
For Data Engineers responsible for delivering data to consumers, the effort needed to wrangle policies can quickly get out of hand as the complexity of data access controls increases.
High segmentation of table access necessitates the management of a correspondingly high number of roles and grants. For example, if data is segmented down to the row-level, those rows may need to be broken out into their own tables via a series of transforms or complex view logic. As a further complication, if you need to mask columns from some users in a way that still provides them some level of utility, you may need to manage even more complex views, functions, and potentially even custom UDFs or complex transforms.
As these issues scale, they quickly become unmanageable; and worse, a mistake could mean that sensitive data becomes exposed. Rather than being able to focus on Data Engineering, most of your time is spent on managing access control.
Benefits of an Access Control Platform
What if, when you went to work, you did Data Engineering every day rather than managing data access control? What if you could do this because you had a platform that could manage access control scalably, evolvably, understandably, and granularly? What would that world look like?
- You would have more time to focus on value-driving data engineering
- Your data consumers would gain access to sensitive data more quickly
- Your data consumers would have access to more data, because the granularity you could provide would be much higher
- Your legal and compliance teams would understand how policy has been implemented and could verify it
- Evolving policy would no longer be a scary endeavor
Why Has What You’ve Tried So Far Failed?
1. Granularity: Most databases only have table-level controls, which leaves you creating new tables or views to solve the access granularity problem. You are beholden to what your database supports from an access control perspective.
2. Scalability: The scale at which you must manage the access control requires an abstraction that will allow you to make simple, understandable changes that have large and sweeping impacts. Right now you have to manage this manually and specifically, and as that complexity increases, so does the time it takes to get data into the hands of your analysts and explain to Legal how data protections are happening. In most cases, this results in overall less data in your analysts’ hands because you just don’t have the time.
Solving for Failure 1:
Granularity
Snowflake has recently introduced a comprehensive set of data governance features. They are aimed to enable complex scenarios requiring highly-granular and dynamic access control:
Row Access Policies: The ability to filter rows through policy. This helps avoid complex transform jobs to separate data into tables (to then GRANT access to those tables separately) or represent those redactions in complex views and instead filter that data live at query-time.
Dynamic Data Masking: This goes beyond simply “hiding” a column, and provides the ability to mask columns to different values. Dynamic data masking is a column-level Security feature that uses masking policies to selectively mask data at query time. Data Engineers can make tradeoffs between privacy and utility, and analysts can query masked data while retaining some level of analytical value. For example, masking PII data like name or street address to a hash for analysts when they query a table of customers. By eliminating the need to create and manage data copies or views, data management and compliance are much easier.
Conditional Masking: Also known as cell-level security, this is similar to dynamic data masking except other columns in the same row determine whether that cell should be masked or not.
As of today, Immuta integrates directly with these Snowflake Data Governance capabilities.
Solving for Failure 2:
Scale
Immuta provides a policy authoring abstraction that can reduce policy authoring burden significantly with a high level of automation. This means that you can build a single policy in Immuta, representing a higher-level intent, and Immuta creates multiple Snowflake policies to carry out that intent in Snowflake. As a result, organizations are able to speed up and de-risk their ability to evolve data policies.
“We strongly believe in Snowflake’s vision for the Data Cloud. With the tighter integration between Snowflake and Immuta, we’re able to secure our data in Snowflake at a more granular level and easily enforce data security policies. Both technologies integrate seamlessly and work at cloud scale”, said Slava Frid, CTO and Platform Architect at Worldquant Predictive.
This is possible because Immuta can centralize metadata about your data and users, and using that metadata, build abstract policies in a scalable manner. At the click of a button, a policy can be created in Immuta and applied across Snowflake in a scalable manner. That policy will also be easily understood by non-technical users, and the policy can be easily modified without fear of the impact of that change, due to the clarity and conciseness of the policy representing a higher-level intent.
