eBooks




Videos
Where AI Breaks Traditional Data Governance
Most AI pilots start safely, since teams test with public documentation or data that’s already anonymized, so traditional access controls hold up fine. The problem shows up later, once agents need access to sensitive data to do real work, and that’s when most access models start to crack. The instinct...
Your RBAC Model Wasn’t Built for Machine Speed
Role-based access control made sense when humans were the only ones asking for data. But agents don’t work that way, and trying to define every possible permutation of access across an entire organization, for every agent, for every question, isn’t just difficult. It’s not feasible. In this video, Immuta Co-Founder...
Videos
AI Agents Can’t Wait. Your Data Strategy Might Not Know That Yet.
The shift to AI agents isn’t just a technology change. It’s a fundamental reset of what “fast enough” means for data access. When a human needs data, waiting days — or even weeks — is frustrating but manageable. Engineers have learned to live with long-running queries. But agents operate on...
Videos
Why Your Agentic Rollout Will Fail Without This
AI agents move fast. Your data provisioning strategy needs to keep up, or your agentic rollout won’t make it to production. In this short video, Immuta CEO Matt Carroll lays out what a provisioning strategy actually needs to support AI agents at scale: sub-second response times, the ability to handle...
Videos
Why AI Agents Need Their Own Identity
As AI agents take on more work across the enterprise, a fundamental access problem is emerging, and most organizations haven’t solved it yet. When an agent connects to a data platform using a person’s credentials, it inherits everything that person can do. That might sound convenient. It isn’t. Agents don’t...
Videos
How Immuta Enables Fine-Grained Masking in Teradata
Not all sensitive data should be treated the same way. Sometimes you need to redact it entirely. Other times, you need just enough visibility to do the work — without exposing what shouldn’t be seen. In this demo, see how Immuta’s masking policies work natively within Teradata, giving data teams...
Videos
The Future of Data Governance: Bridging the Gap Between People, Process, and AI

Videos
Riding the AI Wave Without Drowning in Data Access
AI isn’t just a trend — it’s transforming how every company operates. With AI adoption skyrocketing, industries are approaching it with both excitement and anxiety. Organizations are racing to harness new tools, enable employees, and stay competitive — but many are struggling to answer a simple question: “How do we...

Videos
Immuta’s Product Development Philosophy
At Immuta, innovation never stops. In this video, Chief Product Officer Mo Plassnig explains our continuous product development philosophy, where customer feedback drives rapid iteration, and new capabilities roll out regularly to make data governance and provisioning faster, smarter, and more efficient. What you’ll learn: How Immuta’s customer-driven innovation model...

Videos
Overcoming Ticket Overload with Immuta
As organizations adopt AI and agentic workflows, managing data access at scale is quickly becoming impossible with manual, ticket-based processes. In this video, Immuta CEO and Co-founder Matt Carroll explains how the Immuta data provisioning platform solves that challenge by automating access approvals and tightly integrating with enterprise data catalogs...

Videos
Enabling Native Policy Enforcement Across Your Data Platforms
In this video, Immuta Chief Product Officer Mo Plassnig explains what makes Immuta’s native connectors unique — and why they’re the key to secure, scalable data governance in today’s hybrid environments. Through Immuta native integrations with data platforms like Snowflake, Databricks, and Postgres, you’re able to control access without proxying...

Videos
How Immuta Integrates with Catalogs for Data Provisioning
As enterprises embrace AI and agentic automation, their data catalogs have become rich libraries of every one of their data sources. But discovery alone isn’t enough: data must also be provisioned securely, instantly, and efficiently. In other words, ticket-based processes no longer cut it. In this video, learn how Immuta...

Videos
Bracing for the AI Agent Surge: Are Enterprises Ready?
As organizations race to adopt AI, many leaders are asking the same question: “Where are we in this journey?” In this video, Immuta Chief Product Officer Mo Plassnig explains how bringing together leaders from highly regulated industries to share insights, align expectations, and collaborate on the responsible adoption of AI...

Videos
The AI Agents Are Coming: How Data Governance Teams Can Prepare
The era of agentic AI is here, and it’s transforming data provisioning and governance. In this video, Immuta CEO and Co-founder Matt Carroll explains how Immuta is helping enterprises prepare for a future where AI agents operate alongside humans to request, manage, and govern data. You’ll find out: How agentic...
Videos
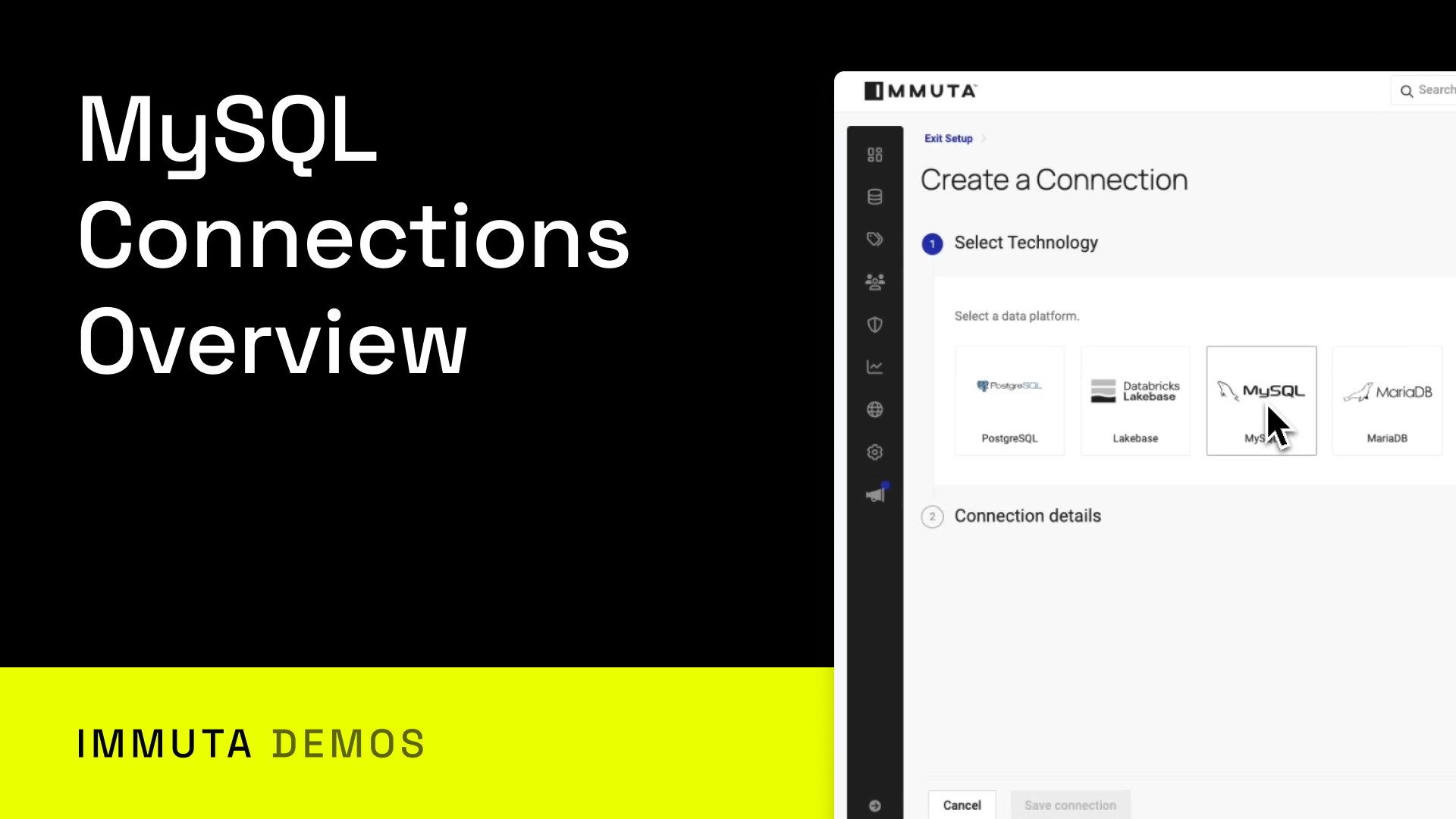
Introduction to Immuta’s MySQL Connector
In this demo, you’ll go inside Immuta’s integration with MySQL. You’ll see step-by-step how to connect, govern, and provision access to MySQL data across Amazon RDS and Amazon Aurora. You’ll learn how to: Configure a MySQL connection in Immuta and register data sources, and tag them by domain Publish MySQL...

