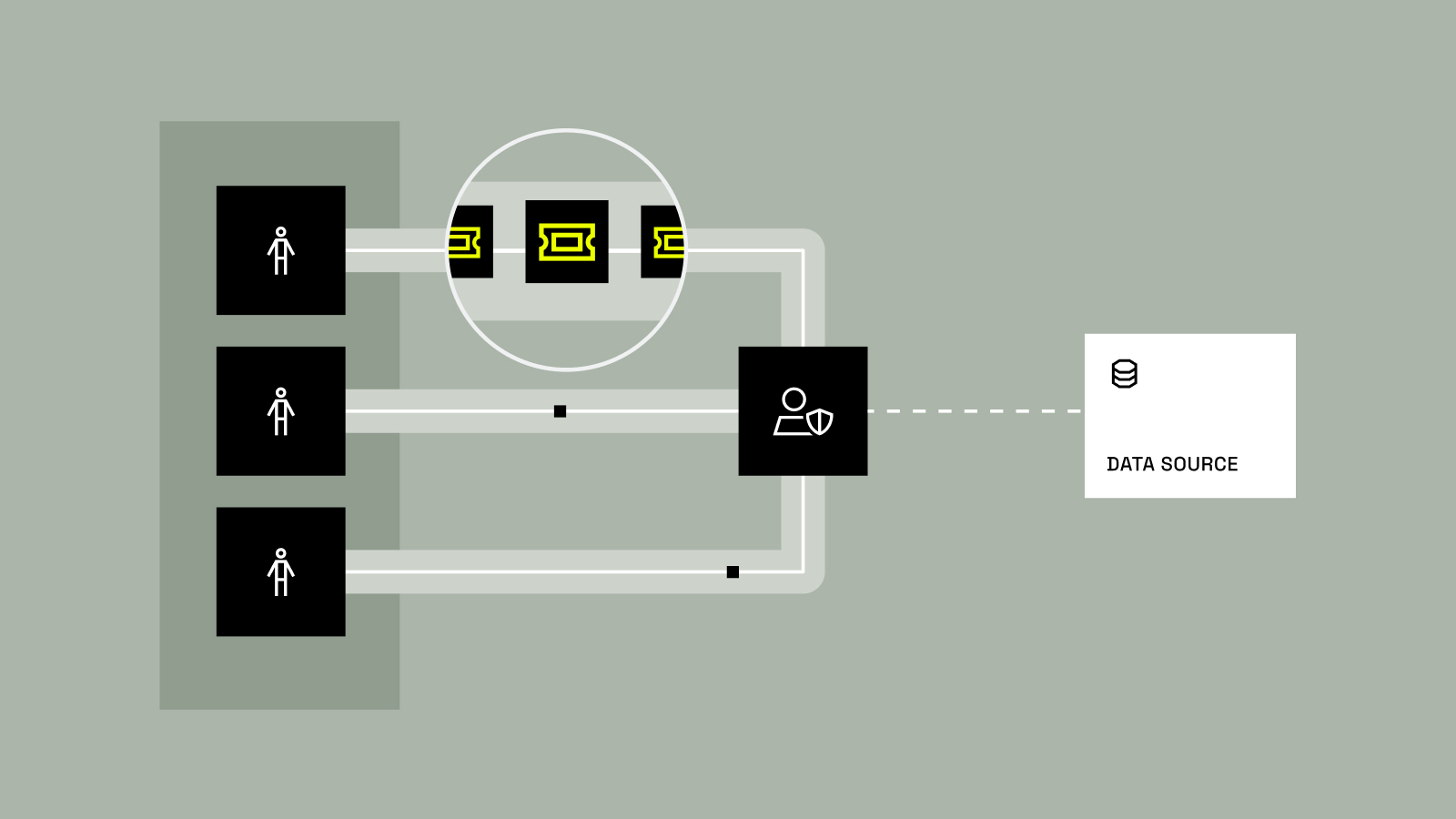



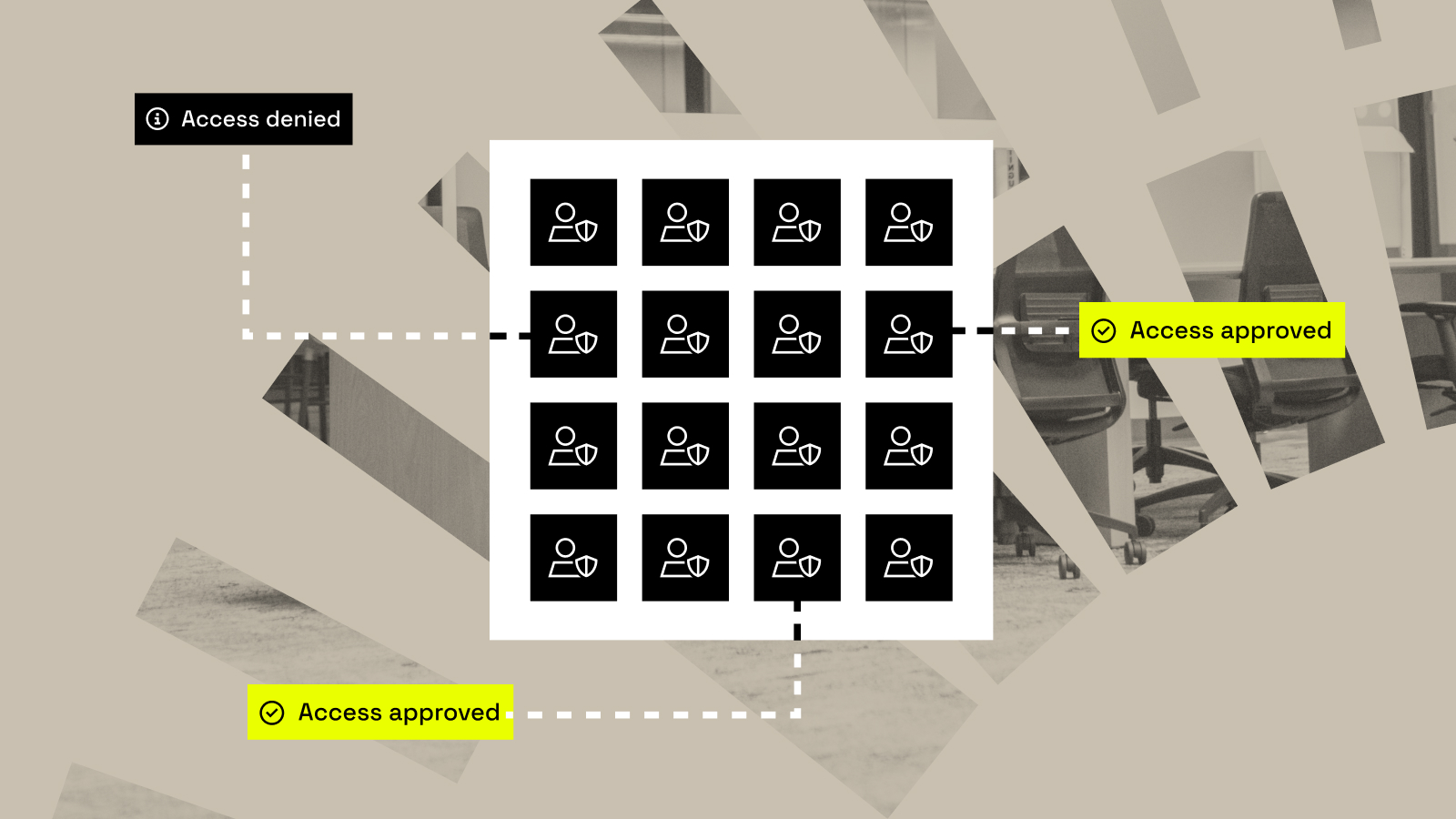

Key Takeaways Immuta’s identifiers in domains feature is now generally available to all global customers. It addresses a critical gap in traditional metadata catalogs by making sensitive data discoverable and governable within domain boundaries, which adds critical context to policy enforcement. This capability empowers domain governors to classify and control...

Data product owners are under constant pressure to publish and manage data products that fuel growth, innovation, and collaboration – at scale and speed. But they’re often at odds with data governors, who have the daunting task of classifying the sensitive information within those data products, enforcing the appropriate policies...

