
We recently conducted an intriguing webinar exploring the data mesh concept, and how it’s transforming the way enterprises decentralize data to enable cross-functional, self-service products tailored to users’ needs.
Though appealing for most organizations, executing a data mesh poses real complexities.
At phData, we’ve implemented several successful data mesh platforms for our customers, and we’re eager to share our experience as your team evaluates next steps on its data mesh journey.
Our methodologies and delivery experience will provide the missing guidance to put your vision into practice. In this blog, we’ll share considerations for traversing common adoption phases, from securing buy-in to demonstrating quick wins in foundational domains, and take a deeper look into industrializing scalable data mesh architecture.
With this blog, you’ll take a big step toward realizing the potential of data mesh.
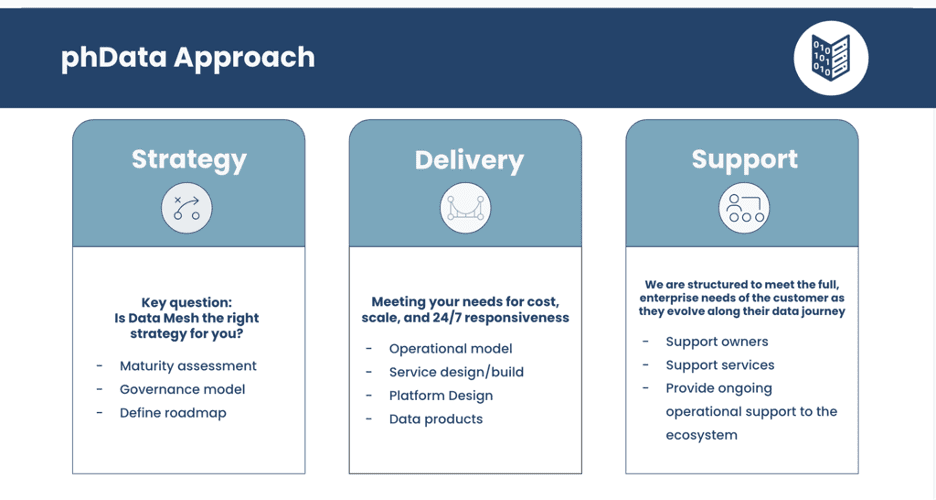
What is phData’s Approach to Data Mesh?
Data mesh is an emerging architectural approach for organizing data and data infrastructure that aims to democratize data access and availability. As organizations adopt data mesh, they face various challenges that must be addressed through thoughtful strategy and execution.
At phData, we find that the most successful data mesh implementations occur in phases, starting with developing a data strategy and a data mesh foundation, followed by building proof-of-concept and minimum viable products (MVPs) that deliver business value. Through an iterative approach of launching MVPs and enhancing capabilities, data mesh can enable scalable and reliable data infrastructure.
The subsequent sections will explore those three phases in greater detail, while providing actionable frameworks and lessons learned for embarking on a successful data mesh journey.
Phase 1: Data Mesh Strategy
Realizing data mesh’s decentralized potential requires aligning technical modernization with enterprise readiness across people, processes, and existing infrastructure. The first initiative is to host a strategic engagement with stakeholders that assesses the landscape maturity to steer appropriate adoption paths.
Evaluate both social and technical dimensions to determine the level of transformation suited to reach current goals and support future scale. No matter the implementation size, ensuring fundamental shifts in platform architecture, domain skills development, and paradigm pioneering lays crucial foundations.
These insights inform a customized sequencing plan—gradually assimilating modern data mesh principles rather than disruptively overhauling ecosystems overnight.
The roadmap should focus on catering to immediate analytics and governance needs while equipping domains with interoperable self-service access, in order to help prove the value quickly.
| Timeline |
Phase |
Deliverable |
| Week 1-4 |
Discovery |
Executive Vision/Goals, Use Cases, Current State Architecture |
| Week 4-7 |
Discovery/Development |
Wrap up discovery, Deep dive into the current system, Processes and standards, Org Model |
| Week 7-10 |
Development/Collaboration |
Future State Architecture, Data Platform Reference Architecture, Use Case Prioritization, Business ROI, Data Governance, Define Domain Boundaries, Data Platform Strategy |
| Week 11-12 |
Wrap-Up/Final Prep |
Wrap up future state architecture, Final touches on all supporting documentation, Next Steps/Roadmap |
| Week 12 |
Final Readout |
Proposal, Executive Presentation |
Sample multi-week strategic engagement timeline. Note: This timeline can be shortened with increased stakeholder availability and leadership commitment.
