
Governance and security are hot topics in data mesh, as evidenced by the recent webinar I co-presented with Andy Mott at Starburst that landed 350+ registrants, including the who’s who of industry luminaries on the topic. It’s easy to see why – without proper planning, decentralization can become the wild west of data management.
The data mesh principles are best documented here by Zhamak Dehghani, director of emerging technologies at Thoughtworks. But there is also a growing body of excellent presentations and articles by practitioners from JP Morgan Chase, Roche, Intuit, Yelp, Netflix, and others, several of which are Immuta customers.
Despite our increasing familiarity with data mesh as a concept, the diversity of stakeholders in the data mesh journey means there is still a bottleneck that is uniquely challenging the equilibrium between centralization and decentralization. The bottleneck is around managing data access control policies in a distributed manner, and is even worse in regulated industries. In this article, we’ll explain why, and how to overcome it.
The Data Mesh Problem: Explosion of Role-Based Data Policies
The central problem for data mesh when relying on traditional, role-based access control is that the decentralized nature of data mesh architectures leads to an explosion of data access policies. What do we mean by a data access policy? Fundamentally, it is a set of governance and privacy controls required to implement a rule to allow data use.
Data Policies in the Mesh
- Decentralized
- Dynamic
- Managed with Attributes

What Happens If We Apply Traditional Role-Based Access Management?
Let’s look at why role-based access control creates a data policy explosion in the data mesh using the example of a finance team accessing sensitive data.
Let’s say Jay in FINANCE should be able to see TRANSACTIONS in his [country of employment] and [business line] for fraud detection purposes.
