Identity governance and administration (IGA) solutions aim to manage access request processing and workflow orchestration, as well as identity access certification. Said more plainly: IGA holds the logic that is the glue between your users and their access to your business resources.
IGA solutions have existed for quite some time. And as with any solution, as we progress forward in time and use cases change, prior solutions tend to veer into square-peg-round-hole outcomes for those new use cases. In this blog, we’ll describe some of these new challenges and how we need to rethink the ways in which we leverage IGA to address them.
Challenges for IGA in modern use cases
Explosion of raw data consumption
As far back as we can collectively remember, we’ve all believed the business that best leverages its data will win. But, strategies for how best to do this have taken several turns. Most recently, we’ve seen this play out in adaptations to the data mesh strategy, which hinges on the creation of meaningful data products meant to solve critical business challenges.
There are three critical philosophical shifts associated with data products:
- They are delivered by the lines of business rather than central IT because the business knows its data and value drivers best.
- They are managed similar to a software product or feature (i.e. they involve discovery, planning, versioning, standards/SLOs, and ownership).
- They break down historical “software application barriers,” allowing more direct access to data.
That third philosophical shift is critical: Prior to data products, insights were gained through pre-created BI dashboards or custom-built applications that were managed by human “go-betweens” working with centralized data. But with data products, direct access to data and insights for business users becomes more prevalent.
Direct data access also means that security and access control measures must account for more data consumers. Organizations can no longer rely on native SaaS application security, nor security-by-lack-of-login to the database. And those access controls need to be managed in a federated manner, since data product delivery is decentralized across the business.
GenAI has further exacerbated the raw data consumption explosion by allowing any user – regardless of technical expertise – to query data products (or even raw data) directly, without the need to understand how to write SQL.
Explosion of access permutations
What is a permutation of access? Consider this diagram:
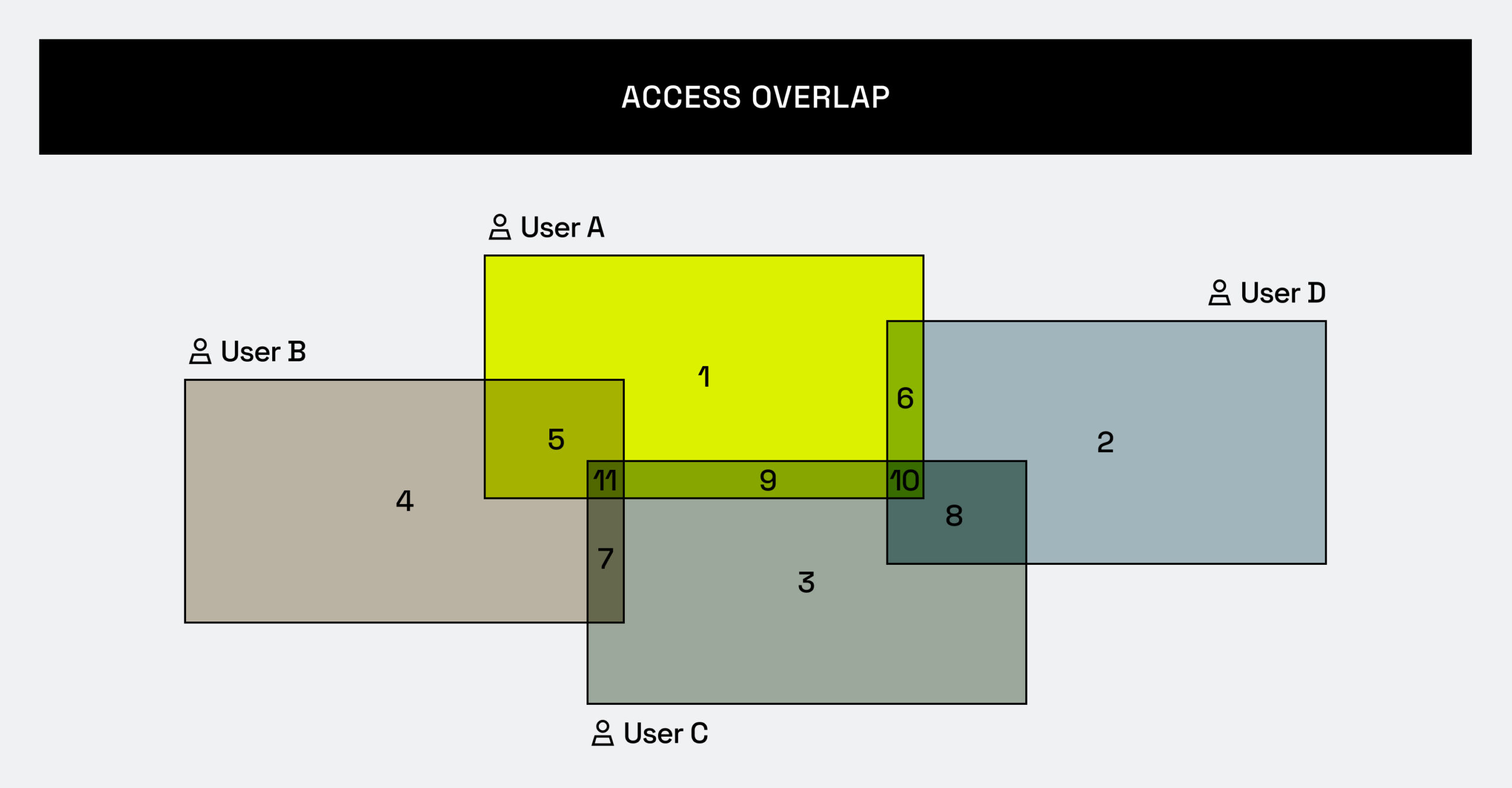
Each square represents a user, and each number represents a permutation of access. For example, if you look at permutation 10, users A, C, and D all have access to it. There might be a single table under permutation 10, or twenty tables under permutation 10 – that detail really doesn’t matter. The point is that there is a permutation of access for the tables with shared access between users A, C, and D.
