As cloud technology has become more advanced, data teams are better able to mitigate the risk of unauthorized access. In fact, the array of choices regarding how to protect data at times makes it confusing to know which is right for your organization’s data. When you’re trying to strike a balance between fast data accessibility and vigilant security, there’s a fine line between not enough protection and too much of it.
Two options that are widely popular – yet often confused – are data tokenization and data masking. And despite the benefits they both offer, one may cause more headaches than necessary.
In this blog, we’ll distinguish between the two and clarify which is best for your data needs.
What is data tokenization?
Data tokenization is the process of swapping sensitive data with a randomly generated string, known as a token. Tokens are non-sensitive placeholders that lack inherent meaning, and they cannot be reverse-engineered by anyone or anything other than the original tokenization system (this process is called de-tokenization). Therefore, even though the absence of an encryption key makes it a secure approach, tokenization can still be undone if you have an account on the tokenization system.
Below is a simple graphic showing how tokenization works.
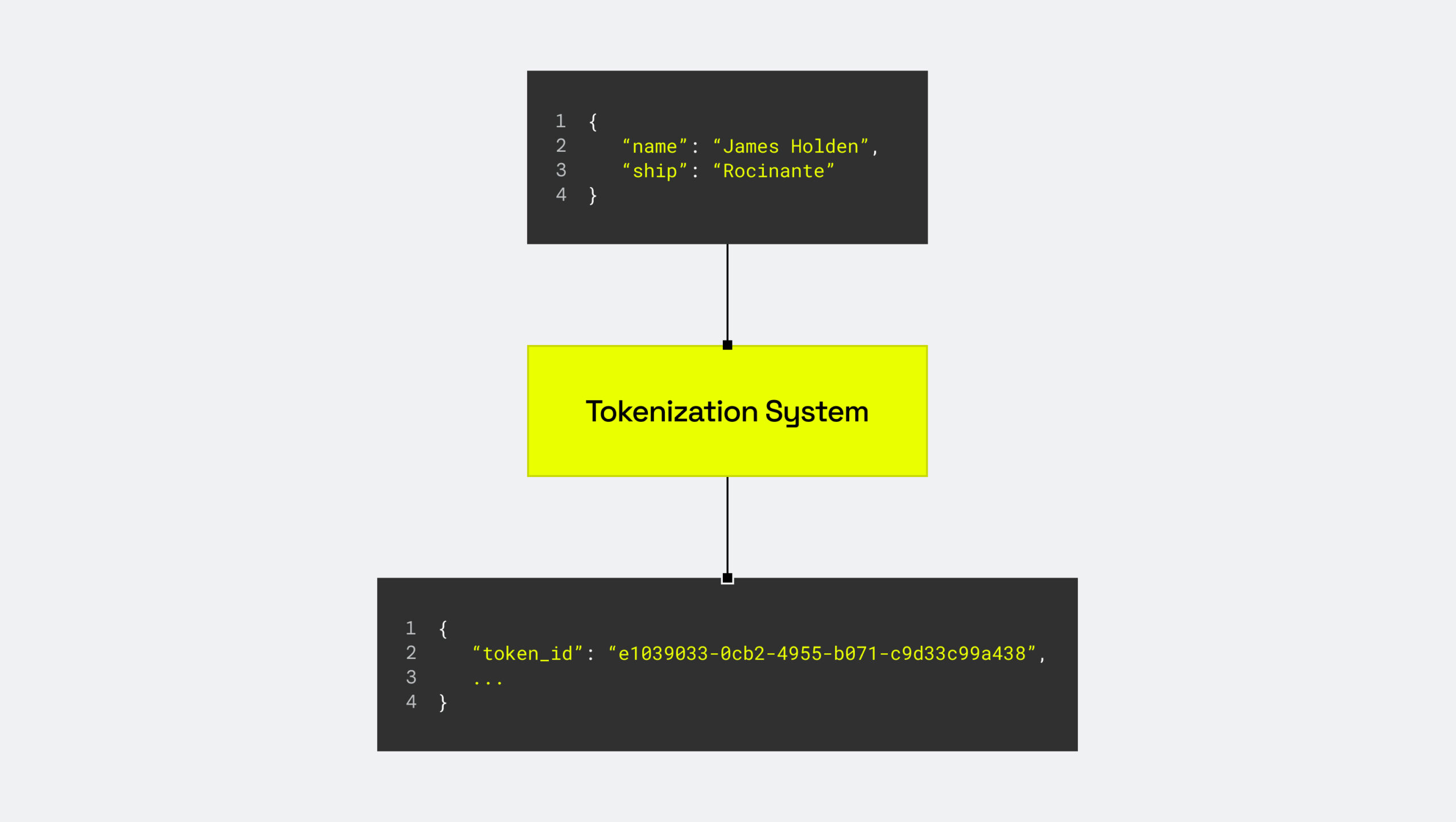
What is data masking?