Videos
How to Enforce Time-Bound Access Approvals for SOX Compliance
For publicly traded companies, governing data access is critical for meeting the strict SOX compliance standards – and time-bound access is a key component. In this demo, you’ll see how Immuta automates secure approvals for Snowflake data products while ensuring SOX compliance and protecting sensitive information. What you’ll learn: How...

Videos
How to Streamline Data Access and Management with Immuta
In this demo, we walk through how Immuta enables secure, scalable data product management — from publishing and governance to consumer access and policy enforcement. What you’ll learn: How to create and publish data products in the Immuta Marketplace Using domains to delegate ownership and governance across business units, and...

Videos
Introducing Immuta’s SQL Server Integration
In this demo, you’ll see how Immuta’s new SQL Server integration allows you to connect, tag, and govern SQL Server data, whether hosted in Azure, Amazon RDS, or self-managed environments. What you’ll learn in this demo: How to configure a SQL Server connection in Immuta Using tags to automatically assign...

Videos
How Snowflake & Immuta Accelerate Trusted Data Access in Life Sciences
With the enforcement of the EU AI Act, healthcare and life sciences companies face new pressure to ensure their AI systems are trained on the right data – with the right controls in place – to ensure they remain compliant in one of the most highly regulated industries in the...

Videos
Introduction to AI Use Cases: A Demo Series
Taking AI from pilot to production at scale is one of the hardest challenges organizations face today — and the biggest barrier is secure data provisioning. In this video, Alan Clarke, Senior Solutions Architect at Immuta, demonstrates how to build safe, scalable AI governance frameworks that protect sensitive data while...

Videos
How to Structure Your Data for Your AI Use Case
As organizations scale agentic AI use cases, they need a way to grant access dynamically without sacrificing privacy or compliance. Data teams need workflows deliver that balance — automating access where appropriate, and enforcing human oversight as needed. In part two of our series on solving data provisioning and privacy...

Videos
Data Access, AI, & Risk: What Data Leaders Need to Know
As AI and machine learning reshape enterprise workflows, traditional governance models can’t keep up. Static, ad hoc reviews no longer work. Data provisioning must be dynamic, automated, and trustworthy. In this video, Andy Ho, Senior Manager, EY Americas Technology Consulting, Ernst & Young, explores how organizations can prepare for a...

Videos
Automating Data Access Decisions with Immuta AI and Model Context Protocol (MCP)
In this quick update, Immuta Co-founder and CTO Steve Touw explains how Immuta AI makes data governance and access provisioning conversational – and easy. Instead of navigating through a complex user interface, data stewards and consumers can now interact with Immuta using natural language, asking questions like: “Show me all...

Videos
Enabling Granular Data Product Access with Immuta
When most people think about data access requests, they think in terms of tables or data products. But in reality, access needs often go deeper — down to specific columns or rows within a data product. Immuta enables users to request granular access to data products without requiring separate versions...

Videos
The Enduring Power of PostgreSQL in Data Platforms
Immuta natively enforces policy for PostgreSQL, adding to our robust ecosystem of integrations with Databricks, Snowflake, AWS, and more. Whether you’re running PostgreSQL on Amazon RDS, Aurora, Azure, on-prem, or via providers like Neon, Immuta delivers consistent, secure, scalable data provisioning and access controls — no matter where your data...

Videos
AI-Powered Review Assist for Data Access Requests
As AI unlocks data for everyone – technical and non-technical users, as well as AI agents – the number of data access requests is exploding. Data is no longer the purview of SQL experts or BI analysts. Now, anyone in your organization can ask questions of data. That puts even...

Videos
Rethinking the Data Provisioning Experience: Immuta’s MCP Support for Scalable Data Access
As AI, self-service analytics, and more data users fuel demand for data, legacy ticketing systems and GUI-based workflows can’t keep up. Approving thousands of access requests a month isn’t scalable with point-and-click governance and provisioning systems. That’s why Immuta is transforming the data provisioning experience. In this video, Immuta Co-founder...