An engineering resource is required to create a role, FINANCE_US_CREDIT_FRAUD, and write code to segment the table by country and business line, while restricting access to a purpose by tracking it in an ITSM or other ticketing system – all before granting access to this role.
Now imagine expanding this model for each data product without any oversight for role definition. For example, this role may exist in a customer data product that accesses transaction data, but with a different naming convention. However, it’s impossible to recognize this since roles conflate members with what they can access. This results in an explosion of roles that is hard to scale with limited data engineering resources.
The Dynamic Approach: Modern Data Access Control
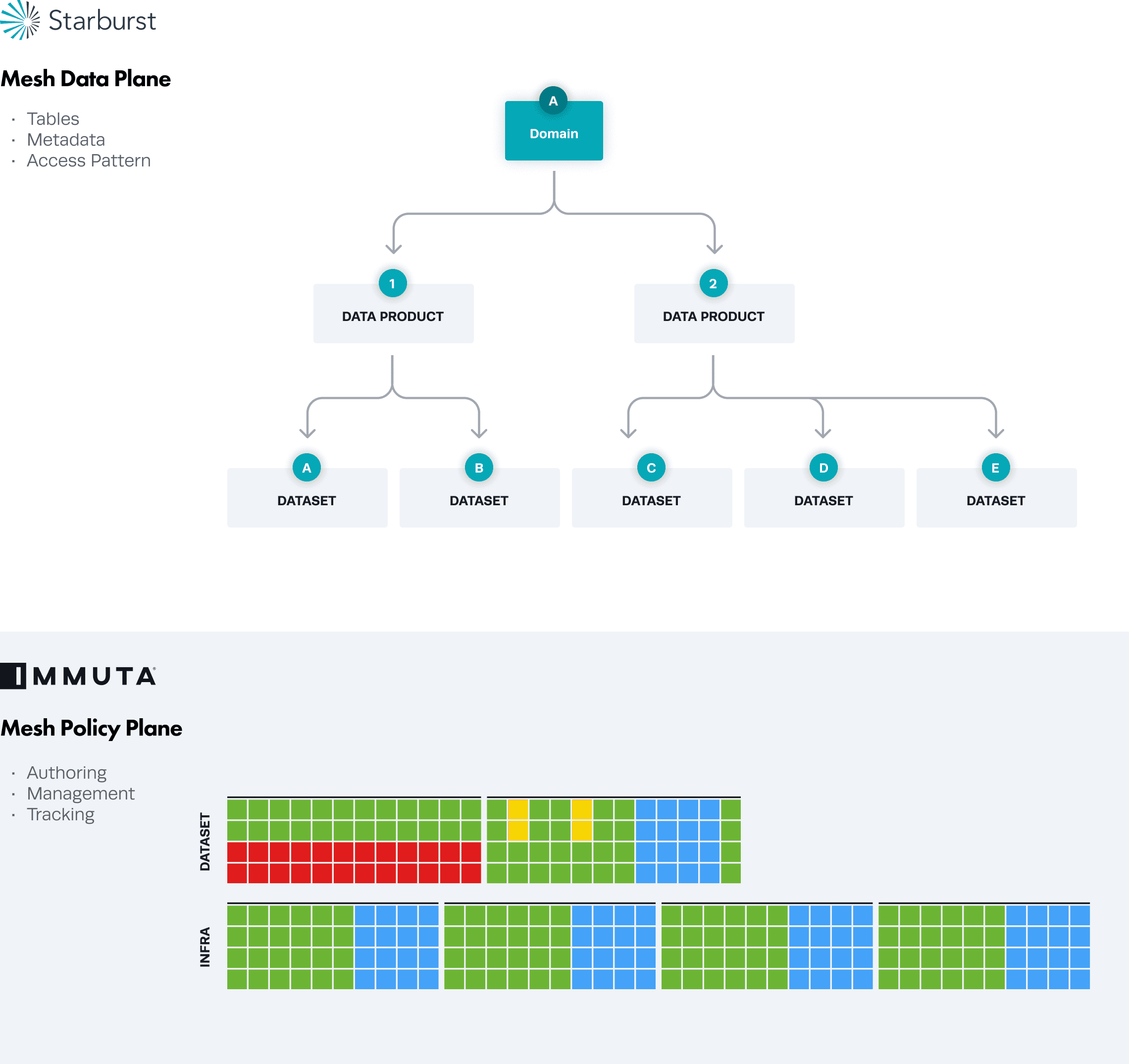
Together, Starburst and Immuta help solve the role explosion dilemma. In the diagram below, we can see that Starburst serves as the mesh data plane, enabling organizations to build data products made up of one or more data sets, logical or materialized, and manage it from a beautiful UI.
However, in a situation like the example above with Jay, in which all the rules around his data use by country, business line, and purpose must be layered in, we need to implement granular policies using a tool like Immuta, which separates user attributes from the policy logic in the data product. This allows consistent and centralized definitions of user attributes, but a decentralized definition of policy based on those user attributes. These policies are indicated by red, for row-level segmentation, or blue, for column-level redaction or data obfuscation. Then yellow represents cell-level protections.
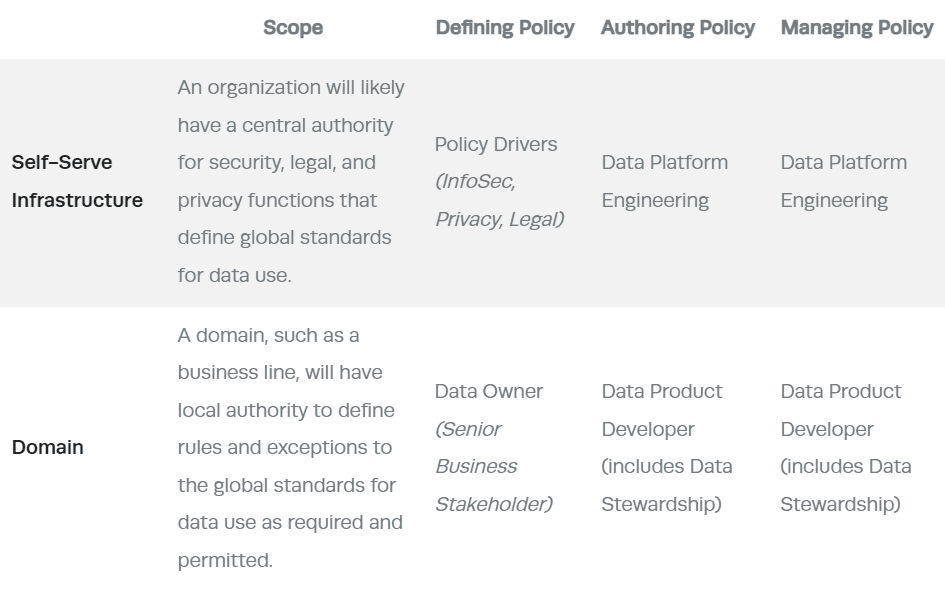
There are three fundamental questions we need to address to control access in a mesh:
-
-
- Who defines the rules?
- Who implements the rules?
- Who maintains the rules?
