
A data mesh is an increasingly popular data architecture framework that moves away from the monolithic approach of data warehouses and data lakes in favor of a more decentralized method of cloud data management.
This approach distributes data ownership to individual business domains, so that data access and management decisions are context-aware. As a result, domain teams can efficiently collaborate and produce useful data products without creating bottlenecks or straining IT resources.
The data mesh architecture is designed to address three key questions inherent in data warehouses and data lakes, namely:
- Who owns data – the team that is the source of the data or the team providing the infrastructure for housing the data?
- Who is responsible for data quality? Typically the infrastructure team assumes this responsibility, but they are not necessarily deeply familiar with the data itself and may therefore require additional resources.
- What happens when an organization needs to scale while avoiding data bottlenecks, a common problem with data warehouses or data lakes?
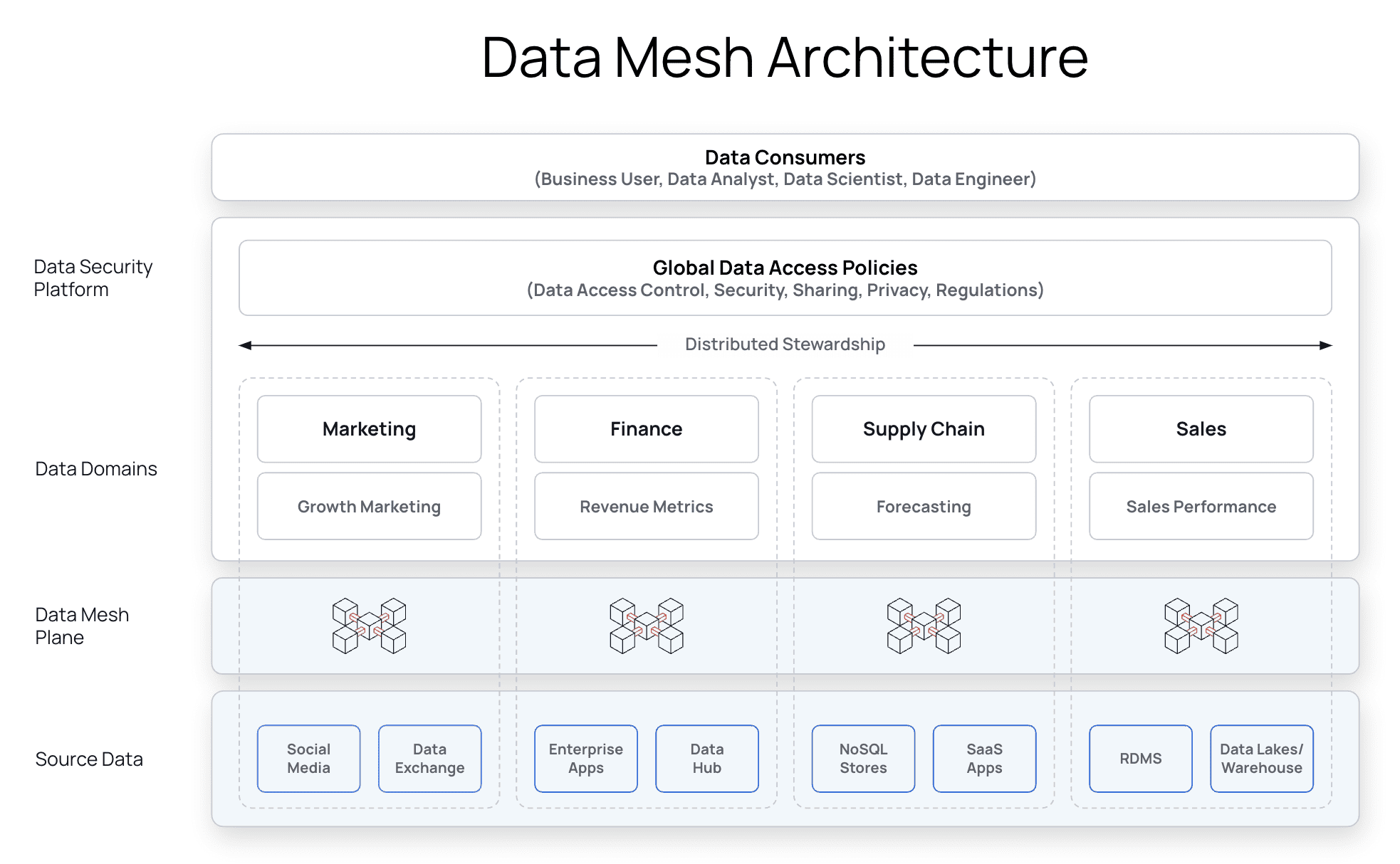
Data Mesh Architecture
Data mesh architectures are built on four key pillars:
- Domain-oriented ownership: Rather than a centralized team, this approach delegates data ownership to individual domain teams. This puts the people closest to the data in control of their own data quality, reliability, and accessibility, so it is leveraged in a way that’s relevant to business needs.
- Data as a product: Data products are containerized solutions built to address a specific business or end user need. With data put in the hands of domain owners, data mesh architectures treat data as a product that consumers across functions are able to easily discover and tailor for specific use cases.
- Self-service data infrastructure: To operationalize a decentralized data mesh, domain teams must have the infrastructure to manage their own data pipelines, cataloging, processing, and data access control. This self-service approach keeps the management burden from falling entirely on centralized IT teams, so domain-level data use is efficient and scalable.