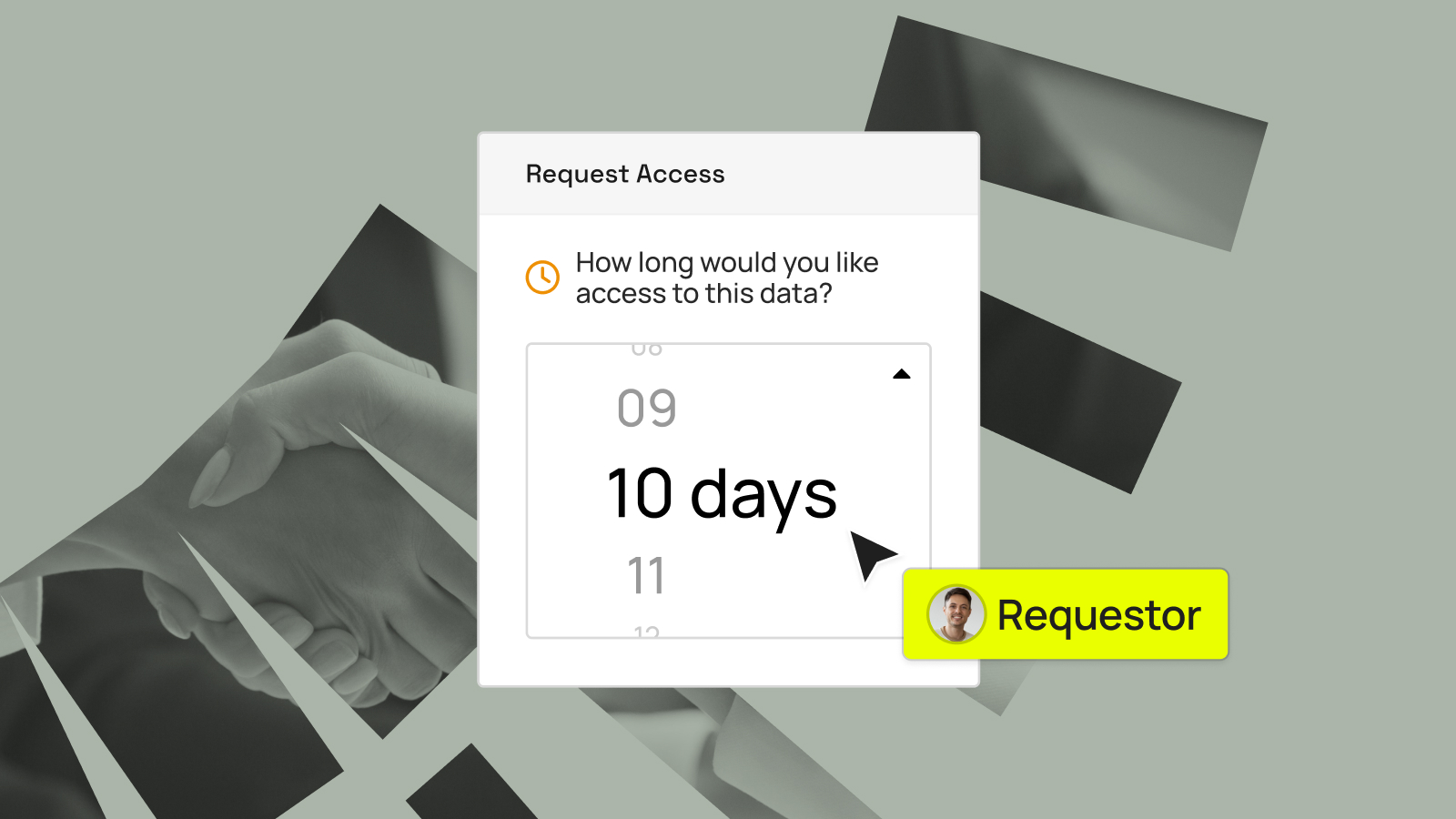
Have you ever felt the frustration of waiting for data access? The demand for data insights is skyrocketing – but often, so is the time it takes to access data. If you’re like more than a third of data professionals, you’re waiting a week or more to gain access after...

Despite advances in cloud technology, 64% of data leaders report facing significant challenges provisioning timely and secure data access. Data governors and stewards are caught in the middle of this dilemma, tasked with ensuring that data products are readily accessible and valuable, while also being secure and compliant. Traditional methods...

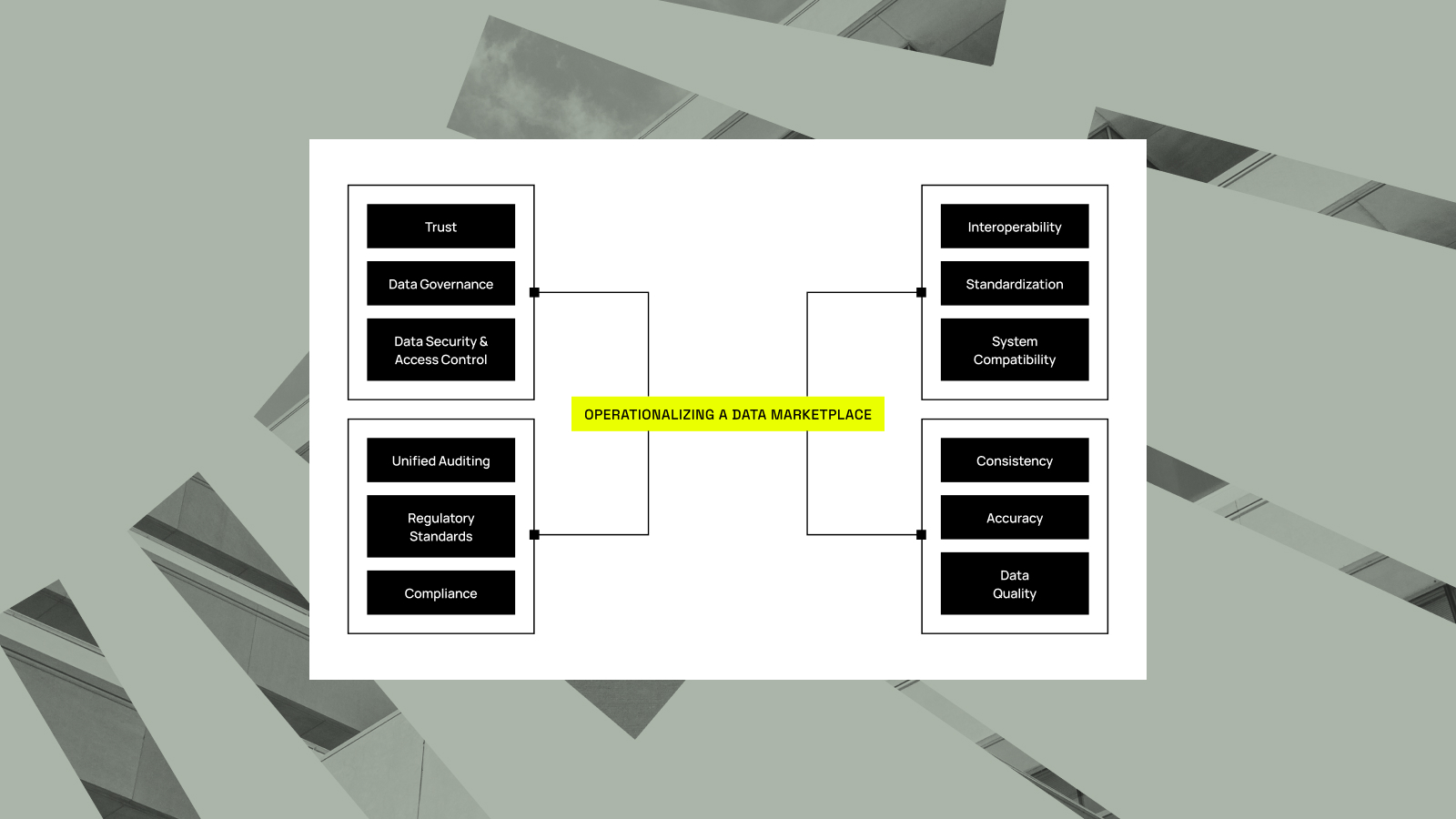
Companies today are only as successful as their ability to put data to work. They invest heavily in pipelines and workflows to create valuable data products for analytics and AI. Yet, data product owners and data governors often realize something crucial is missing: a simple, secure way to find and...
The Immuta Data Marketplace solution marks a shift in how data is accessed and utilized internally: Moving away from exposing raw tables and schemas, and toward delivering polished data products. Why does this transition matter? Raw data alone doesn’t guarantee value – and raw data alone doesn’t equal success. Data...

Identity governance and administration (IGA) solutions aim to manage access request processing and workflow orchestration, as well as identity access certification. Said more plainly: IGA holds the logic that is the glue between your users and their access to your business resources. IGA solutions have existed for quite some time....

As enterprises embrace the transformative power of artificial intelligence (AI) and machine learning (ML), they face the challenge of ensuring sensitive data and insights remain secure. Organizations need a streamlined way to control access to resources that power important AI and ML workflows, but often struggle to do so as...

With nearly half of data teams focusing on creating, publishing, and sharing data products in the next year, and 68% planning to implement a data marketplace, there’s no question that the shift toward leveraging internal marketplaces to maximize the value of data products is well underway. As with any data...

In today’s globalized business landscape, data is a critical asset. However, they must still contend with the friction between provisioning data in real-time, and maintaining security and compliance. For companies dealing with sensitive defense-related information, the stakes are particularly high due to the non-negotiable need to ensure compliance with regulations...
Data powers everything in today’s market, from insights and innovations, to competitive advantages. Without it, organizations struggle to grow, compete, and function efficiently. Yet, for many teams, accessing, managing, and leveraging data effectively remains a significant challenge. Whether you’re a data consumer seeking streamlined access to insights or a data...

Artificial intelligence is more than just a buzzword; it’s a force that’s changing the way we work, learn, and live. In every industry — from healthcare to entertainment — AI is sparking new conversations, debates, and initiatives as organizations race to harness its potential. Case in point: A survey of...

Technologies like retrieval-augmented generation (RAG) are transforming how organizations apply AI to tackle real-world challenges. By merging generative AI with curated, real-time data retrieval, RAG systems provide accurate, relevant, and actionable results, without the resources needed to build a custom LLM from scratch. However, the data powering these systems is...

Organizations increasingly rely on data lakes to store, manage, and analyze vast amounts of information from various data sources. But building a data lake specifically on AWS allows you to leverage a comprehensive cloud ecosystem with a wide array of services. In this blog, we’ll dive deeper into how to...

No one in today’s market can or would deny that data is critical to driving business and innovation. But data alone isn’t enough. To truly unlock its potential, organizations need to effectively share and govern their data assets. “Clearly, data sharing is fundamental to business as we know it,” says...

The rise of the internal data marketplace When Clive Humby described data as “the new oil” back in 2006, he was mainly talking about the huge strategic value that it can deliver. Two decades on, and his assertion holds true. In that time, though, it’s also become clear there’s a...