In the example above, we see that four users can necessitate 11 permutations of access (although it could be more). To illustrate the permutation explosion, consider Immuta’s customers, one of which recently crested 100,000 permutations of access. You can see the top five here:
|
Count of Access Permutations via Subscriptions |
|
Customer 1 |
111,989 |
|
Customer 2 |
92,821 |
|
Customer 3 |
82,608 |
|
Customer 4 |
37,816 |
|
Customer 5 |
12,330 |
So, how did this customer get to 111,989 permutations of access? In their case, they have 11,219 users and 10,518 tables/views. What is interesting (but not uncommon) is that they show roughly 10x more permutations than they have tables/views in the system. This happens because data access is quite different from SaaS application access: Data is structured and can be sliced along several different axes, such as sets of tables (as in our case above), sets of columns within those tables (think masking policies), and finally rows and even cells across those tables (think row filtering policies). All of this different slicing creates an explosion of access permutations.
Conversely, access within SaaS applications is primarily permission-based, which means that each permission maps to a pre-computed permutation of access and/or job duty. Could you imagine a SaaS application with 112,000 permissions!?
But that’s the point – IGA was built for applications, not data. When you consider the rise of data products and GenAI, which increases the volume of raw data consumers and in turn increases permutations of access, classic IGA quickly breaks down.
Understanding how classic IGA works – and breaks
How IGA works
IGA does not directly manage access to objects in systems. Instead, it uses an abstraction between the identities and the objects they are permissioned to, and that abstraction is a role.
Remember our access permutations discussion above? That is a role – an abstraction that represents a set of users and the access they have in common.
A user with privileges in the system that contains the objects to which access must be permissioned, creates these roles and manages their privileges to those individual objects. Then, an IGA administrator registers those roles so that the IGA independently manages which users can actually be provisioned to those roles. This allows the IGA to control access request processing and workflow orchestration, as well as access certification of identities to the roles – all without having to understand the inner workings of the systems the roles permission into (that part is on you, the manager of the system with the objects).
Access to SaaS applications typically has a small, preset amount of access permutations that you must manage through roles that are exposed to the IGA for user provisioning. The key word is small. The complexity associated with managing the roles is directly related to the amount of access permutations that are needed; there are not many with SaaS applications, so it’s feasible.