In a data mesh journey, these questions are usually answered across two levels for data use policy definition and operationalization. A modern data access control model must satisfy all scenarios to enable autonomy for the domain teams. The following table indicates which teams are responsible for different parts of the process in a self-serve infrastructure versus a specific domain.
Data Mesh Policy Plane Requirements
1. Policy Authoring
All stakeholders listed in the chart below must be able to implement and maintain the defined data use policies, either at the mesh or domain level. The data mesh policy plane also requires both visual and “as code” interfaces.
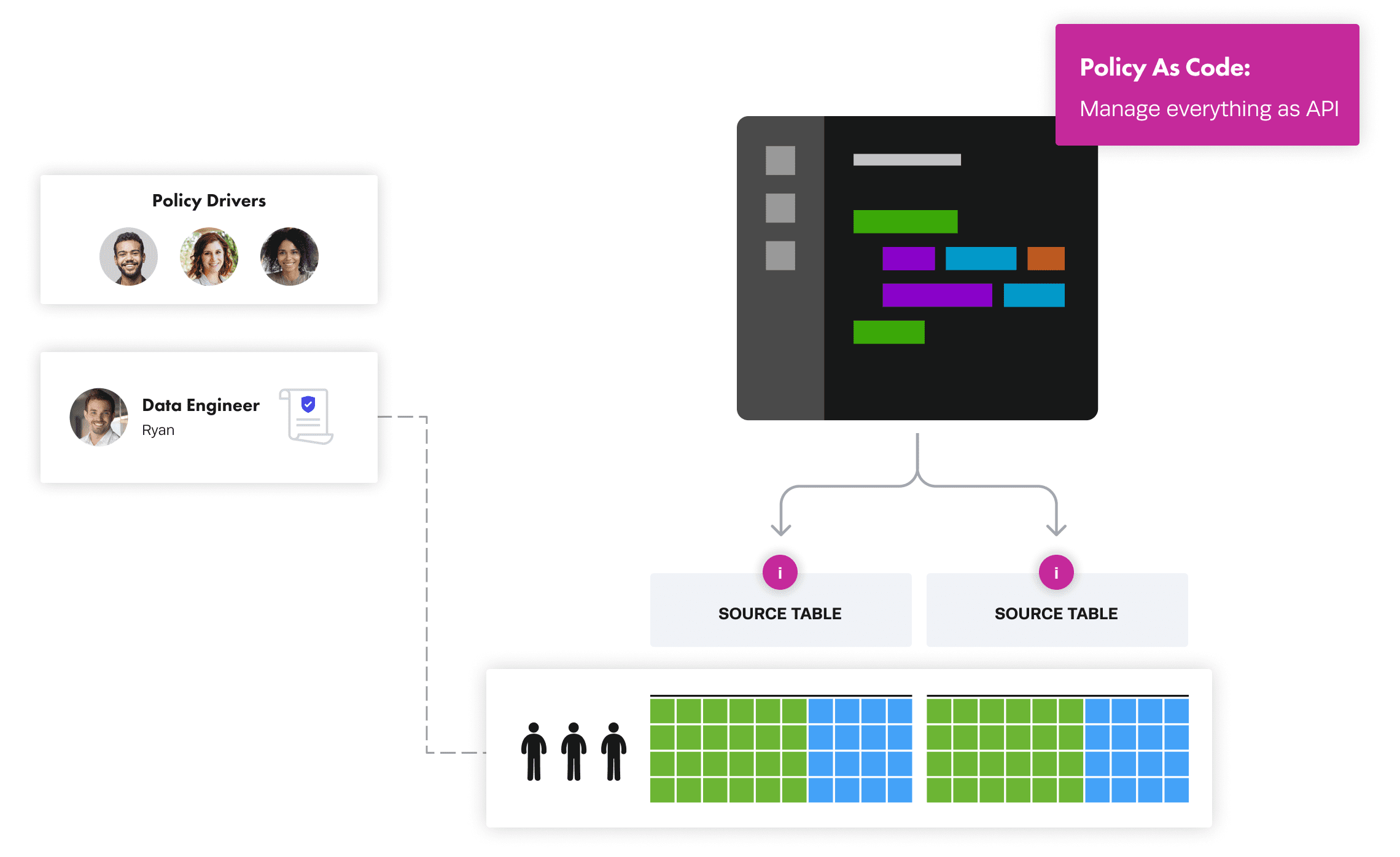
Self-Serve Infrastructure
Let’s take an example to look at policy authoring at the infrastructure layer, where centralization is necessary because common automation will exist to provision the infrastructure across domains:
Jay in FINANCE can see TRANSACTIONS in his [country of employment] and [business line] for fraud detection purposes.
