
Before 1992, if you wanted to buy a stock, you’d call your stockbroker to place, buy, or sell orders. The stockbroker would then communicate the order to the trading floor or exchange desk. The process created a barrier of entry for average consumers, and the banks involved leveraged manual, people-driven processes because the relatively low volume of trades was manageable. But then E-Trade entered the market, and suddenly any consumer could make a trade. The trade volume changed by orders of magnitude, and bankers could not manage it at internet scale. The banks were forced to adapt.
With E-Trade taking off, the banks rebuilt their plumbing to handle trading at scale. New governance and audit platforms were developed. Control systems and automation gave way to new workflows. Banks began to use software to remove the toil of dated human processes.
What does this have to do with the data landscape? Well, the same type of shift is happening to data in the era of AI – any user can be a data consumer. App developers, and those with highly technical skills, no longer act as intermediaries. The data consumer is the CEO, the IT and Ops team … it’s everyone.
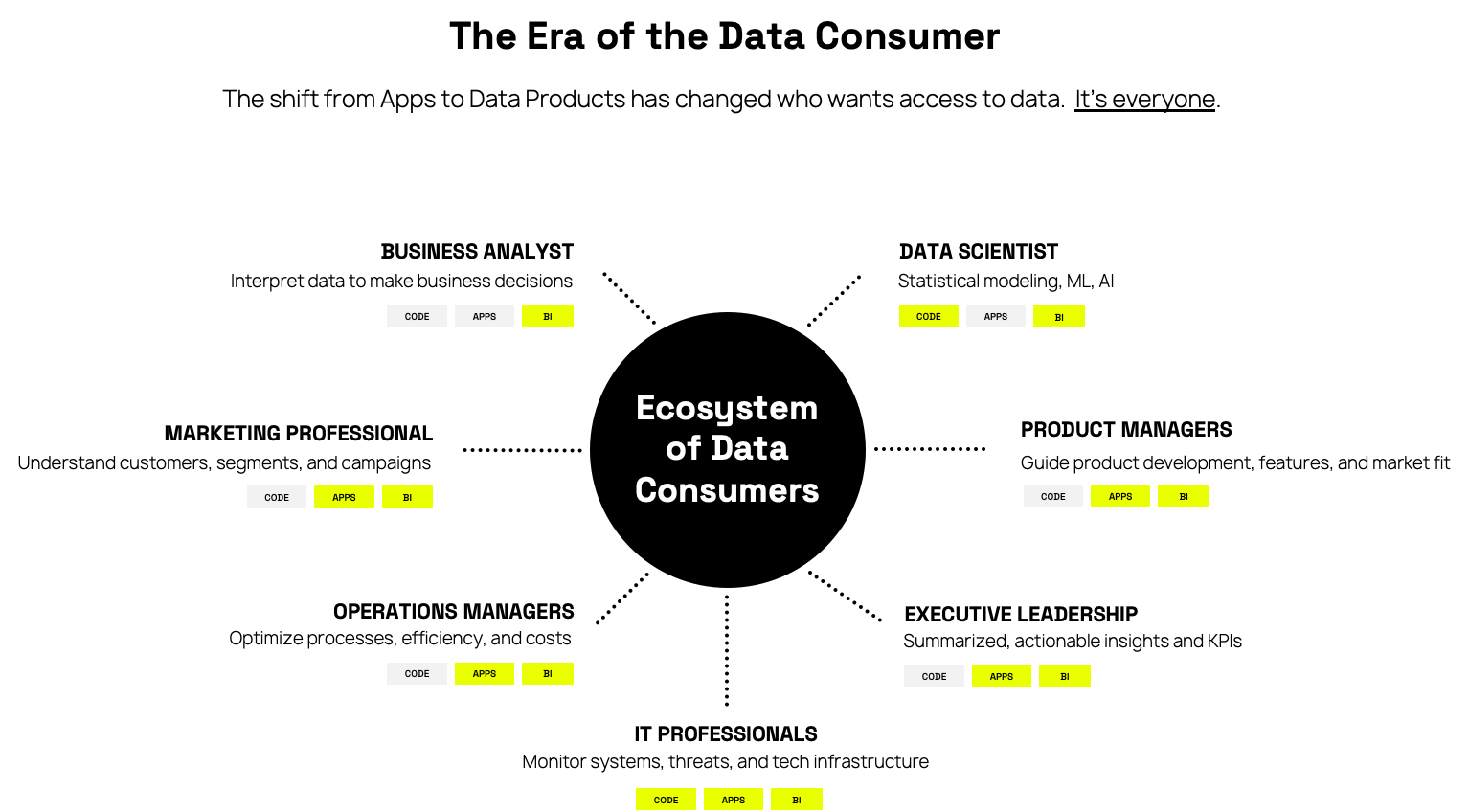
Much like E-Trade, the scale of data consumers is breaking the way enterprises manage and govern data. Centralized IT teams cannot provision data access fast enough for all of these data consumers.