The example below is how a user would define a Row Access Policy in Immuta that will restrict access to rows that match the country to which the user has access. The user’s country is injected at policy-execution-time using the Immuta attribute-based access control (ABAC) model, making policies easily scalable by eliminating the need to create individual policies for every possible country. This policy will apply to all tables in Snowflake that have a column with the ‘Country’ tag, meaning you can write the policy once, and have it apply everywhere relevant:
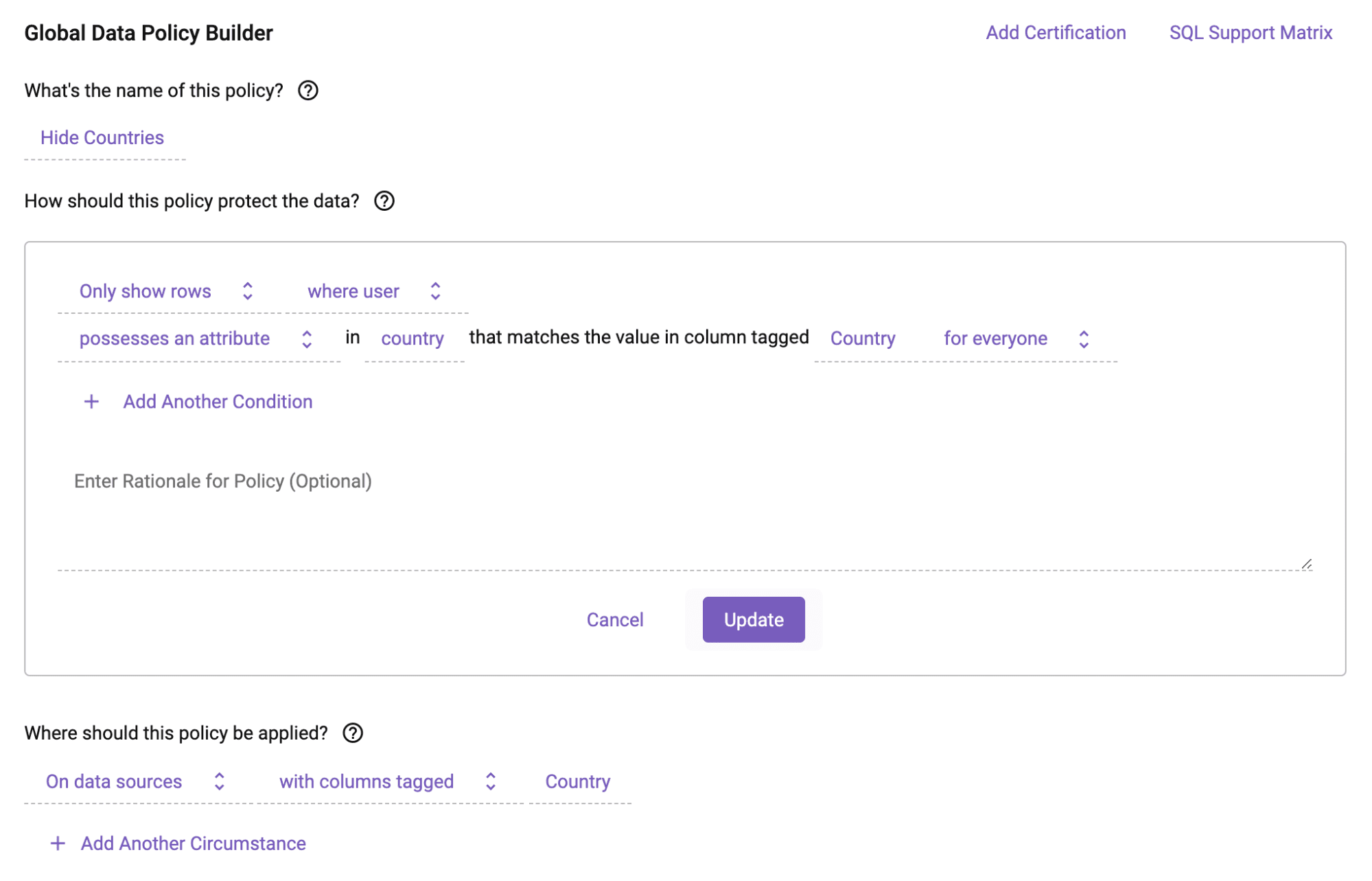
The policy builder is easy to use, empowering more people to govern data in Snowflake.
