The AI Security & Governance Report
Learn what 700+ data professionals think about the future of AI/ML tools.


Advancements in Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing the way we work with data across sectors. By enabling enhanced decision-making and faster operations, these models present us with unparalleled capabilities – but they are not immune to some very human problems.
One of the most critical challenges in AI/ML development is addressing and mitigating unintended bias. Even with the capacity to analyze and derive real-time insights from data, models are still corruptible by long-standing human biases and prejudices.
With a history of designing, developing, and deploying IT systems for organizations – from telecommunications companies to the Federal government – I’ve worked through the integration of many new and evolving technologies into the modern tech stack. In this blog, we’ll explore the concept of bias in AI/ML data sets, and examine the tools, processes, and best practices for combating bias in these evolving models.
It’s no secret that modern data sets often contain biases, whether intentionally or not. This may be caused by a range of factors, including:
Bias can also impact how AI/ML models are configured. Any of the aforementioned biases are likely to play a role in how teams build, train, and deploy their models, which impacts the results they produce. Each of these factors contributes to data sets and models that are neither representative nor accurate.
To recognize the impact of biased data sets and model configurations on the legitimacy of AI/ML tools, think of the phrase “you are what you eat.” This gets to the core of AI models – they are trained entirely on the data they are fed, and therefore will base their decisions and output completely on that information.
If these models are fed biased data, it’s likely to lead to unfair or discriminatory outcomes. For instance, models trained on biased healthcare data are apt to under-represent certain demographic groups, ultimately leading to inequitable healthcare recommendations for those groups.
Before digging into how to combat bias in AI/ML, it’s important to note a few common challenges to minimizing these biases, including:
Though it is impossible to eliminate all bias in existing data sets, there are still plenty of ways to minimize it.
Using the Immuta Data Security Platform, your team can limit the impact of data bias by coupling data security controls and purpose-based access control (PBAC). This methodology provides guardrails for data scientists, enabling them to make use of data for model creation while minimizing the potential for bias.
This is done using the following steps:
