 Discover
Discover
 Secure
Secure
 Detect
Detect







“If you don’t automate around your security and simplify it, the biggest problem you’re going to have is some human making a mistake. I don’t have to worry about building security tools. The possibilities exist for us in a real sense because we can get to that level of finesse around our controls.”
Covering the Full Data Security Spectrum
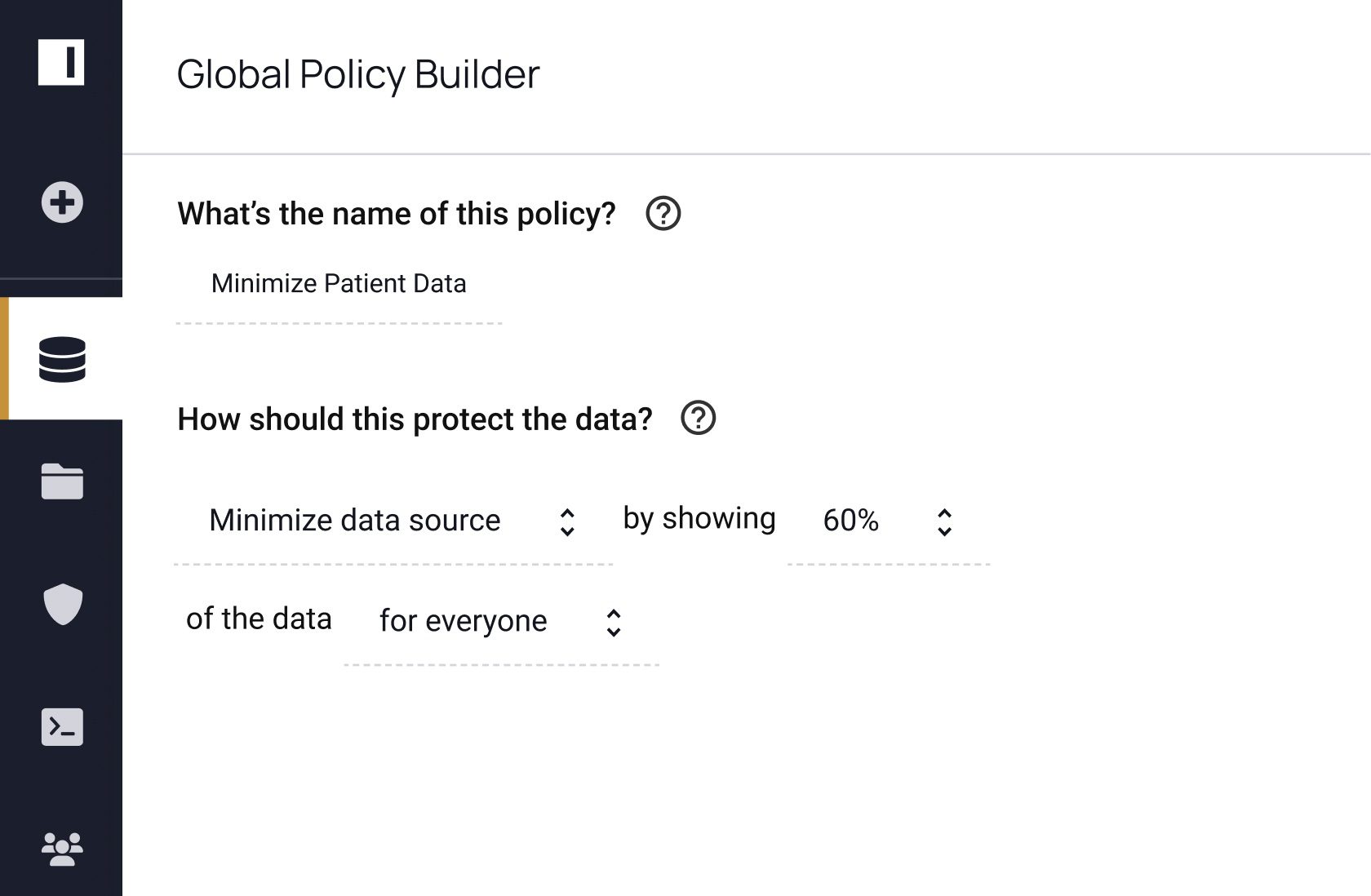
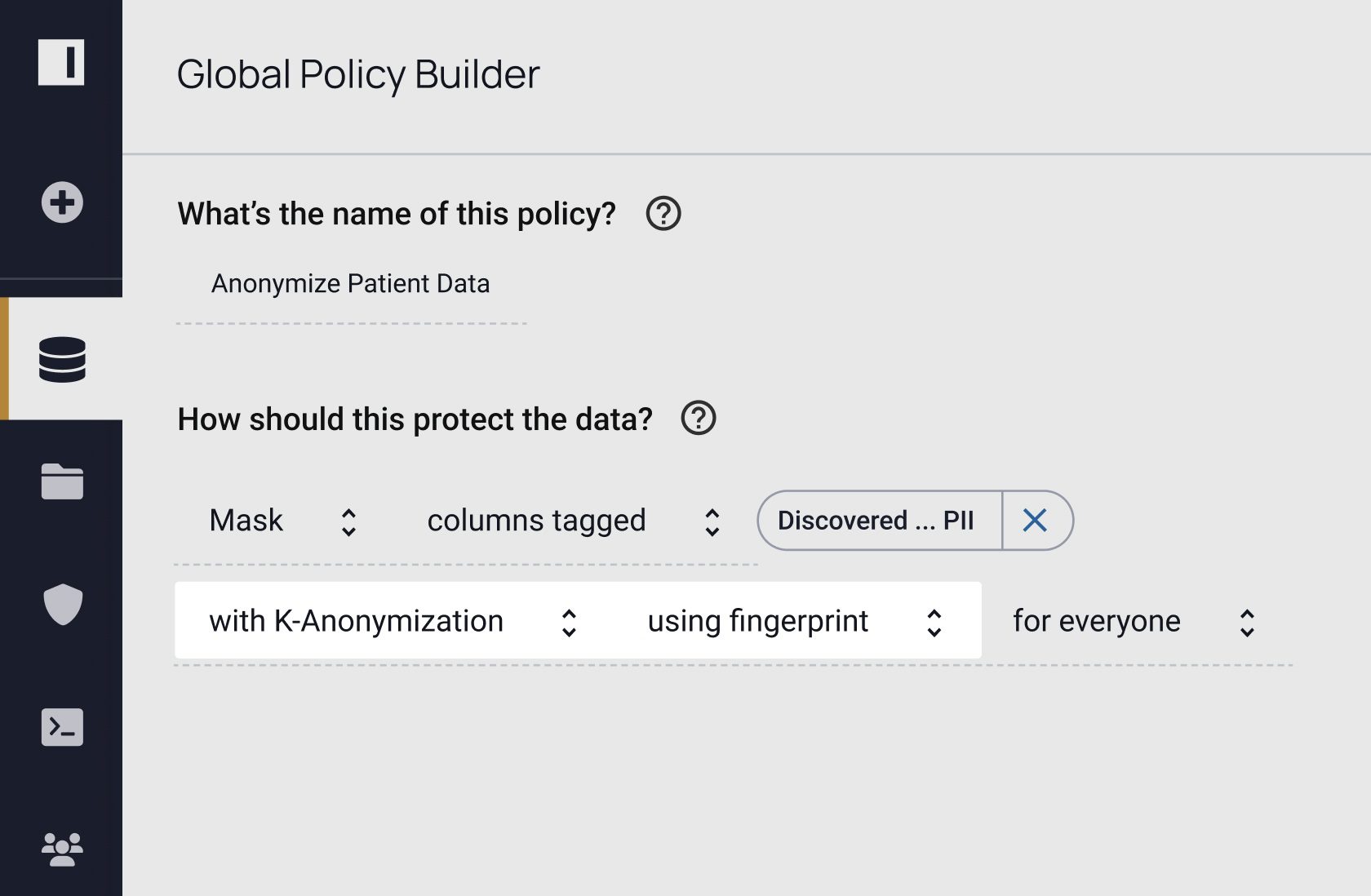
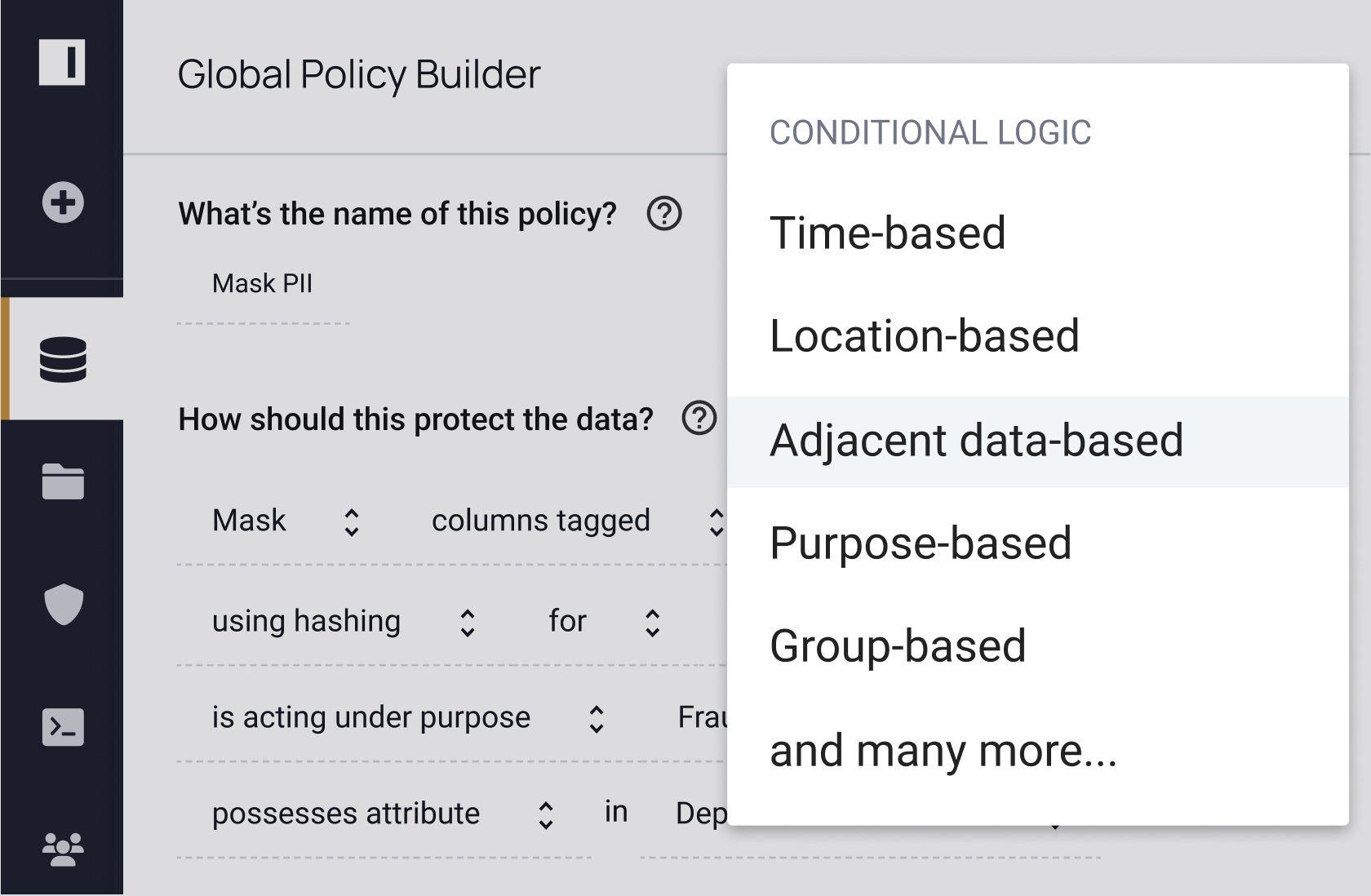
How do you know where to apply data masking policies and if those policies are working? Dynamic data masking is a key part of data security, but it’s one piece of the puzzle. With Immuta, you can discover, secure, and monitor data to detect risks. See how you can do all three – without sacrificing speed or utility.