A Guide to Automated Data Security
In Databricks Using Immuta


For data engineers, the effort required to wrangle access policies grows exponentially as the complexity of data security increases.
High table access segmentation necessitates managing a correspondingly large number of roles and grants. Data that is segmented down to the row level, for example, may require a series of transforms or view logic to split those rows into individual tables. To further complicate things, masking columns while still providing some level of utility may lead to an entirely new set of views, functions, and even custom UDFs or complex transforms.
These security and access control goals quickly become unmanageable as they scale. Not only does this put an additional burden on data engineers, but it also increases the chance that a simple mistake could expose sensitive data. Rather than focusing on data engineering responsibilities, most of your time is spent managing data security.
What if you actually did data engineering every day at work rather than manage data security? What if you had a data security platform that controlled data access in a way that was scalable, manageable, understandable, and granular, so you didn’t have to? What would you be able to get done that you can’t now?

You most likely would:

In Databricks Using Immuta
If you’ve put people and processes in place to manage data security, you might be wondering why keeping up with access control management is still interfering with your day-to-day data engineering responsibilities. It boils down to a lack of granularity and manageability.
Unity Catalog from Databricks provides a unified governance solution for all data and AI assets in your lakehouse on any cloud. Immuta’s integration with Unity Catalog helps Databricks users seamlessly overcome boundaries to granularity and manageability.
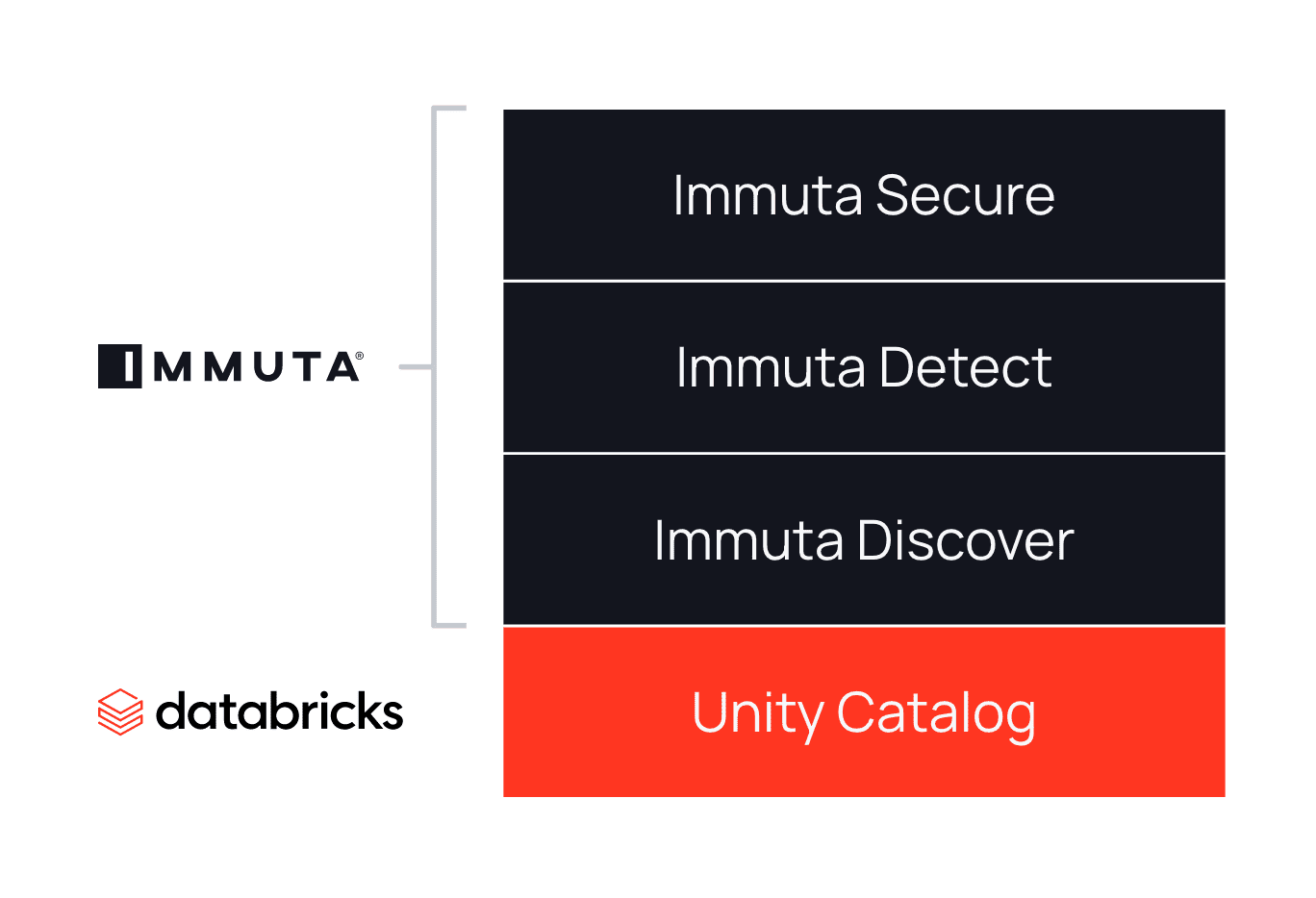
To solve the granularity problem, Unity Catalog will be introducing support for row-level and column masking controls (currently, it supports table-level controls at the Unity Catalog level). Immuta independently enables fine-grained access controls, including row-level security and column masking, and our team has worked closely with the Unity Catalog team