This rule is defined at the domain level, but per the global standard adopted by the federated governance team in this example, domains cannot see PII by default without having prior approvals to make exceptions, such as for fraud detection purposes. Therefore, the data mesh policy plane must implement this across all domains as part of the data infrastructure provisioning so that PII data is auto-discovered and tagged for proper dynamic data masking policies that are agnostic to data or technology.
This can be done in Immuta, which provides sensitive data discovery to auto detect PII with granular and custom classifiers that drive global policies across all data, and that are invoked “as code” by data platform engineers. For the data developer experience, the policies are propagated downstream to data products, removing decision-making from users.
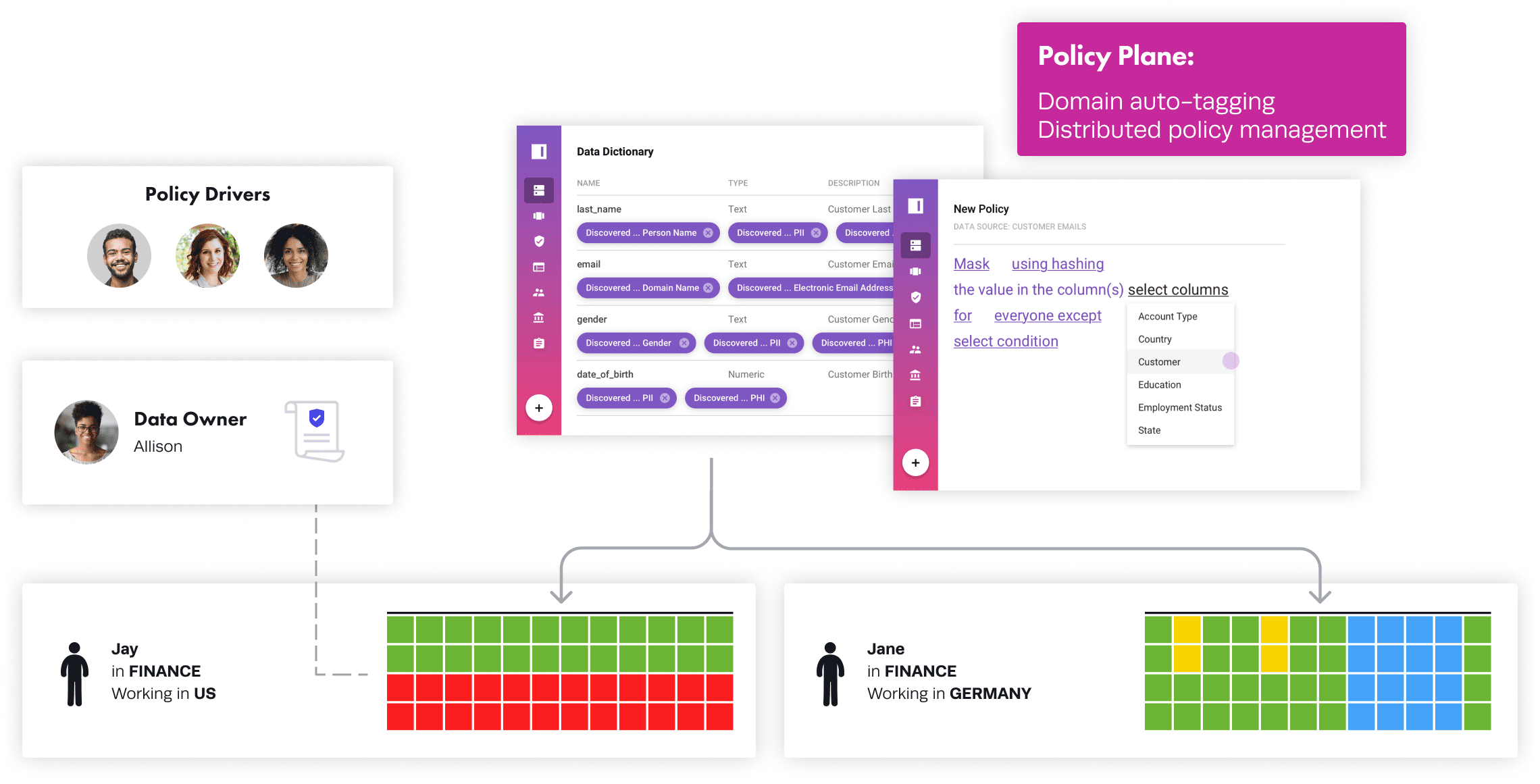
Domain Level
Let’s take the same example for the domain level:
Jay in FINANCE can see TRANSACTIONS in his [country of employment] and [business line] for fraud detection purposes
A data owner has defined this data use rule and a data product developer, or other data stewardship role, needs to implement it. The required skills to do this, including managing roles and SQL GRANTs for security and privacy controls, are not decentralized, which may be the reason for embarking on the data mesh journey in the first place.