Autonomous vehicles From “basic” features like lane assist and self-parking, through to advanced capabilities like sensor fusion and pattern recognition, data is — quite literally — the driving force behind autonomous vehicles. Self-driving cars also generate a great deal of sensitive information, such as location data and driving habits. Ensure...

Organizations are constantly finding new ways to make their growing datasets work harder for them. Amazon Redshift Spectrum offers a flexible solution, bridging the gap between data lakes and warehouses to eliminate unnecessary complexity. By pairing it with Immuta’s robust data governance capabilities, they can move even faster – securely...

Data has become the cornerstone of modern business success, driving everything from customer personalization to inventory management. But more data means more complexity – and organizations need a way to efficiently control access while maintaining compliance, particularly as operations scale. Amazon EMR with Apache Spark gives businesses the tools to...

As AI and other technologies accelerate demand for data and consequently, more users require access to this data to leverage its potential and drive innovation. Leading organizations leverage platforms like Amazon Athena in order to make that data available for analysis. But often, they must navigate the complexity of governing...

As topics go, they don’t come much hotter than artificial intelligence (AI). AI isn’t just another buzzword or passing trend. It’s a technology that promises to have a genuinely transformative impact on the automotive industry. From the supply chain to the powertrain, AI promises to revolutionize everything from design and...

The car isn’t just a car anymore. It’s the center of a dynamic — and ever-expanding — data ecosystem. From design and development through to services and subscriptions, data has become the driving force in automotive today. For manufacturers, that creates challenge and opportunity in equal measure. Extracting the right...

Before 1992, if you wanted to buy a stock, you’d call your stockbroker to place, buy, or sell orders. The stockbroker would then communicate the order to the trading floor or exchange desk. The process created a barrier of entry for average consumers, and the banks involved leveraged manual, people-driven...
At Immuta, we work with the world’s most complex and secure organizations, and almost all have one thing in common: a desire to enable data and analytics through an internal data marketplace. This is quite different from the data space a mere two years ago, which gravitated toward centralized operations....

Standing up a data governance framework is a critical step for any organization. According to reporting from Gartner and Immuta, it topped the list of leaders’ priorities – beating out initiatives related to AI and analytics. But as technology evolves, so does the process of implementing an effective, future-proof data...

Like most data initiatives, data marketplaces are meant to deliver value. But unlike those other initiatives, data marketplaces have an edge – they increase the potential of the entire business by clearly defining the roles, rules, and capabilities that lead to success. To truly maximize the value that data marketplaces...

One of the most consistent challenges that we have seen when working with large global enterprises is a tendency to treat data catalogs and data marketplaces as the same objective, rather than separate ones. Conflating the two may also explain why data and analytical engineering teams, along with business users,...

With 120 zettabytes of new data generated every day, it’s safe to assume that systems and processes that worked even five years ago are struggling to keep up with the demand for data. But keeping up with new and evolving technologies can be a full-time job. And, it’s clear from...

In the world of data management, not all sensitive data fits neatly into predefined categories. Many organizations deal with unique data types and formats that standard data discovery frameworks fail to recognize. As data protection regulations become more stringent, the ability to identify and manage sensitive data accurately is crucial. However, the...

The adage that “we are a software company” is quickly becoming “we are a data company.” In today’s world, software is only as good as the data within it – and the ability to deploy it. As the wave of organizations leveraging cloud data platforms like Snowflake and Databricks continues to build, enterprises must...
One of the challenges that many SaaS products face as they mature and move into enterprise markets is a growing demand for private networking. This is because companies may be wary of allowing access to potentially sensitive internal services over the internet – and in our experience with Immuta as...

We are thrilled to announce that Immuta has achieved the prestigious AWS Data and Analytics Competency status. This recognition from Amazon Web Services (AWS) highlights our dedication to delivering top-tier data security and analytics solutions for joint customers, and is an exciting next step in our long-standing partnership with AWS. Earning AWS Data and...
We’re all witness to the buzz around Generative AI (GenAI). These offerings, which convert user prompts into model-generated text, images, and videos, have permeated our professional and personal lives as they become increasingly accessible. One incredibly prevalent type of GenAI is the Large Language Model (LLM), which includes the likes...

In our super-connected world, data is everywhere, influencing every choice, interaction, and experience we have each day. Simply having data isn’t a bragging right anymore – it’s table stakes. The real game-changer for a modern company is its knack for turning that raw data into a goldmine of insights. Think...

Maintaining the status quo has never been part of any competitive or innovative business strategy. From startups to large enterprises, data modernization is a priority because of the technological and business benefits it delivers. The modernization process gives teams the opportunity to innovate within their data ecosystem. Whether it be an architectural...

Recent data breaches at Ticketmaster and Santander have underscored the critical vulnerabilities that exist in enterprise data security strategies. These haven’t just interrupted operations – they’ve impacted hundreds of millions of customers, eroding trust in well-known and widely used brands. This is particularly pronounced for Ticketmaster, given the company’s recent headlines. Since before Immuta existed,...
Many data teams – especially at large enterprises – fall victim to a difficult paradox: while they generate vast amounts of data across lines of business, actually accessing and using it is incredibly difficult. Take Merck for example, the world’s third largest pharmaceutical company by revenue. Data flowing in from their R&D,...
Advancements in Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing the way we work with data across sectors. By enabling enhanced decision-making and faster operations, these models present us with unparalleled capabilities – but they are not immune to some very human problems. One of the most critical challenges...

We are thrilled to announce that Immuta has been named Snowflake’s Data Cloud Product Data Security Partner of the Year for the second year in a row. This recognition is deeper than the technical aspects of our product integration – it highlights our shared commitment to de-risking our customers’ data and delivering...
The rapid rise and evolution of GenAI applications is making quotes like this quite common. In fact, a recent survey by Immuta found that 80% of data experts agree that AI is making data security more challenging. Despite this, 88% say their employees are using AI, regardless of whether the company has officially adopted...

Any leading organization will tell you that data isn’t a nice-to-have – it’s table stakes for competing in today’s environment. So, it’s no wonder that many of these companies rely on the Snowflake Data Cloud to power analytics and AI workloads. Since 2018, Immuta has worked product-to-product with Snowflake to develop a...
While they may be different on a conceptual level, data fabric and data mesh aren’t mutually exclusive concepts. Within the right data strategy, the two frameworks can actually work together, with data fabric providing a unified data access layer for a larger data mesh architecture. The choice of whether it makes sense to leverage...

The world of financial services never sleeps — and in this always-on industry, delays, mistakes, or indecision can literally cost millions. But speed can’t come at the expense of compliance, which puts data teams in a unique and complex position. Do you grant access to data at the speed of...

British mathematician Clive Humby is credited with coining the phrase “data is the new oil.” Respectfully, this statement no longer rings true – and data sharing is one of the main reasons why. A lot has changed since 2006, when Humby first made this comparison. To put it into perspective, Twitter launched...

We operate in a world of risks. Whenever we get behind the wheel of a car, flip a light switch in our home, or enjoy an alcoholic beverage, we are accepting an inherent level of risk associated with each activity. But this doesn’t stop us from doing them. Similarly, cloud data...

Vizient is the nation’s largest provider-driven healthcare performance improvement company, serving more than 65% of the nation’s acute-care hospitals. The company provides analytics-enabled solutions to improve care quality, as well as spend management. To ensure efficient control of how data is managed and accessed, while also complying with legal, industry, and...
From artificial intelligence and machine learning advancements, to decentralized cloud storage and analysis, and other novel use cases, we’re seeing data innovations happening before our eyes. At the same time, data breaches and noncompliance penalties are increasingly common and costly, and threats to data will only continue to grow. In...

How much time have you spent sifting through organization-level data trying to find the right data sets for your specific needs? Not to mention that once you find what you’re looking for, you may find yourself waiting for a centralized IT team to approve your access request – which could...

Nearly 700 data leaders share how AI impacts their approach to data security and governance.
Pushes toward self-service data use, advancements in AI, and the demand for real time, granular data insights have led to a surge in unstructured data volumes and usage. Research shows that 90% of new enterprise data is unstructured, and it is growing at three times the rate of structured data. This begs...

Life sciences organizations have traditionally been early adopters of data science and analytics practices, which have revolutionized how they conduct research, develop life-saving therapies, deliver personalized medicine, and optimize their operations. Central to these advances is the ability to share data among healthcare providers, researchers, regulators, and more. Data sharing fosters...

For many, the appeal of a decentralized data architecture relates to its potential for enhanced collaboration. But to achieve this kind of streamlined collaboration, your team must first establish a system of secure, self-service domains. In a previous blog, we explored how to make decentralized data mesh architectures a reality based on phData’s...

Although we are living in an age of unprecedented data generation, none of it matters if we can’t make that data available for analysis in a secure and timely manner. In order for users to analyze and derive insights from data, it must be discoverable and accessible. Streamlining accessibility has...

Genomic data holds significant promise in advancing personalized medicine, streamlining disease treatments, and improving health outcomes. By leveraging individual genetic profiles and biomarkers, genomic data allows researchers to improve treatment accuracy and efficacy. But this promise carries significant privacy risks. The volume and high dimensionality of genetic data introduces a...
One of the most persistent challenges modern data-driven organizations face is the divide between IT teams and business units. With data ownership largely in one camp and data use in the other, this gap hinders effective data collaboration, resulting in disjointed efforts and missed business opportunities. At the heart of...

In 2020, global spending on cloud data services reached $312 billion. In 2022, Gartner estimates that this number will rise to a staggering $482 billion. This immense increase proves that the migration to and adoption of cloud platforms is the bona fide standard for contemporary information services and analysis. With...
The federal government’s Risk Management Framework (RMF) offers agencies guidelines, standards, and processes to help secure information systems. According to senior cybersecurity leaders speaking at the AFCEA TechNet Augusta conference, however, the RMF does not in itself make government networks more secure. The RMF provides agencies with a process to evaluate their...

