A Guide to Automated Data Access
In Databricks Using Immuta


The pros and cons of role-based access control (RBAC) and attribute-based access control (ABAC) have been well documented and debated. There are even different implementations of ABAC that use static attributes, defeating the intent of safely scaling user adoption. But understanding the delineations between different approaches and soundly implementing one or both is equivalent to reading a recipe and having a fully cooked meal on the table.
Immuta integrates with Databricks to enable customers to dynamically control data access using fine-grained access controls. This allows Databricks customers using Immuta to ensure the right people have access to the right data at the right time – for only appropriate and approved purposes.
A Guide to Data Access Governance with Immuta and Databricks spells out in detail how exactly this works. But, given the potential value that Databricks users can unlock from their data when they use attribute-based access control — not to mention the scalability and efficiency it can provide — we wanted to share a sneak peek of what you can accomplish in Databricks with Immuta’s native access controls.
To understand how Immuta’s attribute-based access control policy is deployed within Databricks, it’s important to understand Databricks’ architecture.
Databricks allows organizations to separate compute and storage, so they can store data in a cloud-based storage platform of their choice and spin up Databricks clusters on-demand when they’re ready to process the data. Decoupling storage and compute increases flexibility and cost efficiency, in addition to being more friendly to a data ecosystem that includes multiple cloud data platforms.

In Databricks Using Immuta
With compute and storage decoupled, Databricks users have three points at which to control data access:
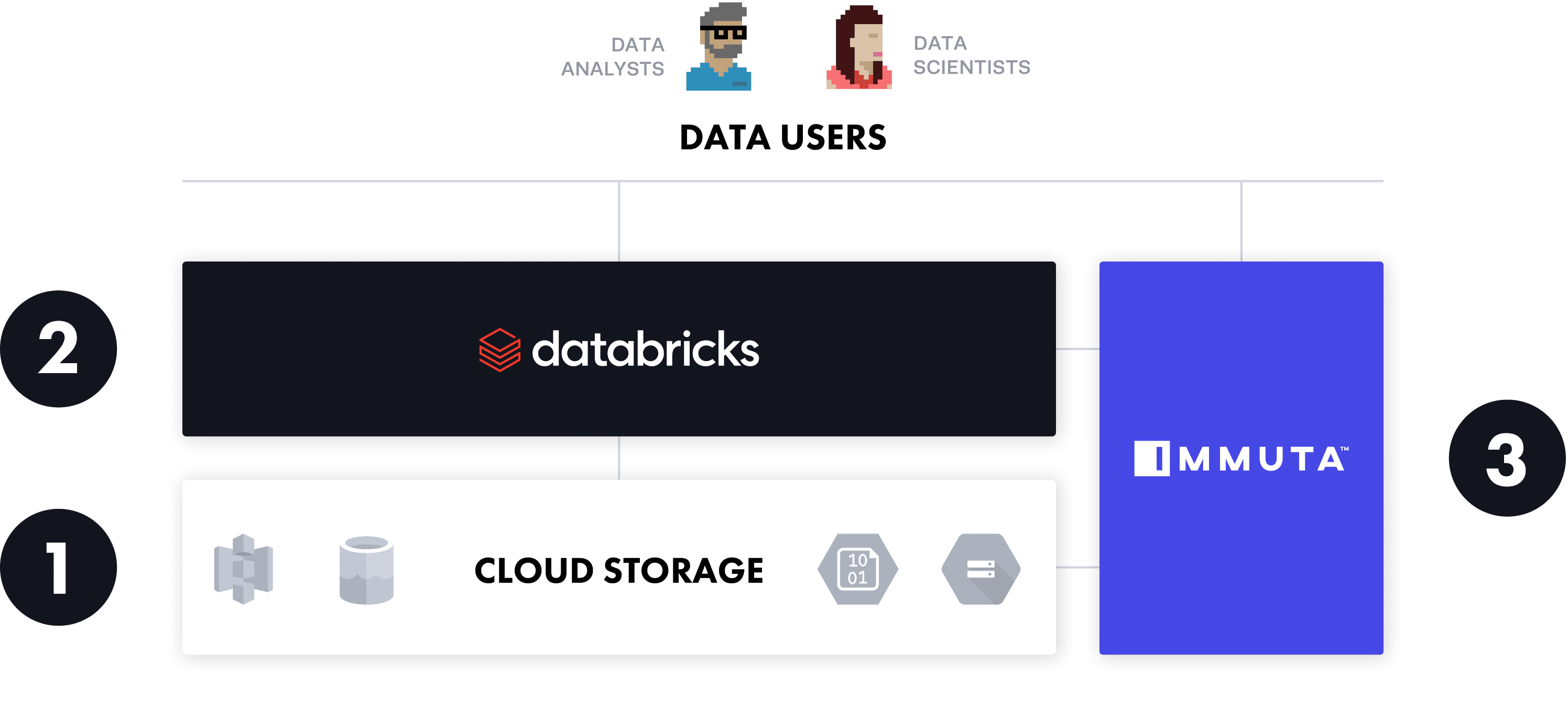
The credential passthrough option allows users to spin up Databricks and continue using existing access controls from cloud storage platforms natively in Databricks, without requiring any new role decisions or updates.
This is a good option for organizations that have already created cloud provider roles to the level of granularity required for accessing data in ADLS or S3, have simplistic access control requirements, or are working with a single cloud provider, through which they can manage all roles. For organizations that plan to adopt multiple cloud data platforms — which is more than half of data teams — and/or manage identities across cloud and on-prem data sources, the credential passthrough option is less attractive since it works with individual providers, but not across data sources or platforms. This option also does not enable dynamic data access control, including row-, column-, or cell-level security, or data masking techniques, which are core aspects of secure sensitive data use.