For example, one of Immuta’s pharmaceutical customers processes more than 200,000 data requests per year. If we assume there are 260 workdays per year, that means this company’s governance team manages 769 requests every day. And, these requests are not an easy yes or no. They require a review of who the requestor is, what project they are working on, the sensitivity of the data, etc. Then, they need to review policies, such as masking specific cells or columns, or removing parts of them. This is also not quick or easy to figure out. A back-of-the-napkin way to think about policy is as follows:
TOTAL COMBINATIONS = (NUMBER OF DATA SOURCES)² X (NUMBER OF UNIQUE USERS)²
Most of our customers have around 1,000 data sources, but our top 25% have 40,000 to 250,000. Almost all of these enterprises have 30,000 to 50,000 active users. You can do the math, but the number of potential combinatorial factors quickly gets into the billions.
It’s simply not possible for humans to manage this in an efficient or sustainable way. What makes it even crazier is that the pharmaceutical company I mentioned has 7x data governors managing this process. So, each governor deals with about 110 data access requests a day, which piles up to 550 requests per week. Each request starts the manual process between the business user, governance, and IT.
At the end of the day, business users need data. They need to do more with it, faster, and they do not have time for governance toil to slow them down. To provide data access at this scale requires a new plumbing system for the enterprise to remove the toil of human-driven data access provisioning.
For those that know Immuta, you might be thinking – isn’t Immuta’s purpose to simplify access rights through automated, fine-grained security? What does data provisioning have to do with data policy?
We have spent the past eight years building the Ferrari of data governance engine. We’ve developed the most sophisticated and performant means to implement policy on data for the world’s largest organizations. These include banks, pharmaceutical companies, and intelligence and defense organizations. We were fortunate enough to partner early on with cloud data infrastructure providers like Snowflake, Databricks, and AWS, and inject ourselves natively into their engines to optimize for scale and performance.
However, highly sophisticated data policy at scale doesn’t fully solve the toil problem. It’s just one part of a two-part problem. Building attribute-based access control (ABAC) at scale does not solely provide data consumers access to data fast enough – it helps, but provisioning access is still a mess.
Remove the crazy number of potential policies. We have figured out a way to compute complicated policy logic at scale and not impact expected query times. We even have great ways to make policy non-deterministic. But, at the end of the day, it’s not just about policy.