Why IGA breaks
But the shift towards data products, GenAI, and raw access to data are now leading to a world of consumer and permutation explosion. Without Immuta, the customer we mentioned earlier would have to create 111,989 roles in their IGA system and grant each role access to the correct sets of tables/views in order to achieve the appropriate granularity of access. And, as new requests arise that create new “slices” of access, new roles need to be created. This slicing happens rapidly, potentially at a rate of hundreds of new permutations per day, not to mention, new data products are constantly being added.
A scenario like this is obviously not feasible to manage with IGA, so IGA/system administrators are forced to “cheat” with the role abstraction. They create broader, coarser roles that represent pre-computed access. Users are then able to request access to those coarse-grained roles. But this means that users are gaining access to much more data than they actually need.
Going back to our example, if we make the access more coarse, all four users now see data at the same level of access (one role) – and each is seeing more than they actually need:
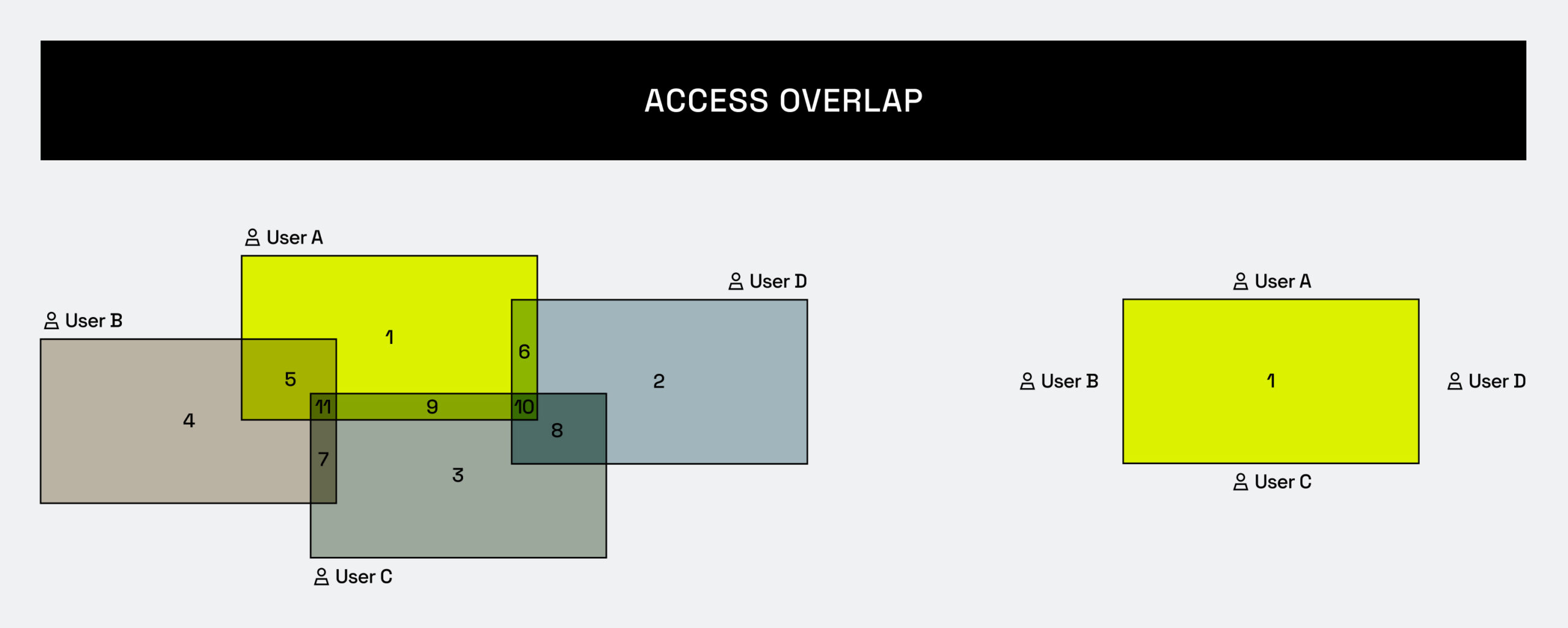
Now, imagine boiling down 111,989 permutations to a simplistic set of 5 roles. When you’re approved for one of those roles, you’ve immediately gone from surgical access control restrictions to essentially wide open access.
