Data Classification 101
How to kick off your data discovery, classification, and protection journey.


“What data do we have?”
Data’s entire life cycle – from collection, to analysis, to insights and business-driving application – begins with this question. Understanding your organization’s data remains critical to effectively using and protecting it, especially as platforms, users, and data sets constantly evolve. But gaining a contextual understanding and building data policies around it are not always as straightforward as they seem.
In this blog, we’ll introduce you to Immuta’s Discover Frameworks, and share how our discovery and classification rules make context-driven data protection that much easier.
The ability to protect your data is entirely context-dependent. If you don’t possess a detailed understanding of your data – including type, level of sensitivity, associated risk, etc. – you cannot adequately keep it safe.
Additionally, virtually every organization is now subject to data security standards. These standards impose security and privacy obligations on the ways data is collected, stored, shared, and used. Data security standards can come in a variety of forms:
With legal and contractual obligations outlined in laws, standards, and agreements, shouldn’t compliant data use be pretty straightforward?
Unfortunately, things aren’t so simple. In many cases, there is a significant disconnect between the letter of regulatory requirements and the technical application of their standards.
Industry frameworks like NIST or ISO 27001, for example, put forth defined measures to protect data and enhance data security. These frameworks, however, do not define what data is actually considered private or sensitive – they only dictate that private and sensitive data need special handling.
In a similar fashion, regulations like GDPR, CCPA, and HIPAA each outline requirements for how organizations should operate with the personal and/or protected information that they handle. These regulations, however, contain open-ended definitions that are not entirely prescriptive. The definitions are context-dependent, meaning that the legal status of data can evolve depending upon the context it exists within. For example, data is considered to be biometric data under GDPR or CCPA if it is collected for uniquely identifying an individual. A bank account number is considered to be personal data if it relates to a natural person, as opposed to a legal entity.
Another example is the HIPAA Privacy Rule. HIPAA protects all “individually identifiable health information,” but doesn’t expand upon what makes this information individually identifiable. In practice, a Patient ID or a Person Name are certainly individually identifiable – but an Appointment ID can be just as identifiable!
When requirements are seemingly open to interpretation, it can be incredibly difficult to apply them to your organization’s data practices.
To address this requirement-to-application gap, the Immuta team has created a number of classification frameworks within our Discover tool, informed by and built around the requirements of common data security and privacy standards.
Discover frameworks are an out-of-the-box solution that enable Immuta users with a holistic, contextual understanding of the data in their ecosystem. Each framework is made up of specific context-based rules, which include a set of required criteria that is paired with a potential tag result for the data. These rules are applied at the column level, and determine if the data in a given query meets the criteria required for a specific tag.
For example, a rule could read: “For each column, x, if all required criteria (r1, r2, …,rk) are met for x, then add tag t to x.” Frameworks bundle several rules in order to factor specific criteria into how your data is tagged and classified, helping achieve a consistent taxonomy. These frameworks offer both modularity (in their application) and interoperability, ensuring that your data is classified in a manner that cohesively protects it across cloud platforms, tools, and users.
How are these classification rules actually applied to data during the discovery phase?
Think of frameworks as filters, each layered on top of another, that take data and tag additional context to it as it passes through. We’ve organized these layers as follows:
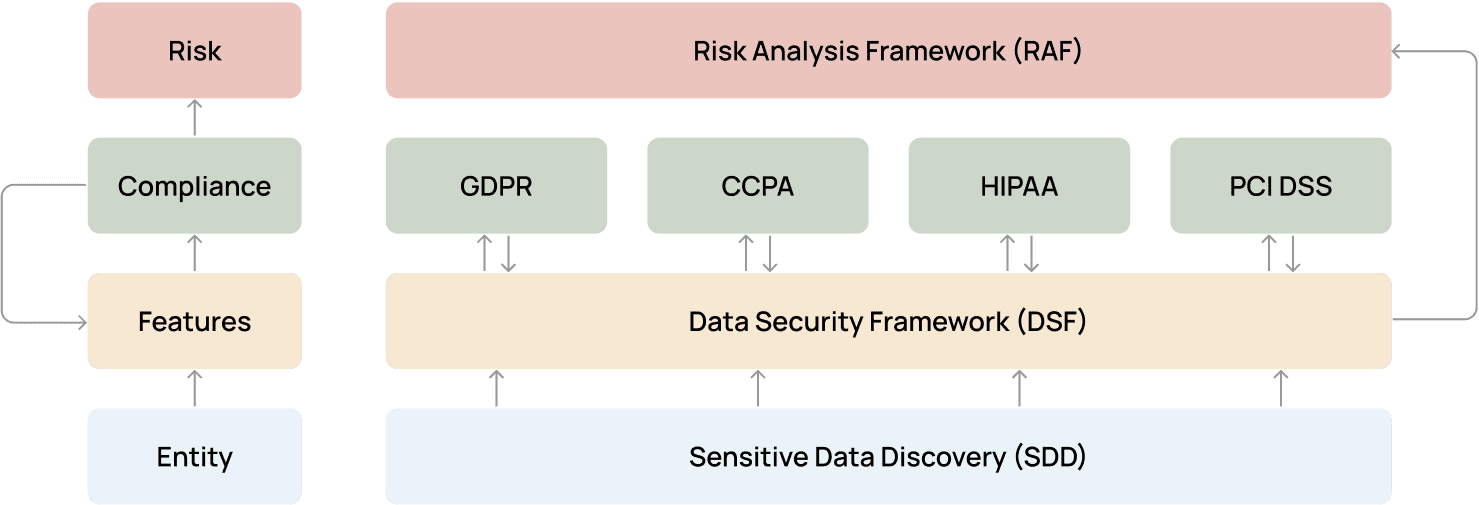
This entire process begins with gaining an initial understanding of the data you possess, through sensitive data discovery (SDD) and classification. Sensitive data discovery is the process of scanning, locating, and identifying sensitive data within your data sets. This allows your team to understand what kinds of data you have – such as social security numbers, passport numbers, driver’s license numbers, names, addresses – and where it lives across your platforms and tools.
