
As data moves among the storage, compute, and analysis layers of a data stack, there is constant need for measures to ensure its security and protect personally identifiable information (PII). This security is often required by law, as is evident through financial regulations like PCI-DSS, the Gramm-Leach-Bliley Act, and more.
Immuta’s integration with Databricks helps give users peace of mind that their data is only accessed by the right people at the right time, as long as they have the right. One of the key facets of the integration is dynamic data masking, a cornerstone of modern data access and security.
In this blog, we’ll demonstrate how Immuta and Databricks allow users to seamlessly mask PII to comply with financial regulations.
Register a Databricks Table with Immuta
Let’s take a closer look at Immuta’s data masking in practice, using a mock credit card transaction table in Databricks. This example will involve two users, one who is an Analyst and the other who is in Finance.
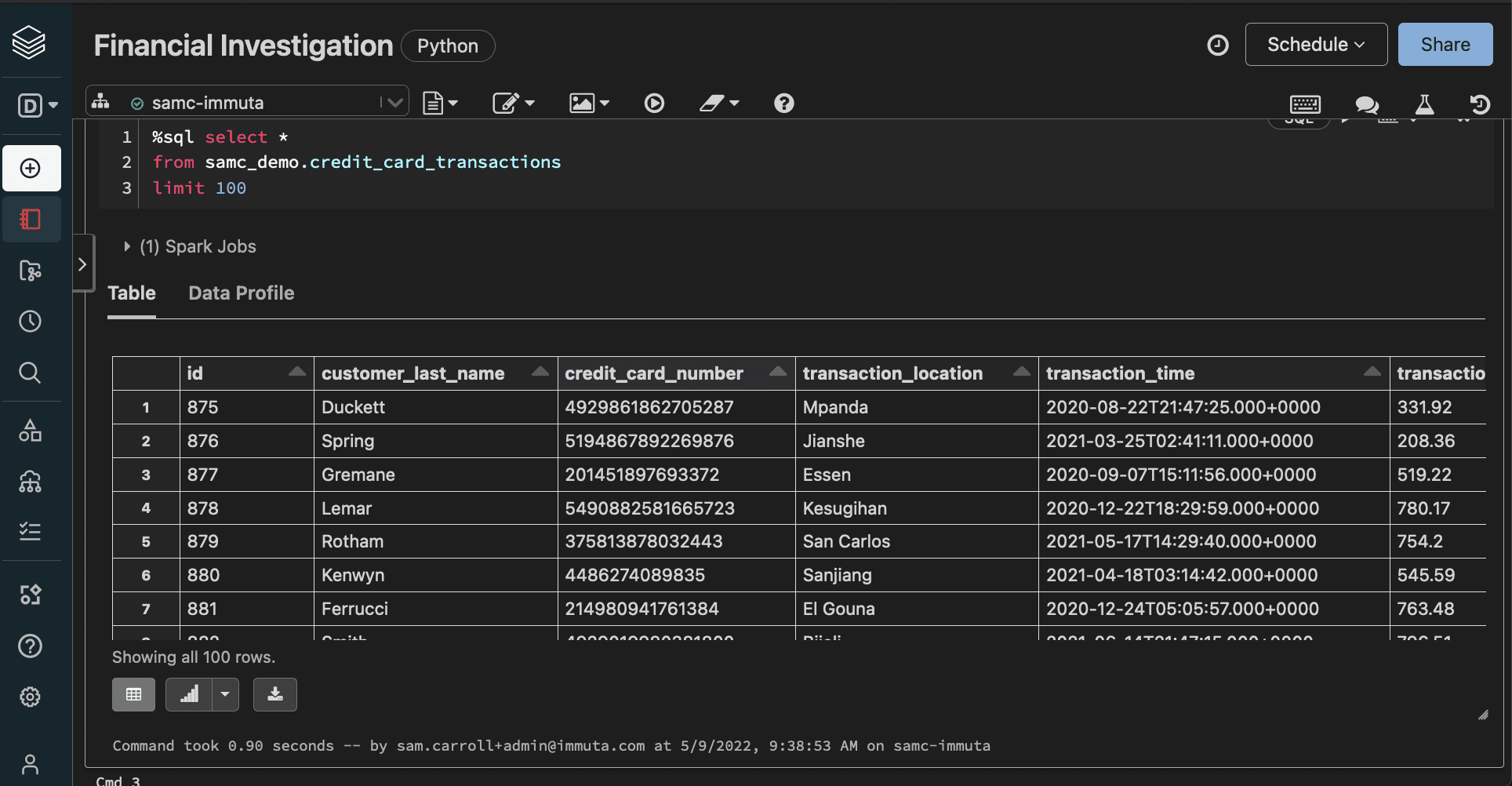
When you first register a table in Immuta, our platform uses sensitive data discovery to analyze all registered data and classify it based on sensitive attributes. The sensitive PII in this table, ranging from names and addresses to credit card numbers, would all be classified during the SDD process. This process is carried out for any data set that is registered with Immuta, including all those that run through Databricks.
Users can also add their own documentation regarding the data, tagging and classifying it in a customized manner. This can include metadata about what type of data is included in the set and where it originated. Immuta also ingests existing metadata from third-party platforms like Alation and Collibra.