Meanwhile, the Databricks table ACL approach allows users to manage table access in a manner similar to relational database systems, with the only difference being that the data exists in external cloud storage.
This is a good option for organizations starting from scratch in the cloud that do not have established access controls on ADLS or S3, have only table-level access control requirements, or do not anticipate using compute services other than Databricks. For organizations with access control requirements beyond just table-level access controls — row- or column-level access controls, for instance — and/or dynamic data masking needs, the table ACL approach can be limiting. Additionally, if organizations plan to use a compute platform in addition to Databricks, this approach requires recreating and managing policies in each of those platforms.
Finally, Immuta enables customers with data access control needs — which, in this day and age, is essentially all organizations — to abstract policy decisions from the policy enforcement point(s). This allows user identities to be managed wherever the customer prefers, policy logic to be curated using attributes from other systems, and policies to be native enforced at query time.
Unlike the credential passthrough and table ACL approaches, Immuta doesn’t restrict policy enforcement to Databricks or require users to create policies for each individual cloud data platform. Dynamic attribute-based access control enables row-, column-, and cell-level access controls, while dynamic data masking capabilities, such as k-anonymization, randomized response, and differential privacy, allow sensitive data to be protected and used securely at scale, without risking inconsistent implementation or dealing with manual protection techniques. Immuta’s flexibility and scalability across Databricks and other cloud data platforms in an organization’s ecosystem make it the most dynamic, secure option.
Let’s take a closer look at how to implement attribute-based access controls in Databricks using Immuta.
From the point that new data is introduced into Databricks, Immuta’s native integration streamlines access control implementation without requiring manual, risk-prone processes.