The first step to reducing bias in models is understanding where sensitive data resides in the enterprise by carrying out data discovery and classification. Out of the box, Immuta’s sensitive data discovery automatically discovers more than 60 types of personally identifiable information (PII), financial data, and protected health information (PHI) shown in the image below. You can also create new rules to classify unique data elements within the enterprise. This highly customizable approach ensures that your organization’s specific data types are recognized for appropriate classification and protection via access policy enforcement.
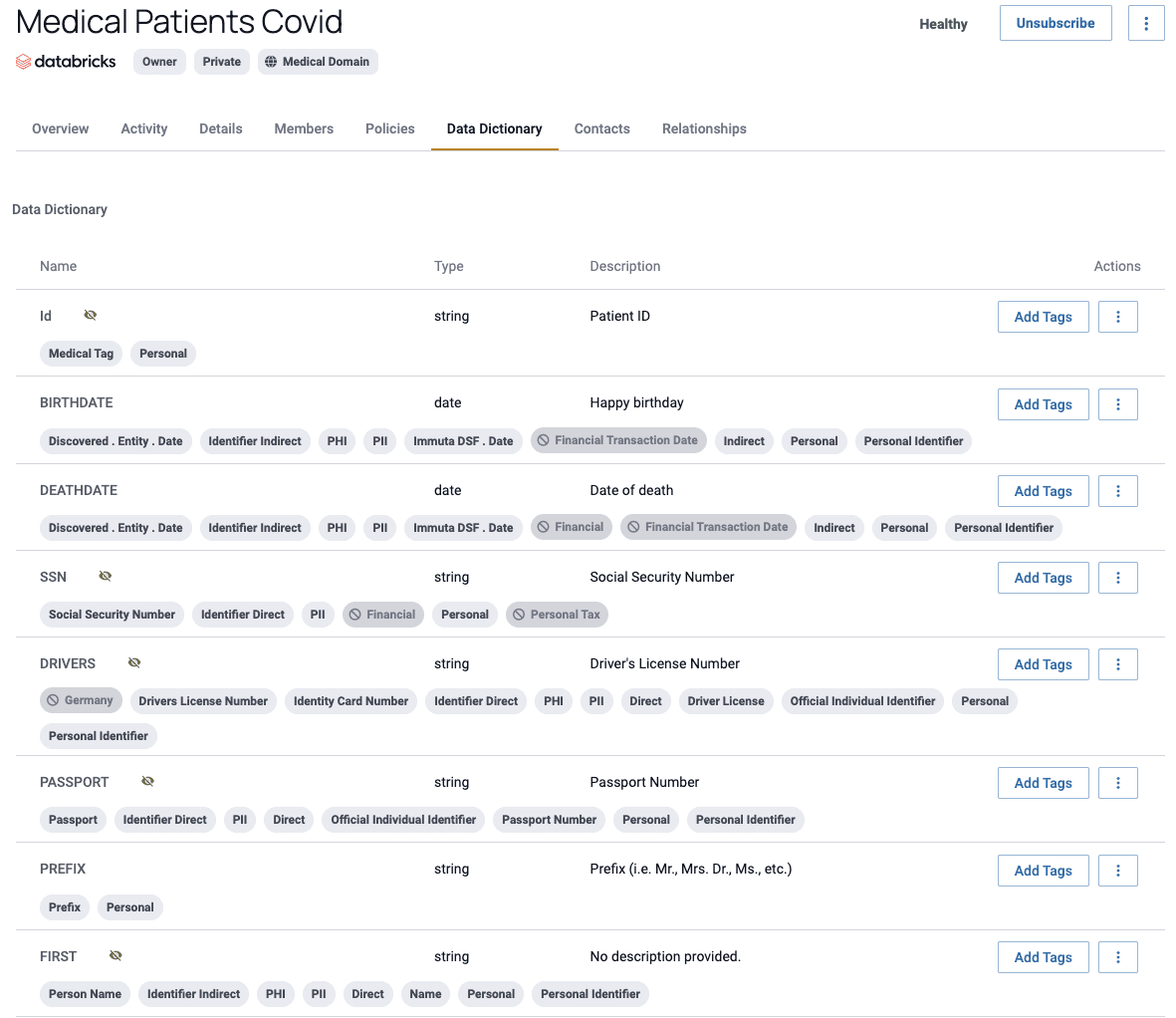
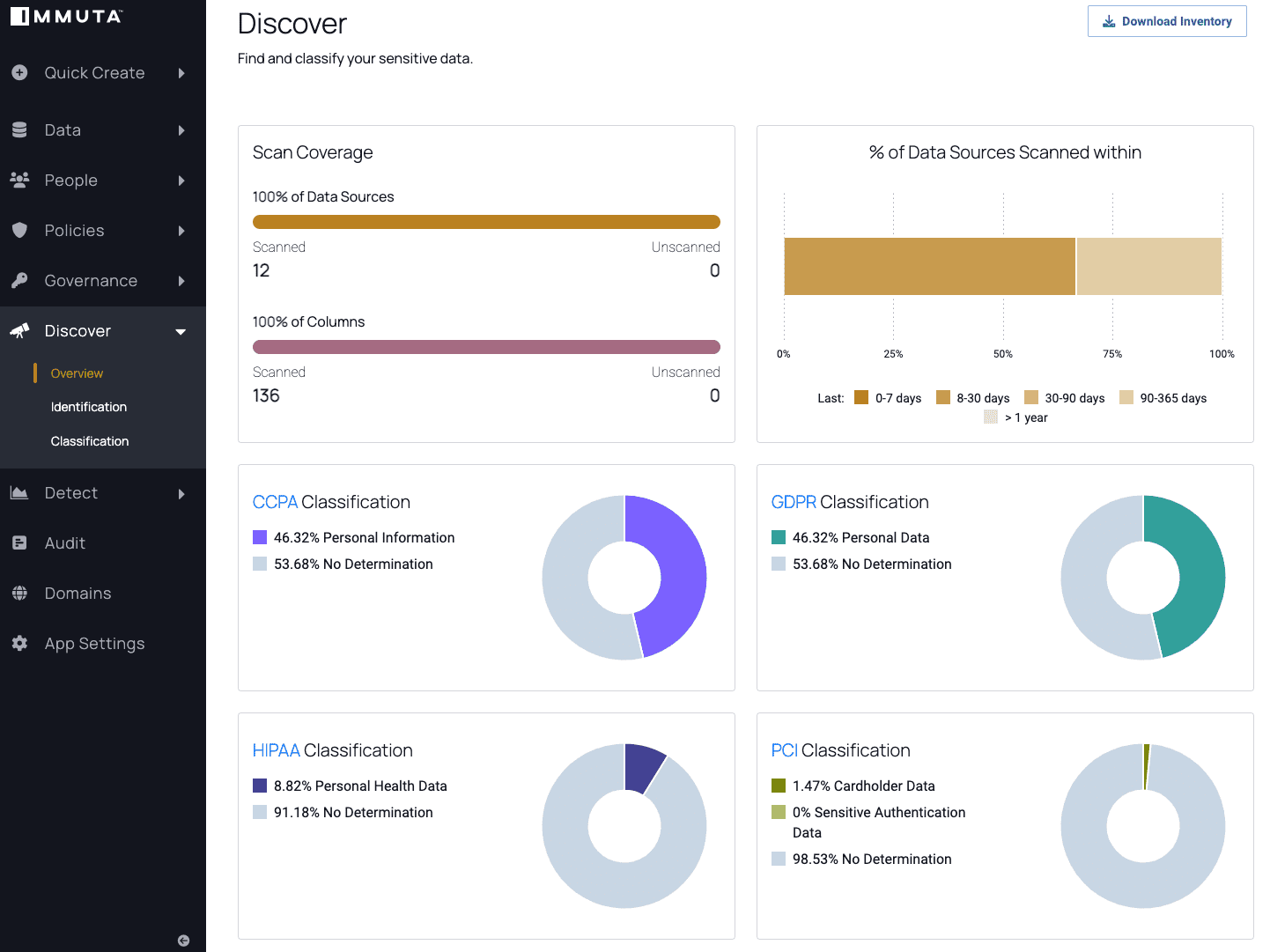
Following discovery and classification, data stewards can view dashboards in Immuta to ensure all data sources have been scanned. They can also see the percentage of data that falls under a classification framework, such as the Health Insurance Portability and Accountability Act (HIPAA) or the European Union’s General Data Protection Regulation (GDPR).
With an understanding of where sensitive data resides, stewards can begin creating data policies to ensure that information is protected from unauthorized use – including in AI/ML models.
Leveraging the metadata tags, and data and user attributes sourced from Identity, Credential, and Access Management (ICAM) solutions, data stewards build data access controls to filter rows, mask columns, or apply cell-level security. These include both purpose-based and attribute-based access controls (ABAC), which enable teams with dynamic control over which users can access which data sets.