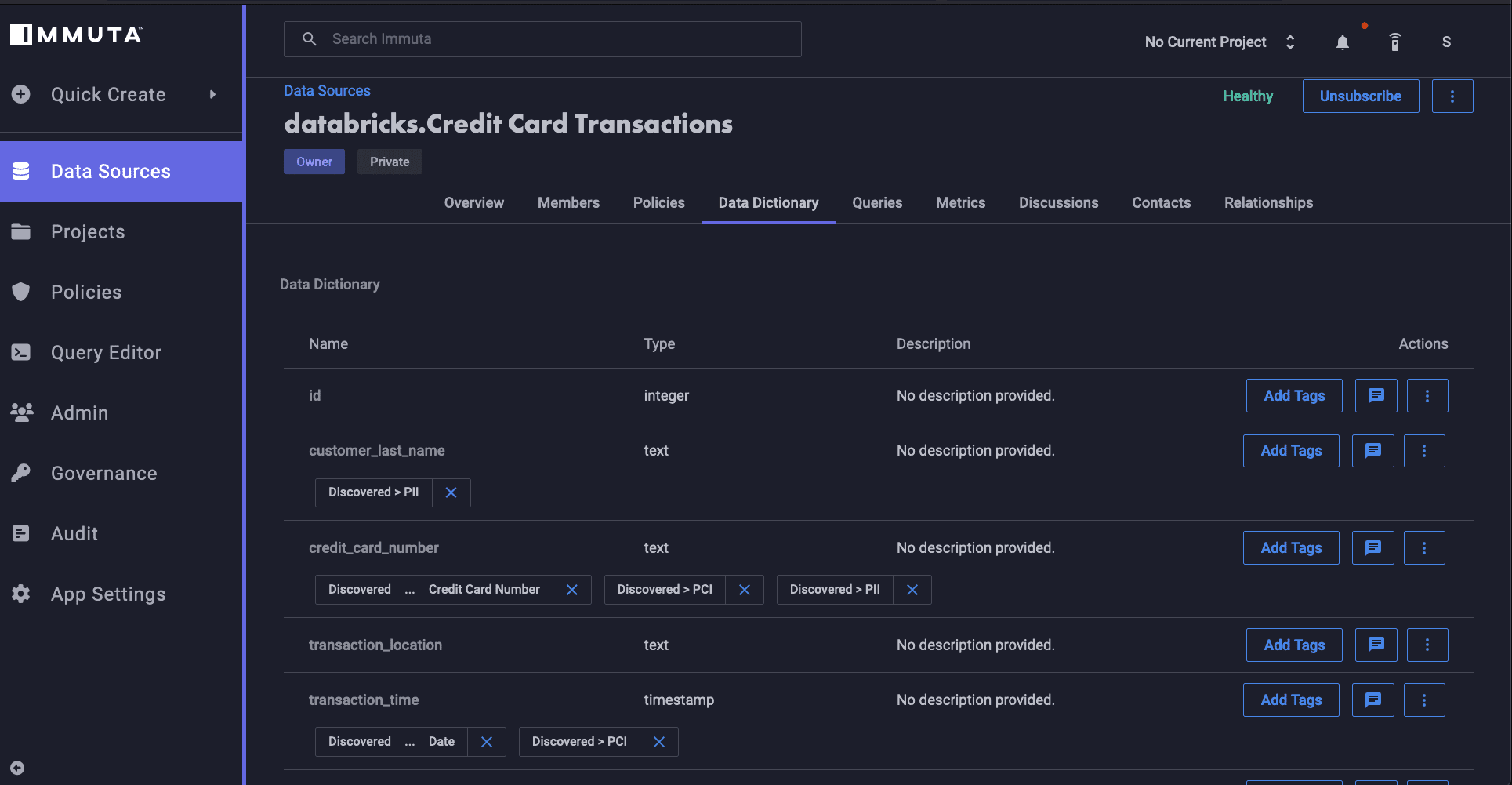
Create a Policy in Immuta
Next, we will use Immuta’s plain language policy builder to protect the sensitive data in the credit card data set. Based on dynamic attributes, roles, and purposes, these policies are enforced at each query time and an audit log is maintained to check compliance.
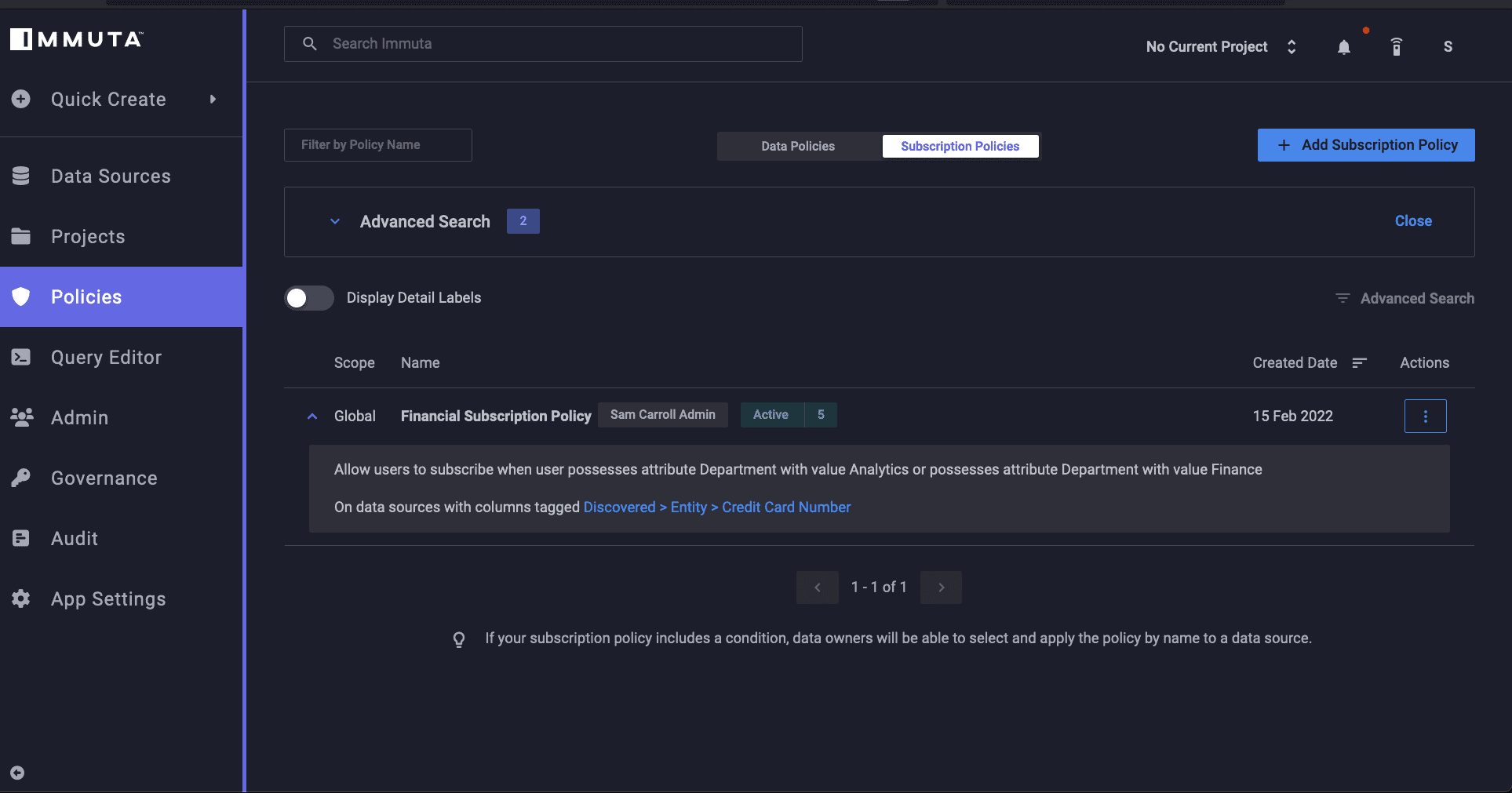
Since we need to mask the PII in the credit card table in order to maintain regulatory compliance, we’ll create the following plain language policy in Immuta:
“Allow users to subscribe when user possesses attribute Department with value Finance or possesses attribute Department with value Analytics On data sources with columns tagged Discovered>Entity>Credit Card Number”
This policy allows users in the Finance or Analytics departments to view the credit card information in this table.