It’s easy to talk about trends in absolutes. “This new development will affect jobs across every sector,” and “this new platform is going to be everywhere” – these kinds of blanket statements remove nuances that can be incredibly important when discussing trends. Instead, we should focus on questions like “How...

In the 2024 State of Data Security Report, a vast majority (88%) of data professionals reported that employees at their organizations are using artificial intelligence (AI). But, only 50% said that their organization’s data security strategy is keeping up with AI’s rate of evolution. This exemplifies a growing challenge we’re facing with contemporary...

“What data do we have?” Data’s entire life cycle – from collection, to analysis, to insights and business-driving application – begins with this question. Understanding your organization’s data remains critical to effectively using and protecting it, especially as platforms, users, and data sets constantly evolve. But gaining a contextual understanding...

We recently conducted an intriguing webinar exploring the data mesh concept, and how it’s transforming the way enterprises decentralize data to enable cross-functional, self-service products tailored to users’ needs. Though appealing for most organizations, executing a data mesh poses real complexities. At phData, we’ve implemented several successful data mesh platforms for our customers, and...
New Year’s is a time for change, for bettering oneself, for taking that first step towards the future. It’s no different at Immuta – we’ve resolved to make our Data Security Platform even better for our customers. And just like our New Year’s fitness goals start with simple habits, our new and improved...
For organizations like Thomson Reuters, which rely on Snowflake to execute advanced analytics on complex workloads, the Immuta Data Security Platform provides peace of mind through end-to-end data security and access control. Immuta’s native integration with Snowflake delivers automated, scalable data discovery, security, and monitoring, and the seamless user experience and close collaboration earned Immuta the title...

The past few months have been particularly hectic for lawmakers across the European Union (EU). With Ursula von der Leyen’s leadership of the European Commission set to conclude after the 2024 elections, lawmakers have felt the pressure to advance critical files and policies as quickly as possible. Amid this legal...
It goes without saying that employee engagement is a key indicator of organizational performance – Harvard Business Review reports that having happy, engaged employees increases productivity by 13%, not to mention its impact on retention and culture. Yet, studies show that employees are more dissatisfied and apathetic than before the pandemic. While many different...

As more capabilities become automated as part of cloud services, we find that our customers are reluctant to give up control over data security. The complexity of managing policies and granting access involves a degree of hands-on management, and customers want to own that responsibility. In the Gartner report, Predicts 2024: IAM and Data...

If there’s one lesson from the constant advancement of data use and technology, it’s that there’s always room for improvement. Even the most sophisticated data infrastructure can be tuned up with new and improved capabilities that streamline data access and use. This was the case for Booking.com, which recently decided...

Moving from concept to execution can be a complicated process – especially with data mesh architectures. But by understanding and preparing for obstacles, you can make the implementation process as streamlined as possible. In our recent webinar Data Mesh vs. Data Security: Can You Have Both?, Immuta Senior Product Manager Claude...

Compliance regulations in the data security space are constantly changing and evolving, with more new acronyms for regulatory standards being introduced every year. In our global economy, staying compliant with government and industry regulations can be challenging, but with the right strategies, it doesn’t have to be a major burden....
The General Data Protection Regulation (GDPR) is one of the most wide-reaching and stringent data compliance laws and regulations, with penalties for violating its terms reaching 4% of an organization’s prior year worldwide turnover. Although some of its provisions, such as Chapter 5, have fed more debate and litigation than others, it’s...

In his Lord of the Rings series, J.R.R. Tolkien writes of 19 rings of power that give their bearers wealth, dominion, and control. Of these, the most powerful is the “One Ring,” which affords its bearer control over all other rings and, by extension, the entire world. What do rings have to...

Over the past year, we’ve witnessed an unprecedented surge in the development and democratization of AI technologies. Companies are building proprietary models, while the average person – regardless of technical expertise – has tools like ChatGPT at their fingertips. AI is not just changing the way we work, it’s changing the way our...

Generative artificial intelligence (AI) are prediction algorithms that are able to create any type of content, be it text, code, images, audio, or video – think ChatGPT, Bing Chat, Bard, Stable Diffusion, Midjourney, and DALL-E, for example. With the emergence of generative AI-as-a-Service – which has lowered barriers to entry – generative AI is spreading to most...

A modern analytics environment is typically built to reduce time to data, leaving compliance as an afterthought. Yet, without a compliance-by-design approach, the analytics environment is likely to break in weeks because safeguards like purpose-based access control are missing; data minimization and de-identification techniques are inadequate and data access requests...

In today’s digital landscape, safeguarding your data is more important than ever. Whether you’re a data platform owner, a data engineer on a busy team, or just a concerned professional who values an improved data security posture, taking steps to secure your data is crucial. But where do you start?...

Immuta CTO and Co-Founder Steve Touw sat down with Paul Rankin, Head of Data Management Platforms at Roche, and Sanjeev Mohan, Principal at SanjMo, for an in-depth discussion about data mesh architectures. Below is an edited transcript from a portion of their conversation. To listen to the full recording, click here. Steve Touw: This...
Data mesh has become a hot topic as organizations look to foster self-service analytics to make evidence-based decisions. There are plenty of articles discussing data mesh, including Zhamak Dehghani’s original blog post introducing the topic from 2019. To get back to basics, data mesh is a socio-technical approach to creating a decentralized analytical...
The concept of the data mesh architecture is widely recognized and often sought after by data teams across a variety of industries. Given its range of promising benefits – including enhanced data democratization and business-driving data products – this should come as no surprise. But with the technical, structural, and organizational overhauls required to...
With data at the root of business-driving initiatives, the need to maintain data security and compliance is becoming imperative for leaders across industries. Security measures, however, are facing an increasingly daunting landscape of potential threats. According to a new survey by the International Data Corporation (IDC), 54% of European organisations experienced an increase in...
Artificial intelligence (AI) systems have recently gained significantly greater visibility and use by the general public. In the next five years, the AI market is expected to grow by 368%, reaching more than $400 billion by 2027. Numerous industries are exploring new ways to monetize AI in the form of AI-as-a-Service...

Like other modern advancements in data use, the data mesh concept is rooted in a central goal: give more users easier access to business-driving data. But like many data initiatives, implementation can be much more difficult than it seems. A data mesh architecture is an amalgamation of moving parts, decentralizing data away...

You’ve just adopted a data security solution – congratulations! Now what? As with any new piece of technology, it can be tempting to jump in feet first to solve all your problems. After all, the sooner you achieve ROI, the better – right? Not necessarily. Often, we see customers struggle...
While generative artificial intelligence (AI), foundation models, and Large Language Models (LLMs) are often described as the future of AI as we know it, their mass adoption is not necessarily straightforward. The emergence of these types of AI models has sparked concerns recently, leading to a series of open letters, enforcement orders (against...
ChatGPT is one of the fastest-growing artificial intelligence (AI)-powered apps of all time, but it is just the tip of the generative AI iceberg. The pace of AI’s advancements makes it difficult to keep up with the latest terminology, let alone understand how it may impact your day-to-day responsibilities. In...
As organizations continue migrating data to the cloud, they often focus on the anticipated benefits: enhanced analytics, scalability, and data democratization, to name a few. With a results-driven focus, the challenges associated with this transformation can sometimes be overlooked. One such challenge is the need to maintain an access management framework that streamlines comprehensive...
According to the United States’ Cybersecurity & Infrastructure Security Agency (CISA), 47% of American adults have had some amount of their personal information exposed by cyber criminals. With the volume of data that today’s organizations collect, store, and leverage on a day-to-day basis, no one wants to be responsible for...
In our globalized world, data sharing is table stakes for organizations that want to innovate and compete. Gartner has predicted that enterprises that share information will outperform those that do not on most business metrics, and leading organizations like Snowflake and AWS are already offering data exchanges to simplify the process. But as consumers become increasingly...

As modern organizations look to innovate with agility, migrating to the cloud enables them to unlock data’s value at scale. Leading cloud data platforms like Snowflake allow data teams to store and analyze mass amounts of data, all while providing access for an ever-increasing number of users and use cases. And while...
As data is being analyzed in new ways to deliver better insights, organizations across industries are focusing on democratizing its use in order to capitalize on its business-driving capabilities. In fact, one survey found that 90% of data professionals are prioritizing data democratization at their companies. This sentiment is also present in...

If you’ve done any work with data, you’ve likely heard the term “sensitive data.” Data compliance regulations like the GDPR, HIPAA, CCPA, and more make repeated mentions of “sensitive personal data” and “sensitive personal information,” and many privacy statements include similar language. A quick search of the term “sensitive data” returns more...
When we think of threats to data, malicious hackers who are out to profit off our information tend to come to mind. But what about the risks that are hiding in plain sight? Outdated systems, shared passwords, and lax controls may all seem like low grade issues – until they...
The volume of cloud data is increasing at an exponential rate. But with this growth comes an increased attack surface, heightening the risk of dangerous data breaches or leaks. To support the operations of modern businesses and agencies across the world, data resources require storage that can remain secure at...
Over the past several years, the Immuta team has worked closely with product teams at Snowflake and Databricks to ensure that joint customers are able to leverage the full power of their cloud investments, while ensuring their valuable data assets remain secure. We are excited to introduce our newest suite of features that strengthen...