Videos
Immuta for Public Sector
Public sector agencies collect, use, and share an immense amount of data, whether operating in service of defense, intelligence, or federal and civilian matters. But unlike commercial and private sector companies, public sector organizations are often working on novel and quickly evolving use cases, which poses a unique set of...

eBooks
Immuta De-Risks Financial Data with AWS
With only 23% of data leaders confident in their data quality and one-third citing poor visibility as their top security challenge, effective governance remains elusive. This ebook explores how financial institutions can modernize data access, overcome regulatory and architectural complexity, and reduce risk—without slowing down. Learn how Immuta, in partnership...

eBooks
Data Products & Marketplaces For Dummies
You’ve invested in data infrastructure. You have the right people on your team. But when it comes to getting governed, ready-to-use data into the hands of decision-makers, friction wins. The future of data isn’t just about collection or storage — it’s about delivery. The teams that can provision data products...

Case Studies
How a Global Bank Saved $50M by Modernizing Data Security with Immuta and AWS
Discover how one of the world’s largest multinational financial institutions overcame data access bottlenecks, compliance risks, and siloed cloud environments to unlock $50 million in savings. Faced with slow, manual approval workflows and growing regulatory pressure, the bank partnered tasked its enterprise data architecture team to work with AWS Partner...

eBooks
Unlocking Pharmaceutical Data with AWS & Immuta
From clinical trials to AI-powered drug discovery, pharmaceutical companies are under pressure to unlock the full value of their data — without compromising security, privacy, or compliance. This eBook explores how global pharma leaders like Roche, Merck, and Eisai are using Immuta and AWS to modernize their data strategies and...

Reports
2025 KuppingerCole Analysts Executive View – Immuta Data Security Platform
Unlock the insights you need to protect your most valuable asset. The KuppingerCole Executive View provides an in-depth look at Immuta’s innovative approach to data security, addressing the challenges of modern data environments. Learn how Immuta empowers organizations to enforce governance, ensure compliance, and accelerate data-driven initiatives. Download the report...

Videos
Announcing Immuta AI
Introducing Immuta AI, a new suite of AI capabilities within the Immuta Platform, built with data governance teams in mind. By using AI to simplify data product discovery, assist in policy authoring, and automate data access decision-making, Immuta AI will expand on the Immuta Data Marketplace solution and eliminate manual...

eBooks
Immuta Simplifies Data-Lake Governance
Struggling to balance data accessibility with security and compliance? As data volumes grow and architectures evolve, many organizations face significant governance challenges, from lack of visibility to regulatory pressures. This eBook explores how modern data-lake governance can help you: Simplify access management in complex environments Enhance data quality and visibility...

Videos
Understanding Data Marketplaces
Why are companies adopting internal data marketplaces, and why now? In order to quickly tap into data-driven insights and value, today’s data landscape requires efficiency, scalability, and seamless collaboration. That’s where Immuta comes in. In this video, Immuta leaders explain the growing need for internal data marketplaces from some of...

Videos
Why LMI Securely Controls Data Access with Immuta
Hear from Josh Wilson, VP of Advanced Analytics at LMI, on how Immuta helped his organization overcome the barrier of time to data in advanced analytics. Learn more about how LMI securely accelerates data access.

Case Studies
Thomson Reuters Secures Snowflake Data and Boosts Productivity
See how this information services provider: Increased data usage by 60x and drove greater productivity by providing faster access to Snowflake data Automated data access across all domains with a single global subscription policy, freeing up data engineering resources Easily administered Snowflake row access and column masking policies, allowing users...

Videos
Managing Modern Data Infrastructure: A Conversation with Immuta & Intel
As organizations migrate to the cloud, the way we think about data and how it’s used is completely changing. The necessary performance, scale, rules, and number of users who want to combine data have increased exponentially. Not to mention, increasingly decentralized data architectures are making visibility into how data is...

Case Studies
Swedbank Unlocks Data Analytics for Financial Services with Immuta
Data analytics in financial services is key to delivering tailored insights, forecasting market conditions, making investment decisions, and more. While the technologies, tactics, and teams vary from firm to firm, it’s safe to say that data use is ubiquitous in financial services. However, financial data is among the most sensitive information that...

White Papers
Self-Service Analytics for Data Mesh in the Public Sector
In the past decade, the enactment of both the Data Act and the Evidence-Based Policy Making Act kicked off Federal Agencies’ journeys toward data modernization. While many have made progress, there’s much more work for the majority of government agencies to do in order to meet the goals outlined by the vision in the President’s...

Solution Briefs
How Immuta Simplifies Compliance with Quebec’s Law 25
Quebec’s Law 25 is the latest in a series of major data localization laws seeking to protect citizens’ privacy and secure national interests. Organizations based in Quebec or that handle data belonging to the province’s citizens are subject to $10 million for failing to administer regulations – and that rises to $25...

Case Studies
National Law Enforcement Agency Toughens Fight Against Crime with Immuta
See how this national law enforcement agency: Accelerated data delivery to its 7,000 employees working across public, private, and international agencies Reduced its number of full-time data access management resources by 67% by increasing operational efficiency Enabled secure data democratization by empowering data owners and governance teams to manage access...

Case Studies
How a Global Bank Secures Electronic Trading Analytics
Electronic trading analytics are crucial to financial services firms’ success, by providing real-time insights into market trends, trading patterns, risk exposure, and decision making. Electronic trading helps optimize business strategies and enhance performance, but its systems could also be easily misused. Therefore, it’s essential to have robust data security in place to...

Videos
Immuta at Snowflake Summit 2022

Solution Briefs
Immuta + Amazon S3 Overview
Amazon S3 is the most popular object storage platform in modern data stacks, with 340 trillion objects stored and more than 100 million requests per second. Leading companies across every industry and geography rely on S3 to store an manage massive volumes of data in a data lake. Data lake...

Case Studies
How One of the World’s Top Streaming Services Scaled Data Access
Learn how one of the world’s top streaming services: Automated data classification and enforcement across platforms, allowing the data team to consistently scale and secure data access for all users. Reduced risk of customer re-identification using mathematical guarantees provided by Immuta’s dynamic PETs. Eliminated the proliferation of data copies, views,...