What is that ‘Country’ tag? Object Tagging is another Snowflake Data Governance capability with which Immuta integrates.
Snowflake Object Tagging (in public preview): Objects in Snowflake, like tables, columns, warehouses, databases, and users, can be assigned tags to track sensitive data for compliance, discovery, protection, and resource usage. Once created in Snowflake, tags are ingested into Immuta in near-real time, along with Immuta-discovered tags, to inform where policies should be applied.
In the previous example, Immuta will apply the Row Access Policy to all tables where there is a column tagged ‘Country’ in Snowflake. It is possible to build that policy ahead of time, and as columns are tagged with ‘Country’ in Snowflake, that policy will apply to those tables without any additional work from the user adding the tag.
We can build a conditional masking policy in the same easy way. This policy will mask using hashing the credit_card_number column when the value in the transaction_amount column is > 500:
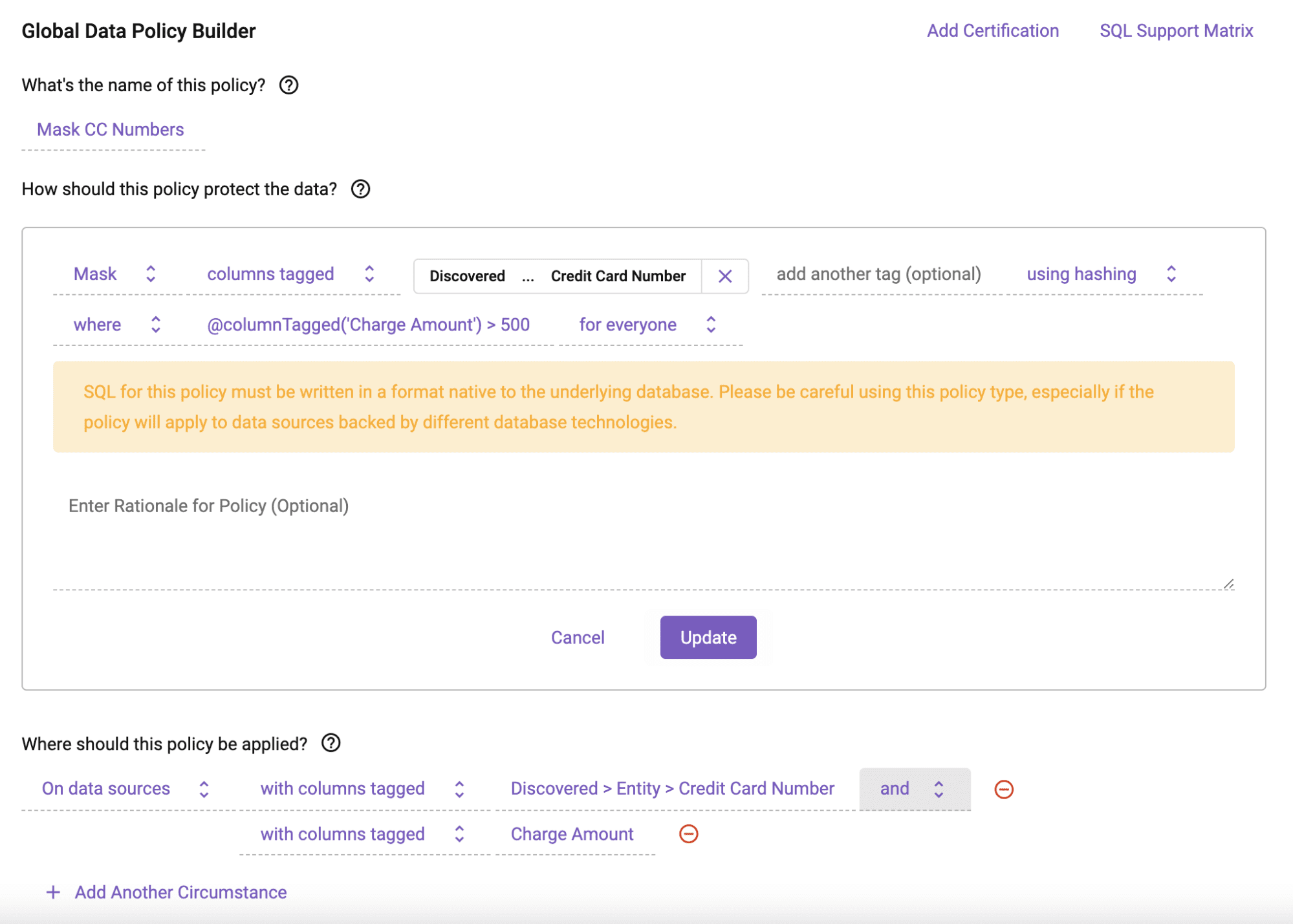
In this case, the policy leverages both tags from Snowflake object tagging, as well as Immuta’s “sensitive data discovery” tags. The Immuta discovered tag: ‘Discovered > Entity > Credit Card Number’ is used to specify which columns the conditional dynamic data masking policy should be applied to. The Snowflake tag, 'Charge Amount', is used as the condition column input for the creation of the Snowflake conditional masking policy.