Immuta continues to innovate in partnership with Databricks, and we’re excited to announce the general availability of Immuta’s native integration with Databricks Unity Catalog to secure workloads on the Databricks Lakehouse Platform. With this integration, the Immuta Data Security Platform natively orchestrates security and offers the same user experience across the Databricks Lakehouse Platform using...
It’s no exaggeration to say that virtually any contemporary organization relies on data. And as data assets and use cases multiply, teams need to be able to store, access, and analyze their data securely and at the speed of business. Platforms like the Snowflake Data Cloud have met this need head-on, offering...
On February 16, 2023, Australia’s Attorney-General’s Department (AGD) publicised its Review Report, the latest output in the Privacy Act 1988 review process that began in 2020. The report seeks to strengthen the Act, while retaining the flexibility of its principles-basis. One core motivation is to bring the Privacy Act closer to...
In today’s tech-driven world, data security is a paramount concern for every industry. But when sensitive government or educational data is involved, the stakes become even higher. The need to protect this information, ensure citizen and student privacy, and mitigate threats to their data has never been more critical. That’s...
In a fast-moving field, established frameworks can often benefit from strategic updates. Think of your cell phone or laptop: do they still function using the same operating system that they had when you first bought them? No, they require regular updates–some more significant than others–that routinely improve their functionality and...
When two different concepts sound or act alike, it can be easy to conflate them. We see this in everyday life: jelly vs. jam, weather vs. climate, latitude vs. longitude, concrete vs. cement, the list goes on. In the ever-expanding world of data jargon, this kind of problem can easily...
As the world becomes increasingly digital, data security has become a critical concern for businesses of all sizes. Threats to data are evolving as technology and bad actors become more sophisticated, which makes the challenge of protecting sensitive information that much more complicated. Ensuring that data protection processes and policies...
With global business and operations so heavily reliant on data collection, sharing, and analysis, data breaches can seem inevitable. In fact, the Identity Theft Resource Center (ITRC) reports that there were 445 publicly-reported data compromises in Q1 of FY23 that affected 89,140,686 individuals worldwide. While organizations often take a proactive approach to...
The modern business is driven by data and AI. Decisions are no longer based on institutional knowledge or gut feel, and they’re not being made solely in the boardroom. Managers and individual contributors are expected to leverage data to make the day-to-day decisions they need to do their jobs, but...
Health data is one of the most valuable assets organizations in the healthcare and life sciences industry can possess. It’s also one of the most vulnerable. Over the years, legal steps have been taken to protect healthcare data security and patient privacy. The Health Insurance Portability and Accountability Act (HIPAA), passed by...

As data breaches and cyber attacks become more common, protecting data privacy is an increasingly important concern for companies that use data to compete. According to Cybercrime Magazine, the total cost of cybercrimes is an estimated $8 trillion, and is expected to climb more than 30% in the next two years....
From providing quality patient care and correctly diagnosing medical issues, to developing vaccines and monitoring public health trends, efficient data use in the healthcare and life sciences industry could literally be a matter of life and death. But data use in healthcare and life sciences is highly regulated, and patients are...
Forrester’s new Total Economic Impact™ (TEI) study provides a detailed financial model based on interviews with six Immuta customers in order to assess the ROI of the Immuta Data Security Platform. The study concludes that Immuta can provide benefits totaling $6.08M, an ROI of 175% over three years, and a payback period...

When it comes to making decisions, context is essential. Imagine your neighbor asks for a key to your house. If they’ve agreed to watch your dog while you’re away on an upcoming business trip, this question should present no issues or concerns. If they’re asking because they want to throw...
As organizations look to migrate and optimize their data resources, cloud data platforms are continuing to evolve. But while these platforms offer enhanced storage, compute, and analysis capabilities for the modern data stack, they may also broaden the attack surface of data ecosystems. More platforms–combined with more users and more data–can...

If you’ve heard the term CMMC being used more frequently, you’re not alone. This upcoming change in certification requirements for Department of Defense contractors and subcontractors will have major implications and require significant changes for organizations in order to continue landing government contracts Here are all the basics of CMMC,...

With cloud data platforms becoming the most common way for companies to store and access data from anywhere, questions about the cloud’s security have been top of mind for leaders in every industry. Skepticism about the security of cloud-based solutions can even delay or prevent organizations from moving workloads to...
Before we can talk about modernizing from a legacy Business Intelligence (BI) extract, we need to answer the questions: why are they used? And what are they? The “why” behind extracts boils down to improved query performance on published dashboards. You can see more details about the “why” for data extracts in...

More organizations than ever are leveraging the power of multiple cloud data platforms for business-driving analytics. In fact, 93% of organizations have a multi-cloud strategy for analytics and data science, and 87% have a hybrid cloud strategy. In the next two years, the trend toward diverse cloud data ecosystems will continue, as more...

Databricks table ACLs let data engineers programmatically grant and revoke access to tables. With table ACLs enabled, users have no access to data stored in the cluster’s managed tables by default until granted access, thereby improving sensitive data security. With Databricks runtime 3.5 or above, table ACLs allow authorized users...
We are extremely excited to announce that Immuta has achieved Google Cloud Ready – BigQuery designation, validating our native integration with BigQuery and providing joint customers with confidence in our partnership. As part of the validation process, Google Cloud engineering teams run a series of data integration tests, compare results against benchmarks, work closely...
The average hospital has seen a 90% turnover of its workforce in the last five years, and 83% of RN staff. Nurses are not just protesting about their inability to deliver great care – they are leaving the healthcare field altogether. And they’re not the only ones. From the doctors to those...
When a data breach occurs, time is of the essence. On one level, modern compliance laws and regulations have set standards for the window of reporting data breaches, often requiring organizations to do so within 72 hours to avoid penalization. But monetary and legal penalties are not the most important outcomes of...
Why settle for one cloud when you can have a whole buffet of platforms to keep your data safe and sound? With more and more sensitive information being stored in the cloud, having a comprehensive cloud data security strategy is absolutely critical to prevent your data from being hacked, leaked, or stolen....

Data is the lifeblood of any organization, and keeping it secure is of the utmost importance. With the ever-increasing amount of data being generated and shared, organizations are facing more challenging data security threats than ever before. The rise of cyber-attacks, data breaches, and regulatory compliance requirements has made data security a...
The concept of Zero Trust is not new, but it is gaining traction as data security becomes more scrutinized. Also referred to as “perimeter-less security,” Zero Trust has traditionally focused on employing network-centric tools that enable automated access controls, network microsegmentation, and continuous monitoring of connected devices. Following a 2021 Zero Trust executive order, government...

The 2020 elections not only saw record turnout, but also ushered in a suite of new laws and lawmakers. Voters in California had a dozen propositions on the ballot, but one that has far reaching implications for citizens and organizations alike is Proposition 24, the California Privacy Rights Act (CPRA) — or...
We are excited to announce that Immuta’s latest product release is here, offering deeper native integrations with Databricks and Snowflake alongside overall performance enhancements. In this blog, we’ll highlight our new key capabilities: Databricks Spark Integration with Unity Catalog – Customers can use Immuta’s Databricks Spark integration to enforce fine-grained access control on clusters in Databricks Unity Catalog-enabled...
Today’s data engineering teams face various challenges wrangling massive volumes of data, dispersed stakeholders with competing priorities, and distributed data architectures. But of all these variables, which is the most taxing? In this blog, we’ll delve into the most common data engineering challenges as reported by 600 data engineers, and how...

As the volume of data generated, transformed, stored, and accessed has increased, digital transformation has significantly altered how companies do business and use data to create value. To deal with increasingly complex unstructured and semi-structured data, organizations are looking to build their analytics to stay competitive. Along with this, the...
Do you have complete confidence in your organization’s privacy law compliance? If your answer is no, you’re in the majority. According to the International Association of Privacy Professionals (IAPP), only 20% of respondents report being fully confident in their company’s approach to data privacy compliance. But data privacy concerns aren’t subsiding anytime soon...
With massive amounts of data being generated each day, and an increasing number of people accessing, analyzing, and sharing that data, understanding all data access activity is more than a full-time job. In fact, it can feel downright unmanageable. The good news? With the right tools, you can get the...

According to one 2022 report, 89% of companies claim that their organization is taking a multi-cloud approach to data storage and analysis. This means the data they collect lives in at least two different cloud databases, if not more. The data must be accessible to the variety of tools meant to...

There are many lessons that I learned throughout my civilian and military careers, but one that continues to hold true is that obstacles to accessing the data national and strategic analysts need are not caused by a lack of reporting in the field. Rather, it is the technical burdens, lack...
According to the U.S. Department of Health and Human Services’ Office for Civil Rights, there were 4,419 reported healthcare data breaches between 2009-2021. As a result of these breaches, roughly 314,063,186 health data records were exposed to those with no right or legitimate purpose to access them. In the first half...
Immuta’s latest release is here, and we are excited to share the new features and integrations we’ve been working on: Google BigQuery Native Integration – enables seamless fine-grained access controls without being in the data path Snowflake External OAuth – provides secure delegated access and allows customers who use their own IdP...
Modern enterprises rely on data to deliver insights across every line of business, from sales and marketing to finance and HR. Gone are the days when data use was limited in scope – today’s increasingly decentralized data initiatives and architectures require decentralized access management. Continuing to consolidate data stewardship within...

Virtually all modern organizations prioritize the collection and storage of insight-fueling data. As these groups strive towards more data-driven initiatives, they are collecting increasingly large amounts of data. In turn, this data needs to be accessible to a growing number of data users in order to maximize the impact on...
Digital-first cloud data management is the future. A survey by the International Data Corporation (IDC) found that “90% of European organizations consider it crucial to have a digital-first strategy to achieve business value from more of their data.” However, only “32% of data available to enterprises is put to work.” This leaves...

For Dave DeWalt, Founder and Managing Director of advisory firm (and Immuta investor) NightDragon, the modern data stack–like dragons–has a compelling dual nature. Balancing power with danger, both evolving data stacks and dragons contain immense potential strength that can (quite literally) go up in flames if not managed properly. DeWalt, John Cordo,...