Case Studies
How LMI Accelerates Speed to Data Access for Government Agencies with Immuta
Learn how LMI: Increased time to data by 10X, giving users fast and easy access to sensitive data for advanced analytics Gained the ability to review and audit data use and misuse to ensure compliance with data use and sharing rules

Case Studies
How J.B. Hunt Is Driving Freight Transportation Into the Future
Learn how J.B. Hunt: Increased permitted use cases for cloud analytics by 100% with Immuta while also achieving cost savings and productivity gains Provided 200+ active users with access to 100+ databases using global PII policies across 250 tables and local PII policies across 50 tables

Case Studies
How a Top Bank Saved $50M by Automating Data Access Controls
In the world of financial services, two factors are non-negotiable: efficiency and security. As one of the most highly regulated industries, financial services must adhere to data compliance regulations without delaying speed to data. For one of the world’s largest banks, data security and utility were at odds, resulting in analysts spending 35% of their time waiting...

Solution Briefs
Hakkōda + Immuta for Healthcare Data Security
For organizations in the healthcare and life sciences (HCLS) industry, protecting sensitive data is critical. But leveraging that data to diagnose illnesses and develop life-saving treatments is equally important. Hakkōda and Immuta allow healthcare and life sciences data teams that run on Snowflake to do just that. This brief outlines...

Podcasts
Signposts on the Road to Data Eutopia – Hitting the Accelerator
In part four of our webinar series Signposts on the Road to Data Eutopia, Editor in Chief of Computer Weekly Brian Glick sits down with Immuta Director of Solutions Architecture Mark Semenenko to discuss how companies can make DataOps and next-gen data control planes a source of competitive edge.

Podcasts
Signposts on the Road to Data Eutopia – The New Rules of the Road
In part three of our webinar series Signposts on the Road to Data Eutopia, Editor in Chief of Computer Weekly Brian Glick sits down with Immuta Senior Privacy Counsel and Legal Engineer Sophie Stalla-Bourdillon to discuss how regulatory pressures are forcing organisations to review traditional data governance processes and technologies.

Podcasts
Signposts on the Road to Data Eutopia – Avoiding the Traffic Jams
In part two of our webinar series Signposts on the Road to Data Eutopia, Editor in Chief of Computer Weekly Brian Glick sits down with Immuta Director of Solutions Architecture Mark Semenenko to discuss the most prominent challenges of data access management and how they can be addressed.

Podcasts
Signposts on the Road to Data Eutopia – Starting the Journey
In part one of our webinar series Signposts on the Road to Data Eutopia, Editor in Chief of Computer Weekly Brian Glick sits down with Immuta GM and VP of Sales, EMEA and APAC, Colin Mitchell to discuss breaking down the data silos and identifying the key blockers to data...

Case Studies
Australian Insurance Provider Strengthens Data Security to Better Serve 1.75M Customers
See how this insurance provider: Quickly onboarded more than 400 users and secured access to 17,000+ data sources with just 9 policies Improved operational efficiencies by facilitating more transparency and collaboration between data, security, and governance teams Achieved greater flexibility across connected data platforms including Snowflake and dbt

Podcasts
Podcast: Purpose-Based Access Control in Pharma with Paul Rankin
There’s a reason purpose-based access control is a must-have for healthcare and life sciences companies: It allows data and governance teams to abide by data usage restrictions laid out by compliance laws and regulations such as HIPAA. In this interview, Chief Data Officer Paul Rankin shares real-world examples of purpose-based access...

Videos
How Immuta and Hakkōda Empower Data Sharing in Healthcare & Life Sciences
In this video, Matt Dubay, Director of Client Services for Healthcare and Life Sciences at Hakkōda, discusses challenges of sharing data in the healthcare and life sciences industry, including data access complexity, regulatory requirements, and the inherent risk of handling sensitive data. You’ll hear about the role of data security...

Podcasts
Podcast: Overcoming Data Governance Challenges with Paul Rankin
As companies grow, their demands for data also grow – often exponentially, which may take data and IT teams by surprise. Static approaches to managing data access quickly lead to role explosion, while an influx of data assets and data users make it difficult to find and gain access to...

Videos
Balancing Speed, Compliance, & Ethics with Life Sciences Data
Data use in the life sciences industry is essential, but highly dependent on data security and governance capabilities. As use cases emerge and evolve, including AI adoption, this dependency will become even more critical. Harini Gopalakrishnan, Global CTO of Life Sciences at Snowflake, sat down with us to discuss the complex data demands of the...

Podcasts
Podcast: Unlocking the Power of Data Sharing with Paul Rankin
Data sharing isn’t a nice-to-have in today’s data-driven world – in order to compete, it’s a business imperative. But it’s not always easy to do. Hear from Paul Rankin, Chief Data Officer, as he shares insights into the critical role of data sharing in driving business success. In this fireside chat...

Videos
How Snowflake and Immuta Bridge the Security-Utility Gap
From navigating complex data ecosystems to ensuring consistent data policy enforcement, data owners and stewards face a myriad of challenges to making data accessible and safe. In this video, Seth Youssef, Field CTO at Snowflake, discusses the gap that exists between the demand for data access, and the ability to...

Videos
How Snowflake Ensures Governance & Security Throughout the Data Lifecycle
In the healthcare and life sciences industry, data is vital – but so is privacy and compliance. Lisa Arbogast, Industry Principal for Life Sciences at Snowflake, sat down with us to discuss the challenges and opportunities in the life sciences industry, including the vital importance of a strong data security,...

eBooks
The AI Security & Governance Handbook
As companies race to adopt AI, the question of how to adequately secure its inputs and outputs remains elusive – creating potential security gaps and ethical questions. This handbook will help cut through the noise, with research-backed strategies for securing your AI systems and navigating the complex landscape of AI governance. Download...

Solution Briefs
How Immuta Enables Media & Entertainment Use Cases
Media and entertainment are central to today’s culture – the leading companies are worth hundreds of billions of dollars, and serve millions of customers around the world. With this kind of influence and reputation, the stakes for protecting their data could not be higher. From customer transaction and streaming details, to...

Videos
How nib Group Enforces Data Security and Privacy Policies with Immuta
As a leader in health and medical insurance for more than 6 million customers across Australia and New Zealand, maintaining customer trust is a top priority for nib Group. So, their data security strategy and implementation must be airtight and closely monitored. We sat down with Kurt Gardiner, Senior Engineering...

Videos
How GM Mitigates Risk Through Data Governance
Hear from Shelly Washington Woodruff, Information Technology Executive at General Motors, about how her team has leveraged Immuta to bridge GM’s legacy and forward-looking databases through unified data access and privacy controls.