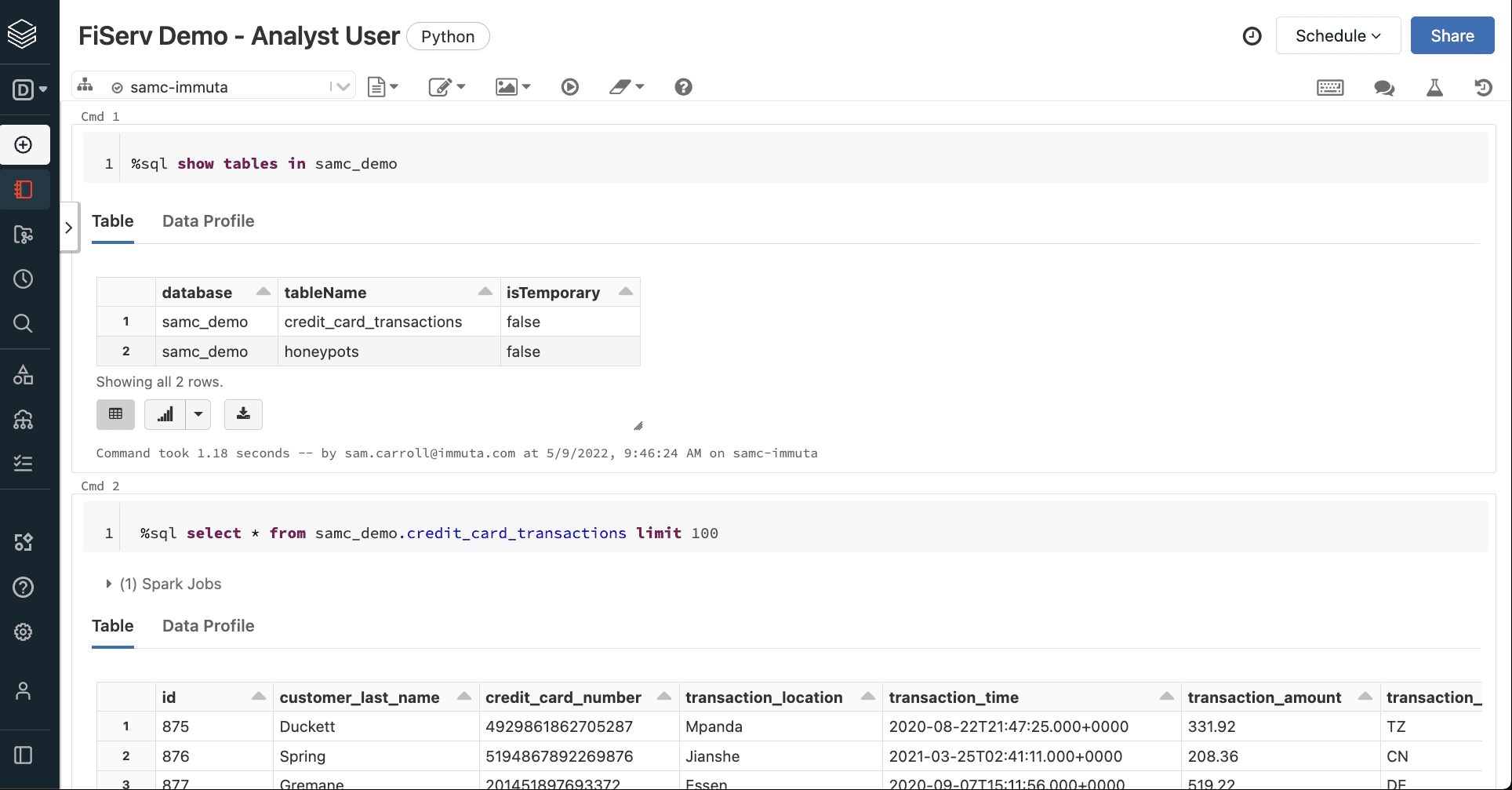
If the Analyst ran a query before this policy was enforced, they would not be able to access the PII in this data set. However, when we look at their profile after implementing this policy, we can see that they are now able to view this sensitive information and fulfill their job purposes. When the query is re-run, the information from the data set becomes visible.
