
The emergence of generative AI and GPT technologies has brought about new concerns regarding data privacy and security.
Diego Souza, Chief Information Security Officer, Cummins
The rapid rise and evolution of GenAI applications is making quotes like this quite common. In fact, a recent survey by Immuta found that 80% of data experts agree that AI is making data security more challenging. Despite this, 88% say their employees are using AI, regardless of whether the company has officially adopted it. It’s clear that the GenAI genie is out of the bottle – now it’s a matter of not just keeping up, but staying ahead.
AI, and particularly GenAI, changes the game because of how data is consumed and knowledge from it distributed. Traditionally, a given data analyst would have access to some large set of data across an organization, but they would need SQL experience to query it. But there’s only so many hours in the day, and so much any given analyst can consume and distribute. As a result, sheer human limits actually help prevent unintended data leaks within the rest of the organization or beyond.
Now, the introduction of AI “copilot” SQL capabilities removes the need for SQL or apps to query data – which vastly increases the number of non-technical users that can query structured data more easily. That growth in users and data analysis significantly increases the risk to tabular data. This is where Immuta has helped our customers for years, as the innovators of centralized attribute-based access controls (ABAC). Amid fast-changing advances in AI, this approach is even more important now.
Additionally, and separately, AI introduces a new unstructured data problem. With GenAI, unstructured data consumption is being done by artificial intelligence, not human intelligence. AI can consume, abstract, connect, associate, absorb, and most importantly distribute that knowledge at scale. This means that unstructured data, once inadvertently “protected” by human limits, must also now be categorized and explicitly protected.
This means focusing on the data warehouse – where the data analysts live – is no longer enough. With GenAI, unstructured data and files are king. This requires a broadening of access control philosophy, with layers of defenses.
The Lines of Defense
Before getting into the solution’s technical details, we’ll first identify where the lines of defense should reside.