on the design of these controls for Unity Catalog. This will ensure that our scalable attribute-based access control (ABAC) model can be injected into the Unity controls, which you’ll learn about next.
In addition to these granular controls, Unity Catalog provides centralization of user and metastore management. This allows separation of duties between those who manage users and access across all Databricks workspaces at once, from those who manage clusters and SQL endpoints. This puts the new granular controls in the hands of the appropriate users.
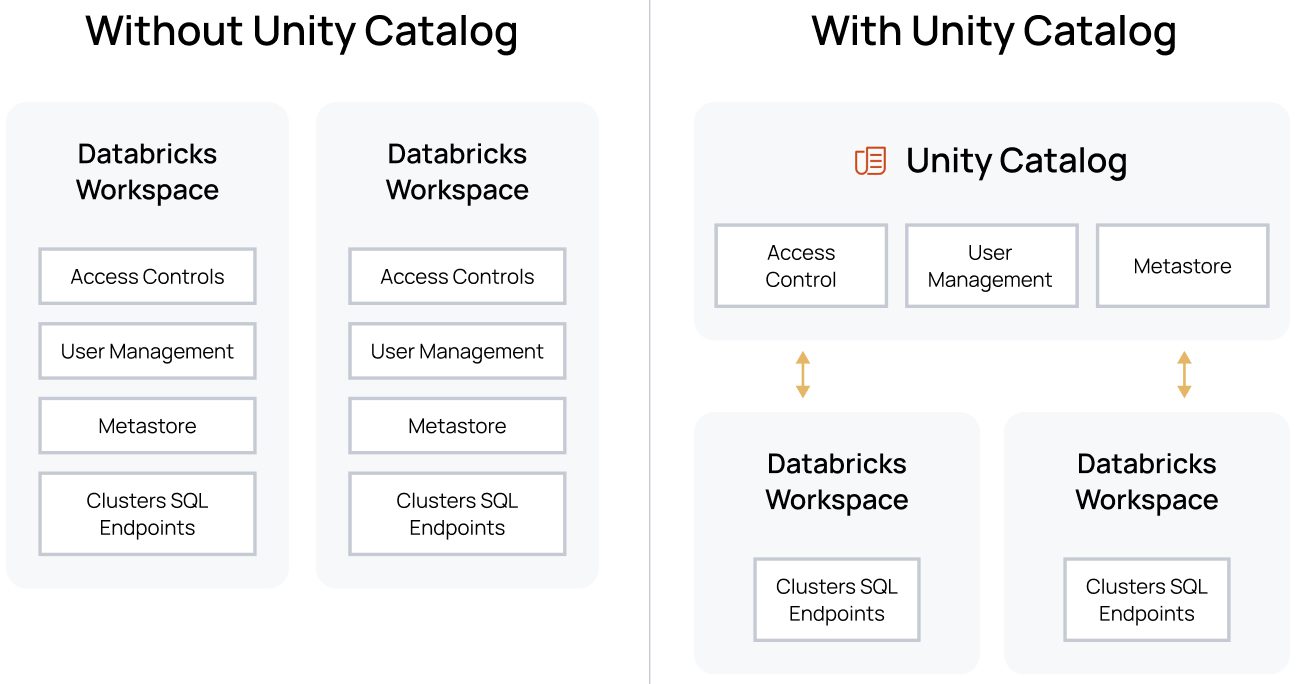
Prior to Unity Catalog, Immuta had to solve the granularity problem by building plugins in Spark and views in Databricks SQL to enforce real-time policies. These integrations are still in production today across many customers, but will be transitioned to the Unity Catalog controls once released, creating a consistent and non-invasive security architecture:
While centralized granular controls certainly create a more powerful access control experience in Databricks, you are still left with the manageability problem. Having to build