These coarse roles also make it nearly impossible to determine “who has access to what and why”, also known as entitlement recertification. How do you know if a given user should still have access to one specific role and not another? They may need access to just one table out of the hundreds or thousands that their assigned role gives them access to, but the nature of this model requires that they maintain this broad and largely unchecked access because of that single table they need. This does not follow the principle of least privilege, nor does it truly enforce any kind of realistic entitlement review.
Lastly, this is extremely challenging for data consumers. They must understand what data or data products map to which roles in order to request the proper role access from the IGA. Extremely coarse roles with access-relevant names (like Confidential or Highly Confidential) are meant to simplify data discovery for the consumers, but they further reveal more data than is actually needed. If you get access to the “Highly Confidential” role, you must get access to everything tagged as Highly Confidential otherwise the role name is misleading.
The Immuta Data Marketplace: IGA for data
It’s no coincidence that Immuta customers with the most access permutations are the same customers that leverage the Immuta Data Marketplace. Immuta handles the complexity of data access control by avoiding the use of a role abstraction to manage it. Instead, Immuta natively integrates with data platforms like AWS, Databricks, and Snowflake, and provisions access directly to consumers rather than indirectly through roles.
With Immuta, data access provisioning can either be done up front via birthright access policies that reference user metadata and data metadata, or through approved data product requests; both directly provision access in the data platform. The overlap between birthright access and approval-based exceptions creates the explosion of permutations, rightfully, but more importantly, invisibly – so you get all the granularity and scale you need, while seamlessly maintaining the right level of control and permissioning.
There are many benefits to this approach:
- Frees the data platform team from having to manage roles or grants at all because Immuta handles it.
- Allows consumers to request and be approved to access data products, not roles, which is a far more intuitive process.
- Grants requestors access to exactly what they need access to – no more, no less.
- Allows limiting how long users can have access using Immuta’s timebound approvals. With classic IGA, you can’t revoke access based on elapsed time because as discussed, the role supports access to many different objects at once.
- Enables meaningful entitlement reviews because they are done at the data level, not role level. As we covered earlier, roles provide access to many different objects at once, so reviewing entitlements is a futile task.
- Adds granularity to access requests by going beyond table/view access and into unmasking requests or row unfiltering requests. With classic IGA, the permutations required to achieve this granularity is completely untenable.
With this, Immuta is able to support 111,989 different permutations of access without data platform teams or data consumers having to think about a single role or grant.
The role of AI in IGA for data
But there’s one last problem we haven’t discussed: the poor access reviewers!
With so many slices of access, how can we reasonably expect a human to make accurate determinations on access requests*? The short answer is, we don’t. This is where Immuta AI enters the picture.
- Immuta Copilot generates access policies through plain-language prompt interaction, which vastly simplifies the birthright policy authoring process without sacrificing accuracy or granularity.
- Access approval/denial trends can drive policy recommendations to auto-approve/deny requests which can also be further automated through AI agents. This includes timebound approvals, which will automatically revoke users’ access after a certain period of time.
- Historical query activity enables automated recertifications or revocations due to lack of activity. Again, this is only possible because the access is controlled granularly at the data level.
Policy recommendations and automated access recertifications will be available soon in the Immuta Platform. In the meantime, see how Immuta Copilot works.
Conclusion
IGA solutions continue to be great for SaaS applications, where the role abstraction aligns well to SaaS application permissions and allows a broad scope of support. But, that abstraction breaks down with data.
Instead, you need a solution that is purpose-built for data IGA, which can handle dynamic permutations of access and the explosion of data consumers: the Immuta Data Marketplace. This does not mean you need two different experiences for your access reviewers either; all of Immuta’s capabilities are available over APIs and webhooks, and can integrate with existing IGA tools to power data access use cases.
*In our example it is not 111,989 access requests that were reviewed, that is just the resulting permutations, which is a combination of birthright and other exception based requests through the Marketplace.
See IGA for data up close.
Go inside the Immuta Data Marketplace.



