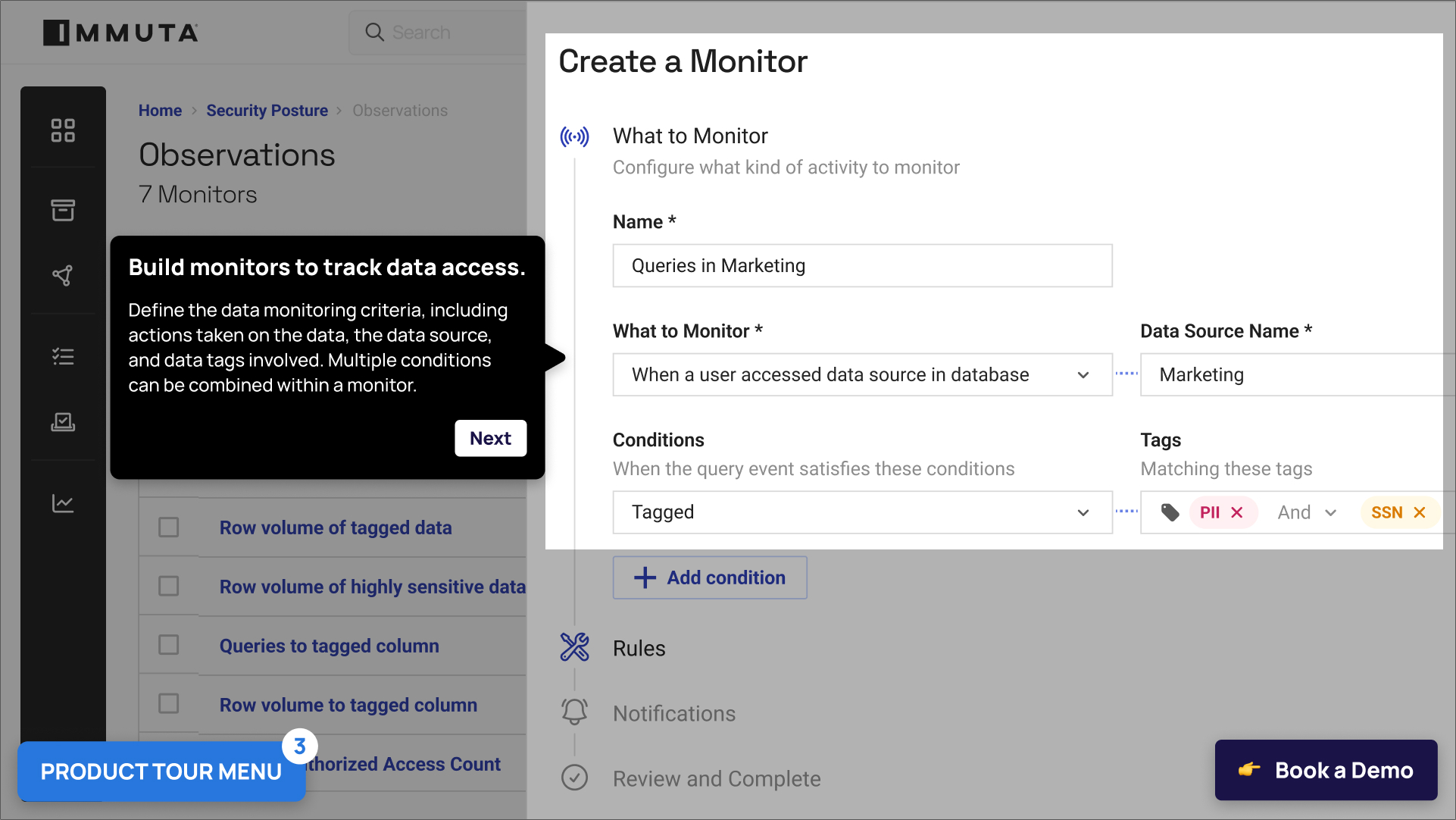
Govern Once. Enforce Everywhere.
Immuta empowers data governors and stewards to define global access policies across any platform — without code or tickets.