First – The Storage Tier: This is where your unstructured data remains at rest, most commonly in Amazon S3, ADLS, or Google Storage. The first line of defense lives here; you must guarantee that objects in storage are only used for approved GenAI use cases to avoid leaking personal information or intellectual property.
Second – The Data Tier: This is where your unstructured data is transformed for training, or more commonly “chunked” for RAG use cases. The second line of defense lives here. This tier requires creating some structure out of the unstructured data, a process that opens the door for intra-file filtering of sensitive information – just like at the storage tier, but more granularly.
Third – The Prompt Tier: This is where your consumers interact with your RAG application. For example, they will ask questions – which may contain unauthorized or sensitive information – and get answers back that are too sensitive in nature or incorrect, as is the case with hallucinations. This is your third and final line of defense. It helps protect against inappropriate questions and sensitive or wrong answers, and is sometimes termed Prompt Security.
Immuta GenAI Solution
We believe there is too much dependence on the third and final line of defense in the market today, leaving customers open to privacy leaks with GenAI. Relying on the final line of defense alone is not enough, and puts too much pressure on prompt security.
The Immuta GenAI solution is focused on the first and second lines of defense.
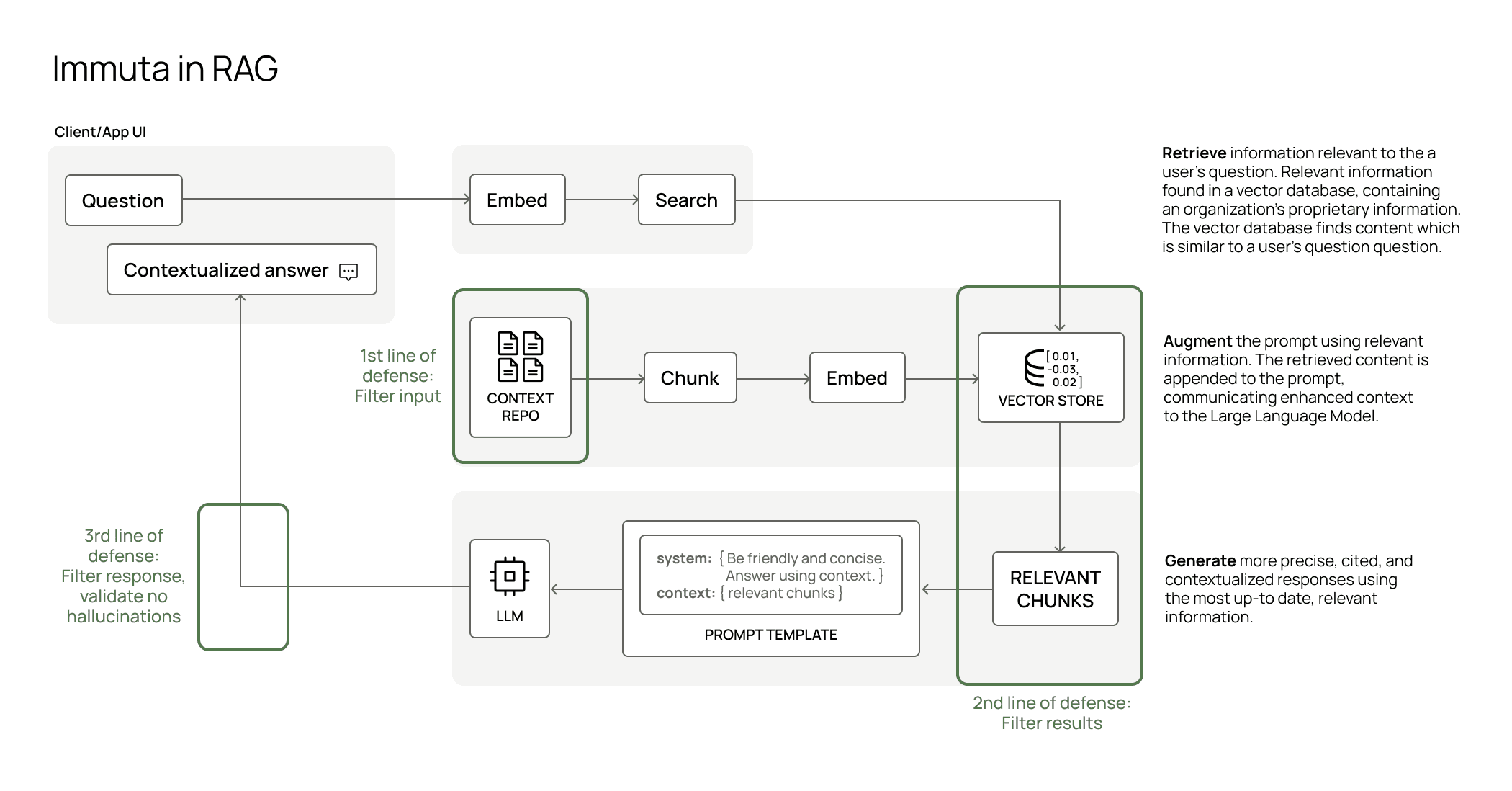
This empowers data platform teams to manage the first and second lines of defense – and when combined with a third line of defense, provides the full spectrum of control against AI risks.
1st Line of Defense: Storage Integrations
In order to protect at the storage tier, Immuta released our native S3 integration. We worked extremely closely with AWS on a joint solution that enforces fine-grained and scalable access control on your unstructured data stored in S3. This means Immuta’s ABAC innovation is no longer limited to tabular data – now, you can push down ABAC controls to the storage tier.
Booking.com, a leading travel company with 120M+ active subscribers, has used this integration to power access to unstructured and structured files, using Immuta as the single source of policy. This allowed them to centralize policy management and enforce policies consistently across all data, with no manual effort required.
S3 is just the start – in the coming quarters, we will expand these same concepts across Databricks Volumes, Snowflake Stages, ADLS, and Google Storage.