Using the Snowflake tag ‘Charge Amount’ as an argument in the Immuta @columnTagged function avoids having to explicitly use the physical column name for the transaction_amount where clause, and instead uses its semantic tag reference. This allows the policy to work seamlessly across tables with differently named columns.
Policy-as-Code: Up until now, we have been showing the Immuta policies in the Immuta user interface (UI). However, those policies can be declared through an Immuta capability called “Policy-as-Code.” This allows data engineering teams to declaratively represent policy state in yaml or json files, source control and pull request (PR) those files, and push that state to Immuta through the Immuta CLI, which in turn translates those policies into the Immuta UI and pushes them down to Snowflake as Snowflake policies as described above. This is a powerful workflow that fits into existing DataOps automation within your Data Engineering teams, similar to infrastructure-as-code.
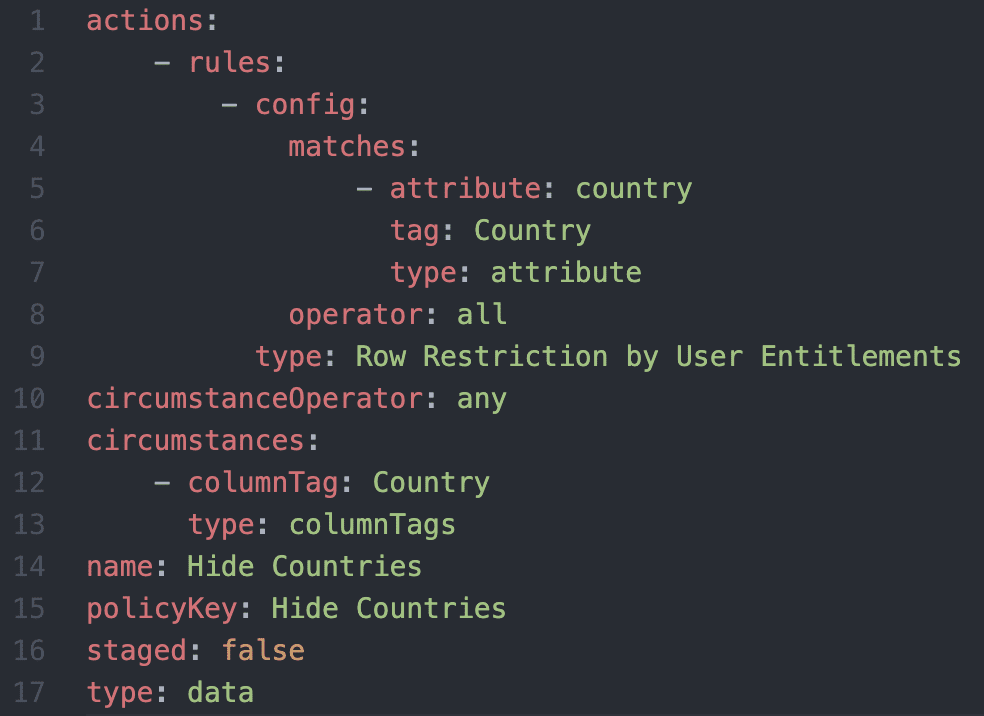
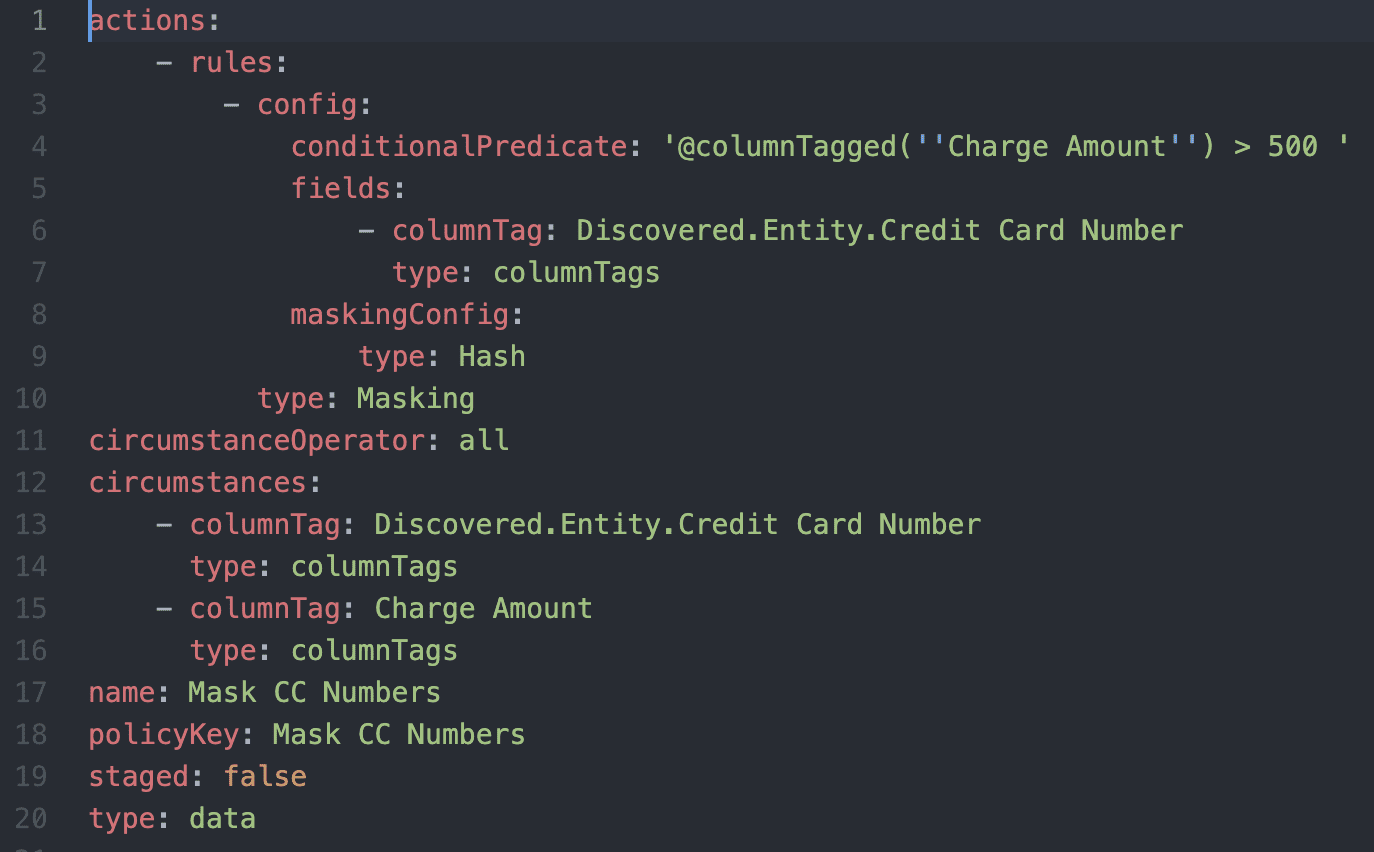
Here are those two policies represented as policy-as-code, remembering these single yaml policies can potentially impact many Snowflake tables for many different user scenarios with just this simple declarative yaml representation:
Hide-Countries.yaml:
Mask-CC-Numbers.yaml:
Benefits:
By integrating Immuta with Snowflake’s Data Governance capabilities, you gain:
- Granularity: By leveraging the powerful Row Access Policies, Dynamic Data Masking, and Conditional Masking features in Snowflake.