Mask PII with Purpose-Based Access Control
Now that we’ve restricted data access to specific groups, we need to implement a policy that masks the PII data in this data set. Because regulations like PCI-DSS require the restricting of access to sensitive financial data, we’ll need to use our plain language policy creation tool to make the following policy:
“Mask columns tagged Discovered>PII using hashing for everyone except when user is acting under purpose Fraud Detection and possesses attribute Department Finance”
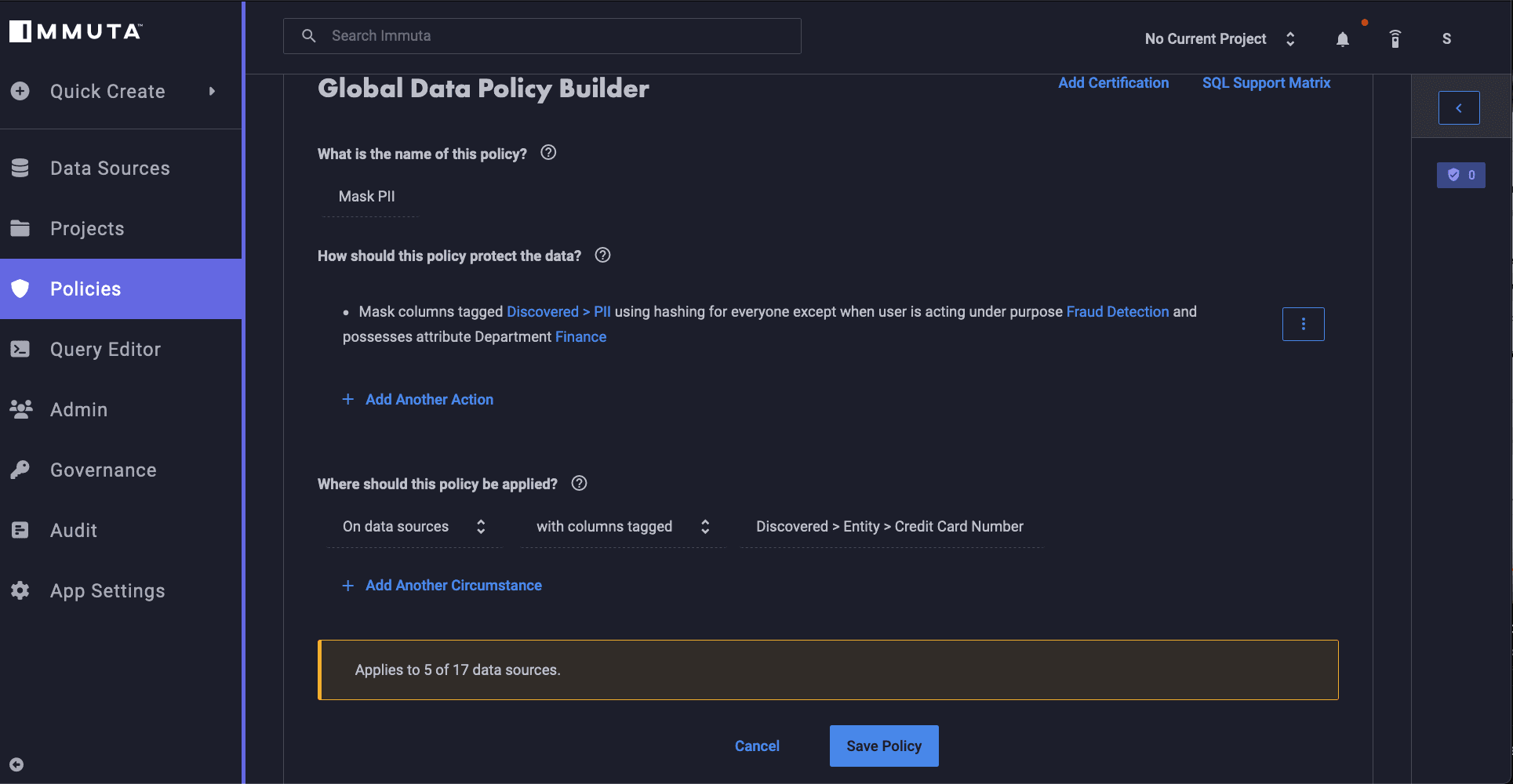
This policy uses attribute-based and purpose-based access control, which restricts access using the added dynamic layer of user purpose in order to create context-based exceptions to the rule.
