A Guide to Automated Data Access
In Databricks Using Immuta


Immuta and Databricks have deepened our strategic partnership and augmented our native product integration by announcing Immuta’s support for Databricks SQL Analytics and deployment on Google Cloud. These are the latest capabilities offered to joint Immuta and Databricks customers, which also include metadata-driven policy authoring, fine-grained and attribute-based access controls, and most recently, expanded access control for R and Scala. The breadth of features offered to Databricks users enables streamlined data access governance and secure data analytics, and earned Immuta recognition as a Databricks 2020 ISV Rising Star Award winner.
As more organizations are embracing Databricks’ data lakehouse architecture, they need a way to centralize data access control across Data Science Workspaces and SQL Analytics to efficiently scale user adoption. This includes a critical need for fine-grained access controls, such as row-, column, and cell-level security, and dynamic data masking capabilities like PETs, which Immuta offers natively on the Databricks platform. Additionally, Databricks’ availability on Google means organizations can adopt the unified data platform on Google Cloud, with Immuta providing a security layer that enables customer flexibility and choice. Now, Databricks users can confidently and securely access data across SQL Analytics and Data Science Workspaces deployed on any public cloud. Immuta is the first platform to provide best-in-class data access governance across all Databricks workspaces on any public cloud.
Let’s take a closer look at these features.

In Databricks Using Immuta
To understand how Immuta supports Databricks, we’ll start with how the two platforms work together. Below is a snapshot of the current architecture.
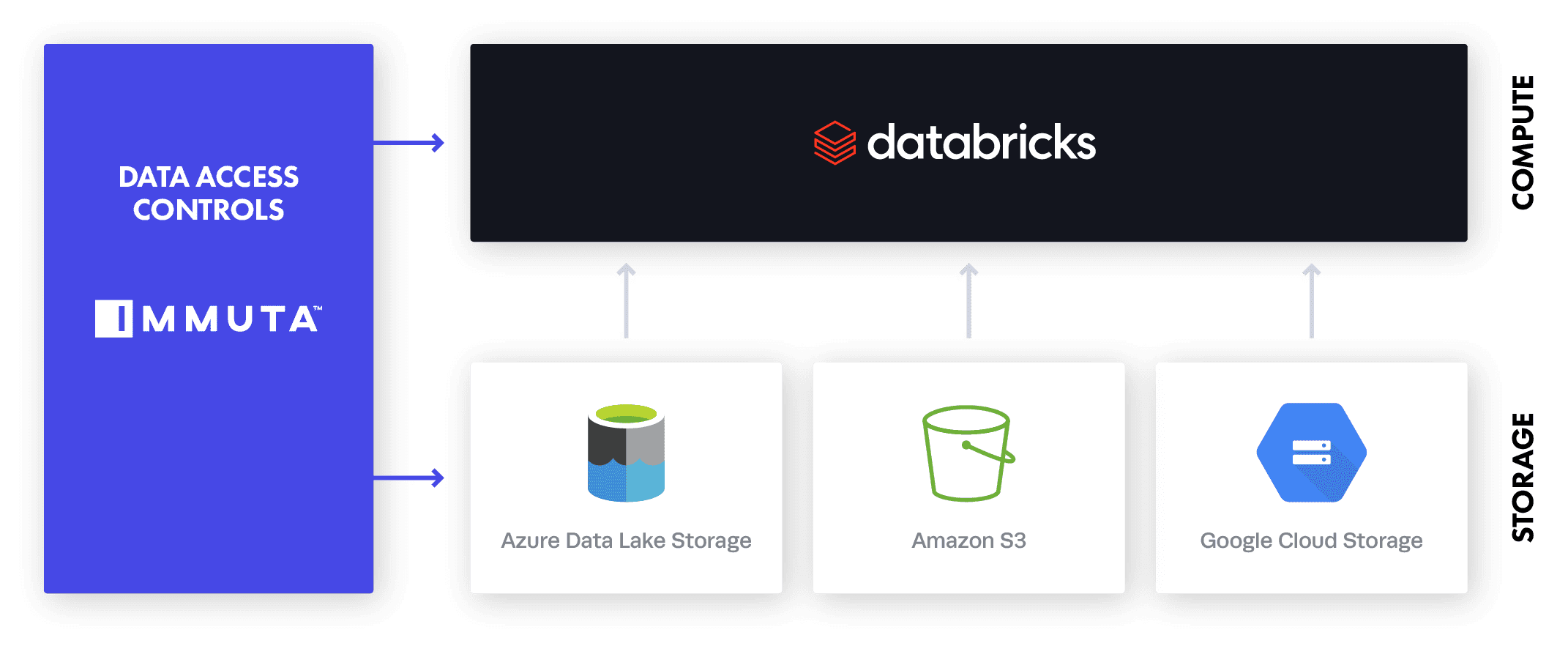
Immuta acts as a centralized governance layer that applies data access controls dynamically at query time, without risk of unauthorized data access. All query processing is done 100% in Databricks.