Videos
The Importance of AI & Data Security in the Public Sector
Hear from Matthew Rose, Snowflake Industry Principal, Global Public Sector, about how Immuta and Snowflake provide key capabilities for public sector missions in an evolving, data-driven world. More on Immuta for the Public Sector here.

Reports
DBTA Report: 2024 Data Governance & Security for the Cloud & AI Era
As AI and machine learning revolutionize industries, ensuring data security and integrity is paramount. But doing so in practice is not straightforward. Organizations face a delicate balance: fulfilling AI’s promise of speed and innovation, with the imperative for cloud data governance and security. Leaning too far in either direction could have detrimental business impacts....

Reports
The AI Security & Governance Report
Compliance, privacy, and ethics have always been top priorities for data-driven organizations. But as generative AI advances open new doors and opportunities for innovation, the stakes have never been higher than they are right now. But for all of AI’s potential, it also presents significant uncertainty and risk. To understand...

Content Bundles
The Amazon S3 Security & Access Handbook
Amazon S3 is one of the most widely used and trusted cloud storage solutions, housing more than 350 trillion objects. Its popularity is particularly relevant because unstructured data living in its storage layers is more accessible and valuable than ever before, which is key to competing in today’s AI-driven marketplace. But...

Content Bundles
De-Risk Your Data Sharing
Data sharing is essential for any growth-oriented business, helping to maintain a competitive edge and deliver business value. By allowing teams to deploy data products, collaborate with internal and external partners, and monetize insights, data sharing drives business outcomes. So why are so few organizations actually sharing data at scale? In...

Solution Briefs
Immuta + AWS for Financial Services
From banking and investing to wealth management and electronic trading, sensitive data is essential to success in the financial services industry. Firms rely on data to generate timely insights, customize services, and guide clients on how best to invest and grow their assets. But data security in financial services is fraught with risk. From data...

Solution Briefs
How Immuta Supports Accenture Federal Services Zero Trust at Scale – Data Pillar
For federal agencies, protecting sensitive data isn’t just a matter of compliance – it could impact national security. A 2021 executive order aimed to bolster data security for public sector organizations by mandating zero trust architectures, which require continuous verification and authentication of user identities before allowing access to data. To support these organizations, Accenture Federal Services built its...

eBooks
2024 Data Security Trendbook
Securing a Changing Data Landscape One of the most exciting aspects of our data-driven world is its dynamic nature. The data landscape is subject to the constant generation, innovation, and iteration of new ideas from experts and newcomers alike. The most impactful of these ideas are those that take hold...

Videos
Year in Review 2023
The past year saw the continued evolution of data, changing the way organizations approach storage, compliance, and data usage in a secure manner. As we reflect on 2023 and prepare for what’s to come in 2024, please enjoy this recap video from the team at Immuta.

Videos
Leadership Spotlight: How AstrumU Achieves Data Security & Compliance
How does a fast-moving startup deliver tailored insights while protecting personal data and complying with regulatory requirements? In this Q&A, with Immuta Chief Product Officer Mo Plassnig talks with AstrumU Chief Technology Officer Kaj Pedersen talks about this and his company’s approach to data security and compliance. As an innovative...

Reports
2024 State of Data Security Report
The 2024 State of Data Security Report surveyed 700+ data leaders for their views on AI, data security, visibility, and more. Download the report to find out: Why data security and governance are bigger priorities for 2024 than AI. Whether data security strategies are keeping up with the pace of...

White Papers
How Do I Integrate Snowflake Security With My Enterprise Security Strategy?
A Deep-Dive with phData and Immuta As we continue to rely increasingly on digital solutions, it’s hard to ignore major security breaches in the news by major corporations like Equifax, Facebook, and First American Financial. Stories like these are part of the reason why security concerns always come up when...

Videos
Deriving Value from Data at Scale with Hakkoda + Immuta
Ryan Tucker, Co-Founder and CRO at Hakkoda, shares how Immuta’s partnership with Hakkoda enables joint customers to streamline administrative data security tasks and better organize, modernize, and monetize valuable data at scale.

eBooks
Data Security for Data Mesh Architectures
Growing in popularity in recent years, data mesh architectures promise a wide range of benefits for modern organizations: increased data democratization, elimination of data silos, and the enablement of more widespread, business-driving data access and use. In practice, however, operationalizing a scalable and secure data mesh can be a complicated process. With the right practices,...

Reports
IDC InfoBrief: How Data Security Platforms Improve Data Security Posture
Data security has never been more critical to business operations, but implementing it remains difficult for many organisations. According to this IDC InfoBrief, 29% of European organisations are unable to fully utilise their data due to security challenges, while 54% experienced an increase in cyberattacks over the past year. This...

Videos
Sanjeev Mohan on The Role of the Data Security Platform in Modern Data Architectures
Learn what Sanjeev Mohan, Principal at SanjMo and former Gartner analyst, thinks about the critical need for data governance and security platforms for modern data use cases. Frrom eliminating data silos, to federating governance for data mesh, and beyond, hear what he has to say in this video. Learn more...

Videos
How to Drive Snowflake Utility, Scalability, and Innovation with Immuta
Immuta’s native integration with Snowflake allows leading enterprises like booking.com and Thomson Reuters to access data faster and make their data work harder – but how? In this video, Vikas Jain, Senior Technology Alliances Manager at Snowflake, shares his insights into how Snowflake users improve ease of use, scalability, and...

Videos
How Snowflake & Immuta Address Data Challenges in Healthcare & Life Sciences
Hear from Murali Gandhirajan, Healthcare and Life Sciences Field CTO at Snowflake, about how Snowflake & Immuta work together to enable HLS teams to address some of their most common data sharing and security challenges. Learn more about data security for Healthcare & Life Sciences, as well as our partnership...

Case Studies
Advancing Lifesaving Pharmaceutical Research & Development with Immuta
With more than 10,000 employees worldwide, this global pharmaceutical company takes a patient-first approach to therapeutic development, focusing on neurology and oncology. In addition to running clinical trials and producing four global brands, its researchers are exploring how to measure biomarkers for Alzheimer’s treatments and leverage DNA sequences to fight...

Case Studies
AstrumU Revolutionizes Data Insights in Higher Education with Immuta
AstrumU is on a mission to enhance workforce development and quantify the value of education for everyone. But they needed to do so in a way that protected sensitive education data while complying with industry regulations. In this case study, you’ll see: Why AstrumU needed to look beyond native platform...

