
In the world of data management, not all sensitive data fits neatly into predefined categories. Many organizations deal with unique data types and formats that standard data discovery frameworks fail to recognize. As data protection regulations become more stringent, the ability to identify and manage sensitive data accurately is crucial.
However, the one-size-fits-all approach of built-in identifiers often falls short, necessitating a more customized solution. This is where Immuta’s advanced customization capabilities come into play, allowing you to define your own patterns to effectively discover and manage your unique data. Customizing sensitive data discovery helps you handle your specific data challenges, enhancing both compliance and operational efficiency.
The limitations of built-in identifiers
Built-in identifiers in data discovery tools are designed to recognize common types of sensitive data, like social security numbers, credit card information, and email addresses. While effective for standard data types, these identifiers often lack the flexibility to handle unique data or non-standard data formats specific to an organization. For example, healthcare and life sciences organizations may use specific formats for patient IDs that are not covered by default identifiers. Similarly, financial services institutions might have proprietary transaction codes, and other companies might store addresses or phone numbers in unconventional formats.
These limitations highlight the need for a customizable approach to ensure all relevant data is accurately identified and managed. Relying solely on built-in identifiers can lead to significant blind spots in your organization’s data security strategy. A more tailored approach, such as the one Immuta offers, allows you to create specific patterns and rules that reflect your unique data landscape, thereby enhancing both security and compliance.
Immuta’s approach to customization
Recognizing the diverse and unique data ecosystems that different organizations manage, Immuta supports a flexible and customizable approach to sensitive data discovery. With Immuta, you’re able to define custom patterns for identifying sensitive data, which is particularly useful for unique data formats that do not conform to standard identifiers. Users can create regex or other pattern-matching criteria to capture data types specific to their organizational context. For example, I could create a PatientID identifier with the following regex pattern: PAT-\d{7}. PAT- matches the literal string “PAT-“, \d matches any digit (equivalent to [0-9]), {7} specifies that exactly 7 digits are required.
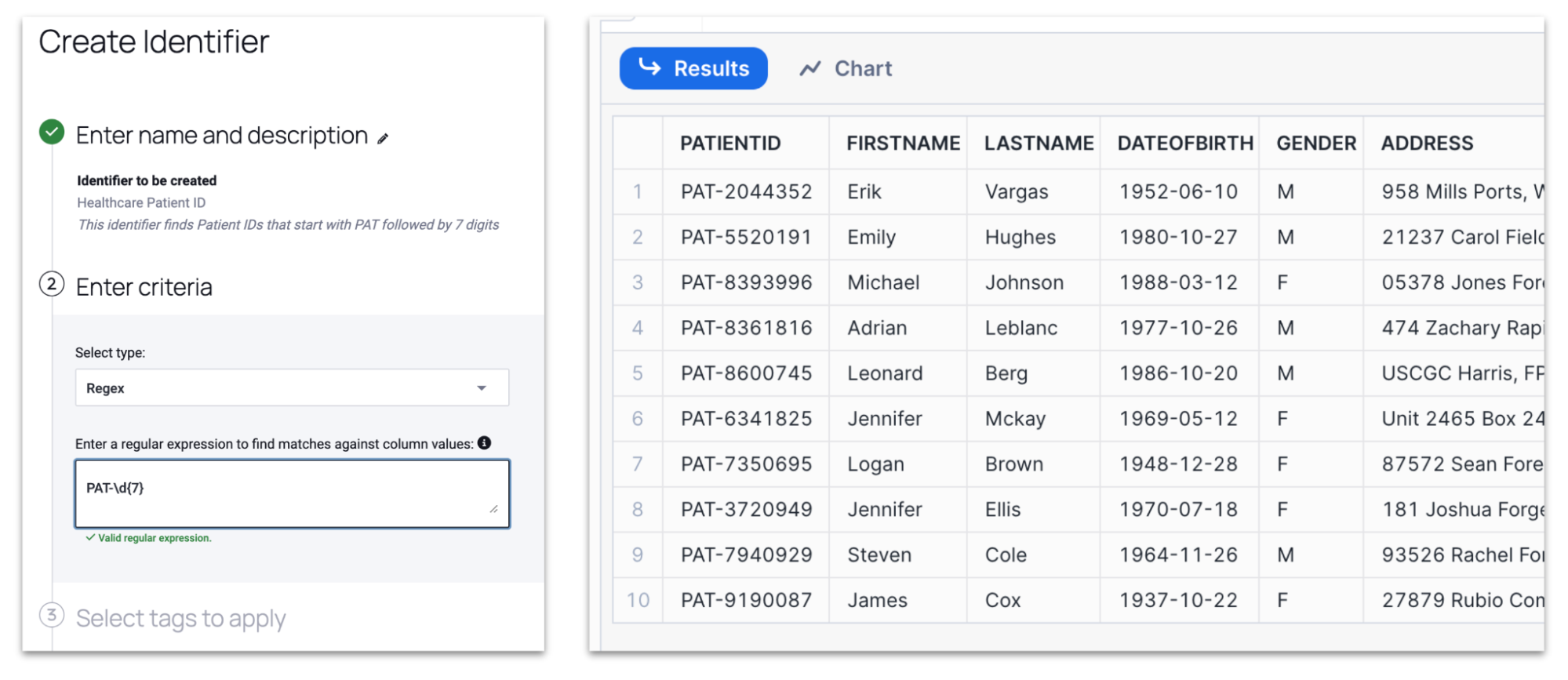
Immuta also enables you to apply dynamic tags to data based on custom rules and conditions. This allows for real-time tagging as data is ingested or processed, ensuring that sensitive data is promptly identified and secured. Tags are used to enforce data access controls and automate compliance reporting, creating a streamlined process that is secure by design.