The Journey of Transitioning to a Data Mesh
Rome wasn’t built in a day, nor is an effective data mesh. Resist any temptations to flip a switch and immediately re-architect existing data and analytics environments. A prudent approach embraces the multi-step nature of implementing a data mesh across your enterprise – accepting this will be an iterative journey spanning months or even years, depending on scale.
Securing stakeholder alignment on this reality before kicking off any formal efforts prevents setbacks down the road, when the finish line seems farther than anticipated. Motivate people for the long haul while setting realistic milestones that demonstrate incremental value.
Start by establishing a cross-functional working group helmed by a dedicated leader, and bring voices from IT, data/analytics, security, and priority business domains into the planning processes early.
Developing an implementation roadmap should be the initial focus of this group, with these key considerations in mind:
Establishing Domain Boundaries and Interconnections
A hallmark of the data mesh paradigm is dividing data products into independently managed domains around business capabilities, products, departments, or other groupings aligned to how organizations operate. This distributed ownership and life cycle management helps focus domain teams on rapidly serving the specific data needs inside their spheres, rather than a centralized data group trying to support general requirements enterprise-wide.
Domain boundaries balance uniqueness and cohesion. Fully autonomous teams aligned on promoting seamless data sharing for cross-domain application is the goal. Take time upfront to carefully evaluate domain options and get buy-in from priority stakeholders on the proposed structure.No single perfect model exists as practical considerations to inform domain design. We recommend a mix of:
- Business Capabilities – Customer, Sales, Marketing, Operations
- Products/Services – Mortgages, Credit Cards, Investments
- Departments/Units – HR, Finance, Regional Operations
- Technology – IoT Platform, ERP System
- LOB – Personnel Auto Line, Workers Comp
Avoid domains becoming arbitrary warehouses of disassociated data. Structure boundaries with an eye towards supporting defined products or use cases. Cross-functional participation balances perspectives and needs, preventing domain builds that simply reflect how your org happens to be structured today.
The future-state mesh must bring high-value data products to bear on priority business challenges in order to serve dynamic enterprise objectives.
Interconnection is equally critical, enabling domain data products to be leveraged across teams. This relies on consistent, descriptive metadata, so data consumers understand available offerings and follow standards. This facilitates a smooth technical integration, regardless of underlying infrastructure.
Architectural Models and Considerations
Various architectural models can support data mesh implementation, but overall favor central orchestration layers that enable autonomy at the domain level:
- Logically Centralized, Physically Distributed – Single pipeline tools and platforms drive downstream delivery into domains that fully manage their own data on regionally distributed systems. This adds global coordination without bottlenecks.
- Common Storage Layer Maintains Domain Separation – Multi-tenant storage behind the scenes isn’t visible, but removes duplication costs. Domain data products are still clearly defined.
- Open Standards Enable Interoperability – Using SQL, open APIs, and formats removes friction and vendor lock-in between components behind the scenes across teams.
The optimal choice depends on the current state and constraints of existing infrastructure, along with organizational attitudes. Still, it balances cost, control, and flexibility in all cases. Capabilities evolve; don’t over-invest upfront before validating proposed models.
Modernizing Security, Privacy, and Governance
Transitioning to a decentralized, self-service model puts responsibility for data quality, protection, and monitoring in the hands of many stakeholders. Without modern solutions weaving reliable data security deep into the infrastructure itself (rather than relying on traditional downstream point enforcement), data mesh sprawl could undermine compliance and trust.
Capabilities like encryption, tokenization, and dynamic data masking enhance control over sensitive data throughout the pipeline, while leaning on robust access policies to prevent internal abuse or misuse of threat vectors from expanding under data mesh models.
Whether worries revolve around external cyber criminals or insider threats stemming from scaling access, building on reactive point tools increases risks.