Databricks’ new release adds SQL Analytics to the existing compute layer, but with Immuta’s SQL Analytics support, data access is governed consistently across SQL Analytics and Data Science workspaces. This dynamic approach removes the burden on data engineering and DataOps teams to manually ensure that data for all types of workspaces is appropriately protected and enables organization-wide scalability.
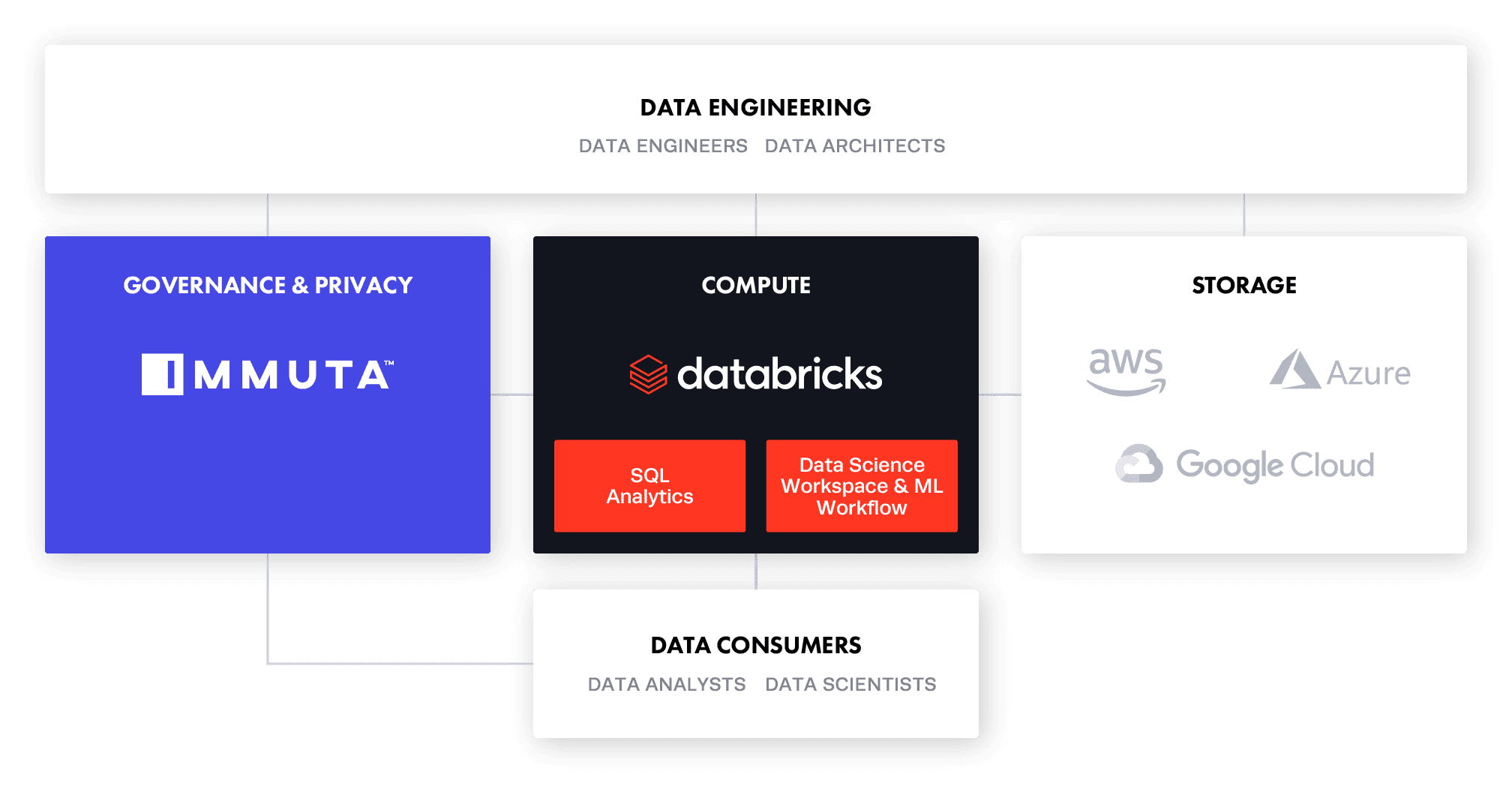
Unlocking sensitive data for use is a challenge on any cloud data platform. We enable Databricks teams to centralize data access governance across Data Science Workspaces and SQL Analytics to safely migrate more workloads containing sensitive data to Databricks.