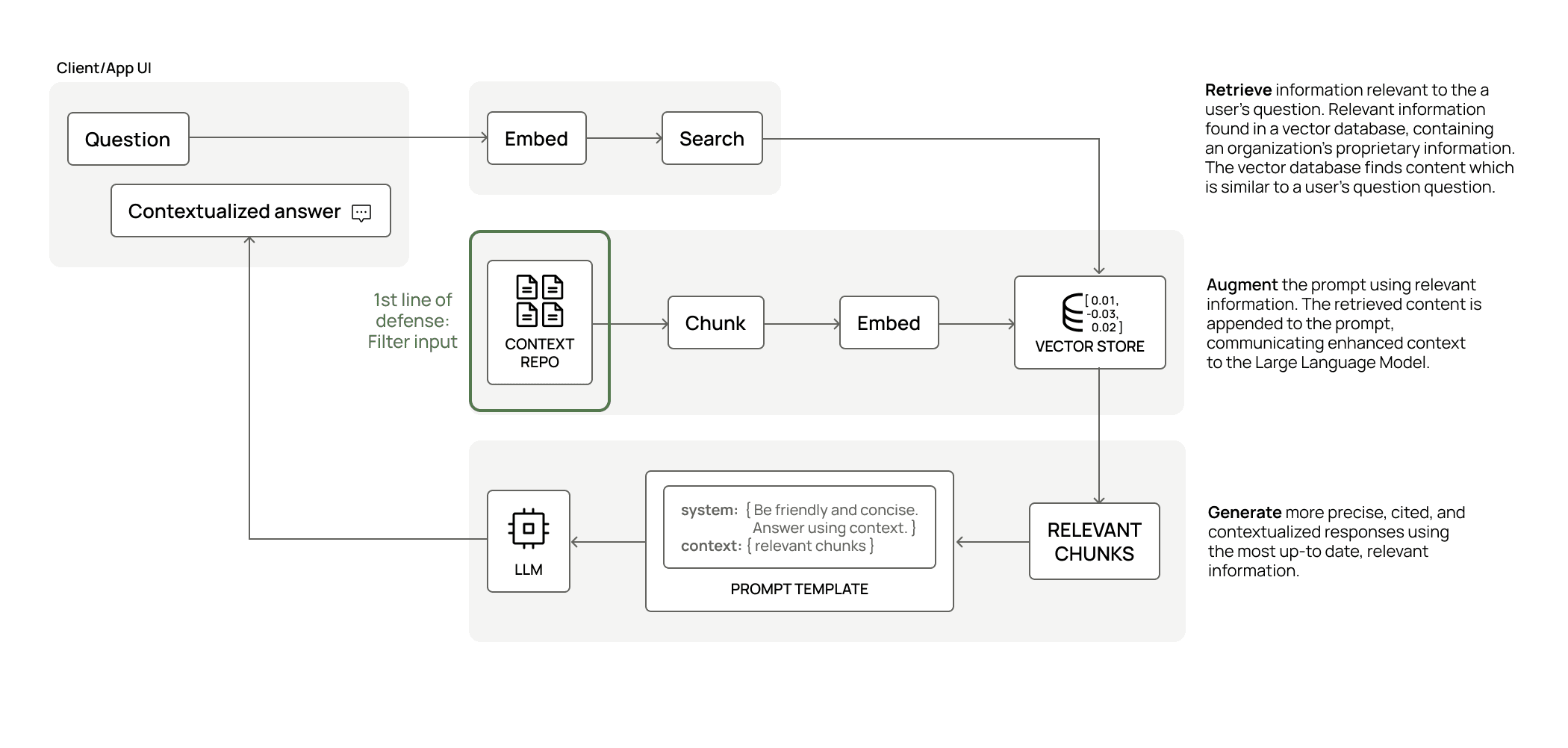
2nd Line of Defense: Retrieval-Augmented Generation (RAG) Filtering
Both Databricks and Snowflake have recently released end-to-end solutions for managing RAG-based LLM applications (see here for Databricks and here for Snowflake). In both cases, the unstructured data is chunked into smaller pieces and stored in rows in a table, which also includes embeddings created by their respective LLM engines. Embeddings enable free-form human language to successfully query the most relevant stored chunks needed to answer the question at hand. Those query results are then passed to the LLM to be converted back into a free-form human language response.