When a Finance user runs this query in Databricks, they would see this:
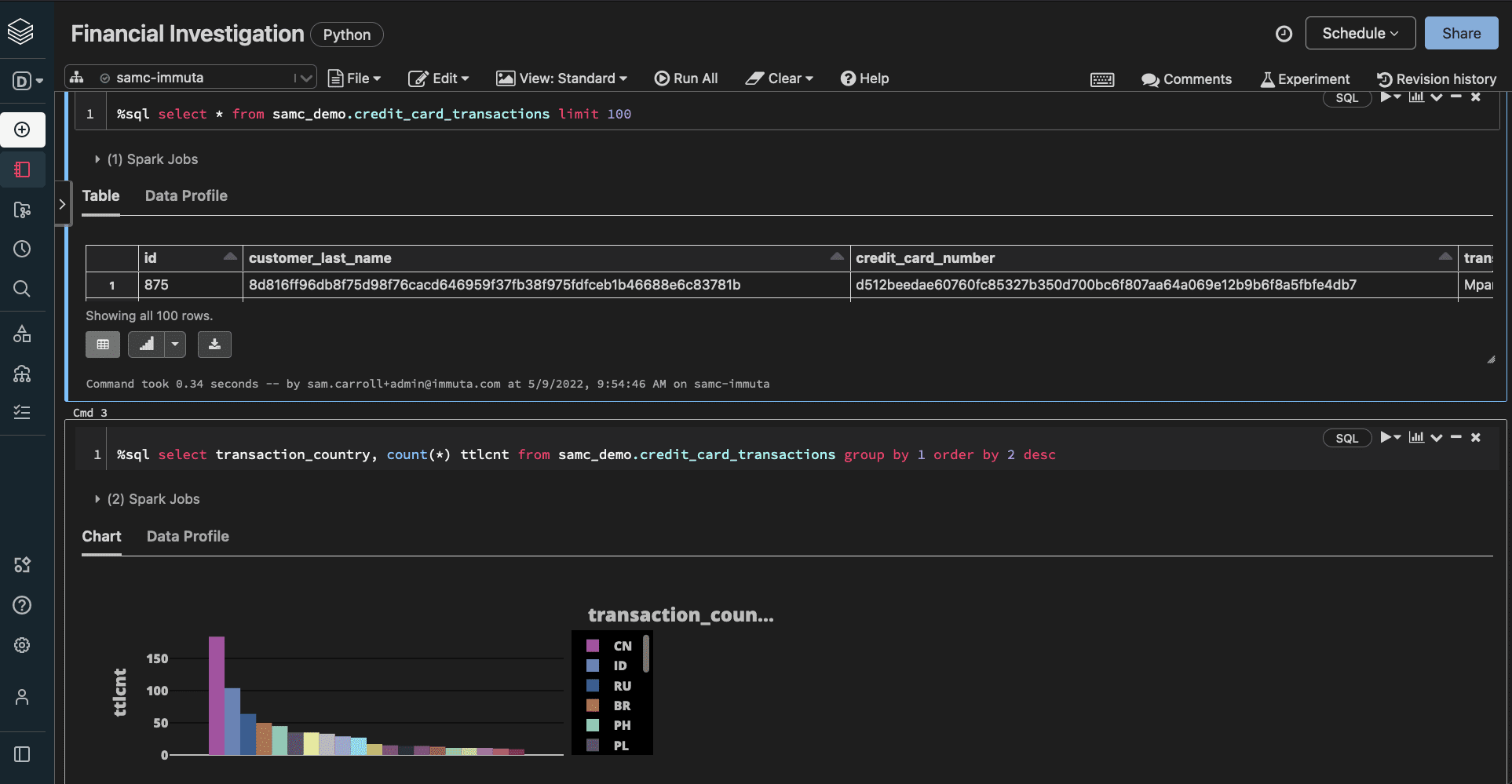
Our first policy gives them access to the data set, but the masking policy prevents them from seeing the sensitive information that requires a “Fraud Detection” purpose. While this example makes specific use of hashing, Immuta can also facilitate k-anonymity, conditional data masking, randomized response, and differential privacy.
Implement Row Segmentation Policies
In the previous image, the hashing successfully masked PII that the Finance user did not have access to. However, the location-based country code information in the data set still remained visible. To prevent unauthorized access to this data, we’ll create a row segmentation policy in Immuta:
