
Over the past year, we’ve witnessed an unprecedented surge in the development and democratization of AI technologies. Companies are building proprietary models, while the average person – regardless of technical expertise – has tools like ChatGPT at their fingertips.
AI is not just changing the way we work, it’s changing the way our systems work.
For many organizations, this is forcing a paradigm shift. The management responsibilities that once fell on IT teams are moving to data stewards. Data infrastructure is becoming more decentralized. And perhaps most importantly, unstructured data living in storage layers is more accessible and useful than ever before.
With more than 350 trillion objects stored, Amazon S3 is one of the most popular cloud storage solutions. Amid the massive volume of S3 objects, securing and monitoring both structured and unstructured data in S3 buckets and data lakes is becoming increasingly critical. Existing data access tools were centrally managed by technically-focused IT teams, which worked well for smaller data volumes and ecosystems. As data lakes grow in number and scale, more business units need access to portions of those data lakes. This creates a need for domain-managed, business-centric solutions.
Immuta’s new integration with Amazon S3 Access Grants is changing that. By building on Amazon S3 controls, joint customers can increase efficiency with fewer policies and less manual effort, reduce operational costs, and open up new revenue streams.
This integration represents a paradigm shift for Immuta, as we go from protecting solely structured data for analytics in compute layers like Snowflake and Databricks, to also providing security for data in storage layers. It also vastly simplifies data policy management since the same policies and access rules that govern your data lake or warehouse can now also govern S3. We firmly believe that this will benefit all organizations, regardless of industry or use case, as we move further into the new frontier of cloud data use.
The AI-Driven Resurgence of Data Lakes
Personalized streaming recommendations, virtual assistants, chatbots, and spam filters all have at least one thing in common – they’re powered by AI. And, to ensure these services provide value for you, the end user, the underlying AI algorithms require massive amounts of data to train and develop.
This data is primarily unstructured and includes large volumes of text, imagery, video, and audio. It augments structured data, helping to train and fine-tune foundation and large language models (LLMs), among other types of AI models. Due to the nature of the data and the sheer volume of it that’s needed, data lakes are the most practical repository for it. This, coupled with the demand for AI, is driving a resurgence of data lakes.
Major organizations that we’ve talked to have validated this – there’s simply too much data in their data lakes to warrant extracting it and then enforcing fine-grained controls on it. Instead, users are pulling data directly from the data lake, in any format they need. Leveraging unstructured data from storage is now just as prevalent as structured data in compute layers.
For central storage admins, this requires creating and enforcing increasingly complex policies in order to maintain fine-grained control of user access permissions. With users and access patterns constantly changing, data teams must manually manage who is accessing data and for what purpose. It’s easy to see how quickly this could get overwhelming and difficult to scale.
A Philosophical Change: Data Security for Storage & Compute
Historically, Immuta has focused on protecting data within the compute layer, as most analytics were focused on processing structured data. But the shift back to data lakes and trend toward accessing unstructured data directly from the storage layer made us reconsider our original approach. If our customers need scalable policy solutions for storage as well as compute, we need to meet their needs on both fronts.