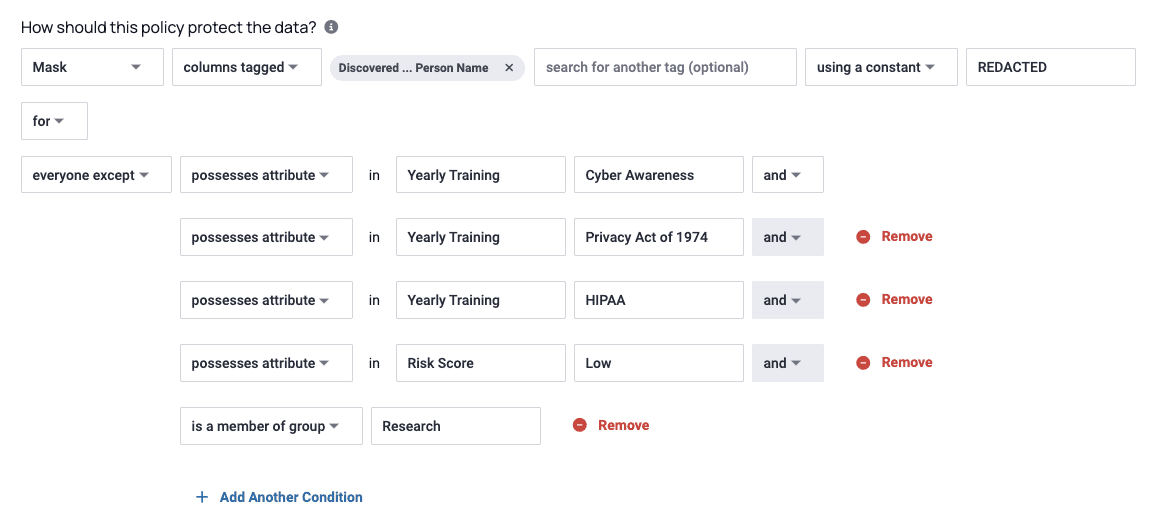
Immuta’s plain-language policy editor allows you to author and enforce policies with just a few clicks – no coding expertise necessary. For instance, you could create a masking policy that redacts subject names for all users except those with specific levels of training (shown below). When policies are activated, they are pushed down to and enforced on connected data platforms, like Snowflake, Databricks, and AWS. This highly scalable approach poses no performance impacts to end users.
Applying purpose-based access controls ensures users only access specific data sets under predefined legal or enterprise purposes – without requiring data to be copied or moved. Therefore, these controls support the purpose specification and limitation requirements included in data protection legislation and enterprise AI/ML governance policies.
An example of a purpose-based control for ethical AI/ML development includes requirements to create a model card, provide model performance metrics with and without potentially bias-causing features, and share training and testing data sets for analysis.
Immuta also allows data to be masked or filtered from data scientists in a process called feature blinding – in which the model is blinded to specific features or protected attributes, such as race and gender, during model training. These potentially bias-causing features, however, can still be opened to data scientists working under a specific purpose. Feature blinding effectively reduces bias since the model was not trained on those features they cannot be used in decisions. This enables data stewards to develop data masking policies to feature-blind sensitive data. Using this methodology allows data scientists to utilize imperfect data while reducing risks of unintended impacts.
Minimizing bias is not a “set and forget” process – it requires continuous security monitoring to ensure that models are operating in their intended, bias-free manner.
Data detection and user activity monitoring help identify potential risks, so you can proactively mitigate or respond to them. Immuta captures the audit records of all actions taken within the application, as well as the queries executed on the protected data platform, to give you insights into data access behavior, query histories, sensitive data indicators, and configuration and classification changes.
Immuta also enriches the data platform audit records with information about user entitlements, and shows whether they were working under a specific, authorized purpose. This is important for understanding what data a data scientist viewed and if they were conforming to the rules of a purpose-based control.
