
ChatGPT is one of the fastest-growing artificial intelligence (AI)-powered apps of all time, but it is just the tip of the generative AI iceberg. The pace of AI’s advancements makes it difficult to keep up with the latest terminology, let alone understand how it may impact your day-to-day responsibilities.
In this blog, we’ll break down the fundamental types of AI models by defining key AI buzzwords and explaining a typical AI fine-tuning pipeline.
Top AI Use Cases
AI is not always a brainstorming partner or writing assistant. Gartner notes that “enterprise uses for generative AI are far more sophisticated” and identifies five main use cases for generative AI:
In addition, Gartner mentions seven sectors with highly relevant AI use cases:
- Automotive and vehicle manufacturing
- Media
- Architecture and engineering
- Energy and utilities
- Healthcare
- Electronic product manufacturing
- Pharmaceuticals
The UK Office for National Statistics, looking broadly across industries, identified improving cybersecurity, efficiency, and personalization as the most common AI use cases. But regardless of how AI is used, the same three terms continue to come up: generative AI, LLMs, and foundation models.
What Are Generative AI, LLMs, & Foundation Models?
AI broadly refers to the automated or semi-automated machine processes that perform complex tasks usually done by humans. This includes functions that are not necessarily related to content creation, such as classifying or grouping data, modeling trends, or executing actions.
Generative AI
When you think of generative AI, think of content. Georgetown University’s Center for Security and Emerging Technology defines generative AI as “any AI system whose primary function is to generate content.” In this sense, it is a subdomain of the larger AI space.
Generative AI comprises systems that are able to generate images (e.g. Midjourney or Stable Diffusion), audio (VALL-E or resemble.ai), code (Copilot), and language (LLaMA, GPT-4, PaLM, or Claude).
Large Language Models (LLMs)
Large Language Models (LLMs) are one type of generative AI. They are statistical models of language that estimate the probability of a sequence of words appearing within a particular context. This context could be spoken dialog, written text, computer code, or text summaries, to name a few.
LLMs have become increasingly sophisticated, making them more realistic and accurate. This is driven in part by a growth in the parameters used to approximate the language model. For instance, the size of ChatGPT has grown from approximately 1.5 billion parameters with ChatGPT 2, to 175 billion parameters with ChatGPT 3, to an estimated 100 trillion parameters with ChatGPT 4.
Foundation Models
Foundation model is a term coined by the Center for Research on Foundation Models (CRFM) at Stanford University. It refers to AI systems that may have been developed for a specific purpose, but can be adapted to a variety of tasks. Because of this, foundation models are sometimes called general purpose AI.
Most of the notable LLMs, such as ChatGPT-4, BLOOM, and PaLM LLM, are described as foundation models. But in reality, the line between foundation models or general purpose AI and other models is rather blurry – either may be used as an input model, and receive additional training rounds or undergo specialization processes. So, the term “input model” is better used to reference a prepackaged model that can be used directly or tuned for a more specific purpose.
The emergence of input models explains why many experts are convinced that AI adoption will greatly accelerate in the coming years. Why?
Input models reduce curation requirements and centralize model training. This helps offset the immense cost of training LLMs, since trained models can be licensed to third parties. Input models are pre-trained on uncurated data, which is often untagged and lacks metadata, but is widely available – uncurated or lightly curated data is mined from the huge quantities of information on public websites, such as Wikipedia, Reddit, and other social media sites.
Input models such as ChatGPT-4 have also been trained on curated training input, such as specific examples of instructions and response scores.
AI Model Training Phases
With this background in AI models, let’s take a closer look at how they are developed and trained.
Pre-training vs. Fine Tuning
What’s the difference between pre-training and fine tuning?
- Pre-training is the process of adapting pre-trained models to specialized applications or narrower domains. LLMs, for example, are trained on a diverse data set used to represent a more generalized language model.
- Fine tuning uses more specialized data, applied through a generalized framework, to gain insights. Essentially, fine tuning is a pre-trained LLM’s college education.
Compared to developing a model from scratch, specialization reduces data demands and costs. Whereas an LLM requires terabytes of data, fine tuning will require megabytes or gigabytes. An LLM may require a few months to train; fine tuning can be done in days.
In effect, fine tuning LLMs democratizes their utilization. The expectation is that a handful of input models will be developed by a small number of organizations, and the majority of deployed LLMs will be fine-tuned refinements of these input models.
How to Fine-Tune an AI Model
The fine-tuning process usually requires defining a curated data set, which categorizes and annotates the data to simplify its analysis. This may be done by marking parts of speech, categorizing entities within the text, defining sources, or assessing the veracity of the information.