Technologies like the Immuta data security platform turn this protection model upside down through intrinsic capabilities woven into the fabric of your cloud data environment.
Immuta’s Capabilities for Data Mesh Security
- Fine-Grained Access Controls – Attribute- and context-based controls are invisible to users, driving security and privacy behind the scenes, even during uncontrolled ELT.
- Just-In-Time Data Provisioning – No standing access to data at rest. Access permissions are considered when queries are made to minimize attack surfaces proactively.
- Automated Usage Monitoring – Watch data consumption to flag suspicious activity and enforce the least privilege at runtime, based on actual user access behavior, preventing credential-based attacks.
Streamlining and automating data access control so that users are not constantly waiting for data analytics helps organizations implement a zero trust strategy effectively.
Driving Adoption and Behavior Change
Implementing a data mesh allows for breaking down old bottlenecks to democratized access. But technology infrastructure alone falls flat without deliberate organizational change management, which ensures humans can fully utilize the possibilities at their fingertips.
Kick off communication campaigns early in the process, clearly explaining “what’s in it for me” to data producers and consumers alike while keeping the following in mind:
- Incent producers to publish quality data products meeting well-documented specifications. This helps avoid a glut of undifferentiated offerings from flooding mesh catalogs without consumers coalescing around clear favorites.
- Actively train and support consumers accessing new products, so ease of discovery and understanding matches the ease of access. Aside from passive metadata and documentation, this means providing technical assistance in understanding unfamiliar data.
Plan for hesitancy in letting go of traditional, centralized control and security models. Seeing cross-functional use cases yields wins and helps adoption spread virally. Consider pitches showing specific bottom line or productivity gains in messages tailored to leadership and staff-level personas. Be sure to celebrate data sharing and consumption milestones publicly.
Change is Hard – Take an Incremental Approach with Quick Wins
Even with the best strategy and organizational readiness, executing a rapid rip-and-replace style switchover to data mesh risks major disruption. Balance the scope of initial efforts with patience for incremental buy-in and growth.
Consider an 80/20 philosophy, where 80 percent of the value will be delivered only after fundamentals are proven at a smaller scope. Jumping straight to elaborate end-state infrastructure prematurely overcomplicates and creates stakeholder fatigue.Start simpler with a pilot prototype focused on:
- Sandboxing in a single domain around an urgent use case to realize essential OKRs.
- Testing novel data pipeline, storage, and analytics technologies on low-risk data first.
- Hammering out data lifecycle management, security, monitoring, and consumption processes in a vacuum.
- Proving value and ironing out quirks before adding complexity.
Building real solutions that generate ROI gives confidence for more ambitious use cases, allowing organic expansion in capabilities. Additionally, delivering to real internal consumers generates interest and excitement, rather than trying to push an abstract vision that loses steam over months.
Once governance, access controls, and design patterns stabilize, it is time to incrementally add new domains, data types, and expanded visibility. Built properly, initial investments serve as a robust foundation to plug into – keeping incremental costs down and preventing ripping out and replacing wrongly selected platforms or tools.
Phase 2: Timeline
Rather than an open-ended process, create a high-level timeline with defined phases for building out foundational components and then iteratively expanding over time. A measured course-correcting approach beats trying to architect end-state solutions upfront before real-world validation.
Typical stages include:
- Foundation – Future state architecture in action, federated governance, training, and implementation tools that enable self-serve data platforms.
- Value Proof – Focus on a single domain, developing policies, technologies, and processes in a sandbox environment (3-6 months).
- Expand Access and Security – With a working prototype, scale horizontally to open up data access and enforce rigorous data governance—all while fortifying controls and trust.
- Increase Domains – Add incremental domains across more business units and data types, enabling wider sharing and self-service use cases.
- Operationalize and Optimize – Solidify the mesh into core enterprise data infrastructure, continuously improving domain interconnections, security integrations, and adoption.
Foundation (3-6 months)
The data mesh journey begins by bringing together a cross-functional working group involving key data, architecture, security, and priority business domain leaders. This sets in motion foundational building blocks spanning people, processes, and platforms.