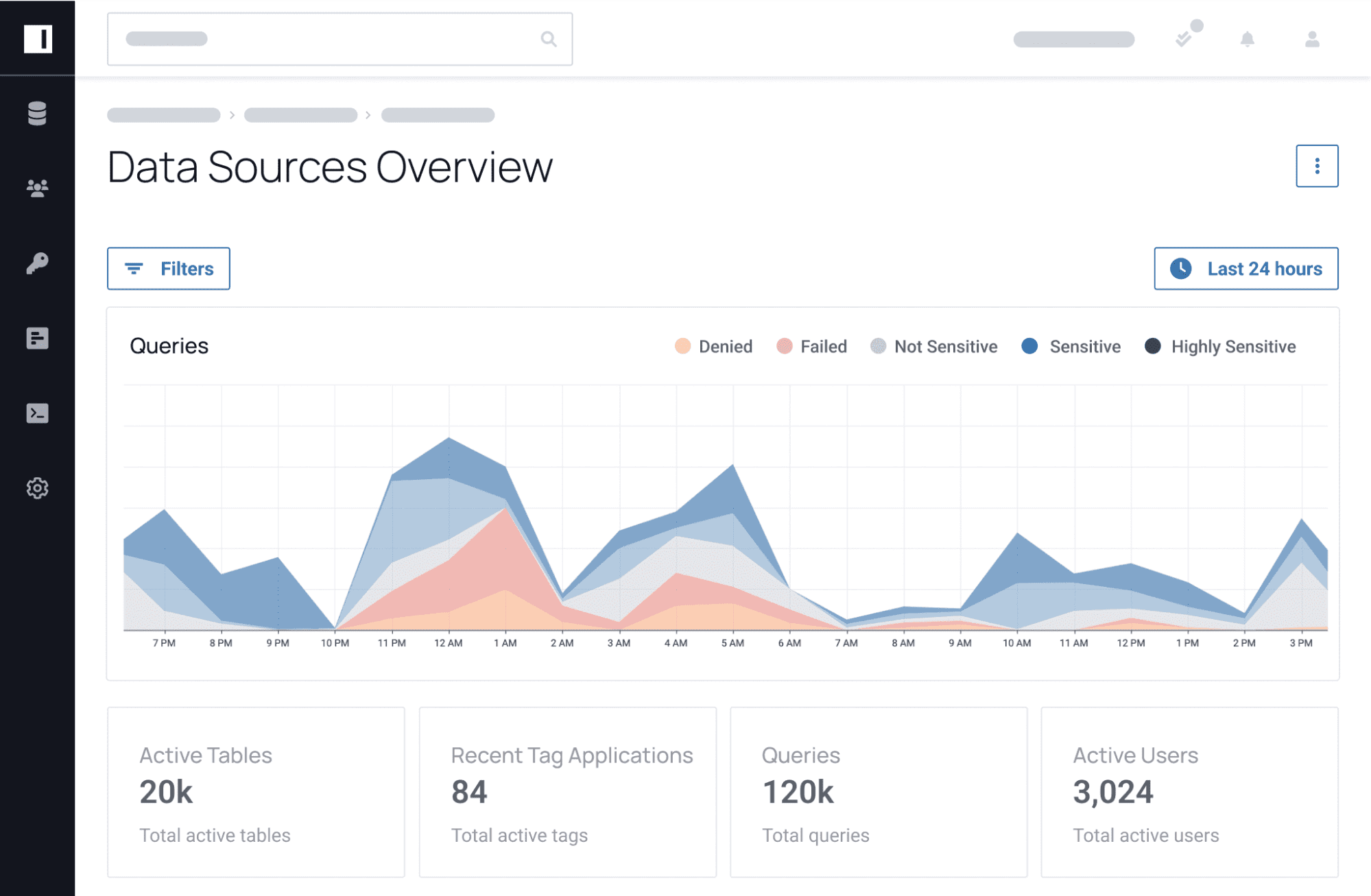
All audit records Immuta captures can also be forwarded to a Security Information and Event Management (SIEM) system to be compounded with other network, server, and application logs and metrics. This supports the security team in understanding all their network users’ actions.
Mitigating bias in AI/ML models is an ongoing challenge, requiring a combination of advanced tools, robust processes, and continued research. By taking action to proactively minimize bias in your data sets, you will develop fair, more reliable AI/ML models that create equitable outcomes.
Immuta’s capabilities enable enterprises to de-risk AI/ML models by automatically discovering sensitive, bias-causing data, enforcing feature-blinding and purpose-based controls, and auditing data scientists’ data interactions. By taking a risk-reduction approach to mitigating bias, you will open more data for users to create evidence-based decisions through AI/ML models.
To learn more about how Immuta empowers data owners, stewards, and AI governance professionals to minimize bias, request a demo from our team. To see what more than 700 data professionals think about the future of AI/ML tools, check out The AI Security & Governance Report.

Learn what 700+ data professionals think about the future of AI/ML tools.