As modern data stacks become more complex, data teams need more efficient ways to manage sensitive data. When more data sources are added or more platforms leveraged for storage and analysis, understanding what kind of data lives in your data ecosystem can become increasingly difficult. This difficulty becomes more of...

“What’s really critical to Snowflake customers is that…to use the data that they have, they have to make sure that it’s secure and governed correctly. And Immuta helps them to make sure that it is.” – Paul Gancz, Partner Solutions Architect, Snowflake At Snowflake Summit 2022 in Las Vegas, Immuta had the chance...
When the General Data Protection Regulation (GDPR) entered into force, US privacy law was still in its infancy. Though enforced by the European Union (EU), the GDPR had wide-ranging implications for organizations well beyond Europe. And though it has become the regulatory standard in data privacy since it became applicable...
As important as data analysis is to modern businesses, enforcing the proper access control on that data will always be paramount. This remains true as organizations in every industry continue migrating sensitive data to the cloud from legacy data storage systems. Regardless of which tools and platforms are used for storage and...
For data engineers, the effort required to wrangle access policies grows exponentially as the complexity of data security increases. High table access segmentation necessitates managing a correspondingly large number of roles and grants. Data that is segmented down to the row level, for example, may require a series of transforms or view...
The ability to efficiently discover data and visualize it in meaningful ways has never been more important. Tools like Tableau allow users to see data in an easily interpretable, shareable way that empowers data-driven decision making. However, with more organizations now collecting, storing, and analyzing sensitive data, the onus is on data...

“Databricks is what I think has thrust this community into a whole new stage of cloud compute.” – Matt Carroll, CEO, Immuta At June 2022’s Databricks Data+AI Summit in San Francisco, Immuta had the chance to meet with a range of customers, partners, and other attendees to talk about the next generation...
As business continues to shift to increasingly digital environments, the aggregation and sharing of financial data is predicted to have a staggering impact on the global economic future. According to research by McKinsey, “economies that embrace data sharing for finance could see GDP gains of between 1 and 5 percent by...
In the cloud computing era, ensuring data policy is co-created with data is essential. Historically, data access and security policies were an afterthought, leading to sub-optimal implementations. These implementations give rise to confusion, data leaks, and unsustainable maintenance burdens. In order to be effective, organizations need to separate policy from cloud platforms....
As data storage and analysis continue to migrate from on-premises frameworks to those based in the cloud, the market for cloud storage and data security platforms (DSPs) has expanded. In fact, the global cloud security market is projected to grow from $29.3 billion in 2021 to $106 billion by 2029. This highlights...

As market demand for data mesh has grown, the need for dynamic attribute-based access control (ABAC) on Starburst’s popular data mesh architectures has increased as well. Therefore, we’re proud to announce Immuta’s native integration with the Starburst (Trino) federated query engine for data mesh architectures. Organizations eager to leverage Immuta’s integration with Starburst to...

The data security and privacy space continues to evolve to keep pace with the constantly changing data regulations, an evolving threat landscape, and increasing amounts of data and users with access to that data. Data security and privacy vendors need to be constantly innovating to keep pace with all the aforementioned changes. With...

Data controls refer to the tactics, policies, and procedures that organizations use to meet their data governance and data management objectives. Put another way, they are the rules and systems that businesses rely on to ensure that only authorized users can access their data, ensuring its security and integrity. Data...
By 2025, experts anticipate that there will be around 175 zettabytes of data in the world, up from only 44 zettabytes in 2022. While those numbers are incomprehensibly large (a zettabyte is the equivalent of a trillion gigabytes), they help demonstrate that there’s an enormous and rapidly growing amount of data in...

As cloud technology has become more advanced, data teams are better able to mitigate the risk of unauthorized access. In fact, the array of choices regarding how to protect data at times makes it confusing to know which is right for your organization’s data. When you’re trying to strike a...

As data further cements itself as an essential resource for modern businesses, more steps must be taken to guarantee its security. Why? These measures may be related to how and why data access is governed, ensuring that proper data access controls are in place to maintain the necessary security of...
As data evolves, so does the threat landscape. Facing the possibilities of targeted breaches from external players, risky or negligent activity from insiders, and mounting pressure from the informed public, organizations need to be more intentional than ever with how they protect their data. At the same time, both data...
Data is essential to modern business, thanks to its ability to improve insights and drive competitive decision-making. Yet, while many organizations are adopting cloud data platforms to simplify seamless onboarding of new data sources, managing access to data can significantly slow time-to-value. Should this stop you from adding more data...

The modern data stack bears the immense responsibility of storing, protecting, analyzing, and operationalizing a resource that is constantly in flux. As data continues to increase and evolve, these tools need to make sure it is both being used effectively and kept safe from leaks. This issue and potential solutions...
Since the White House released its Executive Order (EO) on Improving the Nation’s Cybersecurity in 2021, federal agencies have begun developing long-term zero trust security architectures across their networks while also adopting near-term goals. Officials from the Office of Management and Budget (OMB), the Cybersecurity and Infrastructure Security Agency (CISA), and the White House’s...

I’m excited to announce Immuta’s $100M Series E funding, bringing our total funding to $267M. The funding round includes new investors NightDragon and cloud data leader Snowflake, as well as participation from existing investors Dell Technologies Capital, DFJ Growth, IAG, Intel Capital, March Capital, StepStone, Ten Eleven Ventures, and Wipro Ventures. (read the press...

As data moves among the storage, compute, and analysis layers of a data stack, there is constant need for measures to ensure its security and protect personally identifiable information (PII). This security is often required by law, as is evident through financial regulations like PCI-DSS, the Gramm-Leach-Bliley Act, and more. Immuta’s integration with Databricks helps...

Privacy preserving analytics attempt to enable the exploitation of data sets that include private and sensitive data in a manner which protects the disclosure and linkage of sensitive data to individuals. At a minimum, this means removing or obscuring all directly identifying attributes (DIs), which are defined as publicly known...

Have you wondered how to protect your Snowflake data warehouse with column-, row-, and cell-level protection while accelerating time to your cloud data? With Immuta SaaS on Snowflake Partner Connect, access to data is faster and more secure than ever. Immuta provides data teams with one universal platform to control access to...
Before diving into best practices for data masking, it’s integral to answer the question: what is data masking? Data masking is a form of data access control that alters existing data in a data set to make a fake–but ultimately convincing–version of it. This allows sensitive data like social security numbers, credit card...

Data masking is a data access control and security measure that involves creating a fake but highly convincing version of secure data that can’t be reverse-engineered to reveal the original data points. It allows organizations to use functional data sets for demonstration, training, or testing, while protecting actual user data from breaches or...

What Is Data Tokenization? Why Is Data Tokenization Important for Data Security? When Should I Use Data Tokenization? Top Tokenization Use Cases What’s the Difference Between Tokenization and Encryption? Applying Data Tokenization for Secure Analytics
Data masking replaces sensitive information with fake but convincing versions of the original data. Given the necessity for sensitive data protection, data masking must be adaptable to any data environment. Regardless of the size, purpose, or tools in your data stack, there is a type of data masking that fits your...

The explosion of organizations that collect and store data for analytics use has led to an inevitable rise in data breaches and leaks, in which attackers or otherwise unauthorized users are able to gain access to sensitive data. It makes sense, then, that individuals and organizations alike are more cognizant...

What Is Data Masking? Why Do I Need Data Masking? What Are Some Data Masking Techniques? When Do I Need Data Masking? Top Use Cases How Do I Apply Dynamic Data Masking?

Data anonymization is the process of transforming information by removing or encrypting personally identifiable information (PII), protected health information (PHI), sensitive commercial data, and other sensitive data from a data set, in order to protect data subjects’ privacy and confidentiality. This allows data to be retained and used, by breaking...

The data anonymization landscape is broad and constantly evolving as new technology comes online, regulations are passed, and the limits of what can and can’t be done with data expand. This constant state of flux begs the question: where should you begin when it comes to anonymizing sensitive data? Regardless...

Governance and security are hot topics in data mesh, as evidenced by the recent webinar I co-presented with Andy Mott at Starburst that landed 350+ registrants, including the who’s who of industry luminaries on the topic. It’s easy to see why – without proper planning, decentralization can become the wild west of data management....
In daily conversation, we often use umbrella terms to simplify communication. For instance, if someone tells you they work for “the government,” you get a general understanding of what type of work they do without necessarily knowing their exact agency, office, or role. Categorization allows us to easily discuss a...

There’s no disputing the importance of data in driving cutting edge insights and business outcomes. However, for many organizations, the gap between raw data collection and data-driven results is wide and difficult to navigate. Colin Mitchell, Immuta’s GM of Sales for EMEA and APJ, recently met with data leaders from...
This blog was co-authored with Deepak Nelli, Director of Sales Engineering at Alation. The modern data environment is changing. Cloud data platforms provide data-driven organizations with advanced analytics capabilities alongside much-needed simplicity; yet, greater demand for data, more data consumers and use cases, and a growing body of data use...

According to the Identity Theft Resource Center, there were 1,862 data breaches in 2021, exceeding the previous record of 1,506 in 2017. Of these breaches, 83% contained sensitive information that became available to the attackers. The exposure of large swaths of raw data, especially when sensitive, can have dangerous consequences. In...

In 2021, the National Geospatial-Intelligence Agency (NGA) published its new data strategy, which seeks to improve how data is developed, managed, accessed, and shared to maintain an advantage in geospatial intelligence. In its strategy, the organization pinpoints goals and action plans that the NGA, the Department of Defense (DoD)/Intelligence Community (IC),...