Videos
Cross-Platform Policy Enforcement at Instacart: An Interview with Sanjeev Mohan & Kieran Taylor
Sanjeev Mohan, Principal and Founder at SanjMo, and Kieran Taylor, Senior Software Engineer at Instacart, discuss Instacart’s approach to data policy management and how to scale data security and privacy controls across cloud platforms, data sets, and users. Learn more about Immuta’s Customers and Partners.

Videos
How Roche Unlocks the Power of Data Through the Data Mesh
Hear from Paul Rankin, Head of Data Management Platforms at Roche Diagnostics, about how his team uses Immuta to enable federated governance for their distributed data mesh framework. Learn more about Roche’s data mesh experience here.

White Papers
Immuta + Unity Catalog: The Next Frontier of Scalable Data Security
The introduction of Databricks Unity Catalog gave Databricks customers a unified governance layer for data and AI within the platform. But today’s workloads require a high degree of granularity and scalability that cannot be compromised, especially when sensitive data is involved. That’s where Immuta’s native integration with Unity Catalog comes in. At a high...
Reports
Forrester Report: The Total Economic Impact™ of Immuta
In the world of data, time is money. What could you accomplish with more of both? Forrester’s Total Economic Impact™ (TEI) study, commissioned by Immuta, found that the Immuta Data Security Platform delivered benefits worth $6.08M and an ROI of 175% over three years by streamlining scalable data security and access control. For organizations looking...

eBooks
Data Security For Dummies
Data security is considered a must-have for modern organizations that want to compete with data while avoiding regulatory penalties. But implementing data security measures often comes at the expense of fast, efficient data access. Opening up access too broadly exposes data to risk, but locking it down restricts users’ ability to access...

White Papers
Data Classification 101
The worlds of data security and privacy are converging. Efficiently implementing controls on sensitive data requires an end-to-end controlled data environment. The foundation of such an environment? Data classification. Data Classification: A Brief Overview Data classification is the process of identifying the types, sensitivity levels, and criticality of an organization’s data. This allows you...

Videos
Data Security Cannot be an Afterthought: A Panel with Alation, EY, Databricks, and Snowflake
Join leaders from Alation (Steve Neat, VP, EMEA), Databricks (Robin Sutara, Field CTO), EY (Oana Beattie, Data & Analytics Director), and Snowflake (Seth Youssef, Field CTO, Security) for a panel discussion exploring the recent explosion in data breaches in both the UK and across the globe, what can be done...

Videos
How Swedbank Unlocks Advanced Analytics
Head of Data Lake Engineering at Swedbank Vineeth Menon discusses how Swedbank partnered with Immuta to ensure secure and compliant cloud migration at scale. You can learn more about Swedbank’s cloud migration experience here.

eBooks
Powering Your Snowflake Data Mesh with Immuta
The popularity of data mesh has skyrocketed in recent years thanks to its ability to decentralize and streamline data workflows. As a result, data teams have benefited from greater flexibility, scalability, and utilization of data products, while increasing horizontal data sharing across their organizations. For customers of Snowflake, data mesh is a natural choice for...

Videos
Roche’s Federated Governance and Access Controls for Data Mesh
In this joint presentation, Paul Rankin (Head of Data Management Platforms, Roche Diagnostics) and Claude Zwicker (Lead Data Architect, Accenture) discuss Roche’s transition to the Data Mesh and how Immuta keeps their architecture secure. Learn more about data security for healthcare & life sciences organizations.

Solution Briefs
How to Comply with Australian Data Protection Law Using Immuta
The State of Australian Data Protection Law Australian data protection law is undergoing a sea change, due in part to recent data breaches impacting organizations across the country. Financial services firms in particular are facing increasing regulatory scrutiny as the Australian Prudential Regulation Authority (APRA) expands its data security standards. The Security-Utility Balance Adjusting...

eBooks
2023 Data Access & Security Trendbook
Modern data use can be a complex process, requiring multifaceted tech stacks, adept teams of skilled data users, and streamlined collaboration across entire organizations. And while its increasing popularity spurs innovation and experimentation, there is no standard approach to best achieve data-driven success. By sharing their personal experiences with the...

Videos
What IAG’s Data Transformation Can Tell Us About Cloud Security
What Is a Data Transformation? Data transformation is the process of converting, restructuring, or manipulating raw data in order to prepare it for analysis, reporting, or storage. Its purpose is to improve data quality, relevance, and usability, and it is a key factor in an organization’s ability to drive business...

Videos
How to Protect Sensitive Data: A Panel with EY, Immuta, Databricks, & Alation
Sensitive data usage is ubiquitous in today’s world – from electronic health records to online banking, we often share our personal information in exchange for tailored services and quality insights that improve our daily lives. But how do we know that our data is safe? Too often, threats to data...

Videos
nib Group’s Journey to Building a Modern Tech Stack
Building a modern tech stack that’s equipped for speed and scale is not trivial. All platforms must work together in a way that minimizes performance and workflow impacts, while still providing visibility into how data is accessed and used. The stakes are even higher in highly regulated industries, such as...

Videos
Why Automating Data Access Helps Thomson Reuters Gain Competitive Advantage
Hear how the Thomson Reuters team leverages the Immuta Data Security Platform to address their various data challenges and shift to a company culture that embraces data security. Learn more about Thomson Reuters’ cloud migration and data evolution in this case study.

Videos
Thomson Reuters Customer Testimonial
Learn how Immuta’s Data Security Platform helps Peter Jacob, VP of Data Lake at Thomson Reuters, build comfort, trust, and cohesion between data and security teams while increasing speed of development.

Reports
2023 State of Data Engineering Survey
Amid explosive growth in data users and products, high profile data breaches, and rapidly evolving legislation, data security has never been more top of mind. The problem is, it’s not necessarily well understood. Immuta’s 2023 State of Data Engineering Survey asked 600 data professionals about their responsibilities, challenges, and outlooks...

eBooks
The Snowflake Data Security Guide
Security is a primary concern in most aspects of our lives – so why should our data be treated any differently? Major organizations like Thomson Reuters and Instacart rely on the Snowflake Data Cloud for advanced analytics. But to unlock more Snowflake data for more users, a data security strategy is essential. That’s where Immuta comes...

Reports
The Data Policy Management Report
Data is an essential resource for most organizations today, yet policy management can be riddled with complexity. The speed and scale at which data is utilized are often at odds with policy management responsibilities meant to maintain its privacy and security. In this report with S&P Global’s 451 Research, we...