Outcomes include aligning on domain boundaries and nurturing a distributed data ownership culture across business units by formally empowering teams already managing relevant data assets.
Investing in a robust self-service data platform and tools that ease discovery, access, and governance across domains sets the stage for flexibility at scale.
Proof of Value (3-6 months)
To show that the identified domain-specific use case works, we focus on a specific example and test its worth while improving our methods. First, we work with everyone involved to set clear goals and success metrics.
Next, we create a simple version of the project for a few users with typical data. This is done in a test area, so it doesn’t affect other work. We then ask for feedback from both technical and business stakeholders.
Based on what we learn, we optimize our design, security, and rules before sharing it more broadly. If this trial version doesn’t work, it stops problems from affecting the whole business. If it works, it proves we should use it more widely.
Minimum Viable Products (3-4 months)
Expanding on proven concepts, prioritize additional high-value data products for minimum viable product (MVP) development. Working with domain owners, build out or invest in tools that support catalog assets, making data discoverable and self-serviceable through searching comprehensive metadata.
Scale underlying data mesh to production-grade security, governance, and reliability standards, suitable for formal stakeholder consumption. Maintain continuous integration and monitoring procedures as iteration accelerates, keeping pace with data consumers’ feature requests and ever-evolving use cases.
Scale Catalog and Platform (Ongoing)
As the data mesh scales across domains, focus on advancing platform capabilities and ecosystem maturity. Onboard new teams while cultivating grassroots data literacy initiatives to expand skills. Enable discoverability and reuse by connecting distributed data assets through consistent schemas and governance.
Specifically, prioritize features like comprehensive catalogs for easy data product discovery, data lineage for traceability, smart search, and recommendations for finding relevant assets. Integrate data quality monitoring aligned to global standards so users trust discovered data.
Consider leveraging ML to auto-tag metadata and scale curation bandwidth without compromising richness. Continuously refine performance, versatility, and architecture patterns to smoothly ingest from new upstream sources and serve evolving consumer needs over time.
Phase 3: Ongoing Nurturing (Support)
Smoothly operating data mesh environments relies on automation, community, and purposeful iteration as catalysts to prevent entropy. Workflows spanning security, testing, documentation, and monitoring enable reliable innovation velocity from domains, freed of maintenance burdens.
Regular stakeholder reviews ensure activities and access controls continually realign with enterprise objectives as new realities unfold. Be sure to avoid the set-and-forget dangers of legacy platforms over time.
Plotting an initial one- to two-year plan allows flexibility to adjust while moving the ball forward – preventing data mesh from forever lingering as a hoped-for aspirational vision that fails to materialize in practice.

What are the Key Organizational Challenges with a Data Mesh?
Transitioning to a data mesh architecture represents a major shift for most organizations built on centralized data management. While the decentralized approach enables faster innovation and scalability, the distributed nature of data mesh creates new challenges around culture, governance, and architecture.
With eyes wide open to the challenges ahead, and when executed deliberately through the transformation journey, data mesh can usher in the next-generation paradigm for reliable and innovative data management.
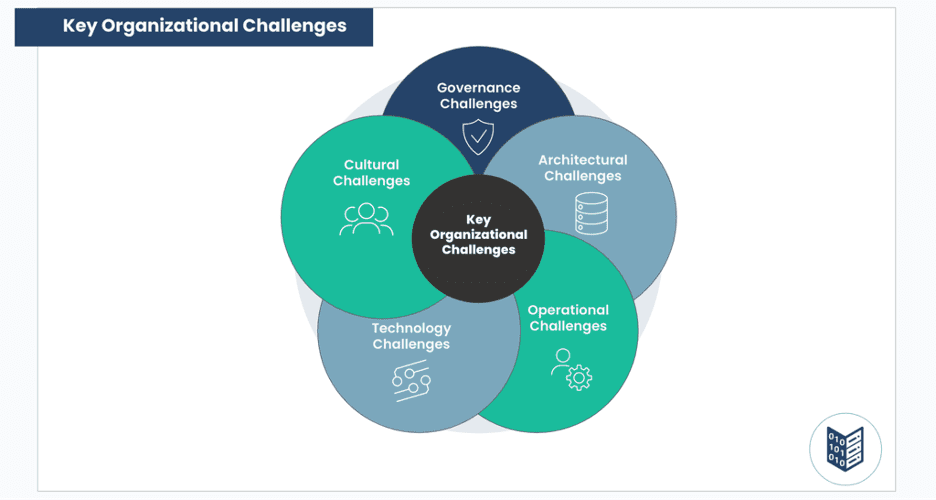
Cultural Challenges
1. Moving from centralized to decentralized data management
This phase requires a shift in mindset and culture. phData can assist by providing training and support for teams adjusting to decentralized data management. The platform’s capabilities in automated usage monitoring contribute to a culture of responsible and secure data handling.