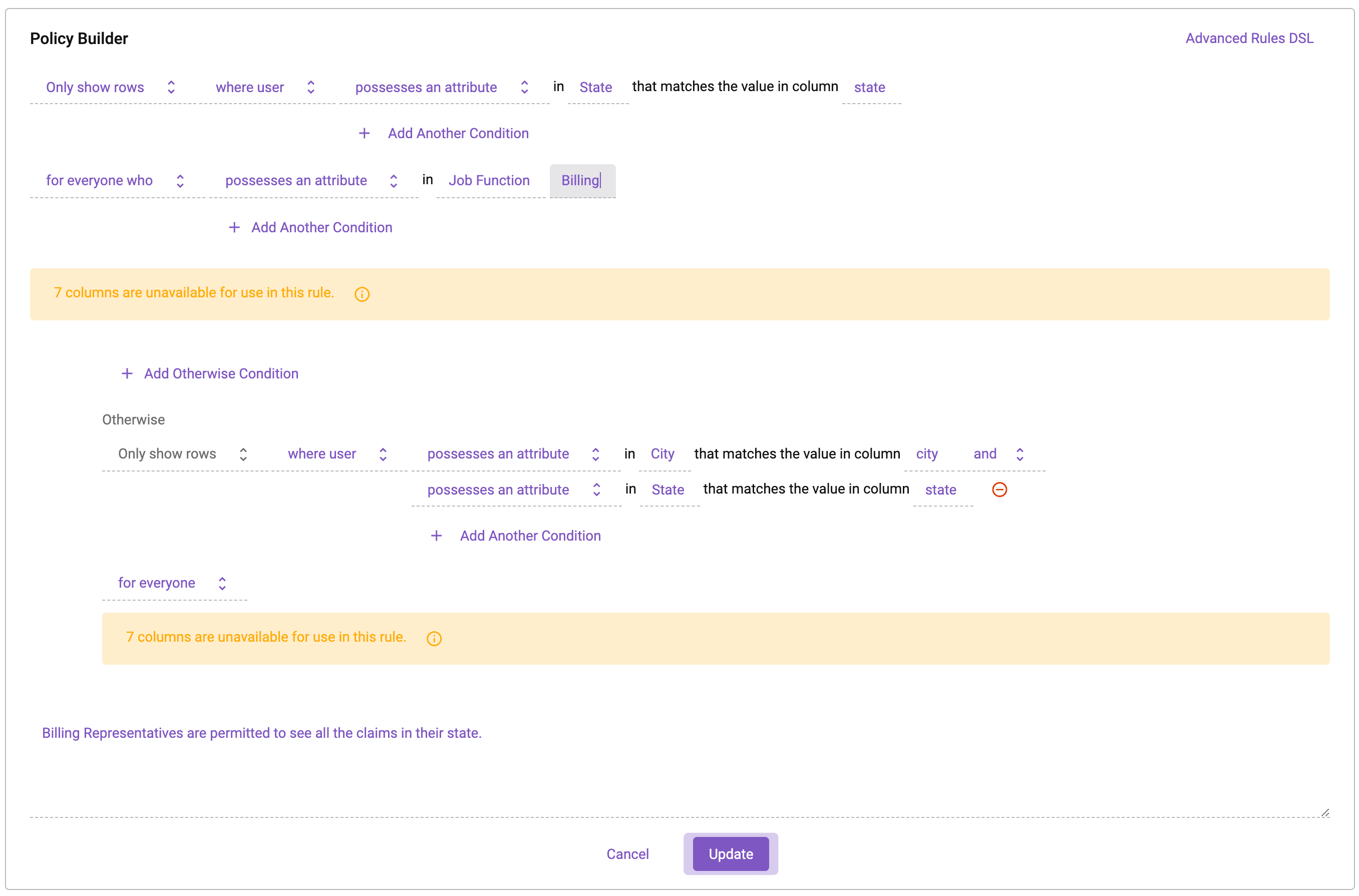
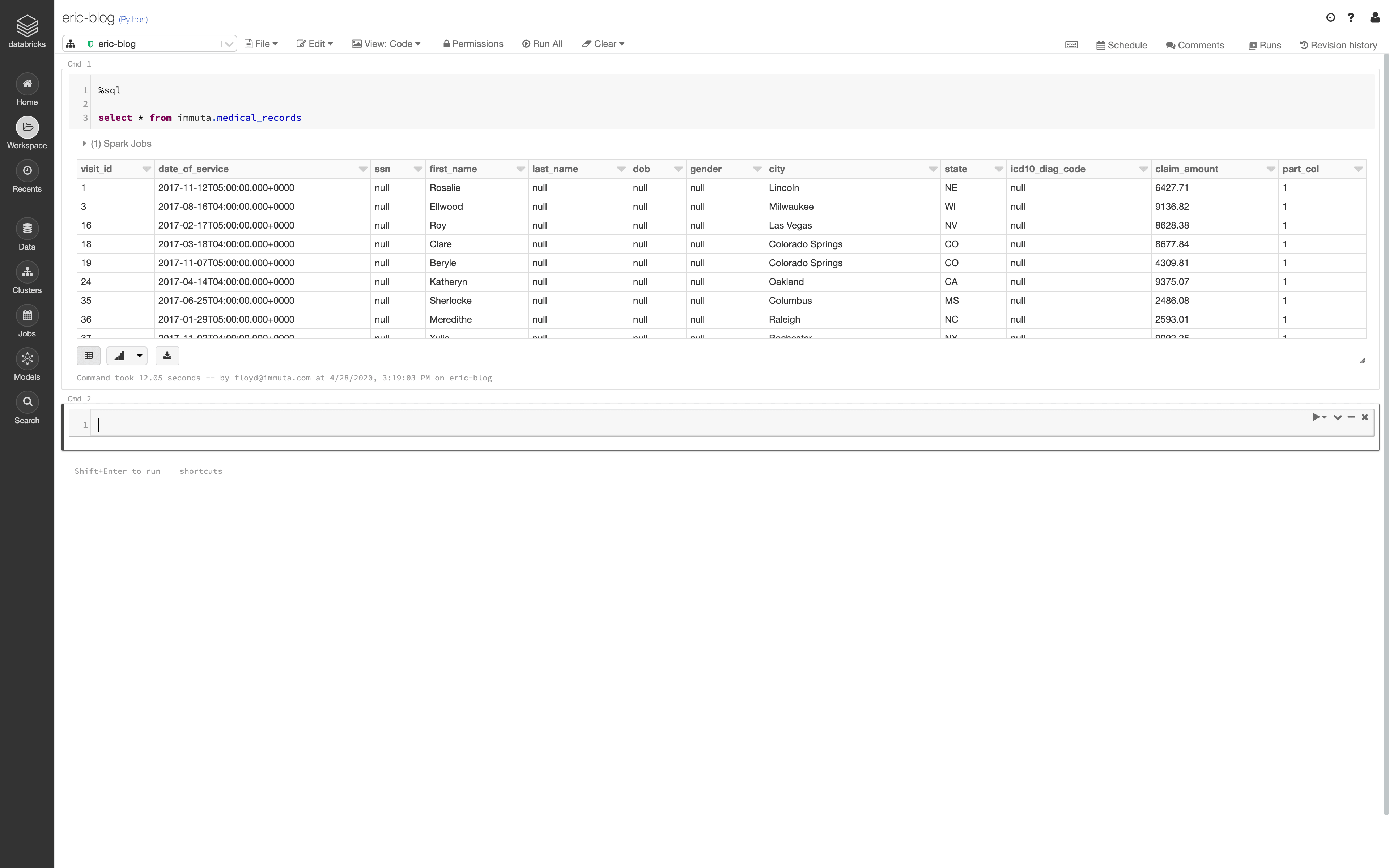
This process means that data access is determined at query time. Applying data access controls at runtime eliminates the need to have all data users defined in a specific system, which vastly reduces the burden on data engineers and architects. Consequently, data teams can quickly and securely scale data access for both internal and external data consumers. They are also able to monitor and audit data usage.