Data access toil is built on humans and roles. Remember, our scenario: 7x data governors for 50,000 users and 200,000 annual data access requests. But those requests involve more than just the data governor. The interaction of data stewards, data governors, data owners, IT, and security makes data access provisioning complicated. There are a myriad of workflows between each group, with sub-workflows that all require tickets and meetings:
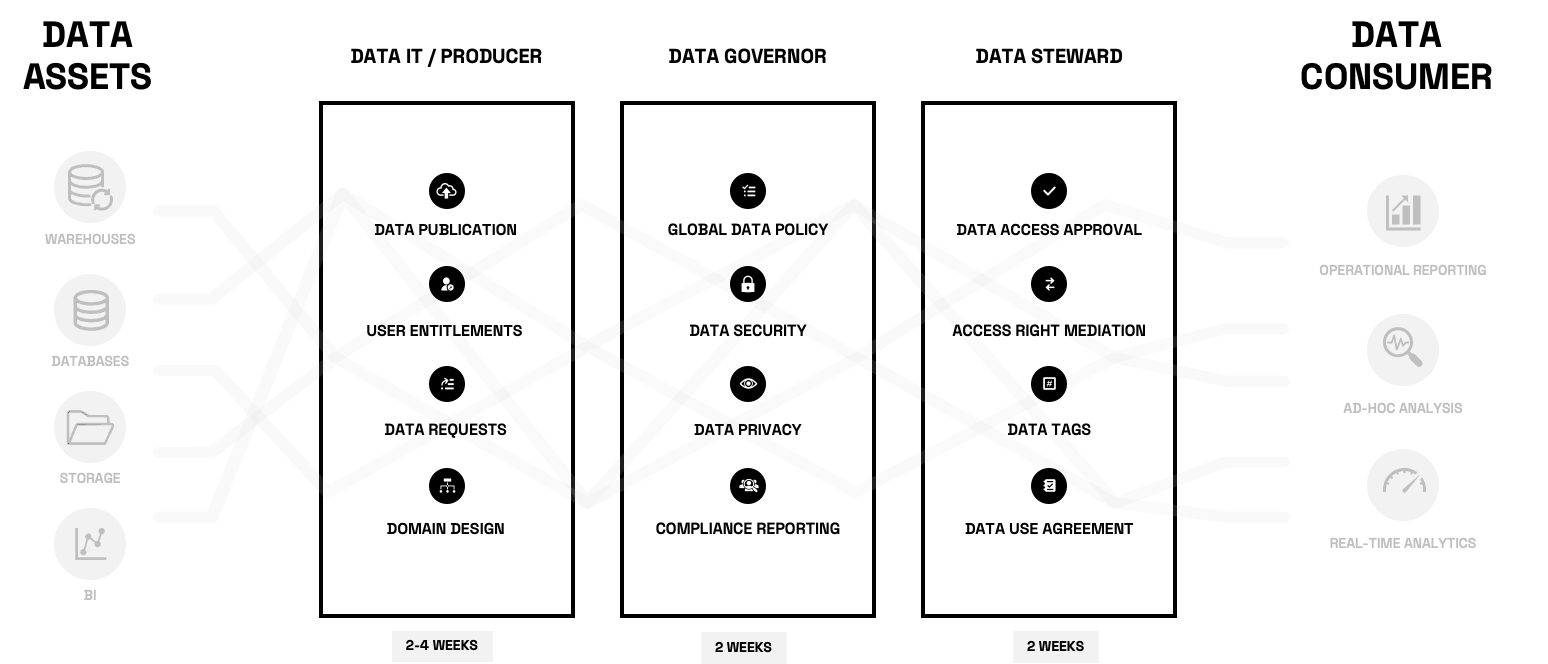
As a result, large companies end up taking months to process a request. In today’s fast-paced environments – where speed to insight is a company’s most important asset – the value of that data has perished by the time it reaches the consumers.
The enterprise needs new plumbing to solve the complexity of both scalable data policy, AND the workflows that engage the stakeholders between the data consumer and data assets.
Only once automation and efficient workflows are in place can insights be generated at the speed of the business and the scale of its data consumers. Enter the future of Immuta: a way to solve both problems.
The Immuta vision has always been bigger than data access governance or data policy. We’ve envisioned controlling data via policy as a baseline set of services, and expanding and leveraging those services to control BI, AI, and eventually robotics. We were ahead of our time, thanks to visionary US Government leaders who invested heavily in the cloud and allowed us to see the future of regulated data access early on, at a scale and complexity no other organizations could fathom.
But what does it mean to expand out? It means leveraging our core data discovery, metadata registry, policy entitlement engine, and unified audit services to build out workflows – or plumbing – that benefit all stakeholders in the data access request process. This requires a way for data governors to write policy, data stewards to provision access to data consumers, and data consumers to easily find and request access to data products. Better said, we want to streamline organizations’ ability to find, request, govern, provision, and access data.
I am excited to introduce the first version of this expansion. We will continue offering the Immuta Data Access Governance software, but will now also offer a Data Marketplace solution.