Data masking alters sensitive data to create a fake but, depending on your goals, potentially useful version of the original data. This approach protects sensitive information – including both direct and indirect identifiers – while preserving general attributes like appearance and averages, among other things. In today’s hybrid environments, it’s critical that data masking policies are consistently and dynamically applied so as to mitigate potential points of failure.
There are two data masking methods: static, which alters sensitive data at rest; and dynamic, which alters data at query time to make context-based masking decisions. Regardless of which you choose, there are subsets of different data masking techniques, including:
- k-Anonymization: Combining data sets with similar attributes in order to obscure information about individual data subjects.
- Differential privacy: Injecting randomized noise into a data set to obscure the impact of any single record.
- Data redaction/nulling: Sensitive, confidential, or personally identifiable information is simply removed from the data set or replaced with “NULL.”
- Data generalization: Forming a more broad categorization of the data in your data set by “zooming out” and replacing precise values with nonspecific ones.
Below is an example of data masking using redaction.
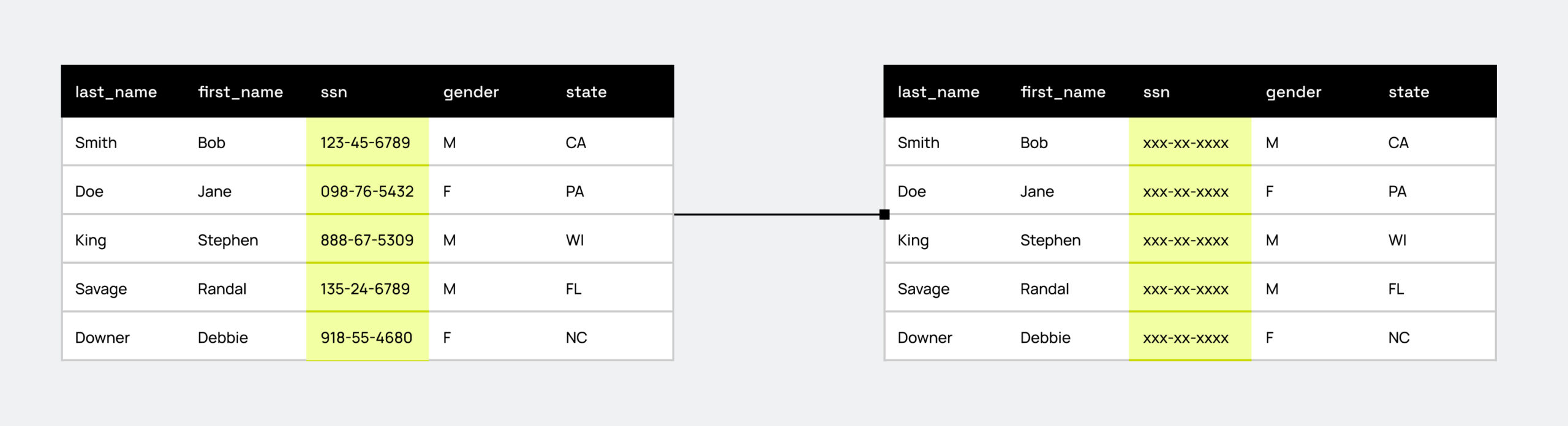
What's the difference between tokenization and data masking?
The primary distinction between tokenization and masking is that tokenization generally protects extremely sensitive data at rest, while data masking is primarily used for data that is actively used in analytical queries and aggregate statistics.
Between the two approaches, data masking is the more flexible. Not only does it encompass a broad range of techniques, as outlined above, but those techniques can be dynamically applied at query runtime using fine-grained access controls. So, depending on the rules, one user may see the data in the clear, while a separate user sees the masked version. With tokenization, there is a one-to-one relationship between the data and the token, which makes it inherently more static.
The table below highlights some of the key differences between data masking and tokenization:
|
Data Masking |
Data Tokenization |
|
Potentially hides or alters data values at read time. |
Replaces data with a random token at write time so it is always present for all queries. |
|
Can be dynamically applied/enforced through data access policies. |
Applied on a 1:1 basis using a tokenization database. |
|
Cannot be reversed, but can avoid being applied by contextual policy exceptions at query time. |
Can be reversed using the system that generated the token, but post-query only. |
|
Optimal for analytical workloads. |
Optimal for data at rest. |
|
Allows tradeoffs between utility and privacy. |
Extremely binary – utility and privacy are on/off. |
|
Good for analytical workloads. |
Good for securing sensitive data at rest, e.g. credit card or social security numbers. |
|
Allows request and approval flows to enable full SQL on the data by exception. |
Allows request and approval flows to de-tokenize, but only post-query. |
When should I use tokenization vs. data masking?