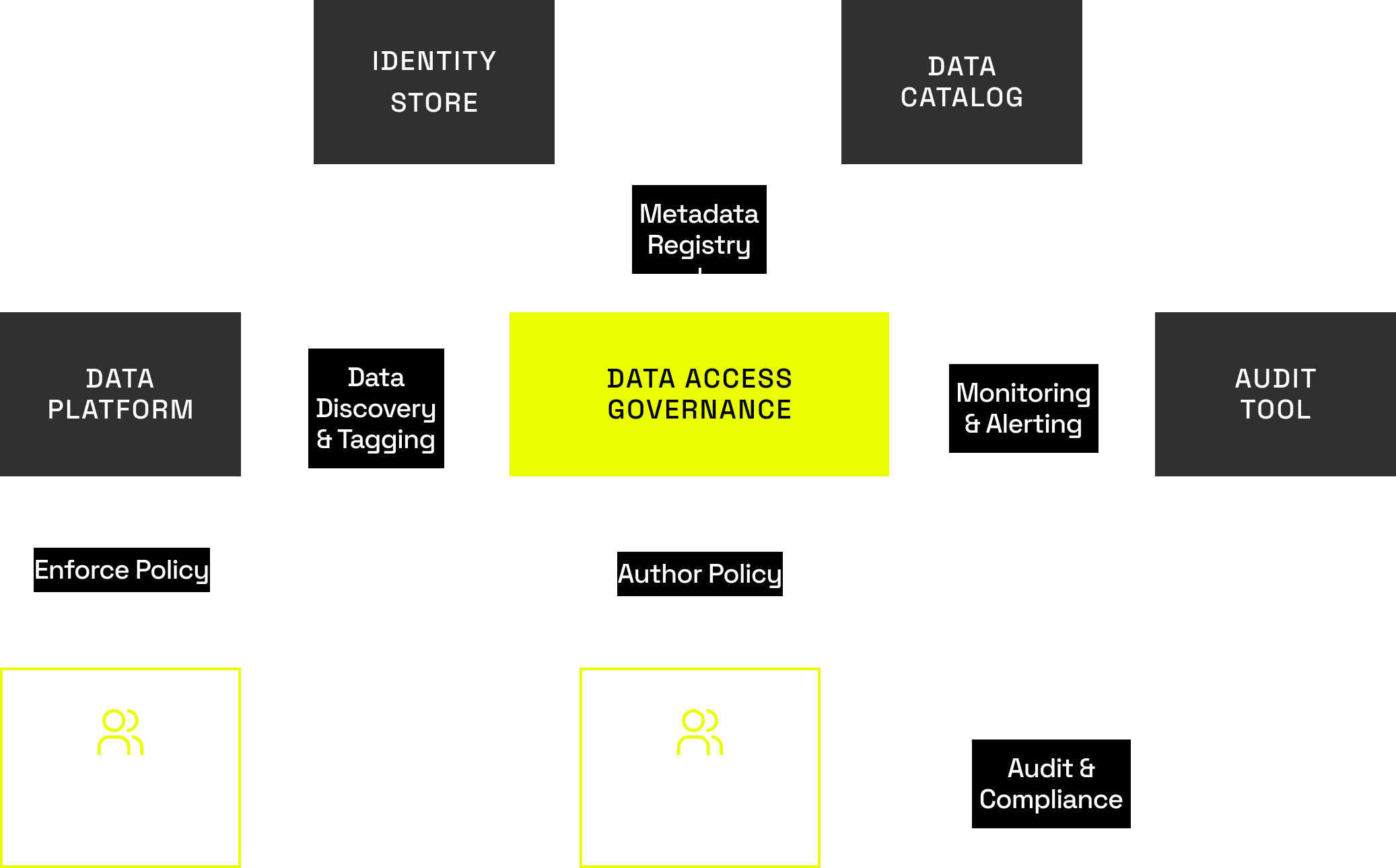
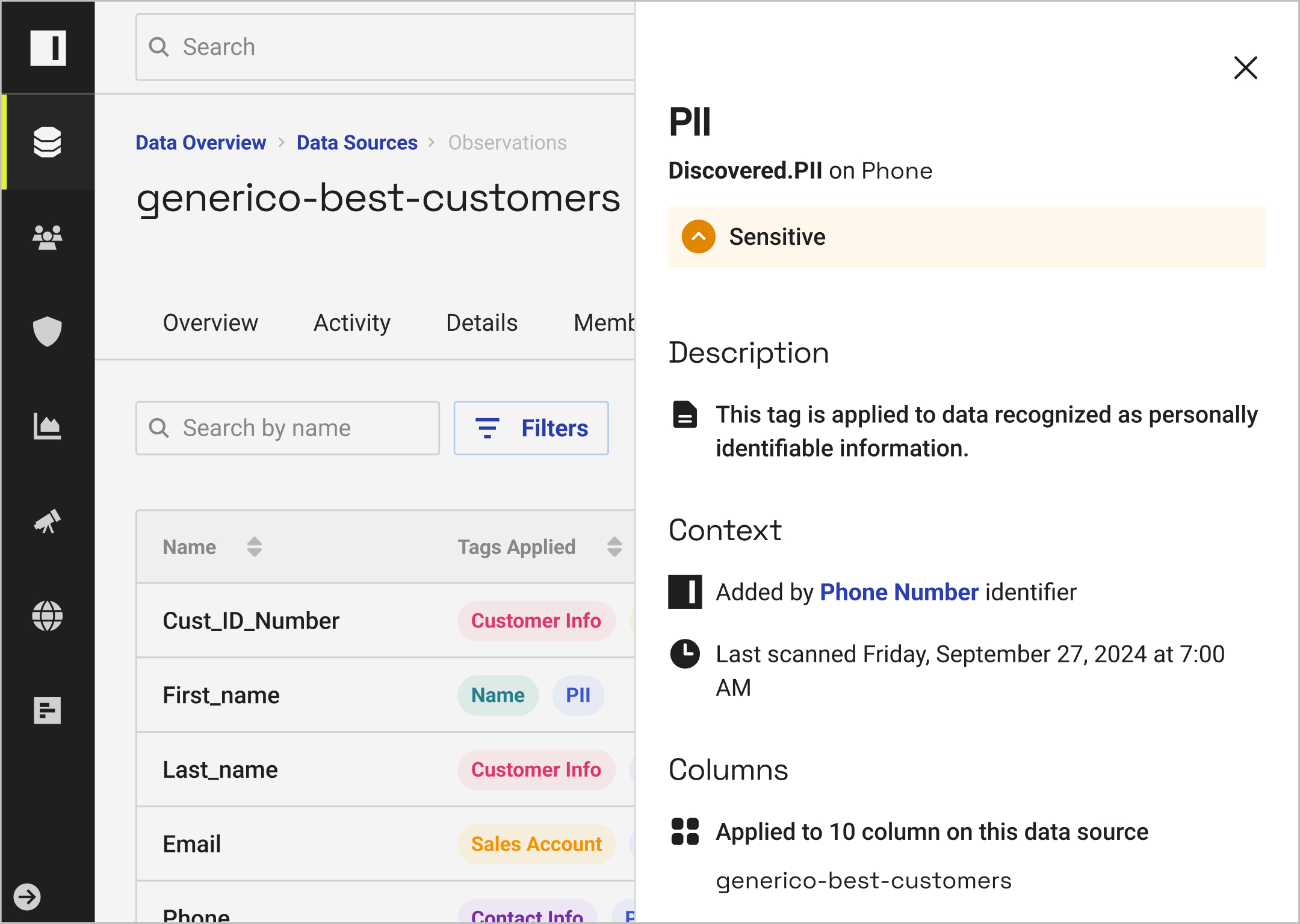
Automatically discover and classify data and data products to drive policy enforcement — while enabling search and managing tag integrations with external catalogs.