Videos
Scaling Dynamic Policies at JPMorgan Chase
Yarik Chinskiy, Chief Architect of JPMorgan Chase & Co., talks about how his company is defining scale and enabling user journeys for his data end users. Yarik discusses the role of dynamic policies and policy as code, along with policy unit tests and observability. Learn more about data security and...

Content Bundles
The Ultimate Guide to Data Privacy in Healthcare and Life Sciences
For Healthcare and Life Sciences (HLS) organizations, data plays a critical role in providing the most effective care and developing innovative treatments. Even more important, however, is ensuring that patient data is not exposed to those who should not have access to it. Data privacy in healthcare requires compliance with a myriad...

White Papers
Five Best Practices for Data Security in Modern Cloud Platforms
How secure is your data? Despite data security and privacy ranking among the top data management priorities in a survey of data professionals, almost half do not think that their data actually is secure. But data demands and usage are continuing to accelerate. To keep up, organizations have a responsibility to know...

Immuta & Data Protection by Design: Making the GDPR Work for Your Data Analytics Environments
Data Protection by Design (DPbD) is the core data protection requirement in the General Data Protection Regulation’s (GDPR) Article 25. In order to comply with the GDPR’s strict mandates on data, understanding how to implement the many different requirements of DPbD is a must. In this white paper, you’ll learn: The principles...

White Papers
Best Practices for Securing Sensitive Data: A Guide for Data Teams
Data security strategies and tactics are not one-size-fits-all. The resources needed to protect sensitive data at a global enterprise are likely very different at a small startup. But data security is essential for any business that collects, stores, and uses data – so, where do you begin? Securing sensitive data is a priority that requires...

White Papers
Data Masking 101: A Comprehensive Guide
Organizations have both a legal and ethical responsibility to protect sensitive data. According to various compliance laws and regulations, this must be done to precise specifications that minimize the risk of re-identification or other threats. Are you meeting this standard effectively? Data masking might help answer that question. Data masking proactively alters...

Videos
Mitesh Shah Discusses Alation’s Partnership with Immuta
Mitesh Shah, VP of Market Strategy for Alation, discusses Alation’s partnership with Immuta and how it helps to ensure that Alation customers are protected with secure data access. To read more, visit this blueprint for implementing Immuta within Alation.

Content Bundles
The Ultimate Guide to Data Security for Financial Services
In the Financial Services industry, data is leveraged constantly in order to derive the most relevant and substantial insights. But where this data comes from – and where it goes – are not always easy to discern. With strict regulatory requirements and reliance on legacy systems, managing data governance for financial services...

eBooks
Building an Agile Data Stack for the Top Data Governance Use Cases
Regardless of size, geography, or industry, organizations are all facing a similar challenge: how to use data effectively without compromising security or customers’ trust. Within the scope of this challenge, there are dozens of data governance use cases. While the specifics of each use case may vary from team to...

Reports
Becoming More Data-Driven Now Requires a Dynamic Data Governance Strategy
Nearly all European organisations consider a digital-first strategy crucial to achieving business results. Still, less than half are able to put these strategies into practice, and just 30% report widespread data use in decision-making. Without a dynamic data governance strategy that can adapt to changing business environments, data and leadership...

eBooks
A Guide to Databricks Data Governance & Security with Immuta
Sensitive data is the most valuable asset for analytics and data science. But if data teams can’t securely prepare it and maximize its utility for real-time access by analysts and data scientists, is it still as valuable? In order to reap the full benefits of the Databricks Data Intelligence Platform, streamlining...

White Papers
Accelerating Data-Driven Insights with Data Mesh
Enterprise products and services create an ever-increasing amount of data, which becomes part of every interaction, decision and process in modern organisations. To enable data democratisation and scale efficient data usage enterprise-wide, many teams are turning to data mesh implementations. Adopting a domain-centric approach promises to increase agility and flexibility, while providing...

Content Bundles
The Databricks Security & Access Handbook
J.B. Hunt saved $2.7M in infrastructure costs and productivity gains. Swedbank doubled its number of data use cases. What can you accomplish with Databricks and Immuta? Immuta enables robust Databricks security, allowing organizations like J.B. Hunt, Swedbank, and other customers to securely leverage all their data – even the most sensitive – for real-time data analytics and...

Playbooks
Immuta’s GDPR Compliance Playbook
The EU’s General Data Privacy Protection Regulation (GDPR) is a sweeping set of privacy regulations that has led the way for data privacy legislation around the globe. It’s not hard to understand why its impact is so widely recognized – organizations that don’t comply face fines of up to 4%...

Playbooks
HIPAA Security Compliance Playbook
The Health Insurance Portability and Accountability Act (HIPAA) governs disclosure by medical providers in the United States. It is the foremost data compliance regulation for the healthcare and life sciences industry, levying fines ranging from $100 to $1.5 million. Needless to say, it’s imperative that healthcare companies incorporate HIPAA security compliance into their data security...

Solution Briefs
How to Make Life Easier for Enterprise Data Architects
Enterprise data architects are facing a triad of challenges in the current state of analytics due to the shift to cloud data platforms, the need to support varied workloads across BI and data science, and the growth of sensitive data being collected for analysis from increasingly digital channels. Amid all of these...

Solution Briefs
How Immuta Enables a Zero Trust Architecture
Traditional perimeter-based information security can no longer offset the safety risks posed by work-from-home models and cloud infrastructure adoption. Zero trust architectures offer a secure solution to these threats, but can in turn slow the access to and insights from important data. With an increased federal focus on this approach...

White Papers
The Five Data Localization Strategies for Building Data Architectures
As an intangible asset, data is not physically restrained. But data localization laws are changing that notion. The number of global data localization laws dictating data residency and sovereignty has more than doubled in just the past five years. With data sharing and collaboration across borders now an essential part...

Reports
DBTA Report: Meeting the Growing Challenges of Data Security & Governance
Risks to data are at an all-time high, with the global average data breach now costing organizations $4.45M – a 15% increase in three years. That’s on top of the reputational damage and bottom-line impacts most organizations experience in the wake of a breach. With the explosion of generative AI – and...

eBooks
How to Build a Governance, Risk, and Compliance Framework for Enterprise Data Analytics
Designing and implementing a governance, risk, and compliance framework that supports data analytics is far from intuitive. But with increasing sensitive data use, it’s an imperative. While technology has come a long way in helping to manage risk and compliance, it cannot also resolve the challenges of organizational design and culture, resources,...