It’s no surprise that nearly 90% of organizations rely on a multi-cloud strategy to get value from their data. Yet, despite budgets for data management solutions continuing to increase, 57% of data leaders say that “their tools and tech definitely need improvement.” This may indicate a lack of cohesion across cloud platforms, but it...

Attribute-based access control (ABAC) grants or restricts access to data using context-based decisions based on information about the user, the data itself, the intended action, and the environment generally. It’s well-documented that ABAC is the more flexible, scalable access control option when compared to static role-based access control – NIST has formally supported...
Financial data is among the most sensitive information an organization can possess, yet its use is essential to the health of global markets. It’s no secret, therefore, that data security in financial services is a highly scrutinized topic – and one that is subject to a plethora of data compliance regulations. The Australian...
The world of data is full of interesting language, complex terms, and more acronyms than a bowl of alphabet soup. Being such a dynamic field, these terms are always being developed, adopted, and adapted to describe new and exciting advances. That said, it’s easy to feel out of the loop...

Successful data platform teams and championship sports teams have a handful of things in common – strong baseline skill sets, effective coaching and training, and good communication skills. But as people come and go, what’s the secret of those that remain on the top over years or even decades? I...

As cloud adoption accelerates, SaaS-based products have also exploded to fill the agility, scalability, and flexibility gaps of legacy solutions. McKinsey estimates that by 2024, the market for SaaS products will reach $200 billion, and according to BMC, more than three-quarters of SMBs have already adopted a SaaS product. While certain SaaS-based services...

There’s a lot of confusion in the market about attribute-based access control (ABAC) and what it actually is. This short blog will use a handy analogy to explain ABAC.

Recently, across the social media spectrum there has been an uptick in government program leaders, technology salespeople, and systems integrators all sharing opinions on how best to deploy new technology quickly, cost effectively, and with the proper architecture to support both short- and long-term federal program goals. Unsurprisingly, there’s little consensus, with...
As data use has become ubiquitous, data breaches have followed suit. Though down from a peak of 125 million compromised data sets in late 2020 – which was at least partly attributable to the sudden shift to remote work during the pandemic – data breaches still expose millions of data assets every...

Scientists predict that by 2025, the world will produce a staggering 463 exabytes of data each day. That’s the amount of data you’d accumulate if you initiated a video call right now and let it run for the next 110 million years. Of course, we’ve been producing vast amounts of data for quite...
Identity and access management (IAM) systems have become essential components of organizational workflows, allowing users to access the appropriate tools without requiring admin privileges. But when it comes to data access control, organizations are often left wondering why the user information stored in their IAM software can’t also be leveraged to...
Data can deliver an important strategic advantage — if organizations can make it simple and safe to consume and share. However, legacy systems and processes that are slow to change means this is often easier said than done. To realize the full potential of data-driven modernization, automated policy enforcement is...

Immuta is the universal cloud data access control platform that gives data engineering and operations teams the power to automate access control across their entire cloud data infrastructure. By leveraging metadata to build and automatically enforce data access policies at query time, Immuta allows organizations to unlock the full value...

To deliver on the need to manage and secure software across modern data stacks, Immuta has announced the general availability of SaaS deployment. This includes SOC 2 Type 2 Certification, enabling data teams to automate data access control while eliminating the need to self-manage and maintain the deployment. Immuta’s SaaS deployment enables data...

With the world of data analytics and governance constantly changing, it is critical for organizations to stay on the cutting edge. The sharing of ideas between innovators and industry leaders help provide a glimpse into the dynamic core of this field, highlighting the trends central to staying competitive both today...
For Data Engineers responsible for delivering data to consumers, the effort needed to wrangle policies can quickly get out of hand as the complexity of data access controls increases. High segmentation of table access necessitates the management of a correspondingly high number of roles and grants. For example, if data...

Is it possible to manage a successful business or organization if you’re not successfully managing your data? Data management in business can be perceived as both an essential task and an annoying nuisance. The fact is that if your organization deals with data of any kind, you need a system...

Collecting and analyzing aggregated data is essential in today’s connected world, but are you doing everything necessary to ensure the privacy of the individuals behind that data? Not only is it ethical and moral to take necessary security precautions when dealing with consumer data, but it’s also a legal requirement...

Data access control and governance are central tenets of a strong cloud data strategy. As demand for data grows, so do the number of platforms touting cutting edge access control management capabilities. The data governance landscape is rapidly evolving and data access control – a subset of the overall market...

At Immuta, the security of our customers’ data is of paramount importance. We are thrilled to announce that our SaaS deployment option has achieved Service Control Organization (SOC 2) Type 2 attestation as part of our ongoing commitment to providing the highest level of security and assurance.
The good news is no. The better news is you are already 90% of the way there and probably don’t even know it!
As data has become one of the most prized resources for companies around the world, two vital imperatives have increasingly butted up against each other in conversations among private companies, consumers, and government regulators — the desire to harness customer data for profit and the need to keep that data...
GDPR, CCPA, and PIPEDA are just a few examples of the growing number of strict data privacy laws around the world that are impacting virtually every aspect of how companies do business. While regulatory hurdles certainly add complexity to any business’s operations, that doesn’t mean that they’re a limiting factor....

The average person doesn’t go through life wondering which data privacy regulations are protecting their personal data. Data privacy as a concept is well-known and desirable, but the specific laws, such as GDPR, HIPAA, and COPPA, rarely receive the same attention. Yet, by 2024 data privacy regulations will dictate how...

It is something along the lines of common wisdom to describe cybersecurity as one of the biggest strategic challenges confronting the United States. And that challenge is growing in scope; In 2023, US federal agencies experienced a 5% increase in cybersecurity incidents — totaling over 32,000 — compared to the...
Increasing demand for data and its evolving uses – particularly personal and sensitive data – are turning traditional data supply chains upside down. Today’s environment necessitates real-time data access to drive decision-making, which in turn requires a continuous, efficient flow of data throughout organizations. It’s clear why manual processes and...
A data mesh is an increasingly popular data architecture framework that moves away from the monolithic approach of data warehouses and data lakes in favor of a more decentralized method of cloud data management. This approach distributes data ownership to individual business domains, so that data access and management decisions are context-aware. As...
We’re all familiar with supply chains in the realm of manufacturing. Well, the same concept applies to data management. In data management, there are data supply chains that involve raw inputs from source data systems that go through a number of processing steps and emerge at the end as a...

Data orchestration is the process of bringing together data from various storage locations, combining it in a coherent form, and then making it available for use by an organization’s data analysis and data management tools. This process is usually software-driven, connecting multiple storage systems and allowing your data analysis platforms...

Someone starting a small business – think custom t-shirts, candlemaking, etc. – could probably operate out of their home, keeping their basic supplies and inventory in a spare room, closet, or garage. If their business were to take off and experience exponential growth, however, this type of operation would quickly...
Scalability and performance go hand-in-hand. If you have great performance, but not a scalable solution, you haven’t solved much. The inverse is also true. This is why the cloud is so successful, and tools like Databricks work so well – they can scale on the cloud by spinning up performance-appropriate compute to...

Metadata management is the collection of policies, processes, and software/hardware platforms used to manage and store metadata for your organization’s data assets. The larger and more complex the stockpile of data assets, the more critical proper metadata management is for ensuring that data is usable, secure, and available for individuals...
The terms ‘data intelligence’ and ‘data analytics’ may as well be enshrined in marble for any modern business looking to capitalize on the power of information. But does your business have a handle on what data intelligence and data analytics are, and more importantly, what they mean for your company?...
The role-based access control versus attribute-based access control debate has been going on for decades. Now, as organizations move away from on-prem and Hadoop-era technologies in favor of modern, cloud-based data environments, the differences between the two security approaches are coming into sharper view. A new study from GigaOm comparing the two approaches head-to-head,...
Technology has made our world increasingly interconnected and interdependent, and as a result, the need to share data to remain competitive is more important than ever. Yet, despite the competitive advantages associated with data sharing, many organizations still treat it strictly as a data function instead of a business priority. According...
Data leaks are everywhere in the news. Is your company safe and readily able to prove compliance? While advanced security measures have become increasingly important for protecting businesses against data breaches, lost data, or other security threats, one simple and straightforward tool is often overlooked — the data audit trail.

There’s an old adage that all press is good press, but one kind of attention that’s been showered on companies both large and small in recent months is the type that no organization wants — scorn after an inadvertent data leak. While keeping customer data safe from leaks may seem...

Data has been called “the new gold” for its ability to transform and automate business processes; it has also been called “the new uranium” for its ability to violate the human right to privacy on a massive scale. And just as nuclear engineers could effortlessly enumerate fundamental differences in gold...
Writing or modifying scripts, managing templates, or creating policy for cloud data platforms is historically a manual process. Assuming there is very little maintenance, doing this process once may be sufficient — but that assumption is never realistic. Complicating this further is the need to manually replicate this environment at...

For more than 160 years, Credit Suisse has been providing customers with best-in-class wealth management, investment banking, and financial services. As one of the largest multinational financial firms, technology is critical to the company’s global operations — and with nearly 50,000 employees worldwide, there is a high standard for efficient, adaptable IT...

Data masking is one of the most important tasks in data governance. It may seem simple in practice, but getting it right can be the difference between a straightforward path to properly secured data, and a complex, confusing experience that leaves your data exposed to breaches. To add to the...
As Zhamak Dehghani describes in her original article, “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”: “[a Data Mesh] is the convergence of Distributed Domain Driven Architecture, Self-serve Platform Design, and Product Thinking with Data.” What does that really mean? Rather than putting one team...