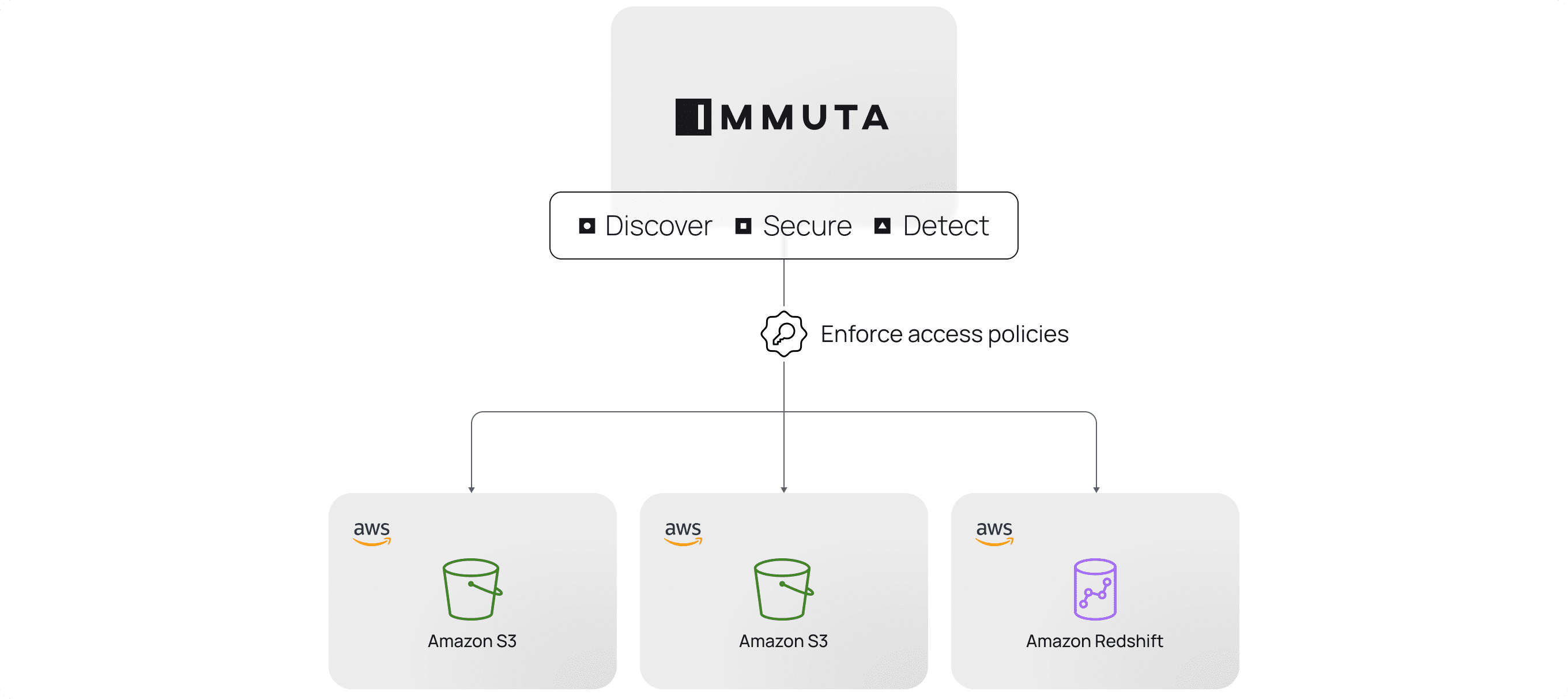
We need to be able to connect to any data source, apply fine-grained controls on the data, and ensure those controls achieve compliance with rules and regulations, regardless of whether data is in storage or compute. Our native integration with Amazon S3 via S3 Access Grants is our first opportunity to deliver data access control for the storage layer.
How Immuta Builds on Amazon S3 Security
For enterprises to build AI and other analytics at the speed of the market, they need a self-service approach to its development. This requires users to automatically be able to access any data they need, so long as they have the right to do so. But this comes with a few challenges:
- Users require ad hoc access to more S3 buckets than ever before, but managing authorized access is often tedious and burdensome to manage at scale, with too many users, rules, and assets to audit.
- Access management responsibilities are shifting from IT teams to data stewards, who are often less familiar with policy logic, regulatory frameworks, etc.
- Users expect all data endpoints to be quick, easy, and performant.
On top of all of this, AI is more of a hindrance than a benefit if it has performance issues. Any non-native solution will inevitably encounter such issues.
That’s why it was key when we set out to protect data in the storage layer that we delivered a native solution. So, using the new Amazon S3 Access Grants feature, we created a simple GUI to control S3 prefixes (folders) and objects (files) directly through the Immuta Data Security Platform. The GUI handles subscription access based on user rights, as well as more complex policies, including purpose- and location-based policies. This is a more dynamic and scalable access control approach than legacy methods like RBAC (role-based access control), and avoids having to manually write controls for every S3 object. Further streamlining policy management and enforcement, Immuta leverages existing metadata in your enterprise data catalog like Alation, or sensitive data discovery tools like BigID or Amazon Macie.