Further, the role-based access control model is largely flawed for data mesh since domains run the risk of ending up with more roles than users. Immuta addresses this with plain language policies that are easy to author and understand, and might look something like this:
Only Shows Rows where [@country of employment] = Country and [@business line] = Business Line for everyone except those working for fraud detection purposes.
Note the policies can also be invoked “as code” by the data product developer.
2. Management
Self-Serve Infrastructure
Since the data discovery and data policy enforcement are implemented as the standard using global policies in Immuta, no additional work is required at the infrastructure level.
Domain Level
At this level, it’s important to have policy management interfaces and experiences for any stakeholder in the domain. The Immuta policy example above is easy to manage since it works across all users in the domain and dynamically segments the data at query time based on the users’ context (country = France and business line = Finance). For a deeper dive into attribute-based access control (ABAC), which is a superset of RBAC that treats roles as an attribute with the option to scale management along the data mesh journey, you can find more details about ABAC here.
Note the policy management can also be invoked “as code” by the data product developer.
3. Tracking
With the different levels, it’s critical for organizations and domains to be able to answer simple questions from auditors or investigations, such as, “Who accessed PII or personal data in the last 30 days for purposes of fraud detection?”
Immuta provides centralized auditing and monitoring at the self-serve infrastructure layer that enables supervision across an organization, while still empowering domains to respond to inquiries from policy drivers and data owners alike.
Summary of the Data Mesh Policy Plane
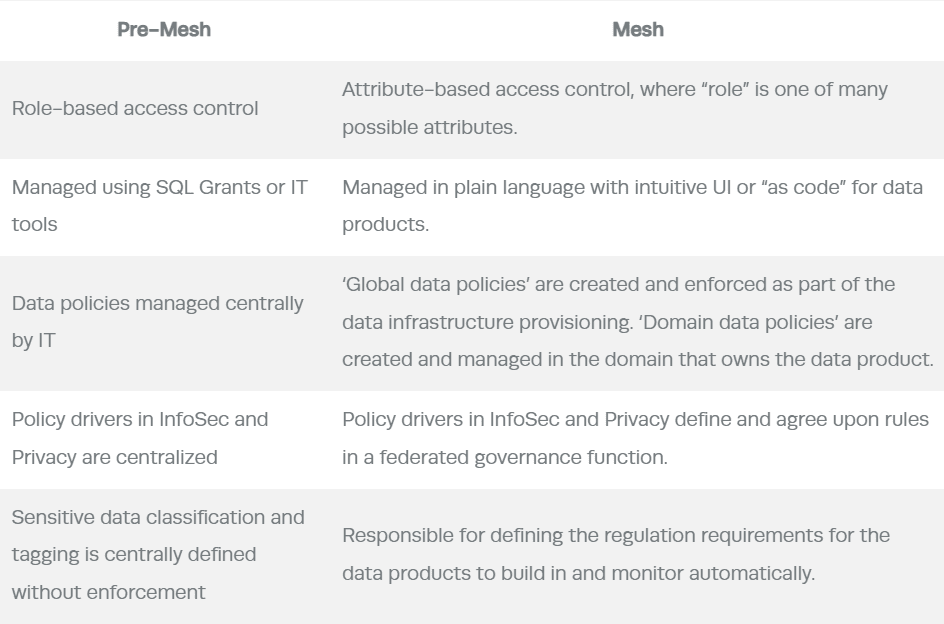
The data policy management burden is a critical bottleneck that is further exacerbated by decentralization. However, organizations such as NIST have defined modern access control models, such as ABAC, which are adopted by cloud-first data access control vendors such as Immuta, as fundamental to scaling data access management in the data mesh. The table below summarizes the key concepts in the journey from pre-mesh to mesh.
Find out more about how to craft a data mesh governance strategy, check out this webinar with Starburst.