policies manually, one-by-one, across hundreds or thousands of tables, users, and policies can quickly explode into an intractable problem ripe for automation. This is why Immuta exists.
Manageability is broken down into three components: Discover, Detect, and Secure.
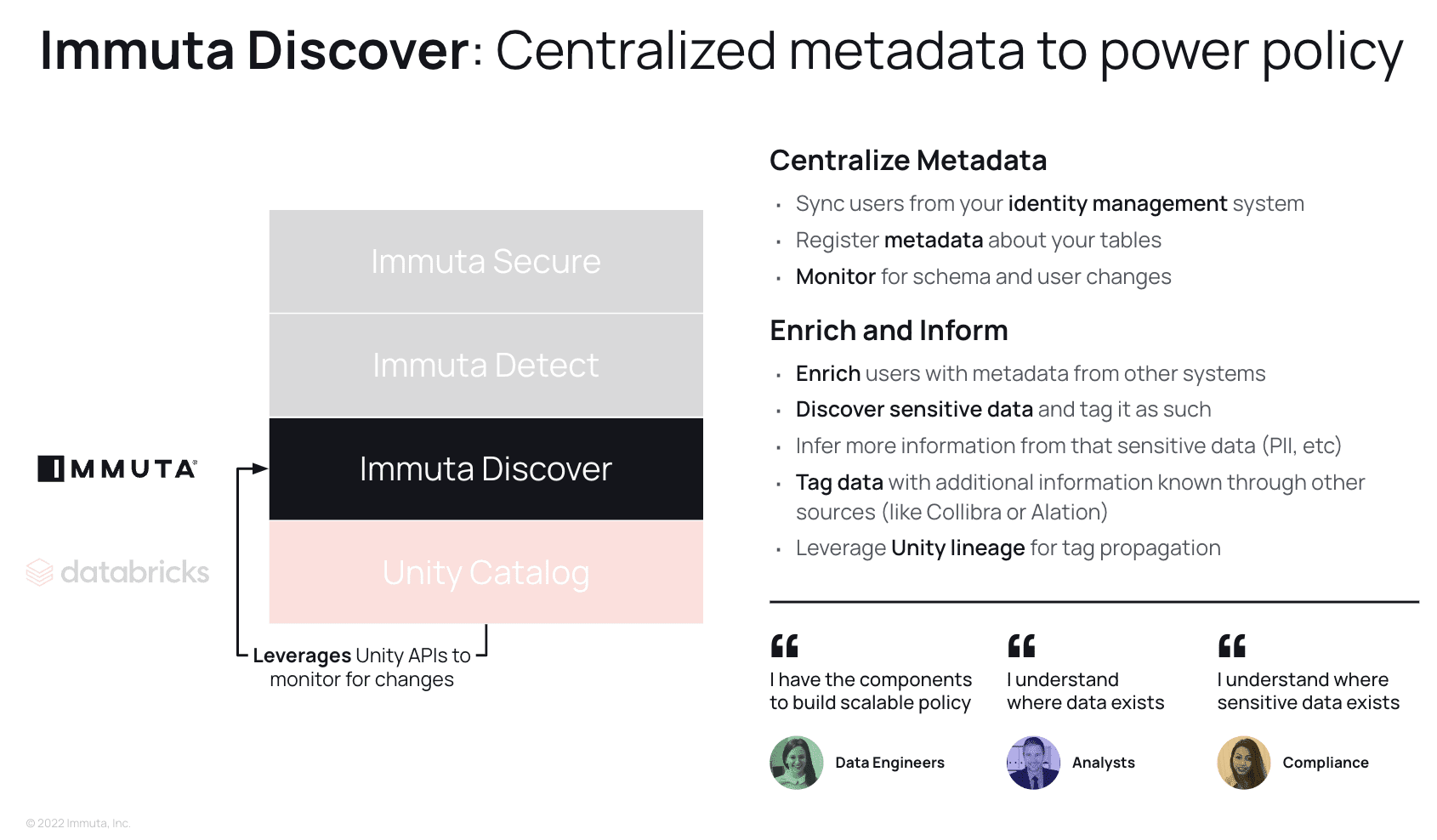
Discover is all about centralizing metadata management in order to power policy automation and orchestration. However, it also has side benefits in that it can inform your analysts and compliance teams of where all of your data, and most importantly sensitive data, exists.
Immuta synchronizes all your user and data metadata, creating a unified layer that describes data as abstract entities and decorates your users with metadata. This metadata can come not only from your databases or identity managers, but also from any system across your organization. Data is scanned and tagged for sensitive entities, such as credit card numbers or social security numbers, and additional tags such as personally identifiable information (PII) can be inferred based on what is discovered. Using Unity Catalog’s new lineage feature, those discovered tags can be propagated throughout all future derivative data products to allow proactive policy enforcement.