Data generalization is the process of creating a more broad categorization of data in a database, essentially ‘zooming out’ from the data to create a more general picture of trends or insights it provides. If you have a data set that includes the ages of a group of people, the...
Data lakes have become essential tools for businesses in the era of Big Data. But keeping those data lakes secure has never been more important as cyberthreats are constantly on the rise. Here’s everything you need to know about data lake security and how Immuta can be an essential partner...

Organizations expanding their cloud data ecosystems (multi- and cross-cloud services for building data products) are faced with a number of options on where to enforce fine-grained access control policies on sensitive data, including security and privacy controls. As modern cloud architectures decouple compute and storage layers, the policy tier that...

Would you like to monetize your internal data by sharing it externally with third parties? Do you see the power of joining your data with data from other organizations to drive stronger and better insights? The desire to share data with third parties is fueled by the realization that: The...

Immuta was born out of the Intelligence Community in 2015 to help organizations solve the most complex data access control challenges. These challenges have only grown since that time as our dependency on sharing sensitive data across platforms and groups to support decision makers has increased. To meet the needs of this...

When we founded Immuta in 2015, the data landscape barely resembled what it is today. Then, organizations were focused on big data management and few were primarily cloud-based. Hiring for data scientists and analysts skyrocketed as leaders realized the value of data-driven insights, and DevOps was becoming a popular paradigm....
As companies started moving data to the cloud and separating compute and storage for added efficiency, cost savings, and flexibility, data platforms became more advanced and diverse, introducing new categories for best-of-breed technologies. With data engineering and operations teams now accelerating adoption of more than one cloud data platform, according...

Data de-identification is a form of dynamic data masking that refers to breaking the link between data and the individual with whom the data is initially associated. Essentially, this requires removing or transforming personal identifiers. Once personal identifiers are removed or transformed using the data de-identification process, it is much easier to...

Kaj Pedersen, Chief Technical Officer at AstrumU, joined Immuta and Databricks at a recent Amazon Web Services Machine Learning Dev Day. This blog recaps his presentation on building a data governance and compliance strategy. Before founding AstrumU, Adam Wray identified a crucial — and costly — problem plaguing the American employment...
Data protection law emerged in the 1970’s in Europe as a means to protect against the risks posed by automated or computer-based data processing. As a concept, it thus goes far beyond protecting individuals against the disclosure of nonpublic information, a concern that is still very much at the center...
Businesses and organizations hold more personal data now than ever before. In general, this data is used to better serve customers and more effectively run business operations. But with plenty of malicious parties eager to access personal data and track sensitive information back to its source, finding a way to...
The first step of goal achievement is goal setting, and the first rule of goal setting is to make SMART goals — specific, measurable, attainable, relevant, and time-based. This best practice is well known by teams across industries and has been implemented for decades. However, as Gartner’s report The State of...
As a data engineer or architect, your organization’s security and compliance teams look to you for answers about who is accessing your company’s data. But in the wake of data privacy regulations like the CCPA and Europe’s GDPR — not to mention a growing array of other state, federal, and industry rules — requests...
Whether your organization has 50 people or 50,000, one common denominator remains: Data analytics is no longer a nice-to-have, it’s a need-to-have. But what value are your analytics, data science, or BI initiatives providing if you’re unable to fully leverage all your data — including the most sensitive? When Immuta...
Immuta and Databricks have deepened our strategic partnership and augmented our native product integration by announcing Immuta’s support for Databricks SQL Analytics and deployment on Google Cloud. These are the latest capabilities offered to joint Immuta and Databricks customers, which also include metadata-driven policy authoring, fine-grained and attribute-based access controls, and most recently, expanded access control for R...
One of the most traditional methods of determining who can and cannot access certain data is a framework known as role-based access control (RBAC). This approach defines specific user roles within a company, then specifies permissions for each individual role. But what if a company needs to go beyond these simple...
A data governance tool can help your organization automate data governance at scale, increase data utilization, and comply with data privacy regulations. In this blog post, we’ll highlight five of the most important features to look for in a data governance tool.

By the time COVID-19 was classified as a pandemic, it was already spreading like wildfire. As healthcare professionals, scientists, and federal agencies tried to understand the nature of the virus and implement appropriate mitigation measures and public health guidelines, it was quickly seeping into all corners of the globe. As...

In today’s day and age, we’re accustomed to technological advances and capabilities being uncovered all the time. However, mere availability does not necessarily correspond to immediate adoption. This is at least somewhat true for differential privacy. The first seminal contribution on the topic was published in 2006 by Microsoft Distinguished Scientist Cynthia Dwork,...

“Data initiatives never live up to their full potential without appropriate governance behind [them].” This quote, from a senior data strategist interviewed in the new Best Practices Report on Modern Data Governance from TDWI, encompasses precisely why organizations should be prioritizing a data governance framework. Yet, just 38% of report respondents have...
Organizations are increasingly recognizing their data as a valuable asset that can significantly shape and enhance business outcomes. As organizations continue to navigate digital transformation and the inevitable growth of big data, effective data governance frameworks have become essential to maximizing data’s value throughout its entire lifecycle. In this guide, we’re taking...
The General Data Protection Regulation (GDPR) is omnipresent: It applies to every person or entity processing personal data in the European Union (EU), as well as all organizations that process the personal data of individuals located in the EU. The regulation seeks to increase individuals’ control over their personal data, including...
The pros and cons of role-based access control (RBAC) and attribute-based access control (ABAC) have been well documented and debated. There are even different implementations of ABAC that use static attributes, defeating the intent of safely scaling user adoption. But understanding the delineations between different approaches and soundly implementing one or both...

Imagine this — You’re at the starting line of a road race. The gun goes off and the clock starts ticking. Runners take off — as you bend down to tie your shoes. You don’t have to be a runner to know that this tactic ends in your competitors leaving...
The terms role-based access control and attribute-based access control are well known, but not necessarily well understood — or well defined, for that matter. If attribute-based access control includes user roles, then what is role-based access control? Where is the line drawn? Fundamentally, these data access control terms — role-based access control and attribute-based access control...

With an industry-wide 92% cloud adoption rate, well over half of organizations using multiple public clouds and enterprises planning to spend a third of their IT budgets on cloud tools in 2020, it’s clear that the future of enterprise analytics is in the cloud. Cloud computing and analytics promises to enhance...
Access to sensitive data is more critical to data analytics and data science than ever before. But in today’s environment, speed to data access is contingent upon how secure that data is. To help data teams achieve faster, safer, more cost efficient analytics and data science initiatives, we have formed a...

Cloud provider capabilities are evolving faster than ever, and enterprises are taking notice. With all the progressive features, cost savings and labor efficiencies modern cloud data access control platforms offer, why wouldn’t organizations seize the opportunity to accelerate data analytics and derive insights that could give them a competitive edge? Unfortunately, cloud migration doesn’t...

Imagine going to a library in search of a specific book with a piece of information needed to finish an assignment. Did we mention you’re on a deadline? Good luck. This example may seem extreme, but for organizations that don’t have a data catalog, it’s not unfathomable. In either scenario,...

The vast majority of organizations now utilize the cloud in some form or another, yet there is no single process data teams follow when migrating data to their cloud platform. This may not seem like a red flag on the surface — if all the data gets from point A...
Why it’s time to reexamine the binary dichotomy between personal and aggregate data, and what aggregation, synthesisation and anonymisation mean for the future of data privacy. Privacy-enhancing technologies are typically used to transform data to enable sharing of private data with third parties. However, not all techniques reduce re-identification risks;...

A few years removed from the peak of the pandemic, we’re still understanding COVID-19’s impact on daily life. But one thing is certain – the pandemic made clear the importance of collecting and sharing health data. The virus’ unpredictable and widespread nature made tracing and testing critical to understanding transmission...
The new Databricks Enterprise Cloud Service architecture provides powerful network security capabilities, however, a lesser known benefit is that it enables Data-as-a-Service.

Data engineers and product managers are often responsible for implementing various controls and audit capabilities when managing healthcare data. To enable faster, data-driven innovation, these data professionals – particularly those who come to healthcare from other industries like tech or financial services – apply best practices such as deploying a proven data analytics stack...

“Over the past few years, data privacy has evolved from ‘nice to have’ to a business imperative and critical boardroom issue,” warns a Cisco benchmarking report. Security and privacy are colliding in the cloud and creating challenges like we’ve never seen before. This is particularly true for organizations making the move...

Many people fall into data engineering by accident. Software engineers may find that they enjoy building platforms to drive their company’s data initiatives; data scientists may find they need to get “dirty” to deliver insights at scale. What they have in common is that there’s always something new to learn...

The European Union’s General Data Protection Regulation — one of the most forward-leaning privacy regulations on the planet — was praised by Tim Cook in a recent speech in the EU because our personal data is “being weaponized against us with military efficiency.” Those are strong words, and frankly, accurate:...
Immuta was founded in 2015 in response to the U.S. Intelligence Community’s (IC’s) complex and sensitive data governance problems, empowering organizations to harness the value of their data while preserving data privacy and security. Our data security platform enables data engineers and data stewards to automate the enforcement of data access, governance,...

Striking the privacy-utility balance is the central challenge to organizations handling sensitive data. Assessing the privacy side of the balance requires understanding how different privacy policies are undermined. This post will focus on one particular attack against privacy and show how two different privacy policies respond to this attack. In...

Anti-patterns are behaviors that take bad problems and lead to even worse solutions. In the world of data governance, they’re everywhere. Today’s anti-pattern probably isn’t thought of as a “pattern” at all because it feels so obvious, and (on the surface) is too “easy” – you share data by giving...

Enterprises have a wealth of data at their fingertips and are eager to accelerate data innovation. But data governance can frequently stand in the way, posing issues that are both profound and vexing. Immuta’s CEO Matthew Carroll spoke with Dataiku’s Florian Douetteau, CEO, about the relationship between data governance and...