2. Ensuring buy-in and sponsorship across business domains
Promoting technology solutions that enforce secure cross-domain data sharing can gain buy-in from different business domains. Immuta’s fine-grained access controls contribute to building trust across the organization.
3. Promoting company-wide data literacy and mesh understanding
The platform’s role in providing visibility into data consumption and enforcing least privilege at runtime aligns to promote data literacy. Communication campaigns can highlight the platform’s capabilities, making it an integral part of company-wide data understanding.
Governance Challenges
1. Maintaining standards and trust while distributing ownership
Data platform support for maintaining fine-grained access controls ensures that standards are upheld even as ownership is distributed. Policies and processes for secure cross-domain data sharing can be implemented through Immuta’s capabilities, providing a governance framework for a decentralized data landscape.
2. Implementing policies and processes for secure cross-domain data sharing
Immuta’s automated data monitoring contributes to ensuring policies and processes for secure, cross-domain data sharing are sufficient and work as intended. The platform’s capabilities align with the need to maintain trust while enabling seamless data sharing across domains.
Architectural Challenges
1. Integrating existing monolithic systems and legacy workflows
The right data platform and tool choices can play an important role in the integration process by providing a centralized orchestration layer. Support for open standards enables interoperability, making it easier to integrate with existing monolithic systems and legacy workflows.
2. Preventing fragmentation and enabling interoperability
A data platform focusing on maintaining domain separation while using a common storage layer aligns with the goal of preventing fragmentation. The platform’s capabilities contribute to enabling interoperability across different domains, ensuring a cohesive data mesh architecture.
3. Scaling infrastructure for performance and reliability
Data platforms’ role in providing a secure and scalable data access layer contributes to scaling infrastructure for performance and reliability. The platform’s just-in-time data provisioning capabilities and automated usage monitoring align with the need for a scalable and reliable data mesh infrastructure.
Putting it All Together: Customer Example
Recently, phData partnered with a Fortune 100 financial services organization looking to adopt a next-generation data architecture for powering analytics innovation across business domains.
We led them through a 4-phase engagement focused on incrementally implementing data mesh in sync with their cloud-first roadmap.
Early strategy sessions aligned executives and IT leadership on domain boundaries for distributed data ownership. We helped stand up initial data products in delimited sandbox environments compliant with the organization’s stringent security protocols.
Seeing the self-service value delivered to marketing in surfacing customer insights faster started to prove the potential. This organic adoption prompted expansion into additional domains around risk, fraud detection, and customer lifetime value predictions, enabling use cases that were simply impractical under legacy centralized systems.
Immuta’s data security platform played a crucial role woven throughout, allowing teams to control access and share data products seamlessly without compromising security or compliance. Purpose-built for the challenges of mesh architectures, it automated enforcement so domain owners could focus on driving innovation and value.
Now 18 months into their data mesh adoption, 57+ domain data products fuel analytics across business functions. What started as a pilot has transformed data culture and time to insight across the enterprise, positioning them as an industry leader. The CDO credits the phased approach focusing on incremental value as the blueprint for their success in embracing modern data paradigms.
This example highlights how blending vision, pragmatic strategy, and the right technology investments allows enterprises to actively shape data mesh into a competitive advantage rather than just a buzzword. If transforming siloed analytics choked by centralized bottlenecks sounds appealing, phData offers specialized advisory services and our proven playbook to help accelerate your data mesh journey today.