This is not to monetize data, but rather to power an internal marketplace where data products can be published, searched, and accessed – improving collaboration and workflows across teams, so that the enterprise can generate new insights faster and more efficiently. Our goal is to make it easy to find data, request access to it, trust that it’s authorized to use, and actually deliver the data to the user – all without having to write code, make a copy of the data, manage cumbersome tickets, or involve technical resources.
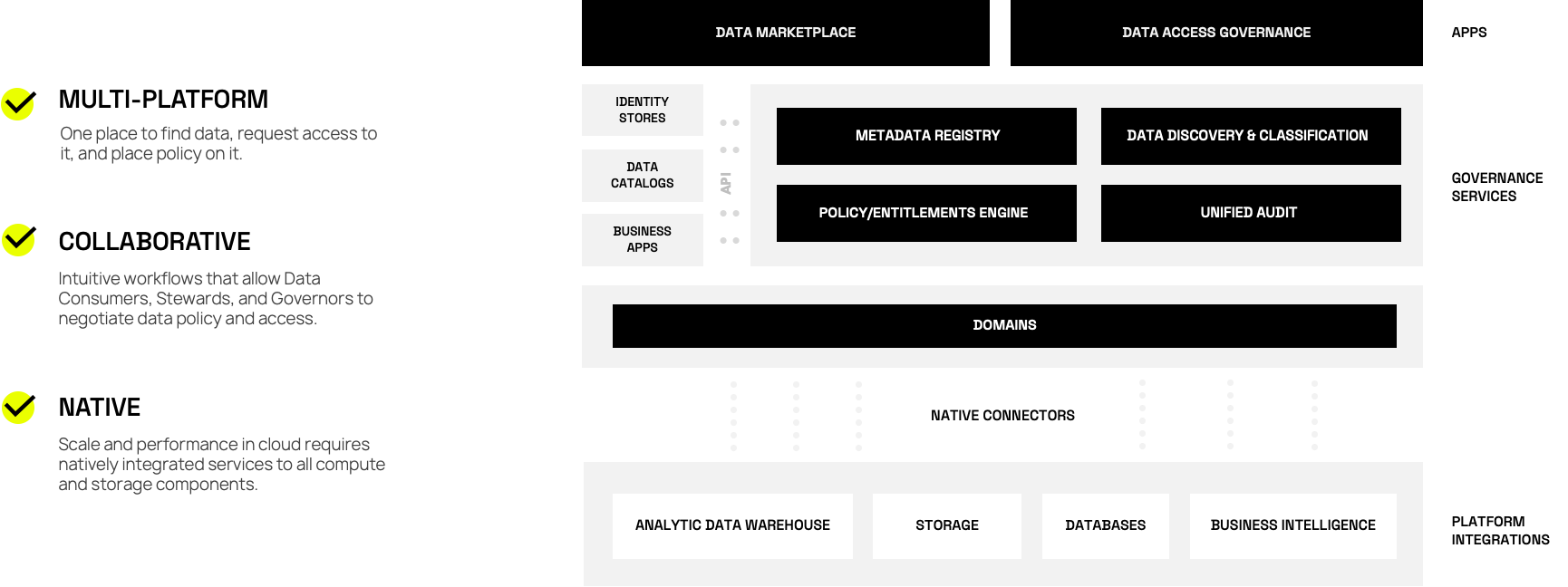
Our new architecture makes it easy to complete end-to-end data access requests. Data consumers can find data products and request access to them, data stewards, product owners, and governors can review and change policy, and provision access to the data. No more tickets or meetings necessary.
With the release of the Data Marketplace solution, our focus will be on treating the data consumer and data steward as first-class users. To that end, we will introduce:
- Data Marketplace Powered by Immuta: An application where stakeholders can publish, search, and request access to data products.
- Workflows: A series of integrated functions within the Marketplace and Data Access Governance apps to connect data consumers, data stewards, and data governors and optimize data provisioning as a service.
- New Connectors: Expanding beyond cloud data infrastructure and broadening our connectors. Over the next year, we plan to build out support for traditional databases, business intelligence tools, retrieval-augmented generation (RAG) models, and storage. All of these will be natively integrated and perform within a standard deviation of a direct query within the infrastructure.