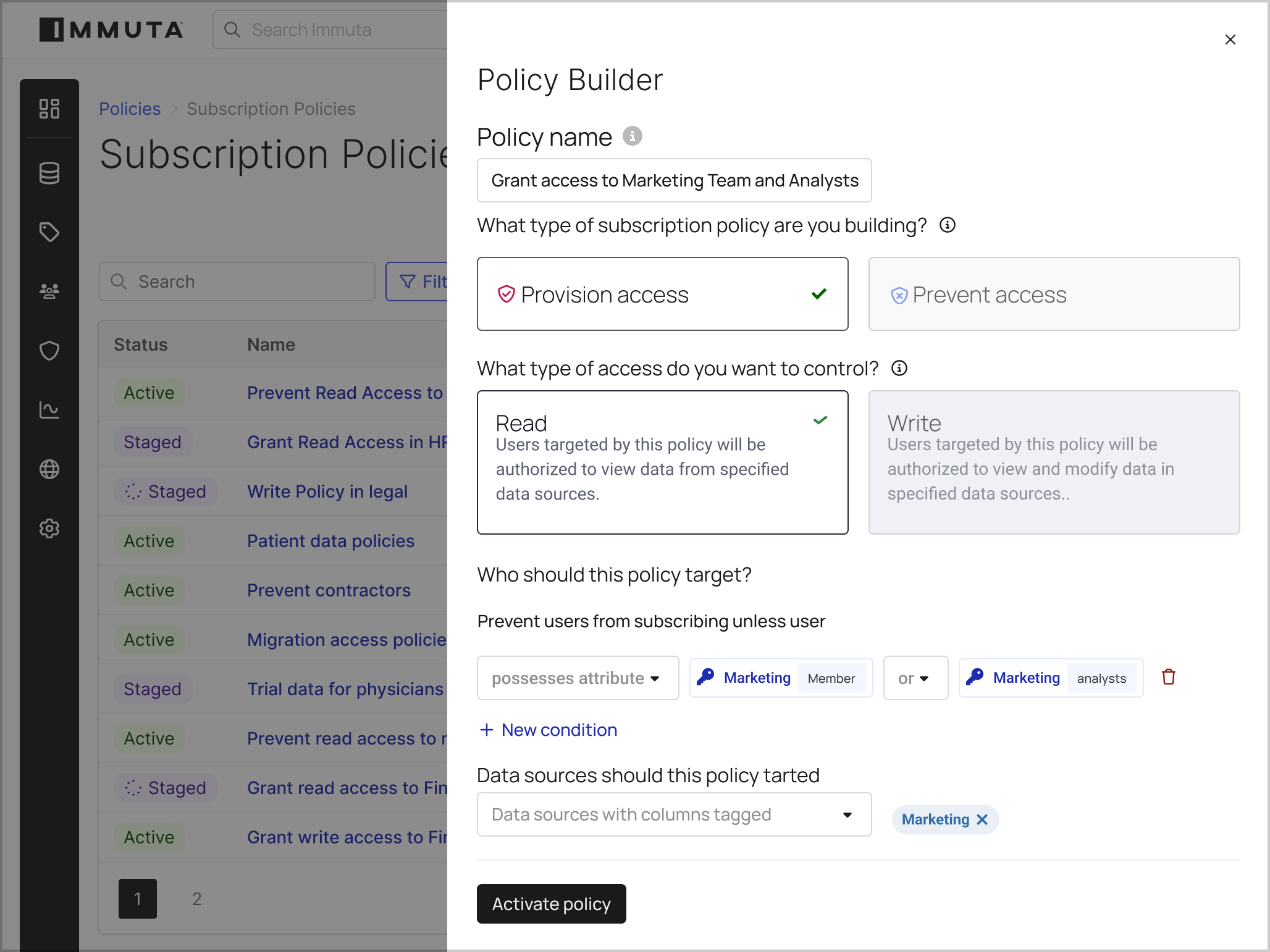
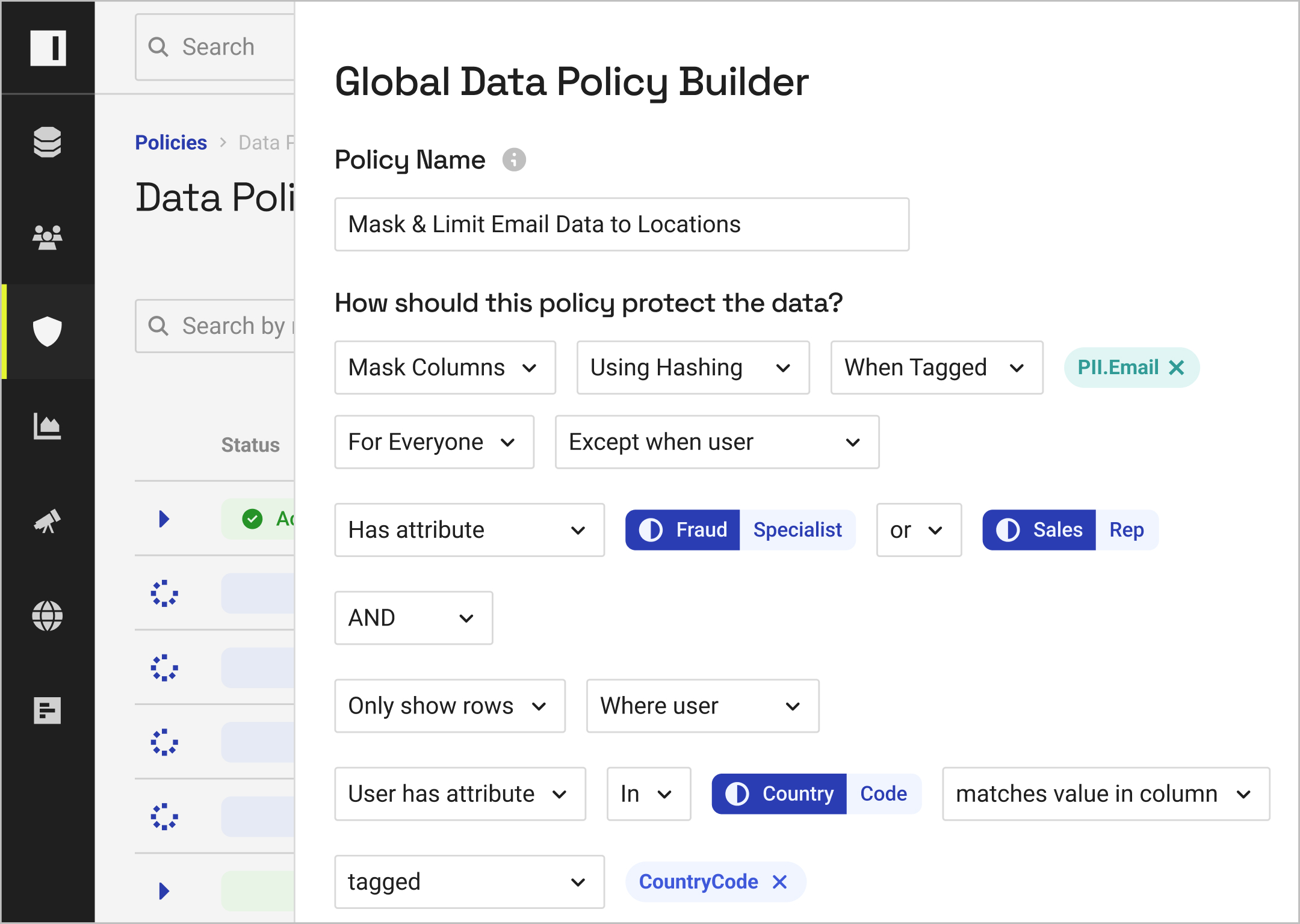
With the ability to build cross-platform data access policies in natural language, you can eliminate policy bloat and the need for repetitive, platform-specific policy creation.