Closing
In conclusion, data mesh promises a future where decentralizing control puts need-based, customized data products within reach instantly through self-service access. Implementing this reality demands a strategy blending patience, discipline, vision, and technological innovation.
The recommendations covered in this blog equip teams to balance these drivers with an actionable blueprint tailored to enterprise contexts.
Of course, most enterprises still need specialized internal skills and solutions around emerging data mesh architectures. That’s where leveraging outside expertise can drive quick impacts and focus energy. Purpose-built data platforms remove security roadblocks to agility, while partners like phData offer implementation services smoothing every step of the journey.
Combining the right tools with the right guidance accelerates data mesh adoption on timelines matching corporate priorities. The intelligent future of analytics starts today therefore when you’re ready to take the next steps beyond vision, phData’s trusted advisors will help you navigate what comes next on the data mesh journey.
Data Mesh FAQ
Question 1: How much upfront planning of the technology landscape is needed when getting started with data mesh?
Answer: Some key foundational decisions do need early alignment including:
- Centralized vs decentralized services
- Primary cloud platform(s)
- Data formats & protocols standardization
- 3rd party tooling for governance and security
On the last point regarding tooling, key considerations include:
- Metadata management – Maintains context across domains
- Sensitive data discovery & classification – Critical for consistently tagging and defining sensitivity levels of data assets
- Policy management enforcement – Global data access, security, and privacy policies applied across mesh
- Domain-specific policies – Additional localized policies for specific data products
Vetting and onboarding the right 3rd party governance tooling, like data catalogs, lineage, and policy engines, is recommended even as the first few MVPs focus on solving for specific use cases. The tools provide the instrumentation needed for traceability, security, and building institutional knowledge of data assets as the data mesh scales across the enterprise. Close partnership with centralized data governance teams is key during tool selection.
Solid foundations in governance and security not only accelerate data mesh adoption, but also ensure compliance and safe data sharing across the decentralized data architecture.
Question 2: How can we convince stakeholders who are resistant to change when adopting a data mesh architecture?
Answer: Transforming to a data mesh architecture represents a major shift that can face organizational resistance. Some effective ways to get buy-in include:
- Educate on the benefits of decentralized data ownership and domain-oriented architecture, such as improved autonomy, quicker innovation cycles, and scalability. Compare these to the pitfalls of existing monolithic platforms.
- Involve stakeholders early and foster shared data governance across domains versus top-down policies. Collaborative governance increases adoption.
- Start small with low-risk MVPs that demonstrate value instead of boiling the ocean. Quick wins build confidence in larger initiatives.
- Communicate a compelling “Why” linking data mesh to business outcomes. Financial incentives via chargebacks or talent mobility for domain teams also spur adoption.
- Compromise on some centralized services, like discovery and observability, while domains control their own data and infrastructure. This balance acknowledges real concerns.
With a combination of education, collaboration, tangible benefits delivery, and willingness to compromise, data mesh can achieve stakeholder alignment critical to sustainable transformation.
Question 3: How can we measure the success and ROI of a data mesh implementation?
Answer: Quantifying success metrics and ROI for data mesh is vital for continued executive sponsorship and team adoption. Some effective KPIs to track include:
- Business Value – The most critical metric. Measure how data products influence business KPIs in different domains, whether through revenue, customer retention, production efficiency, etc.
- Time to Data Impact – With decentralized teams owning domains, track velocity from idea to value realization using data. The target is faster innovation cycles.
- Data Asset Reuse – The ability to discover and leverage data across domains indicates maturity of data sharing and governance practices. Increasing reuse signals efficiency gains in data and infrastructure.
- Platform Ownership Costs – Compare cumulative costs across domains pre- and post-data mesh adoption. Costs should decline over time as teams adopt the self-serve infrastructure.
Essentially, data mesh success means faster use case realization and lower TCO, while increasing data asset leverage across the organization. Business value metrics substantiate the ROI. Maintaining priority dashboards with these KPIs helps drive timely actions, and celebrating milestones towards a thriving mesh increases buy-in and adoption!
Tracking these tangible returns beyond just architectural measures cements executive support through the transformational journey.
Put the Roadmap into Practice
Get in touch to start your data mesh journey.