- Intelligent Policy Management: More data and more users means a lot more policy. We will introduce a co-pilot, along with global policy packs, to scale those 7x data governors to act like 700. Our goal is to help automate 80% of data policy decisions through AI and pre-built, domain-specific policies.
Our goal is to make data access provisioning across the enterprise as easy as possible. We will be able to automate 80% of data access requests so that data governors and data stewards can focus on the 20%. It’s all just a simple series of clicks and decisions to put data to work:
REQUEST ACCESS WORKFLOW
APPROVE ACCESS WORFKLOW
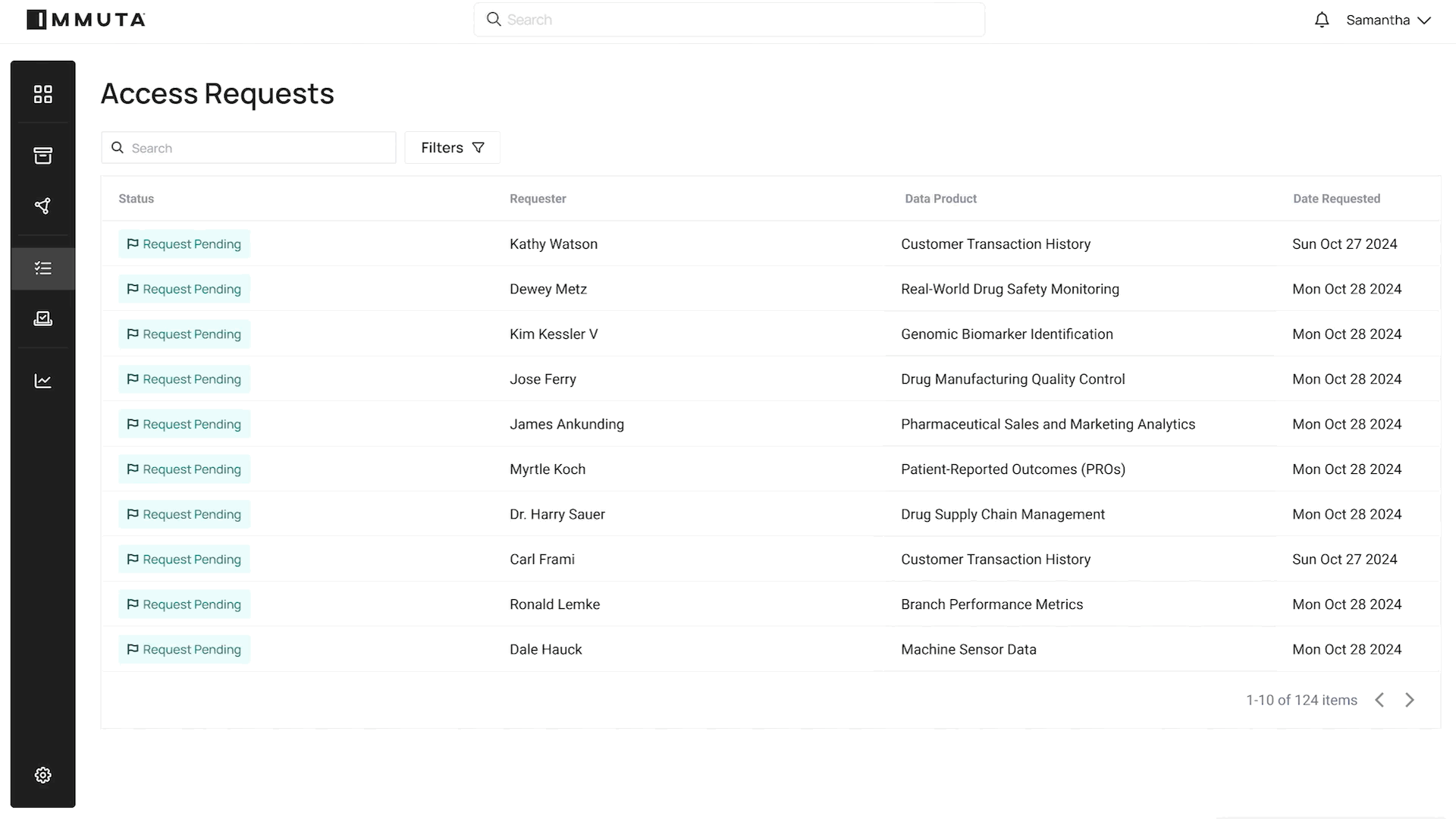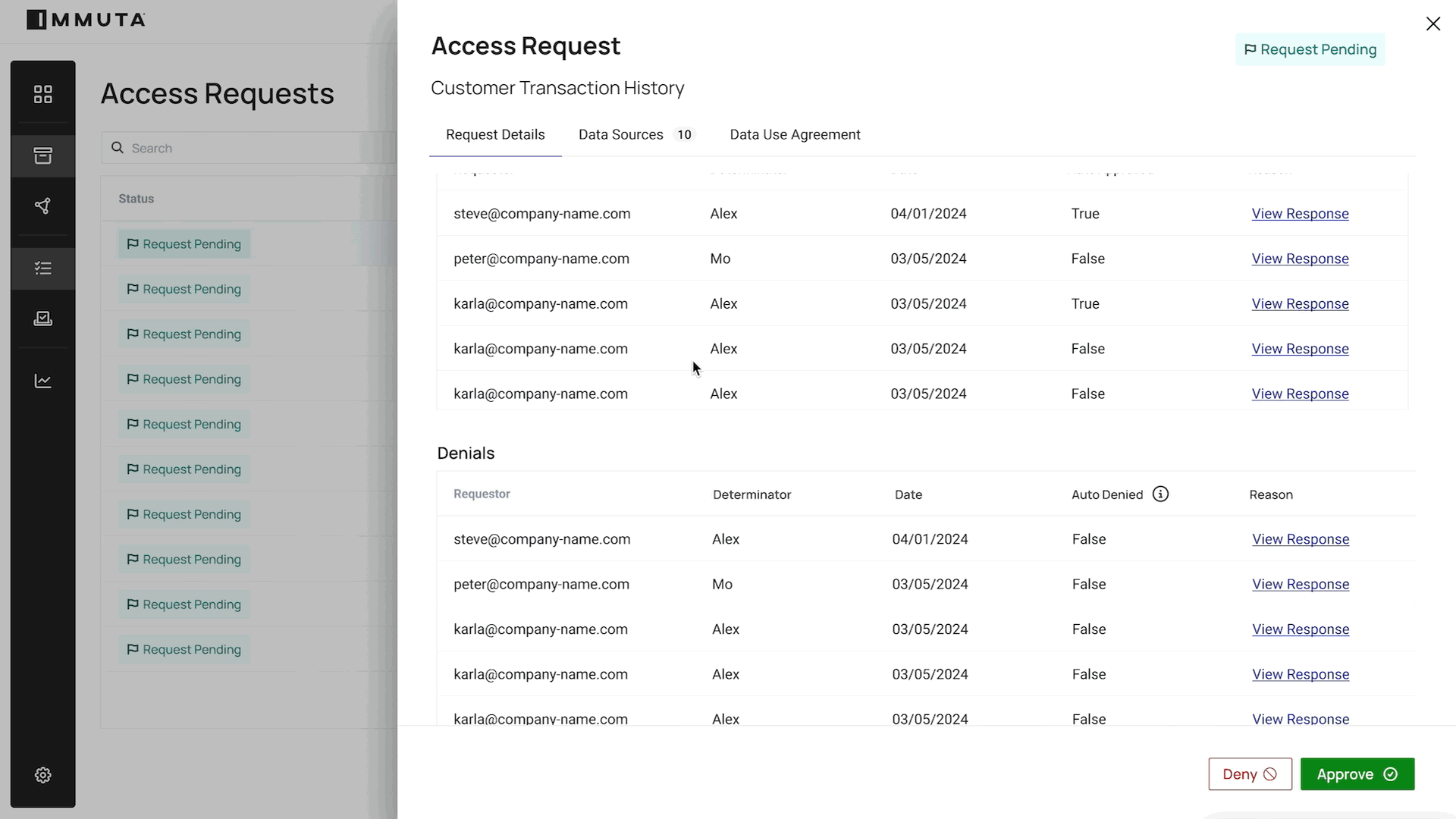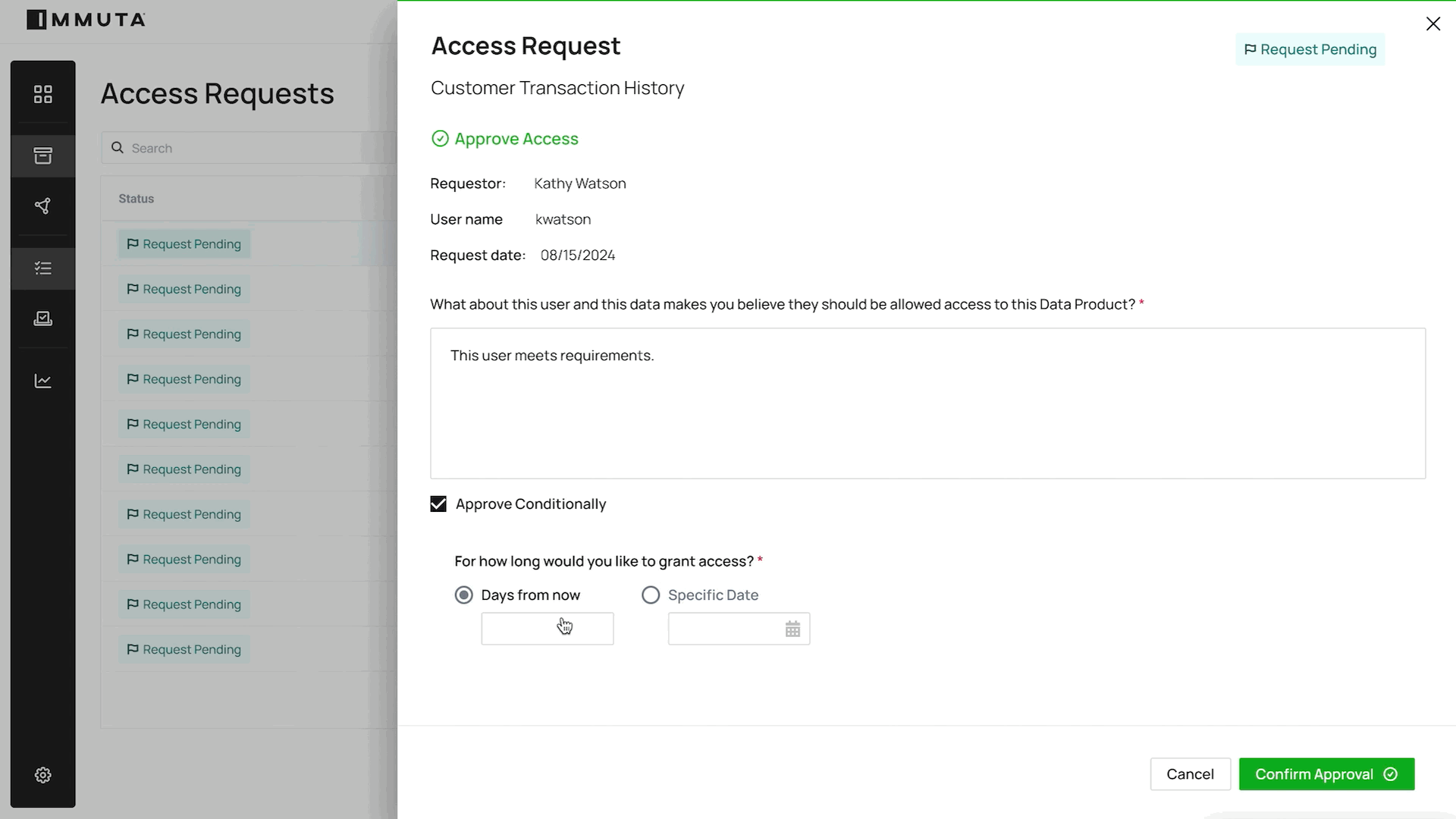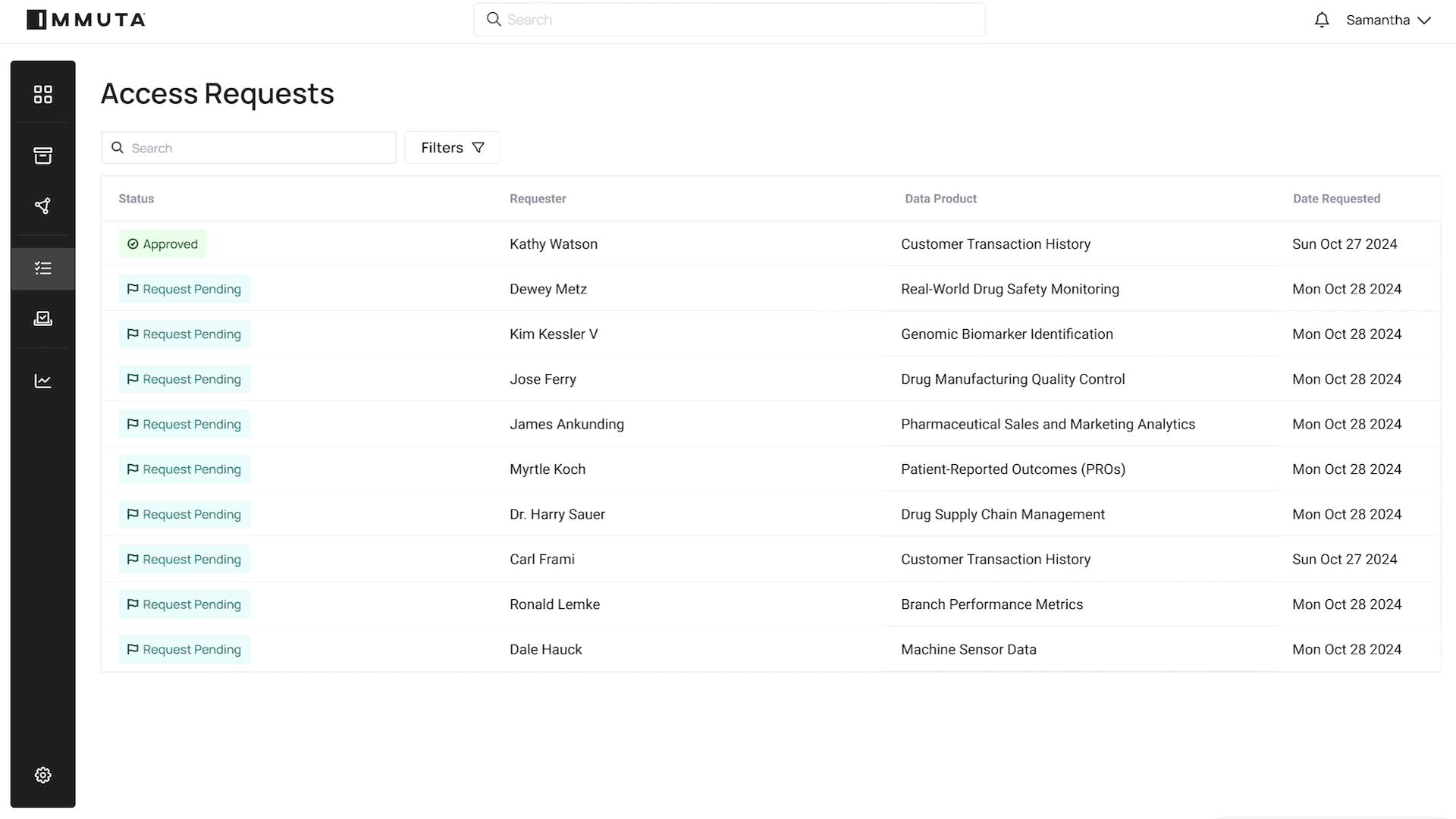
As we connect data governors with data stewards and data consumers, our belief is that enterprises that embrace this shift will be more flexible, and their data-powered end users will be less reliant on manual workflows. That in turn will fundamentally change the way their business operates, making data use more efficient and scalable, while maintaining governance and security. With peak time to data and a culture focused on aggregated insights, any organization – no matter how large or complex – will be able to tap into its most valuable data assets without taxing its human assets.
Dive deeper into data marketplaces.
Read more about our Data Marketplace expansion and functionality.