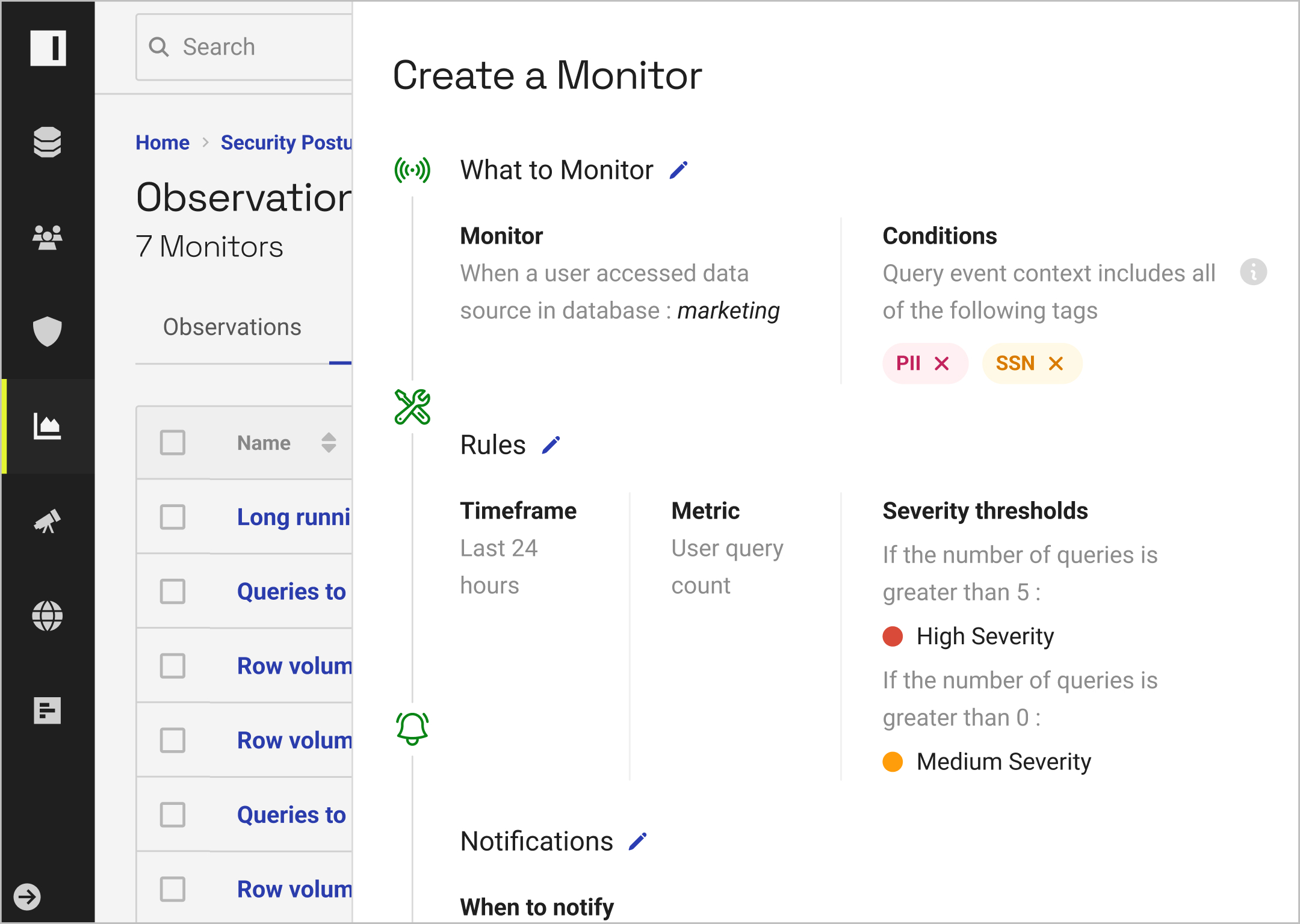
With real-time monitoring and unified reporting, you can understand how data is being accessed and used at any time.