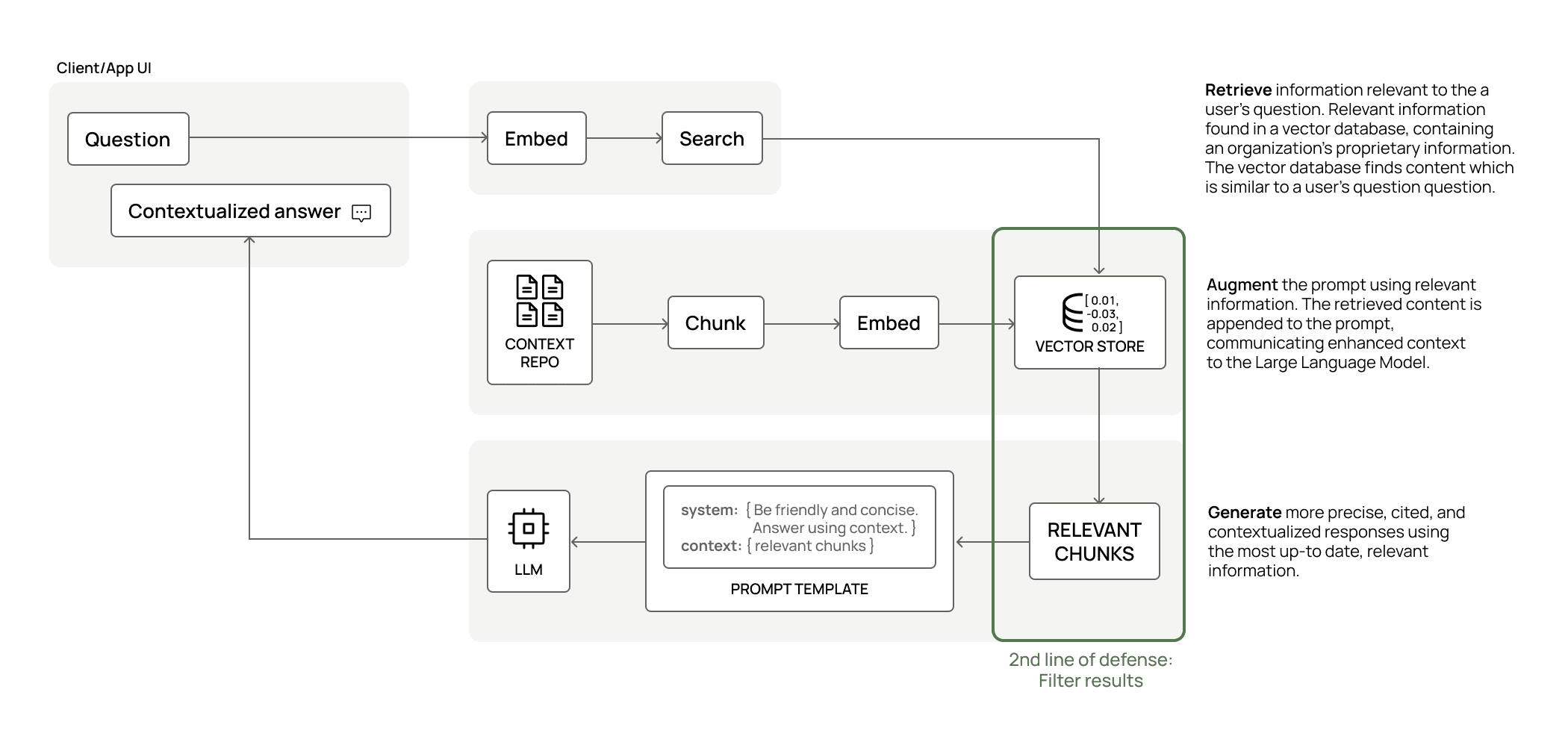
This process allows customers to dynamically inject their own proprietary data into LLM responses without having to fully train a proprietary LLM on their own – which would require substantial time, effort, and money. Because of this, you can also create many more use-case specific LLM applications with ease.
The key word in the RAG flow is dynamic: since the chunks of text used for the response are sourced from a table at runtime, traditional structured controls can be applied to that table. Therefore, the Immuta ABAC-powered row filters are able to filter your RAG chunks dynamically at response-serving time. And since the Immuta ABAC model is dynamic and agile, there can be many permutations of access filtering to match the querying user’s access.
But what really makes the RAG filtering special is Immuta’s latest innovation: row classification. Most users are familiar with column tagging in a tabular world – you tag columns according to their contents. Immuta offers this capability via sensitive data discovery, which allows you to automatically discover and tag columns. We have now extended this capability to topic modeling so that you can classify text chunks per row. This topic classification drives the dynamic RAG filtering, leveraging Immuta ABAC row filter policies as you always have. These reads can also be audited and monitored to alert you when sensitive data is being used in models or responses.
RAG filtering through the Immuta GenAI solution is available in Private Preview for Snowflake and Databricks today.