In summary, Discover creates the key components of an ABAC model:
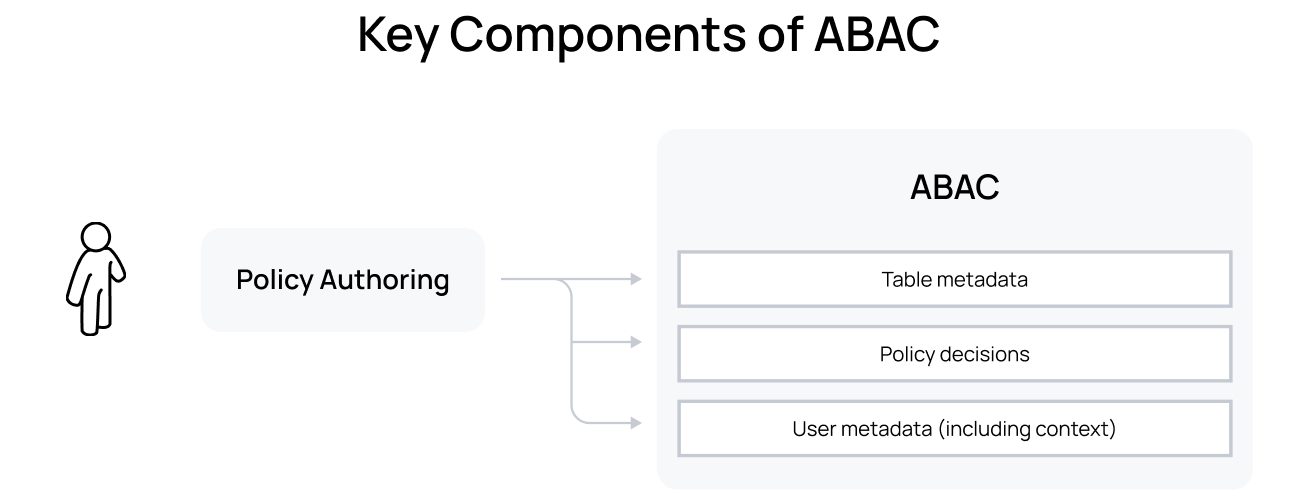
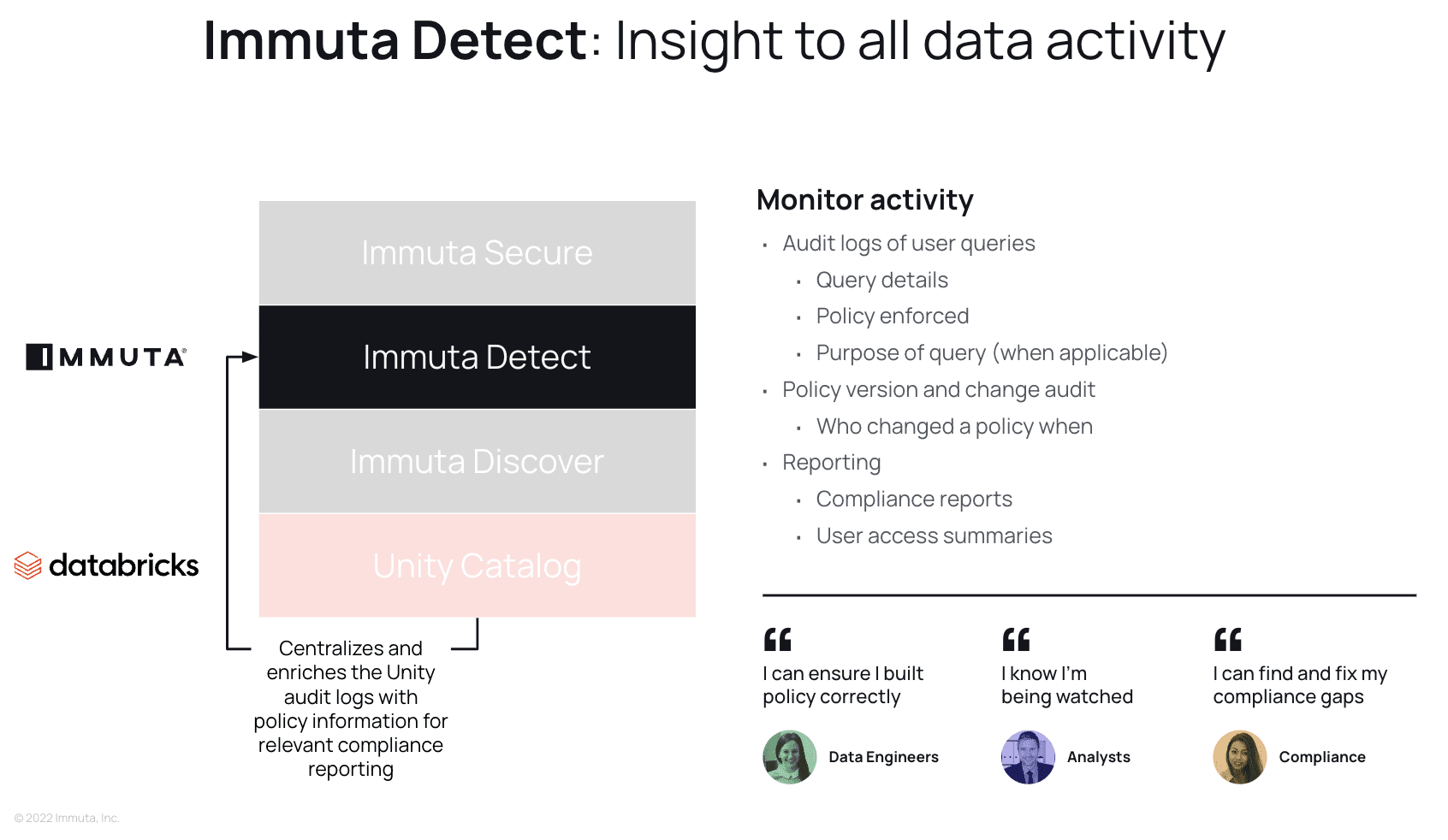
Next, we have Detect. Compliance teams need an enriched query audit trail in order to build meaningful reporting to prove that policies and data usage adhere to regulatory requirements. This not only includes knowing what queries have been run on which tables, but also which policies were enforced at time of access. All policy actions are monitored and logged, so a clear version history of a policy and its authors is available for reporting. Understanding which users have access to what data at any given time is critical in order to highlight and mitigate risks with Immuta’s Secure capability. Additionally, Immuta’s Unified Audit Model (UAM) provides a consistent audit log structure and metadata across data access audit events from Unity Catalog and Immuta, which centralizes and simplifies filtering and analysis.
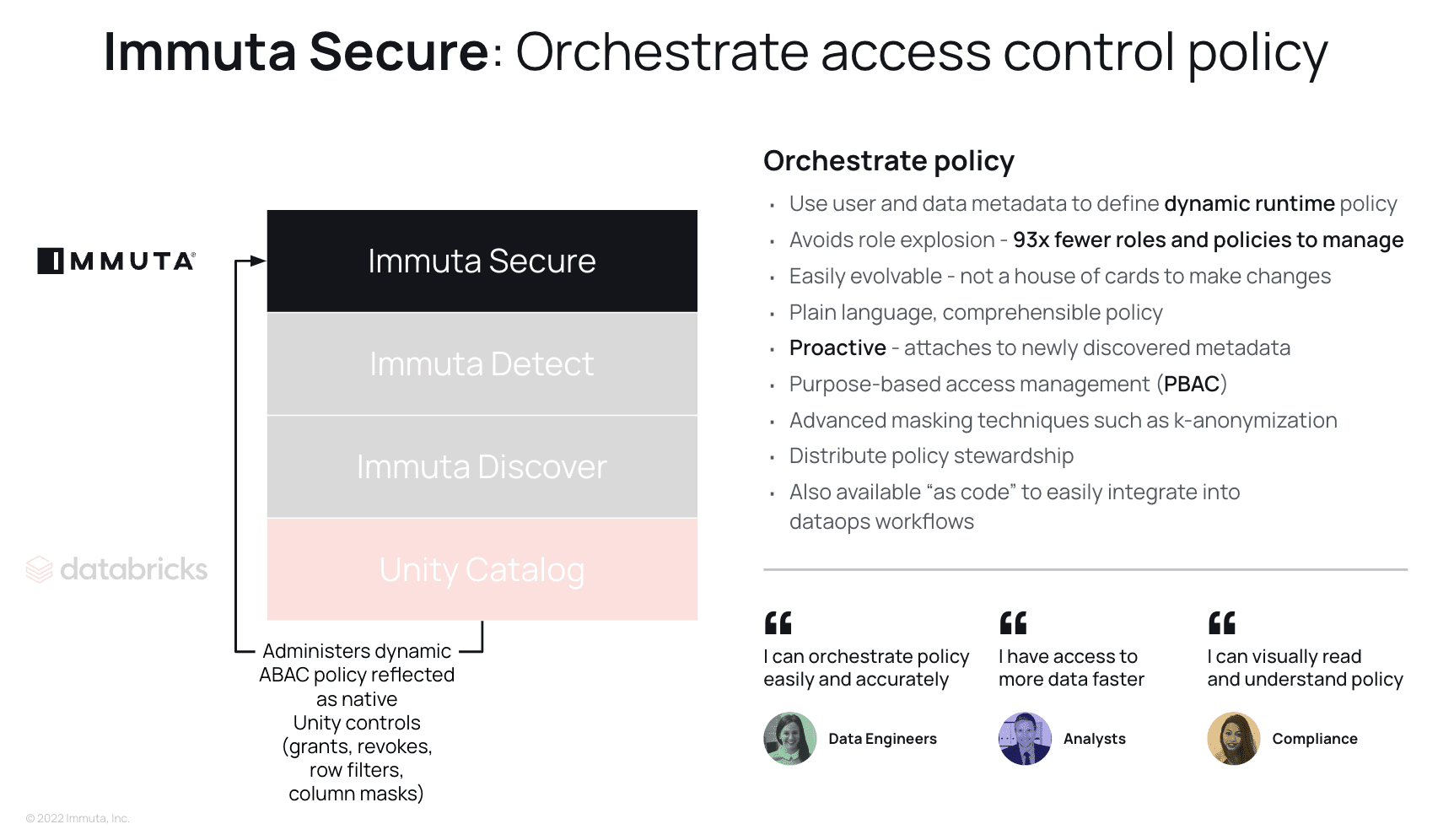