While Immuta offers native SDD out-of-the-box, it’s important to note that other factors might need to be considered on a case-by-case basis. Our frameworks are customizable for our customers’ needs, allowing additional tags to be built into existing frameworks so that all required classifiers are taken into account.
Following SDD, the next three framework layers classify and tag data in a manner that provides necessary context for policy creation. Within these frameworks, data classification categorizes data based on shared properties, e.g., personal data or protected health information, and ranks it according to its category’s associated level of risk.
[Read More] What is Data Classification?
The first layer after SDD is the Immuta Data Security Framework (DSF). The DSF is a set of data categories and classification rules that reflect the baseline standards put forth by many privacy, data protection, and cybersecurity regulations. Think of DSF as a horizontal baseline or taxonomy from which other frameworks can borrow.
This framework avoids having to repeat the same rule for data sources governed by different regulatory frameworks or voluntary standards. Rules can be applied as a global policy, maintaining consistent standards for all of your data sets.
While DSF is based on the amalgamation of various standards and laws, the frameworks in our next layer are attached directly to specific regulations or standards. These compliance frameworks, as we refer to them, are meant to operationalize the requirements of four major regulatory standards: GDPR, CCPA, PCI DSS, and HIPAA.
Each compliance framework maps their unique tags to DSF’s pre-existing tag categories, and have the capacity to add new categories where needed. Take the GDPR: While DSF refers to an identified/identifiable individual’s information, it does not include a pre-defined list of sensitive personal data – there is no constant definition of such across frameworks. The GDPR framework introduces the concept of special categories of data atop the DSF’s pre-existing categories.
The final layer of this process is Immuta’s Risk Assessment Framework (RAF). Similar to DSF, the RAF is informed by a range of important regulatory standards. However, RAF differs from DSF in that it attaches specific risk levels to predefined data categories belonging to DSF or other frameworks. All data will either be classified as not sensitive, low sensitivity, sensitive, or highly sensitive, based on its risk assessment.
RAF has been conceived as a standalone framework to reflect data classification practices. Although organizations may be subject to various regulations, they usually maintain one overall data classification that associates risk levels with relevant data categories. In other words, there are no unique risk assessment frameworks per each applicable regulatory framework and voluntary standard.
The need for both context-aware protection and regulatory compliance requires you to have standardized data taxonomies and classification systems. More often than not, we’ve found that organizations lack this kind of consistency in their existing classification frameworks. Whether it be tagging the same information in a different fashion depending on who is evaluating it, or only classifying a fraction of your growing data sets, lacking cohesive data classification makes it incredibly difficult to write and enforce data access controls to govern your data.
When data is consistently discovered and classified, you can enforce controls at both a high level and a granular one. This is crucial for teams with diverse and growing data sets. Global policies enforce your most important security controls across data sets, while granular policies allow for fine-tuned controls to be set according to different data types, purposes, locations, etc.
Once data is classified and tagged according to these frameworks’ layers, you can leverage tags to create dynamic attribute-based access control (ABAC) policies that control data access across your organization. This helps bridge the gap between regulation and application, translating the letter of regulatory requirements into standard-informed security controls on data access and use. By applying these same frameworks to all discovered and classified data, you can ensure that your controls are as effective as possible across data sets, platforms, and users.
Ultimately, consistent discovery and classification can enable greater:
By standardizing data classification with Discover frameworks, our customers achieve consistent tagging and security across their data ecosystems.
Beyond security, standardized discovery and classification also allow your team to apply consistent monitoring and detection controls on your data. Like access policies, data monitoring capabilities are highly dependent on knowing what data you actually possess. Empowered with information about the types of data you have, their level(s) of sensitivity, and their risk profile, your team can maintain continuous security monitoring to proactively prepare a response for any leak, breach, or misuse. These measures should be prioritized based on risk and sensitivity levels to keep your most sensitive data protected and in compliance with regulations and security standards at all times.
SDD, classification, access controls, governance, and monitoring are all capabilities of a modern data security platform like Immuta. To learn more about identifying and protecting data using a data security platform, request a demo from our team. To dig deeper into discovery and classification, check out our Data Classification 101 white paper.

How to kick off your data discovery, classification, and protection journey.