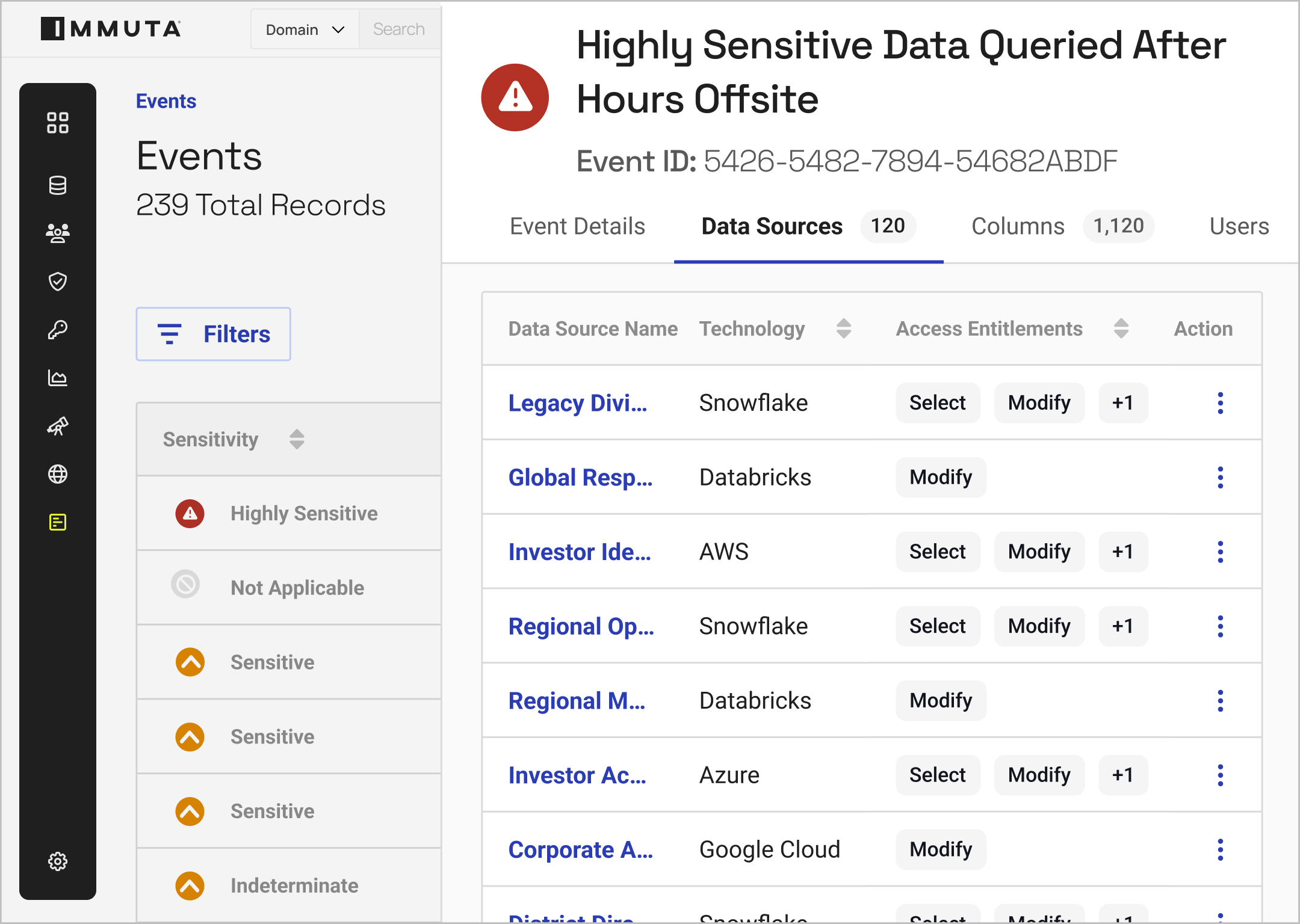
By building reports based on policy outcomes and user activity, you can streamline the auditing process and easily prove compliance.

Natively connect to multiple data platforms so you can scale data access provisioning without impacting speed or performance.

Empower non-technical users to build, understand, and approve policies with natural language commands.

Ensure consistent policy control across multiple cloud data platforms, without adding management overhead.

Define domains and delegate approvals to data stewards to eliminate bottlenecks and speed access to data.

As companies grow, so do their demands for data. In this interview, Chief Data Officer Paul Rankin dives into the technical challenges of data governance, including common scalability and findability obstacles.



When licensees use Immuta SaaS services to manage access to licensee personal data, Immuta acts as a data processor. Licensees may act as data controllers or data processors, and Immuta acts as a data processor or sub-processor. Immuta contractual terms incorporate Immuta’s commitments as a data processor. Our security controls are described below and our list of sub-processors is available here.
When Immuta processes personal data and determines the purposes and means of processing that personal data, it acts as a data controller. As a data controller in relation to Immuta SaaS services, Immuta usually processes account information for account registration, administration, billing, and fraud prevention, as well as usage data for service optimization, service improvement, and fraud prevention.
For more information about how Immuta processes personal data as a data controller, see Immuta Privacy Notice.