- Evolvability: By taking higher-level policy intent and prescribing it into a simple to understand abstraction, this makes evolving policies a less scary proposition, you can understand how to make that change, and the impact of that change clearly.
- Scalability: The policies are built in a way that dynamically injects the user attributes at policy invocation, avoiding the need to build a policy for each user scenario. For example, you built a single Row Access policy that works for all country combinations, rather than a Row Access policy per country. Immuta policy definitions also leverage Snowflake’s object tagging feature to push policy to all relevant tables/columns.
- Comprehensibility: Even though you can build policy through the policy-as-code mechanism, those policies are clearly represented and rationalized in the Immuta UI, allowing non-technical Legal and Compliance users to verify policy is being applied correctly without having to understand yaml (Immuta policy-as-code) or SQL (Snowflake policy).
- DataOps: Policy management can fit into your existing DataOps/CD workflows through Immuta’s policy-as-code feature.
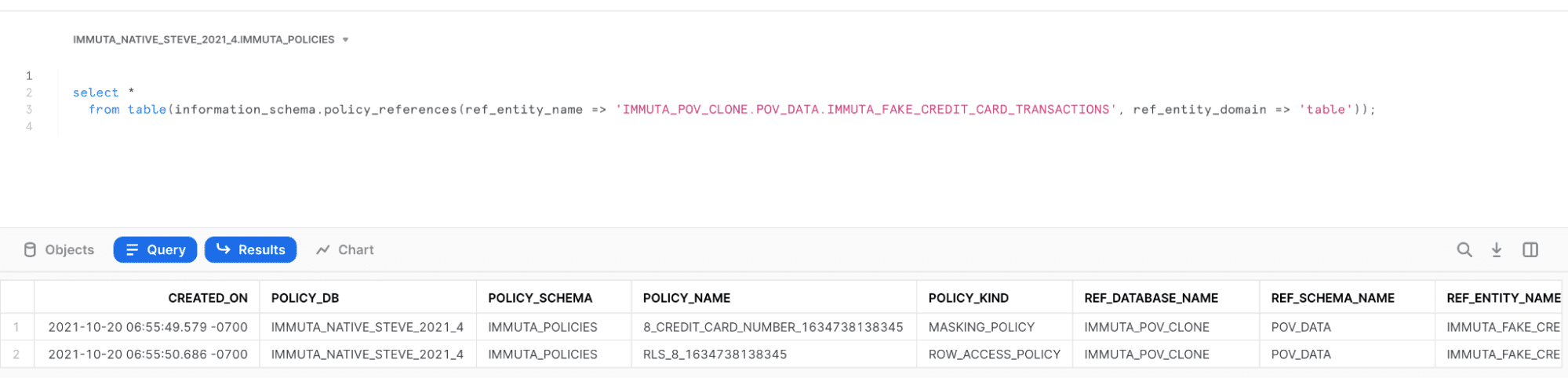
- Interoperability: Since Immuta is simply administering Snowflake policy through an abstraction, those policies will continue working even without Immuta. This is an example query showing the Snowflake data policies created from the above examples (all policy administered by Immuta is stored in a single policy database), as you can see, a MASKING_POLICY and ROW_ACCESS_POLICY has been applied to the IMMUTA_FAKE_CREDIT_CARD_TRANSACTIONS table.
There you have it – by combining Snowflake with Immuta, you are able to “turbo-charge” the Snowflake Data Governance capabilities to meet extremely complex access controls requirements in your own business.
Watch this demo to see it in action, or get started with a self-guided tour.