“Only show rows where user possesses an attribute Authorized Countries that matches the value in column tagged Discovered.Entity.Location for everyone except when user is acting under the purpose Fraud Detection”
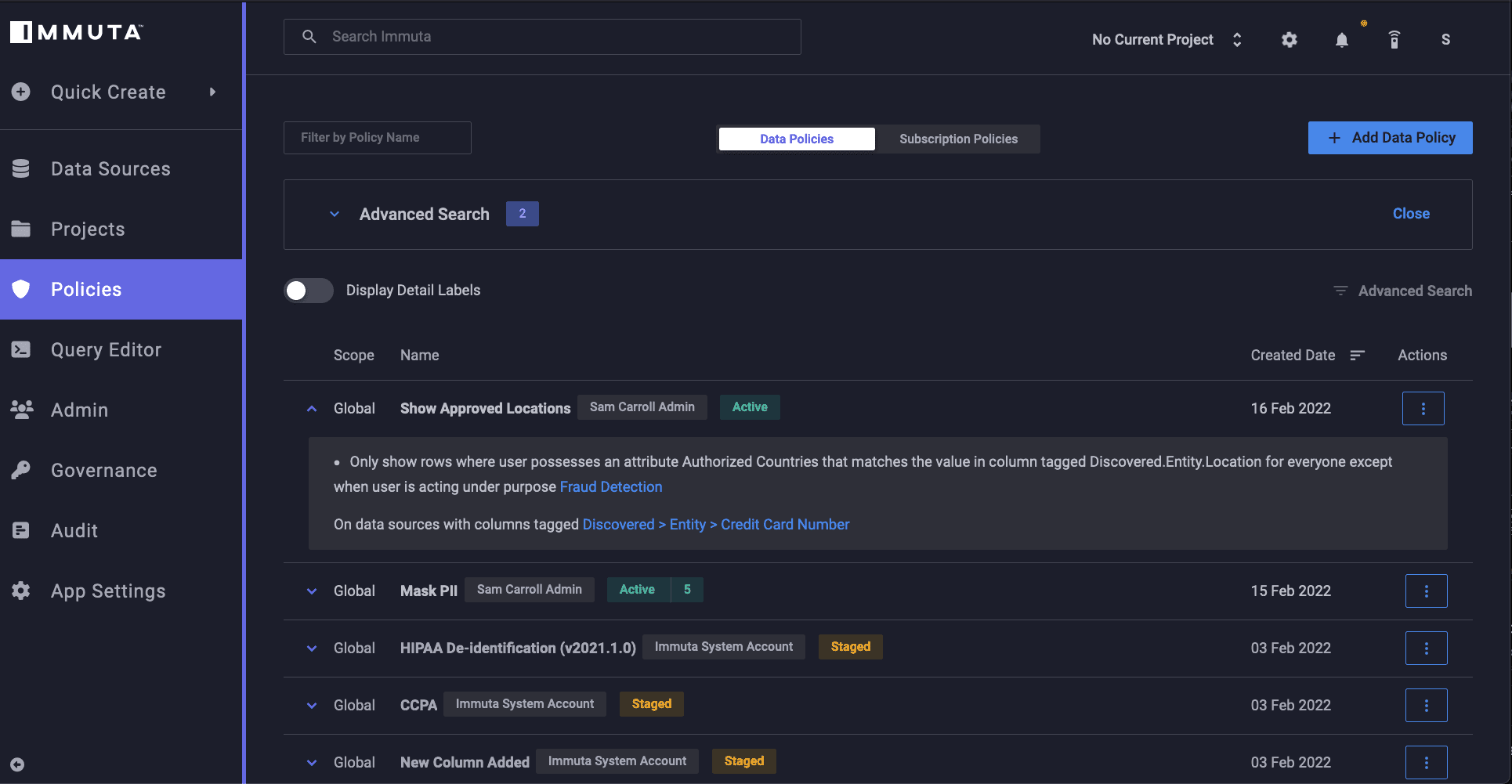
This policy permits access to the country code data that users are permitted to see. If we were to rerun the query for both our Analyst and Finance users, we would see just how rows are segmented accordingly:
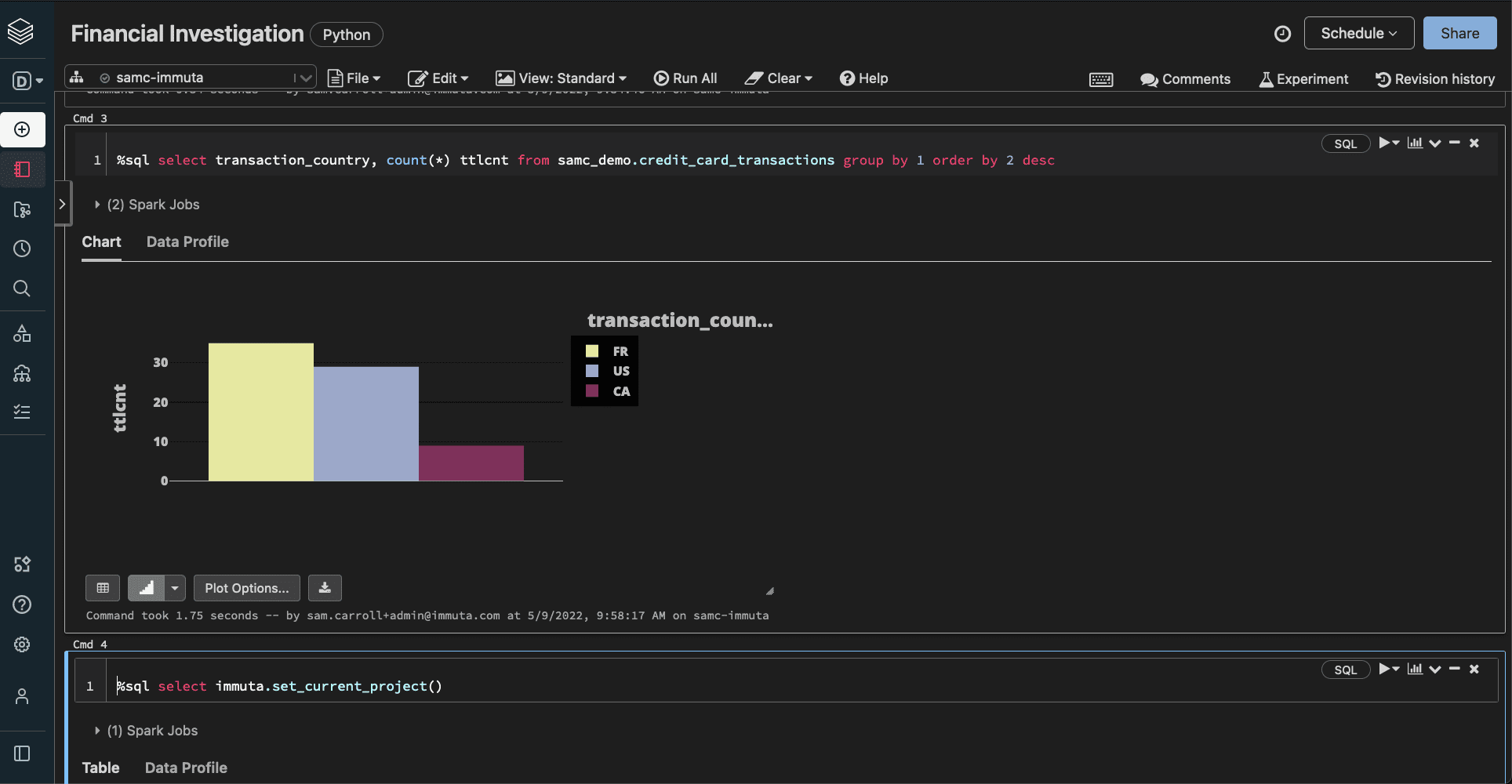
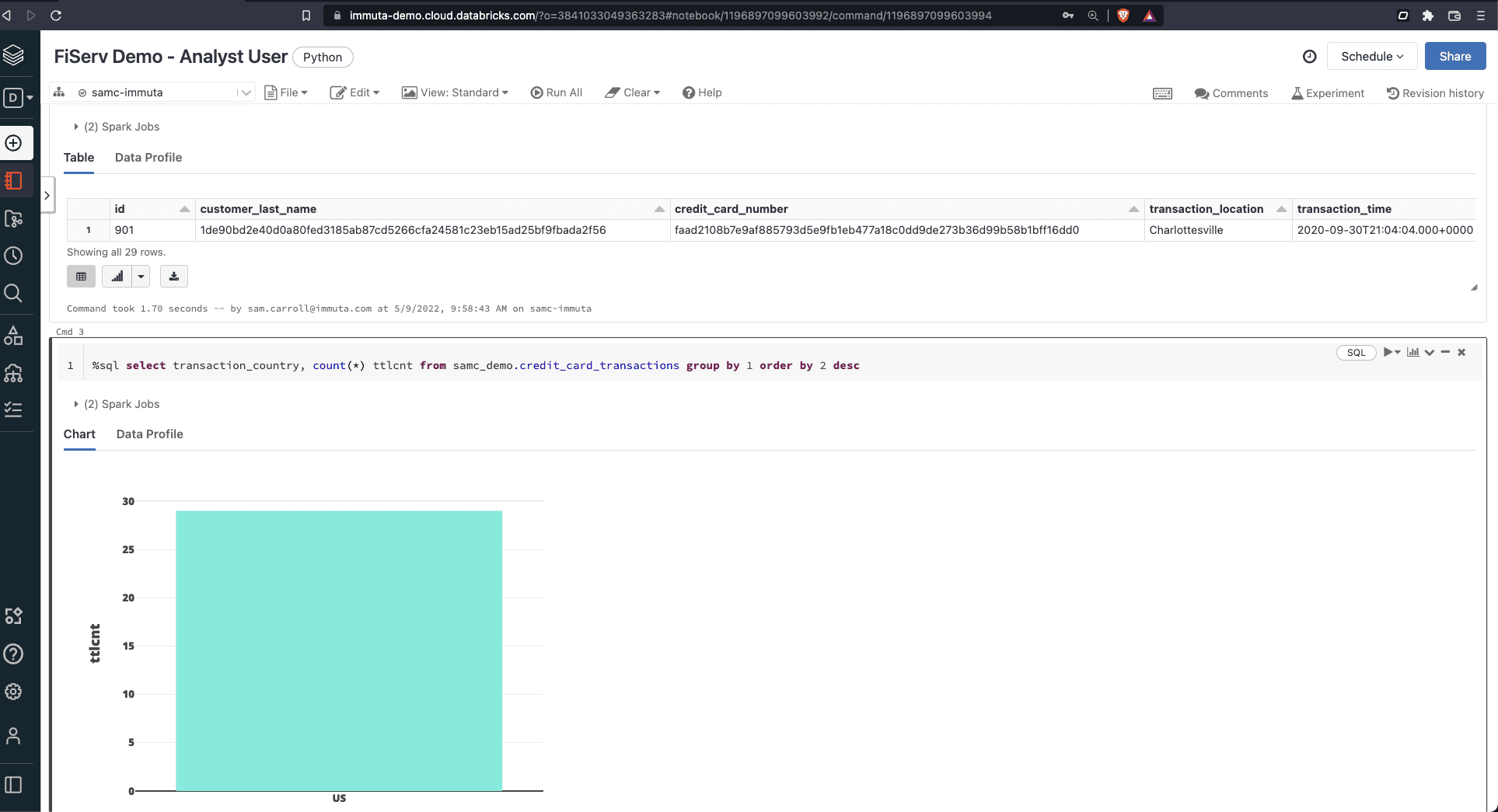
Each user is only permitted access to their relevant and approved geographic locations, not the whole collection.
Add Access Context to Users
One of the greatest strengths of a dynamic access control model is its flexibility. Rather than requiring manual updates and upkeep