Using a model and a curated data set as inputs to the fine-tuning process, it’s possible to draw a notional training and deployment flow. The diagram below is a representation of a fine-tuning workflow:
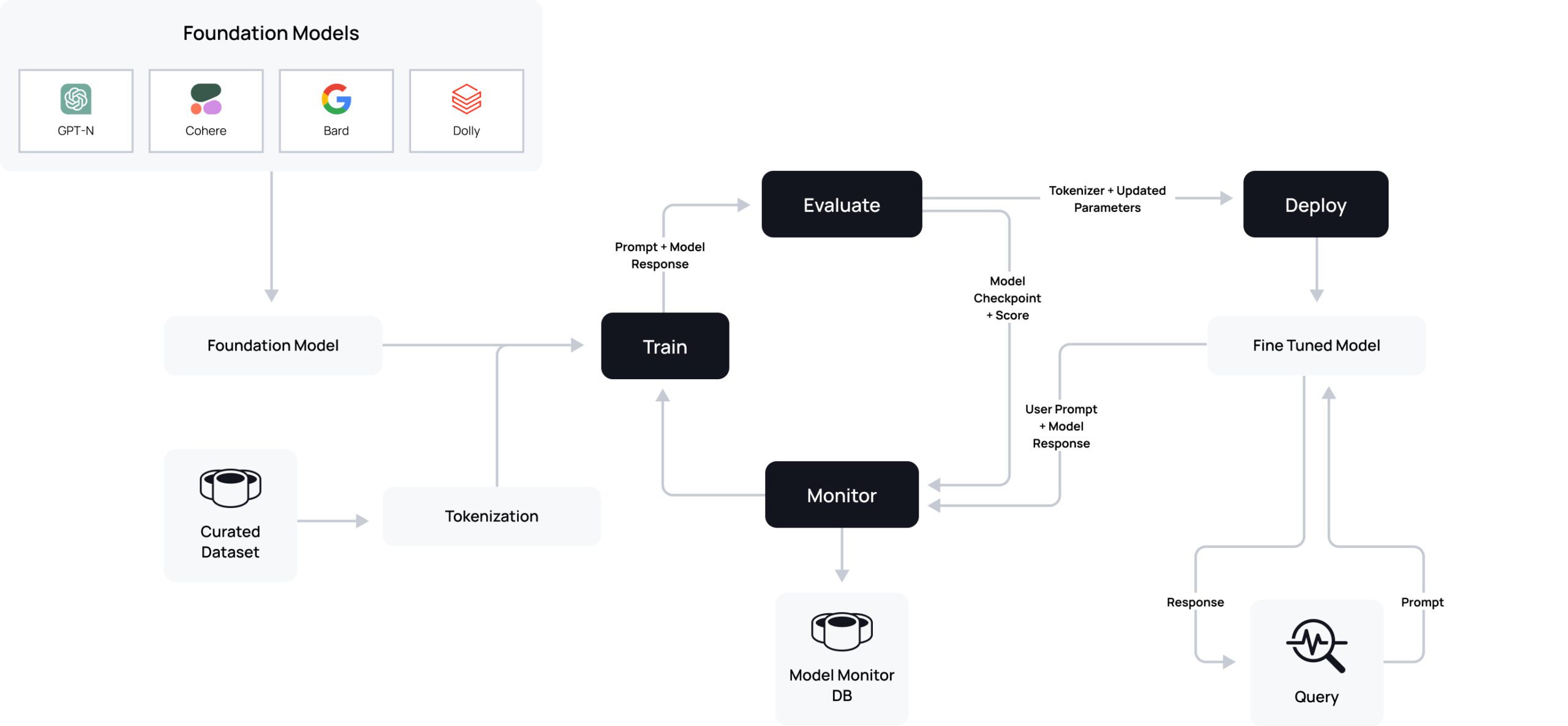
- We start by selecting a LLM (four notable examples are shown here, but this list is constantly expanding).
- We then take our curated data set (shown above) and extract meaningful chunks of words in a process known as tokenization to capture the semantic and syntactic structure of the text.
- Both the prompt and response tokens are fed into a training process using the input model as a warm starting point. In traditional modeling, the starting parameters are often guesses, either confident (e.g. acceleration due to gravity is roughly 10 m/s2), or purely random. Starting with an input model allows us to have an informed starting point for these parameter values.
- The training process modifies these parameters based upon the new data.
- The resulting model is evaluated, and if performance is acceptable, deployed.
- Once deployed, external users query the fine-tuned model and receive responses based on their prompts. Throughout the process, even after deployment, it’s essential to monitor results and performance.
Governing access to the curated data set used during the fine-tuning phase is key to mitigating the risk of sensitive information ending up in the model or its responses. This is an important first step incorporating security into AI workflows.
What's the Worst That Could Happen?
AI risks explained.