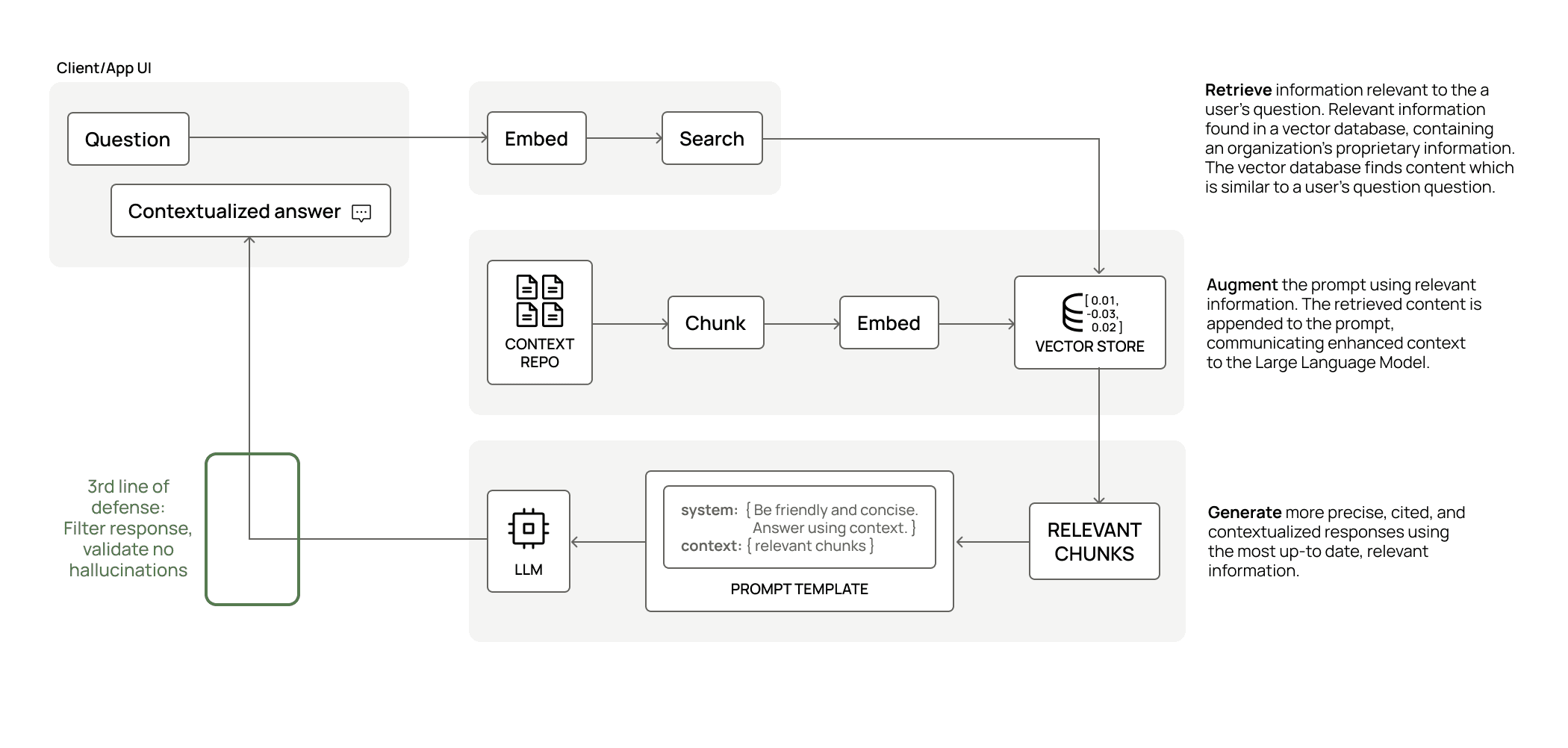
3rd Line of Defense: Prompt Security
Immuta doesn’t claim to solve it all. Prompt security bleeds well beyond the data platform, and into the application tier. It requires a solution that not only covers sensitive question/response filtering, but also hallucinations. The Immuta GenAI solution will improve and remove strain on your existing prompt security solutions by putting two lines of defense before it.
Conclusion
GenAI has forced a change in the breadth and depth of security coverage that data teams require. We advise organizations to not only focus on prompt security, but to also adapt their data security strategy to address the feeding of those models (tiers 1 and 2). Ultimately, it is critical that three lines of defense are in place with clear ownership across them.
The Immuta GenAI solution covers the first two lines of defense to empower your data platform team to take control of GenAI security at the data tier. With more scalable control, you’ll be able to innovate with AI faster, generate more productive outputs, and confidently move at the speed of AI – all while keeping risks at bay.
To learn more about how to protect RAG-based GenAI applications at every layer of defense, click here.
Start protecting your AI workloads.
Talk with our team of experts.