For example, an organization might tag all email addresses within certain data sets as “PII” and enforce stricter access controls on those data points.

Use Cases for Custom Sensitive Data Discovery
Use Case: Custom Patient Identifiers and PHI Detection
In the healthcare sector, managing patient information securely is paramount due to strict regulations like HIPAA. Standard data discovery tools may recognize common PHI, such as names and social security numbers, but they often fail to capture custom patient identifiers and specialized medical codes unique to individual healthcare providers.
For example, a large hospital network uses a proprietary patient ID format that includes a combination of alphanumeric characters and special codes that represent different medical departments. Additionally, they store sensitive data, like lab results and imaging data, in formats not covered by built-in identifiers.
Solution: Using Immuta’s customization capabilities, the hospital network defines custom patterns to recognize their specific patient ID formats and medical codes. They also create tailored data classifications for various types of PHI, ensuring that all sensitive information is comprehensively identified and protected. Dynamic data tagging is also employed to label sensitive medical data in real time, enabling precise access controls and facilitating compliance with HIPAA.
Use Case: Proprietary Transaction Codes
Take, for example, a multinational bank that uses a set of proprietary transaction codes to monitor and analyze financial transactions across different regions. These codes are essential for detecting fraudulent activities and ensuring regulatory compliance, but are not recognized by default data discovery tools. This gap poses significant risks, as unrecognized transaction codes may lead to missed fraud indicators and compliance violations.
Solution: With Immuta’s advanced customization capabilities, the bank creates custom patterns specifically designed to accurately identify its proprietary transaction codes. This tailored approach ensures that all transaction codes are detected and monitored in real time. By applying dynamic data tagging, the bank is able to label these transaction codes immediately as they are processed, facilitating stringent policy-based access controls. These measures enhance the bank’s ability to detect fraudulent activities promptly and maintain robust compliance with international financial regulations.
Use Case: Non-Standard Address Formats
Consider an e-commerce company that stores customer addresses in various non-standard formats due to the diverse ways in which data is entered by users and collected from different sources. Standard data discovery tools may fail to recognize these unique formats, complicating data classification and protection. This inconsistency may lead to gaps in data governance and potential regulatory breaches. Non-standard formats, such as unconventional ways of splitting street names and numbers, may also pose significant challenges.
Solution: Immuta makes it easy to establish flexible data classifications that cover the company’s diverse address formats. By defining custom rules and patterns, the company ensures that all address data, regardless of how it is formatted, is accurately identified and classified. Immuta’s capability to discover and tag data effectively accounts for these variations. Alternatively, the company can use regular expressions (regex) to look for standard column names such as “Street_Name” or “Address_Line_1” to identify address data. That way, even if the contents of the addresses are formatted strangely, the columns would still be identified.
Conclusion
Customizing sensitive data discovery is no longer a luxury, but a necessity for organizations handling diverse and unique data types. Immuta’s advanced customization capabilities provide the flexibility and precision needed to ensure comprehensive data protection and compliance. By leveraging Immuta’s sensitive data discovery features, you’ll be able to confidently navigate the complexities of your unique data landscape.
To explore more about data discovery and classification, check out Data Classification 101.
See for yourself
Find out more about customizing sensitive data discovery for your organization.