White Papers
Zero Trust Solutions for Federal Agencies
This Executive Order, and the subsequent memo M-22-09, outlined the federal government’s plans to implement Zero Trust architectures for improved national cybersecurity. They also made specific calls for proper data access control methods, and placed a new emphasis on the data central to these networks. We’ve taken the required actions from these directives and...

eBooks
2022 Data Access & Analytics Trendbook
Where might the evolution of data access and analytics lead next? There’s no definitive answer to this question. But experts across industries who are driving innovation with data can give us a clue. We’ve compiled a range of expert outlooks on the state of data in an effort to understand...

White Papers
RBAC vs. ABAC: Future-Proofing Access Control Models
Is the access control model you choose really that important? It turns out, the answer is an emphatic yes. Data access control models, which refer to the system of controls put on data and technology assets to determine who has permission to access them, continue to evolve alongside modern data use. Models like...

eBooks
Securing the Snowflake Data Cloud with Immuta
As cloud data workloads, regulations, and ecosystems evolve, managing data security at scale can be complicated, time-consuming, and downright overwhelming. For organizations leveraging the Snowflake Data Cloud, being able to access Snowflake data efficiently is critical to driving business outcomes and achieving ROI. Immuta’s native integration with the Snowflake Data Cloud helps customers strike the...

Videos
The Keys to Enterprise Digital Transformation with Immuta & Intel
An enterprise digital transformation refers to the integration of digital technologies and strategies into all aspects of an organization, fundamentally reshaping its operations, culture, and customer experiences. In today’s rapidly evolving business landscape, enterprise digital transformation is crucial for staying competitive and responsive to market demands. But enterprise digital transformation...

Content Bundles
The Ultimate Guide to Cloud Data Access Control in Snowflake
With Snowflake and Immuta, data teams are able to harness the power of the Snowflake Data Cloud with the flexibility, scalability, and transparency of Immuta’s automated data access controls. Organizations leveraging Immuta’s native integration with Snowflake have saved more than $1M in data engineering costs, while ensuring their data remains...

Reports
2022 State of Data Engineering Survey
Emerging Challenges with Data Security & Quality Organizations have been investing in data science, analytics, and BI resources and tools for years to reap the benefits of data-driven decision-making. But as sensitive data use has become more common – and even expected – and data rules and regulations expand and...

Playbooks
Enabling a Zero Trust Model for Data Analytics
For organizations in the public and private sectors, zero trust is the future of data security. With the rise of remote work, bring your own device (BYOD), and cloud-based operations, zero trust models help protect digital assets in a perimeterless world. The zero trust framework assumes that all devices, users, and applications are potential...

White Papers
The Guide to Enforcing Access Control Policies with Your Data Catalog’s Metadata
You’ve invested in a data catalog to reap the benefits of self-service data discovery and usage that drive analytics and data science – now what? How do you ensure that as your data consumers grow, the right data is available to the right people without risking misuse or non-compliance? The bottom line...

White Papers
A Guide to EU Data Anonymization Standards
The EU’s General Data Protection Regulation (GDPR) is among the most influential data compliance laws and regulations in the world – setting the standard for how global organizations implement their data security and privacy programs. What Are the EU’s Data Anonymization Principles? While the GDPR does not explicitly define a data anonymization standard, it...

Reports
Data Governance & Management Report: The Data Supply Chain
The Growing Complexity of Data Governance & Management As the demand for data has grown — alongside constantly evolving compliance laws and regulations dictating its use — data governance and management have become increasingly complex. Maintaining visibility into how data is being used and by whom, and constantly updated policies accordingly, requires...

Videos
How IAG Scales Secure Insurance Data Management with Immuta
Insurance Australia Group (IAG) is Australia and New Zealand’s largest general insurance company, with more than $14B in premiums underwritten annually. Since the company handles sensitive personal information to generate quotes and process claims for its customers, data security and governance are top priorities. To ensure that IAG was able...

Reports
GigaOm Data Access Control Report: Immuta ABAC vs. Apache Ranger RBAC
GigaOm cloud data security report finds Immuta’s data access control 75X more efficient than Ranger’s. The data access control debate over role-based access control vs. attribute-based access control is over. In a head-to-head comparison by GigaOm, Immuta’s attribute-based access control (ABAC) required 75X fewer policy changes than Ranger’s role-based access control (RBAC) to accomplish...

White Papers
How to Avoid the Top Data Access Governance Challenges
The vast majority of organizations – an estimated 90% – now leverage a multi-cloud architecture for data storage, compute, and analytics. And it’s not hard to see why. The cloud offers seemingly endless benefits — cost savings, increased productivity, real-time analytics, and decoupled compute and storage, to name a few. But managing data...

Reports
TDWI’s Modern Data Governance Best Practices Report
What Is Modern Data Governance? Modern data governance refers to a framework that orchestrates an organization’s cloud data management strategies, policies, and practices in alignment with evolving technology and regulatory requirements. It encompasses important components like data security, privacy, quality, and compliance, while also enabling accessibility and availability. Why Should You Care About...

Reports
Immuta Data Engineering Survey: 2021 Impact Report
We’re on the verge of a perfect storm for modern data access governance. As organizations lean into data and the cloud, new research shows that the majority will adopt multiple cloud compute technologies within the next two years. Data teams need a modern framework, architecture, and suite of tools to...

White Papers
Seven Steps for Migrating Data to the Cloud
Migrating data to the cloud doesn’t happen overnight, nor does it happen in a vacuum — it requires a careful planning process to ensure all systems work as they should. That includes a system for protecting sensitive data. Failing to plan for data security and access control in the cloud migration process could...

White Papers
How to Securely Use De-Identified Health Information
In today’s data ecosystem, threats are abundant. From unintentional data leaks to orchestrated external attacks, organizations have an obligation to prepare for – and mitigate the incidence of – any potential risks. In no industry is this more true than healthcare and life sciences, which routinely has the costliest and most...

eBooks
Layers of Trust
Data security is a driving force, particularly for organizations making the move from on-premises databases to SaaS-based data warehouses where users outside the organization need to be trusted at some level. This massive shift to the cloud – with its security concerns – has been coupled with a rapid increase...