of hundreds or thousands of roles and policies, access changes can be made once and applied across your data ecosystem.
Let’s say that we need to add our Analyst and Finance users to a Fraud Detection project. In our initial masking policy, users with this attribute were permitted access to the unmasked PII. If we were to add both users to Fraud Detection, however, the visible information would still vary.
The Analyst, not fulfilling both the Fraud Detection and Finance requirements of the masking policy, would only have the previously-masked country code information revealed to them.
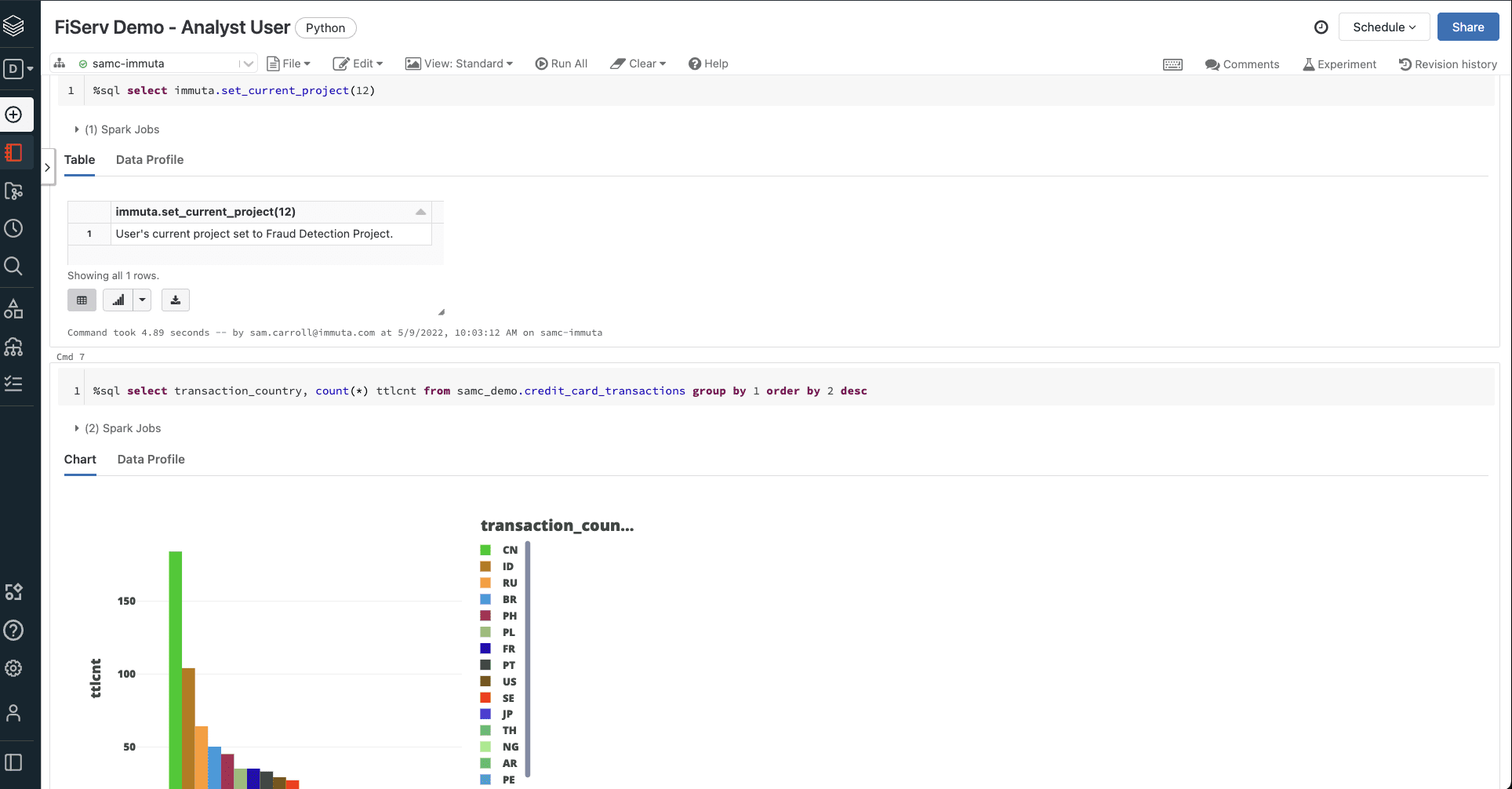
The Finance user, fulfilling both requirements in the masking policy, would then have authorization to view both the unmasked country codes and the unmasked PII.