- Federated computational governance: This distributed structure necessitates governing data at the domain level while maintaining centralized oversight. This way, data security can be effective and efficient, without hindering collaboration or accessibility.
The best domains are easily discoverable, self-service, highly secure with flexible data access control. As you can see from the diagram below, each data domain has its own areas of focus and data sources. With purpose-built data mesh planes, each is better able to focus on specific objectives without getting bogged down by other teams’ competing priorities.
Why Is Data Mesh Important?
Many consider data mesh to be the future of data management as companies move away from a single data warehouse (traditional or cloud-based) or data lake, which generally rely on technical specialists, tend to incur technical debt, and provide teams with less control over growing data pools. As unique data use cases proliferate alongside growing volumes of data and users, leaning heavily on a single, centralized platform becomes less practical.
Organizations increasingly also deal with inefficient data supply chains – data producers that are out of the loop, data consumers who are constantly delayed by bottlenecks, and data platform teams that don’t have the resources to keep up with massive amounts of data and fast-paced data demands of their business.
A data mesh has the potential to solve all of these problems by combining a centralized data hub with a series of spokes (domains) that are each responsible for a data pipeline. This theoretically allows for improved data scalability over time, when executed correctly.
That said, for all its potential benefits, the data mesh architecture also has its share of potential challenges.
Challenges & Benefits of Data Mesh
Let’s compare some data mesh implementation obstacles with the benefits of a successful switch from a centralized architecture to a data mesh.
Challenges of a Data Mesh
Data mesh is not necessarily right for all organizations. For instance, it’s generally not particularly well suited for organizations that do not have large data domains. Organizations with smaller-scale data needs and less potential confusion about who is in control of data may find that implementing a data mesh architecture is not worth the effort of transitioning from existing processes. Doing so could ultimately prove to be even more confusing and complex.
Meanwhile, the tools available for enabling data access control in a data mesh architecture are currently limited. Traditional RBAC (role-based access control) approaches lack the scalability that data mesh paradigms require, which limits implementation and effectiveness. For Roche Diagnostics, this proved to be a key challenge.
“It didn’t take a week or two and we were flooded with requests for customized roles,” said Claude Zwicker, the former Lead Data Architect at Accenture who worked with Roche’s team on its data mesh implementation. You can hear more about their data mesh journey here.
Organizational buy-in is also key to successfully implementing a data mesh, but can cause headaches if treated as a second tier priority. Data teams must have cross-functional alignment and executive-level support in order to make such a drastic mindset shift stick.
Finally, data virtualization is a process still rife with potential challenges that are outside the scope of this article, but which could stand in the way of a successful data mesh implementation.
Benefits of a Data Mesh
Despite a few potential challenges, a data mesh can deliver significant benefits and results. Chief among these is the ability to avoid the politics of ‘data sovereignty,’ or confusion over who is responsible for the data coming in from a range of different sources.
Because a data mesh puts control of data into a series of domains based on those domains’ specific needs, there’s no single data ‘owner.’ This not only helps streamline operations and decision making, but can also reduce confusion and frustration within your organization.
Under a data mesh approach, domain teams enjoy greater autonomy when creating and using relevant data, while data users benefit from global interoperability standards and independent data products with their own value. With the right controls in place, governance and compliance stakeholders also have peace of mind that data use is secure and auditable.
Finally, a data mesh removes the burden of centralizing responsibility to a single team. Data product managers have control over their specific data domains, removing bottlenecks that often plague monolithic architectures and improving efficiency across the enterprise. Plus, a data mesh architecture can ensure that your data ecosystem can scale as data sources, use cases, and access models increase.
35,000 data professionals receive our Immuta Unlocked newsletter.
Subscribe to stay up to date on the latest insights, best practices, resources, and more.
When to Consider a Data Mesh
Data mesh is most useful for large, complex organizations that have difficulty managing and scaling secure data use due to IT bottlenecks, data silos, lack of clear data ownership and context, and highly scrutinized compliance concerns, among others.
When determining whether or not you should move to a data mesh architecture, consider the following questions:
- How many sources of data does your company deal with on a regular basis?
- How large is your data team, including analysts, engineers, product managers, and other roles?
- How many non-data teams (sales, operations, marketing) at your organization use data to make key decisions?
- How many products does your company offer?
- How many products or features currently exist or are being built that will be heavily data-driven?
- How often do bottlenecks slow the momentum of implementing new data products?
- Are data security and access control major priorities at your organization?
- Do you have/will you be able to secure cross-functional buy-in?
When managing large data sources, various data consumers, and a range of use cases, a data mesh architecture could provide substantial benefits that bypass inefficient processes and allow you to get more out of your data.
Looking for a data security platform that helps effectively and securely implement a data mesh architecture across your organization? Immuta provides automated self-service data access with dynamic data security, consistently across all of your cloud data platforms. Its data monitoring detects potential threats, so you can proactively respond to anomalous behavior and easily audit data access for compliance.
“We replaced our access control roles within Roche from 300-plus roles down to one…using Immuta’s attribute-level access control feature and the new table grants access feature,” said Paul Rankin, Head of Data Management Platforms at Roche. With less overhead, the company has streamlined domain data ownership and access, without sacrificing security.
Ready to learn more? Check out this webinar with Immuta, Snowflake, and Roche about building and implementing a data mesh architecture.