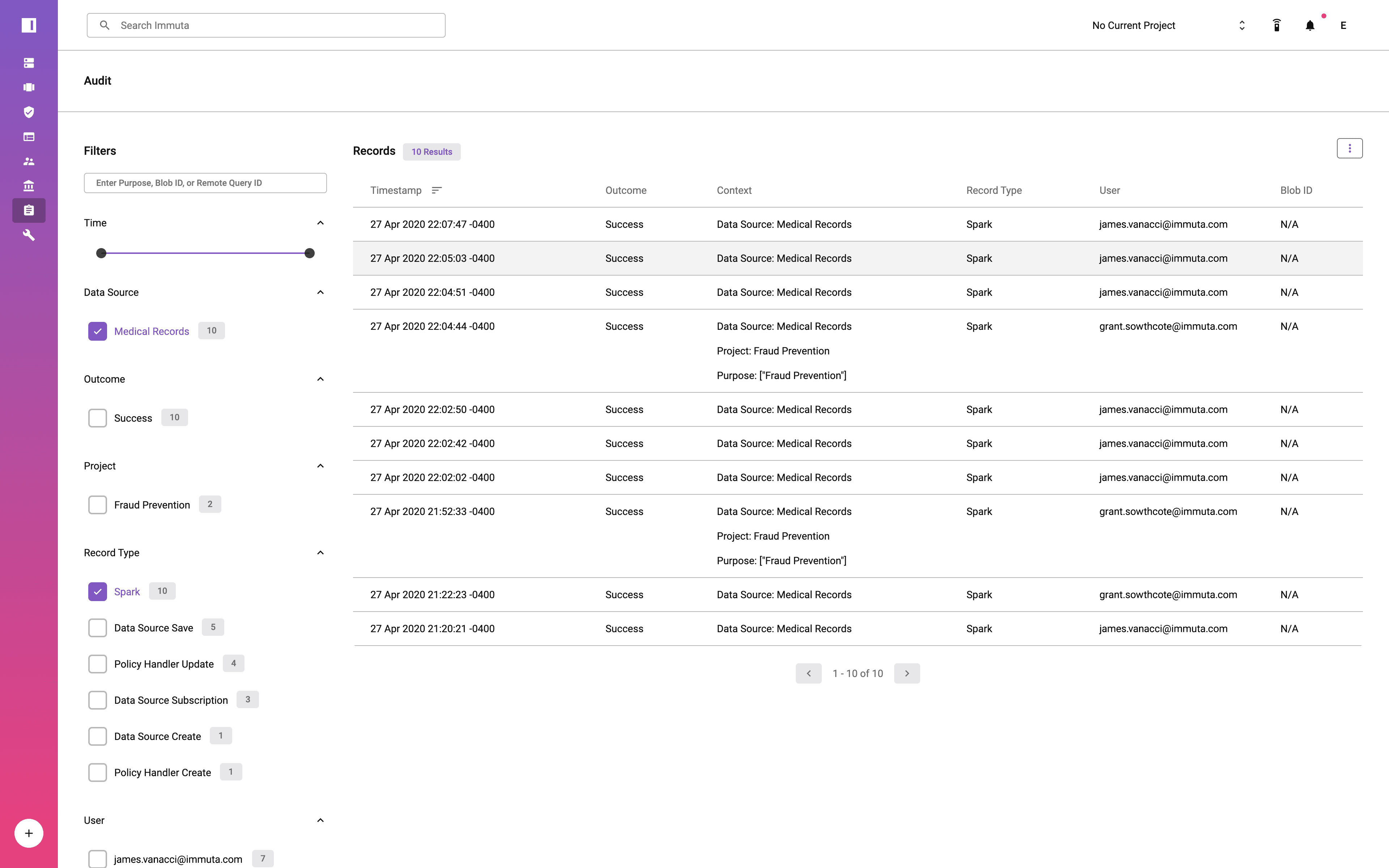
To learn more about access controls and the other capabilities of Immuta’s native integration with Databricks, download A Guide to Data Access Governance with Immuta and Databricks.
If you’re a Databricks user, experience Immuta for yourself by starting a free trial today.