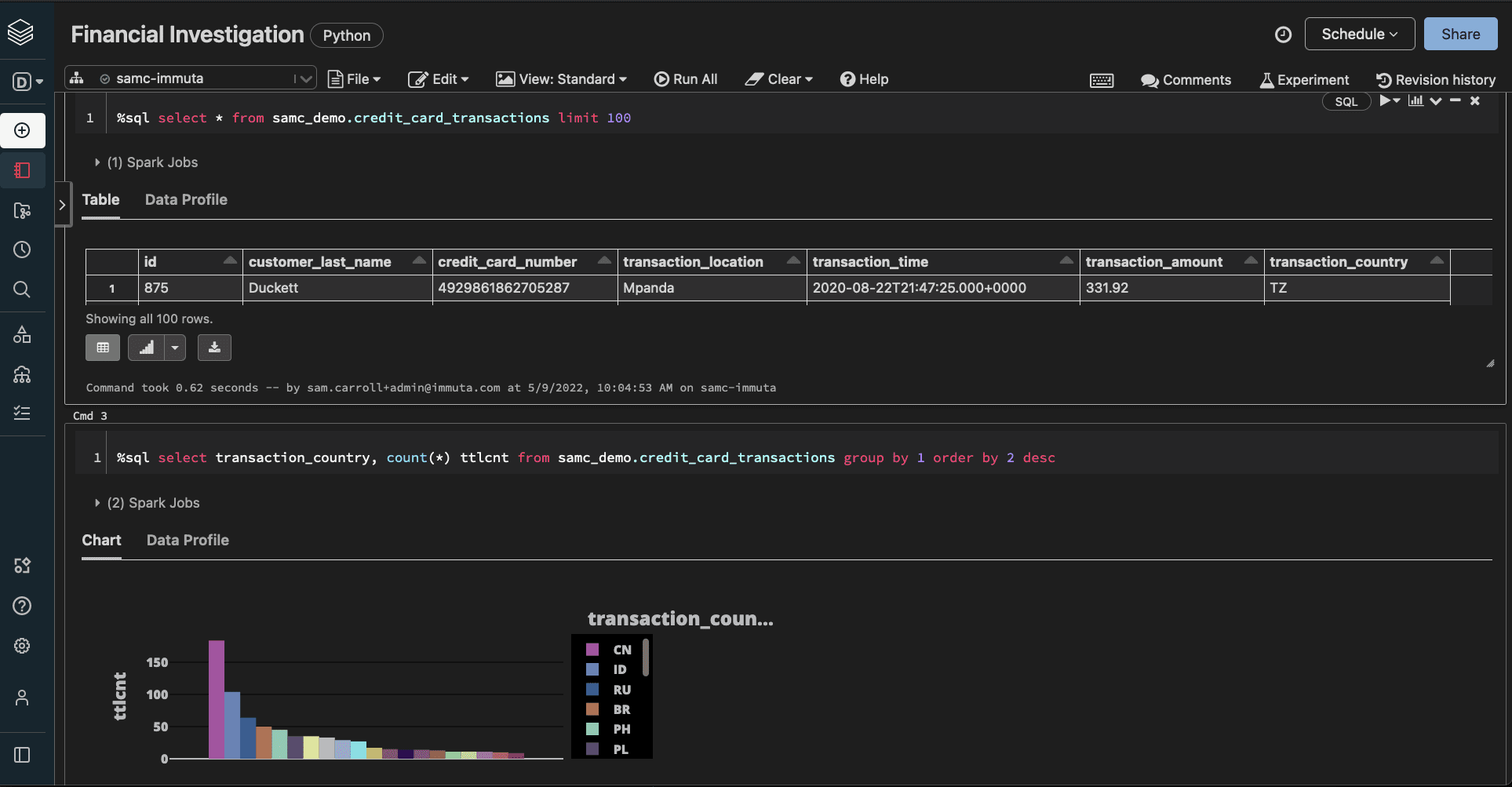
All it took to change these users’ access levels was a few quick clicks in Immuta, and the permissions were dynamically applied to their queries in Databricks.
Why Immuta + Databricks?
Through this example, we saw how simply Immuta and Databricks are able to protect sensitive data and maintain compliance with financial regulations.
With Immuta integrated with Databricks, you’re able to create, update, and maintain policies with ease from a centralized policy plane, and the results are effective instantly in users’ Databricks instances. This provides organizations with the flexibility they need to keep up with the evolution of data use and analytics, while maintaining the regulatory security standards necessary to keep consumers and their information safe.
To create a policy of your own with Immuta and Databricks, try our self-guided walkthrough demo.
To see this example worked through in real-time, watch the video below!



