2024 State of Data Security Report
The latest insights on data security, visibility, AI, and more


A modern analytics environment is typically built to reduce time to data, leaving compliance as an afterthought. Yet, without a compliance-by-design approach, the analytics environment is likely to break in weeks because safeguards like purpose-based access control are missing; data minimization and de-identification techniques are inadequate and data access requests are rejected; or, as lengthy compliance workflows are initiated from scratch each time a new data access request is submitted, it becomes impossible to reduce time to data in practice.
One of the broadest data compliance laws that organizations must comply with, according to survey data, is the General Data Protection Regulation (GDPR). The penalties for violating its terms are substantial – in addition to reputational damage, the most severe GDPR fines can reach 20 million euros or 4% of an organization’s prior year revenue.
So it’s clear that GDPR compliance is important, but what exactly does that mean for your company’s data strategy?
Let’s look at five essential steps you should take when building a data strategy that satisfies the GDPR’s strict data privacy and security standards.
GDPR protects personal data by preemptively restricting its use before harm can be done. Therefore, prior to data usage, it’s key to detect and label personal data within an analytics environment.
How do you know what data falls within the GDPR’s scope? If a link can be established between the data and an individual, that data must be legally protected. This is not exactly the same thing as saying that only identifying items of data are protected – unfortunately, not all data engineers are aware of this key difference.
Let’s put this into context. Data within an analytics environment is usually presented with a fixed set of attributes organized into tables, where the rows correspond to records and attributes are organized along columns. Take this typical table containing consumer health data as an example:
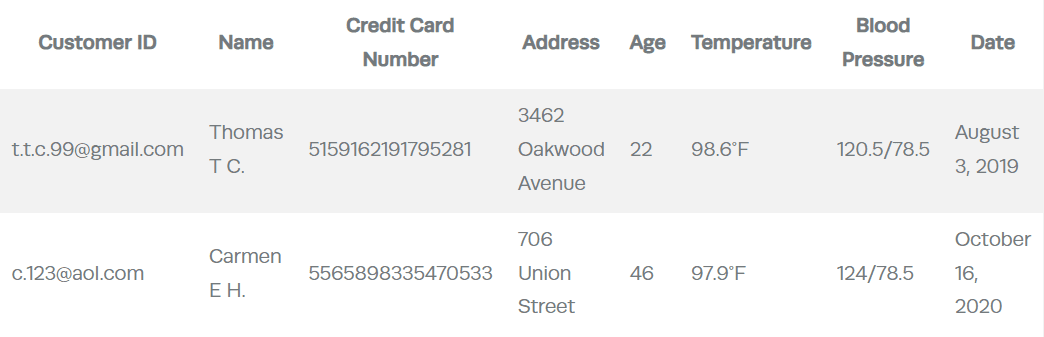
Under GDPR, each column within Table 1 should be tagged as personal information because all column attributes are linked to an individual, who is actually identified.
When taking this first step, adding sensitive data discovery capabilities to your data stack should make it possible for your DataOps team to easily detect and label personal identifiers and other attributes associated with an individual.
De-identification is the process by which the link between the data and the individual is altered. However, this does not mean that data custodians and/or data recipients are necessarily relieved of all obligations. In many cases, data recipients are subject to a series of process firewalls and obligations, including an obligation to not re-identify individuals and to comply with a breach mitigation plan. It’s important to take this into account when building a GDPR-friendly data strategy. Let’s take a closer look at the implications for data teams.
Two common de-identification techniques are pseudonymization and anonymization.
Pseudonymization as a de-identification technique is less demanding than anonymization – it does not require acknowledging external information to determine whether the data can be attributed to an individual. Under GDPR, pseudonymization is considered to be a key security measure, which helps justify the legitimacy of the processing.
Anonymization considers the means of all situationally-relevant potential attackers, not just the intended recipient, when determining whether the link between the data and the individual is broken (and not simply altered). Under GDPR, anonymization makes it possible to avoid restrictions on data re-usage, such as intervenability rights.
Once the legitimacy of your processing activities is established, your DataOps team should use data and context controls to significantly reduce re-identification risks while preserving utility, i.e, meet the pseudonymization or anonymization standards as often as possible. Data controls affect the visibility of the data and include the familiar techniques of tokenization, k-anonymization, and local and global differential privacy. Context controls, on the other hand, affect the data’s environment and include data access controls and user segmentation, contracts, training, monitoring, and auditing. When it’s not necessary to process direct personal identifiers (and eventually, indirect personal identifiers), your DataOps team should only enable access to de-identified data. Putting these controls in place early on – and automating them when possible – will set the foundation for a scalable GDPR-compliant data strategy.
Although data security is a key data protection goal under GDPR, the law goes well beyond it and includes purpose limitation, data minimization, data accuracy, transparency, accountability, and fairness. Importantly, these goals or high-level requirements are interdependent and imply tradeoffs. They are therefore critical to incorporate into your data strategy.
Purpose limitation and data minimization are two of the most important data protection requirements teams should be aware of.
Data minimization can only be achieved once the objective of the analysis has been established, and is interrelated with the purpose limitation requirement, which mandates both a specified and limited purpose. Once the purpose has been specified and circumscribed, the data cannot be reused for a secondary purpose, unless a valid justification is established or the secondary purpose is compatible with the primary purpose.
Your data team should thus organize processing activities by purpose through the creation of unlinkable processing domains and the implementation of purpose-based access control, which is enabled by the attribute-based access control model. By systematically identifying the impact of each project, you can also anticipate high-risk activities that require more intensive monitoring and auditing.
A corollary to the requirements of data minimization and purpose limitation is that access should be terminated as soon as the data ceases to be necessary for the processing. When building a data strategy, your data team should thus create time-based policies to govern access to data. Ultimately, if data retention cannot be justified, you should have the means to request deletion from all live systems, and subsequently, backups.

The latest insights on data security, visibility, AI, and more
GDPR enables individuals to intervene at various points of the processing for different reasons. Although individual rights are not absolute, they must be taken into consideration when creating and implementing a data strategy.
Under GDPR there are seven types of individual intervention: data correction, data access, data portability, data deletion, processing restriction, opt-out, and opt-in.
When building a data strategy, data teams should be able to trigger four intervention functions and generate logs to capture metadata when these functions are being performed:
GDPR’s record-keeping and transparency obligations require DataOps teams to capture four types of metadata.
When creating a data strategy, this is a critical step for auditing data use and proving compliance. The richer the metadata your analytics platform can embed or generate, the easier it will be for your DataOps team to produce compliance reports and interact with the compliance team.
What next? Check our full Data Protection Grammar white paper for a deep dive into the core building blocks of secure data environments and request a demo to see how Immuta can support your organizations’s data strategy.