Immuta provides four core solutions to help enable sensitive data use in SQL Analytics:
1. Attribute-based access control
Immuta’s attribute-based access control leverages traits about the user, data, environment, and usage purpose to dynamically enforce data access control policies at query time. This avoids role explosion and other limitations that are common with static policy attributes in Hadoop-based tools like Ranger, and instead uses policy variables to streamline role management and scale policies across hundreds of roles. Immuta’s attribute-based access control has enabled data engineers and architects to reduce roles by 200x.
2. Dynamic data masking
Manually removing or anonymizing data is a risk-prone approach to data protection. Our dynamic data masking for Databricks SQL Analytics allows DataOps teams to mask, anonymize, or randomize data across hundreds of tables without copying data, and to execute secure cloud migration of on-premises workloads to Databricks, even when sensitive data is involved.
3. Explainable policy builder
When scaling user adoption across SQL Analytics and Data Science Workspaces, transparency is key for collaborative data governance. Our explainable policy builder provides that transparency for non-technical stakeholders on governance, legal, and compliance teams so they can easily understand and weigh in on access control management. Policies displayed in plain English, yet authored optionally through the Immuta APIs, reduce the time and cost of writing custom code. Data engineers are therefore able to manage policies using code to integrate with existing DataOps toolchains.
4. Sensitive data discovery
Combing through data to identify direct, indirect, and sensitive attributes is like trying to find a needle in a haystack. The risk of missing sensitive data is high — and so are the consequences. Immuta’s sensitive data discovery feature automatically detects, classifies, and tags data that has been registered within Databricks from any cloud, now including Google Cloud Storage, and that contains direct and indirect identifiers, as well as other potentially sensitive information. Tags map to corresponding access control policies for swift policy implementation, data protection, and compliance at scale.
Immuta’s best-in-class solution offers Databricks users access and privacy controls across Databricks, explainable policy authoring, streamlined role management, and increased data warehousing use cases with sensitive data, enabling DataOps teams to maximize the security, utility, and value of their data — without sacrificing time or efficiency.
Immuta is the first data access governance solution on the market to provide support for Databricks on Google Cloud. This capability builds on existing support for AWS and Azure, giving Databricks users expanded flexibility with support to deploy across any cloud. As Databricks shops increasingly embrace the lakehouse architecture, as well as multiple cloud providers, Immuta’s support for Google Cloud enables them to safely unlock more sensitive data use cases.
With these capabilities, Immuta provides Databricks teams with expanded data access governance capabilities, and is the only platform to support all Databricks workspaces on any public cloud. This means Databricks customers are able to get consistent access and privacy controls across the Databricks lakehouse architecture, without managing roles, views, or data copies. As organizations share data across SQL Analytics, Immuta uniquely empowers new policy stakeholders in the lakehouse — beyond IT admins — to manage policies, scale access, and unlock more data for use.
Our explainable policy builder provides data owners across lines of business with domain knowledge of their specific requirements for policy management, while “policy as code” capabilities that integrate with existing DataOps toolchains allow data engineers to efficiently operationalize and manage global policies. This combination increases data engineers’ impact and empowers organizations to optimize their work in Databricks and drive meaningful business results.
To see all the ways Immuta helps Databricks customers maximize their data’s value, request a demo.