The nuances between data tokenization and masking can make it complicated to distinguish when to use each approach, particularly since tokenization is a form of data masking.
But here’s the truth: tokenization is often the overkill of the data governance world. Yes, it has its place, but it’s not a universal solution. The real answer to when you should use each approach comes down to the type of environment in which sensitive data is most used, the regulations the data is subject to, and the potential points of failure that could allow a breach to occur.
Let’s cut to the chase:
When to actually use data tokenization
Data tokenization is highly useful – and arguably, only truly necessary – for extremely sensitive data like credit card numbers and social security numbers, which have no analytical value.
Think about it: if your primary concern is preventing direct theft at the infrastructure or raw storage tier containing highly sensitive, regulated data at rest, and you have a robust system to manage those tokens, then tokenization is a valid option. In these specific scenarios, like achieving PCI DSS compliance in e-commerce and financial services, tokenization can simplify compliance and offer strong protection.
However, and this is crucial, the one-to-one relationship between data assets and tokens makes tokenization a far less scalable approach than data masking for analytical workloads. So, before you jump on the tokenization bandwagon, ask yourself: “Am I limiting tokenization to only the most sensitive information that provides no analytical value?”
When to use data masking (and why it's often the better choice)
Like tokenization, data masking is typically implemented to secure PII and protected health information (PHI). But here’s where it gets interesting: while masking can protect the same data types, it’s primarily designed for data that is analytically relevant and in use.
This makes it the superior choice for the vast majority of modern data environments. Think AI, machine learning, BI dashboards, testing and development, data sharing, and any situation where data needs to be efficiently accessed for insights, without exposing the real sensitive information.
In today’s world of complex data regulations (GDPR, HIPAA, CCPA, etc.), data masking is essential for achieving compliance without crippling data utility. It’s the key to maximizing both data’s value and privacy.
In short, while tokenization has its niche, data masking offers a more flexible, scalable, and often more practical approach to data security in the real world.
Implementing tokenization and data masking for modern cloud environments
The widespread use of sensitive data, and restrictions dictating how and why it can be accessed, may necessitate advanced data security techniques like tokenization and data masking. However, depending on your use cases, the sensitivity of your data, and your available resources, data masking may win out over tokenization.
Platforms like Immuta tackle the spectrum of data protection needs by enforcing controls dynamically at runtime, based on the querying user. While traditional approaches often rely on tokenization of data at the point of ingestion, Immuta’s approach offers several advantages and a consistent risk profile compared to tokenization:
- Flexibility in policy implementation. Unlike binary access control systems such as tokenization, Immuta’s more nuanced masking policies allow data to be masked using various techniques that balance utility and security. This means users can still derive some level of utility from the data while ensuring its protection, which is not possible with a simple tokenization approach that either reveals or hides tokenized data.
- Ease of policy management. Since tokenization must occur on-ingest, changing a policy often requires re-ingesting all the data to update the policy. With dynamic enforcement, policy changes – such as a request and approval to see data unmasked – can be implemented quickly and seamlessly, making it a more efficient approach in environments where policies are subject to frequent updates. For example, with tokenization an authorized user needs data to be de-tokenized/decrypted before they can see it, but after they queried it; whereas with dynamic masking the policy can simply be altered, allowing the data to be queried like any other column with SQL.
- Avoids performance pitfalls associated with tokenization. Tokenization can render data nearly useless for meaningful queries due to performance overhead. Because the data is tokenized in the database, operations including “like,” mathematical operations, or joins require decrypting all the data in the column before executing the operation for excepted users. Dynamic access control allows for normal query operations as long as the user is an exception to the masking policy, ensuring optimal performance.
From a security standpoint, masking has the same risk profile as tokenization with regard to credential theft. With tokenization,
- If an admin user’s credentials are stolen, the attacker gains access to the encryption key used to de-tokenize the data.
The same risk profile is present with masking:
- If an admin user’s credentials are stolen, the attacker’s ability to access the data can be compromised by altering the runtime policies in place.
In conclusion, while both tokenization and masking approaches aim to protect data, Immuta’s dynamic enforcement offers several advantages in terms of policy flexibility, preservation of analytical value of your data, ease of management, performance, and equal security. By providing a more nuanced and efficient way to protect data while maintaining its utility and query performance, Immuta allows leading organizations to put more data to work – quickly and safely.
Learn more.
Start protecting your data with Immuta's advanced governance techniques.