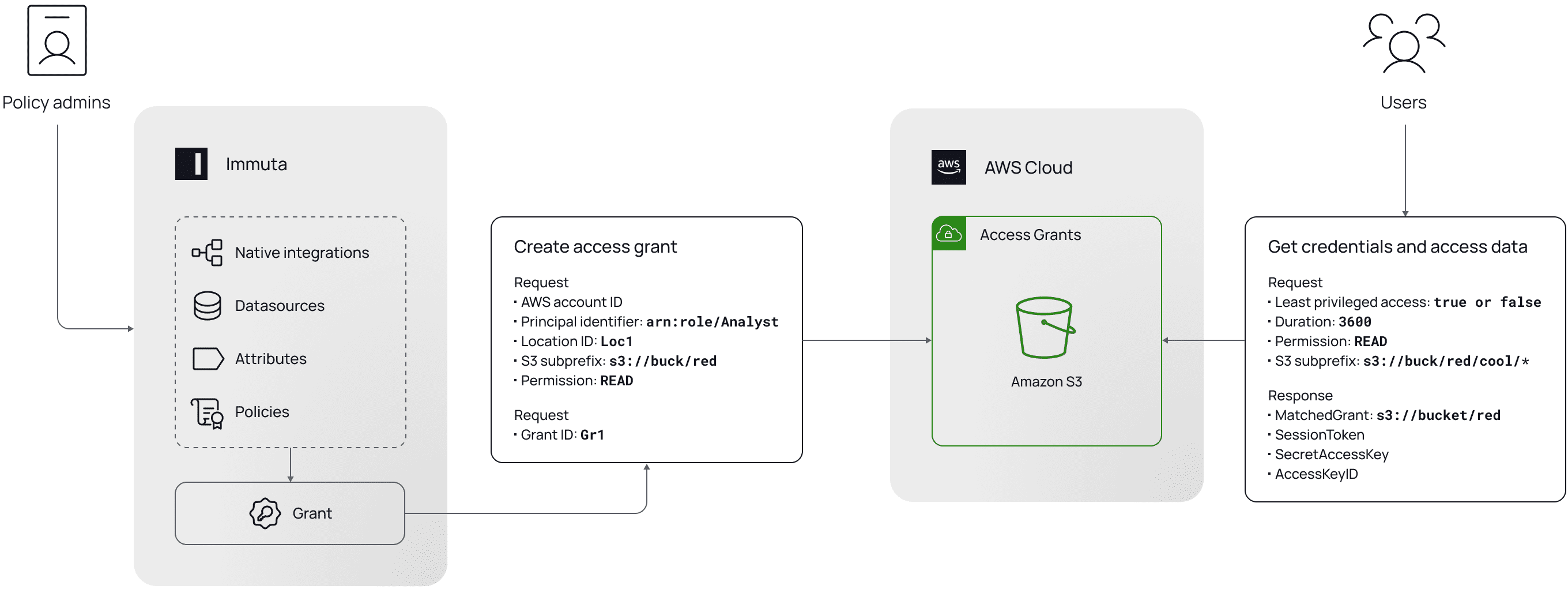
Since Immuta natively integrates with S3 Access Grants, there is no performance overhead when objects are accessed. By supporting complex rules that make real time access decisions which track directly to regulatory frameworks, Immuta provides nuanced access control, versus a simple yes or no. And, these controls extend consistently across the rest of your compute environment, so data stewards can control access from a single governance layer, regardless of where the data lives.
In short, end users encounter no friction or delays when they need to access data.
To ensure these controls are working as intended, Immuta unifies audit capabilities across all protected platforms, providing a single lens into who is accessing what data and for what purpose. This puts automated compliance reporting in your hands, so you can identify anomalous user behavior, receive alerts about unusual data access or usage, and proactively respond to potential threats. With 75% of organizations now subject to 10 or more regulations, this is key to achieving compliance with a proliferation of data security requirements.
Looking Ahead: Immuta + AWS
Immuta customers can now centralize scalable data access governance and granular enforcement across complex data stacks comprising data lakes and data warehouses. These data stacks often include S3, in addition to Redshift, EMR, Snowflake, Databricks, and Starburst (Trino). Our partnership aims to simplify data security controls and provide customers with the tools necessary to protect their data across all AWS services.
To learn more about our partnership with AWS, click here.
See how the integration works.
Experience Immuta + Amazon S3 in action.