The final piece of the puzzle is Secure, which focuses on streamlining policy authoring, orchestration, and privacy. Immuta provides a policy authoring abstraction that can reduce policy authoring burden significantly with a high level of automation. This means that you can build a single policy representing a higher-level intent in Immuta, and Immuta creates multiple Unity Catalog policies to carry out that intent in Databricks. As a result, organizations are able to create and evolve data policies faster and with minimal risk.
The example below shows how a user would define a Databricks row-level security policy in Immuta that restricts access to rows matching the country to which the user has access. The user’s country is injected dynamically at policy execution time using Immuta’s ABAC model, making policies easily scalable by eliminating the need to create individual policies for every possible country. If you had to do this without Immuta, it would result in potentially hundreds or thousands of roles and policies to manage: one for each possible country combination that may exist in your organization. This policy will apply to all tables in Databricks (or other databases) that have a column with the Discovered.Entity.Location tag, meaning you can write the policy once, and have it apply on every relevant table with that column, even when that tag is discovered in the future:
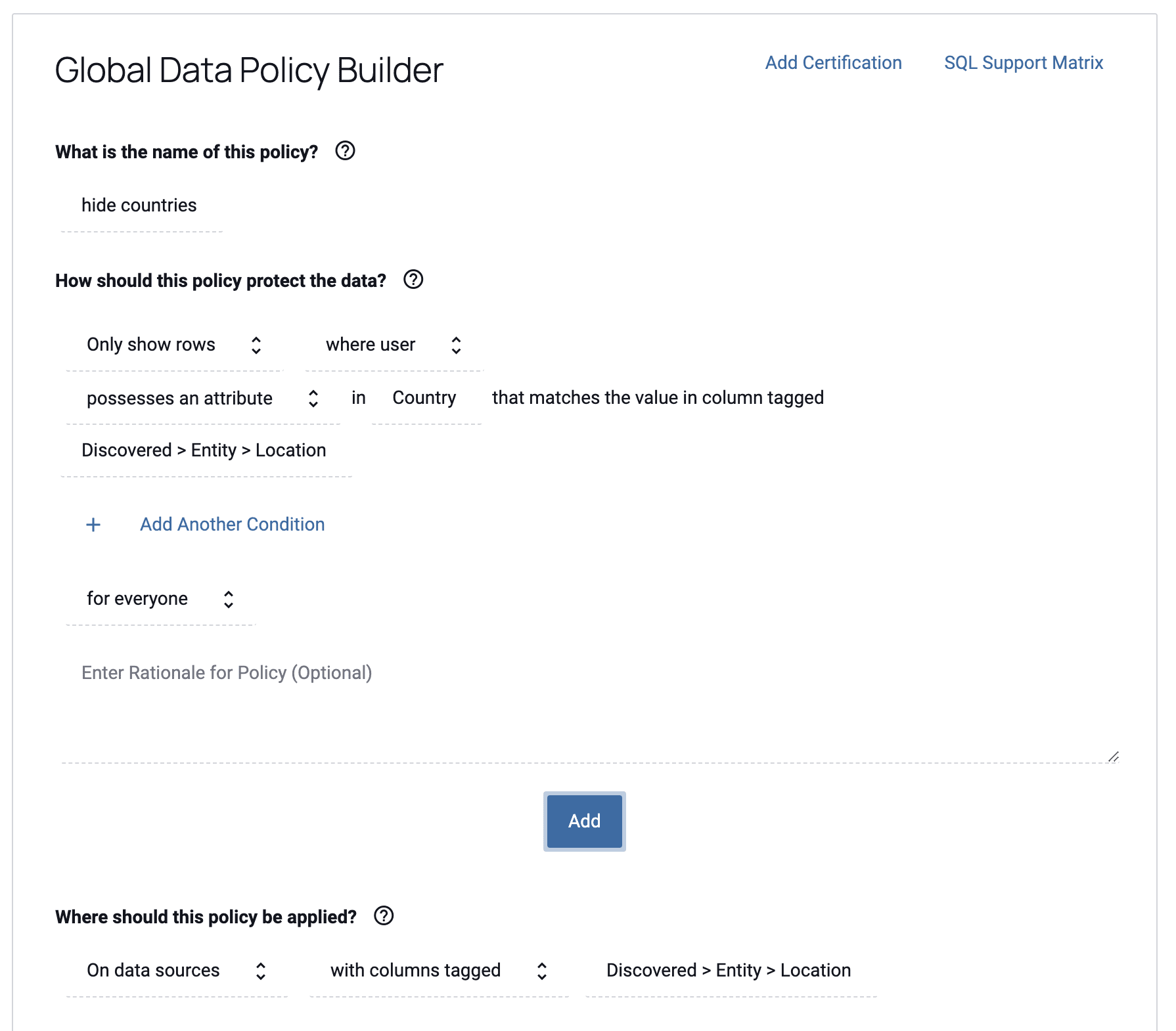
This policy will administer the native Unity Catalog controls in Databricks, avoiding manual, burdensome, and error-prone administration by the data engineering team.
In addition to ABAC’s scalability and tag-based policy authoring, Immuta provides:
These same policies can be represented through an Immuta capability called “Policy-as-Code.” This allows data engineering teams to declaratively represent policy state in yaml or json files, source control and pull request (PR) those files, and push that policy state to Immuta through the Immuta CLI, which in turn simultaneously translates those policies into the Immuta UI and pushes them down to Databricks as Unity Catalog policies, as described above. This is a powerful workflow that fits into data engineering teams’ existing DataOps automation, similar to infrastructure-as-code.
In either case, policies are represented in Immuta in human-readable form so that compliance teams can easily understand what policies are doing across your data estate.
Unity Catalog enables Databricks customers to centrally manage their access policies directly in Unity Catalog, across all workspaces and workloads running on Databricks lakehouse platform. For customers with a large number of or high complexity of data policies, the combination of Immuta and Unity Catalog delivers the best of both worlds – granular enforcement and manageability at scale.
Unity Catalog is the foundation that Immuta has always needed, providing access control primitives that Immuta can administer to create a modern data security and access control framework. By combining Unity Catalog with Immuta you create an environment that empowers data engineers to build manageable, scalable, and provable policies, which in turn gets more data in the hands of your analysts more quickly and allows your compliance teams full insight into the data platform’s policies.
Check out this demo to see exactly how Unity Catalog and Immuta work together.


