
To deploy a successful data strategy, that needs to be twinned with a successful data governance strategy. Increasingly, with a lot of the organizations I work with, that’s turning into a fully-fledged AI governance strategy.”
Michael O'Kane, Senior Solutions Architect, Databricks
In the 2024 State of Data Security Report, a vast majority (88%) of data professionals reported that employees at their organizations are using artificial intelligence (AI). But, only 50% said that their organization’s data security strategy is keeping up with AI’s rate of evolution.
This exemplifies a growing challenge we’re facing with contemporary data use – are our data security and privacy measures dynamic enough to keep pace with the constant advancements of new AI and machine learning (ML) tools and technologies? In this blog, we’ll look at how the combined capabilities of Databricks Unity Catalog and the Immuta Data Security Platform provide teams with the capacity to confidently govern and secure their data across platforms, tools, and evolving AI/ML models.
Addressing The Challenge of Evolving Data + AI Governance
The AI/ML governance challenge is one that leading data platforms like Databricks are actively working to address. During the Foolproof Your Unity Catalog Upgrade webinar, Databricks Senior Specialist Solutions Architect Michael O’Kane spoke to how his team is approaching evolving data and AI governance needs.
“To deploy a successful data strategy, that needs to be twinned with a successful data governance strategy,” said O’Kane. “Increasingly, with a lot of the organizations I work with, that’s turning into a fully-fledged AI governance strategy.”
O’Kane also noted that building an end-to-end AI or ML platform often requires multiple technological layers for storage, analytics, business intelligence (BI) tools, and ML models in order to analyze data and share learnings with business functions. The challenge is deploying consistent and effective governance controls across these parts of your ecosystem, especially when a lapse in coverage could risk data breaches, leaks, and misuse.
To meet these disparate data needs, the Databricks Unity Catalog was created – a core set of capabilities and APIs within the Databricks Data Intelligence Platform that enable users to manage permissions, centralize auditing, track data lineage, and share data across platforms, clouds, and regions. The Immuta Data Security Platform integrates with Unity Catalog to help users dynamically enforce this unified governance model across their entire data ecosystem. Immuta streamlines access and security management by allowing users to quickly discover sensitive data, apply policy, and audit user interaction with data in Databricks, making Unity Catalog’s controls more accessible, scalable, and repeatable.
With these integrated capabilities, maintaining a singular governance model across the various functions of a modern end-to-end AI/ML platform is streamlined and straightforward. The consistency and transparency that result are crucial when experimenting and innovating with AI and ML platforms, as lacking clear and cohesive data security and governance measures is a recipe for disaster.
Immuta + Unity Catalog For Evolving Use Cases
Immuta and Unity Catalog are primed to meet the critical requirements needed to successfully deploy AI/ML projects. Let’s walk through an example of these two platforms in action.
In this example, a financial institution is running transaction data through a new AI tool in order to provide users with more data-driven, personalized financial insights. Since the tool will be leveraging customers’ account information and credit card transaction data, it’s crucial that effective data access controls are applied at all times.
Since data security in financial services can be notoriously difficult, it’s critical that this new tool does not expose sensitive information to anyone that should not see it, including unqualified data users within your organization.
Discovering & Classifying Sensitive Data
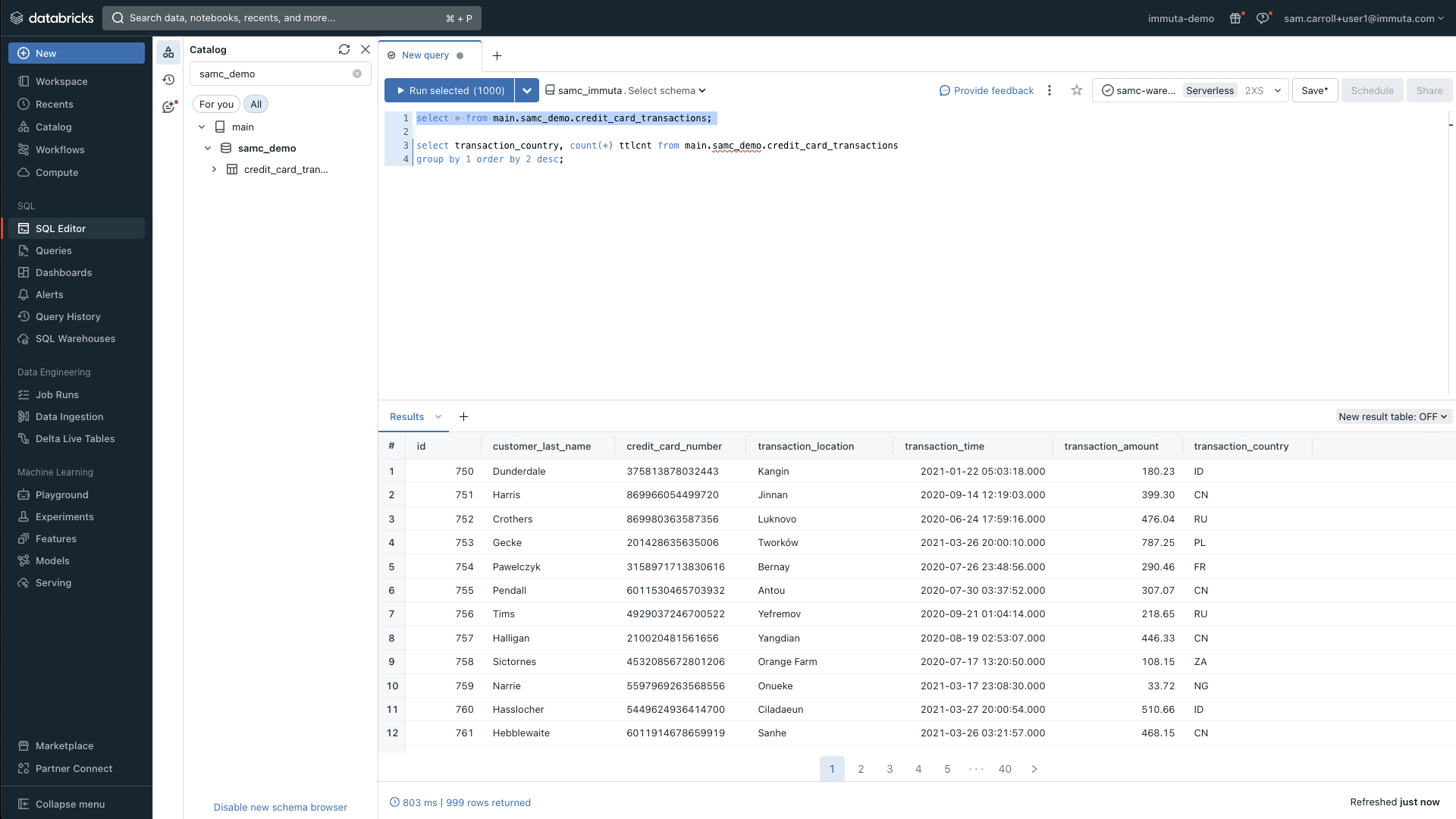
To get started, let’s look at an example table in Databricks Unity Catalog called credit_card_transactions. This table includes certain data that your AI tool must be able to access and analyze. When you log into Immuta as a governance user, the Immuta Discover engine automatically scans and classifies the example data above allowing you to gain an understanding of where sensitive information lives within your data sets.
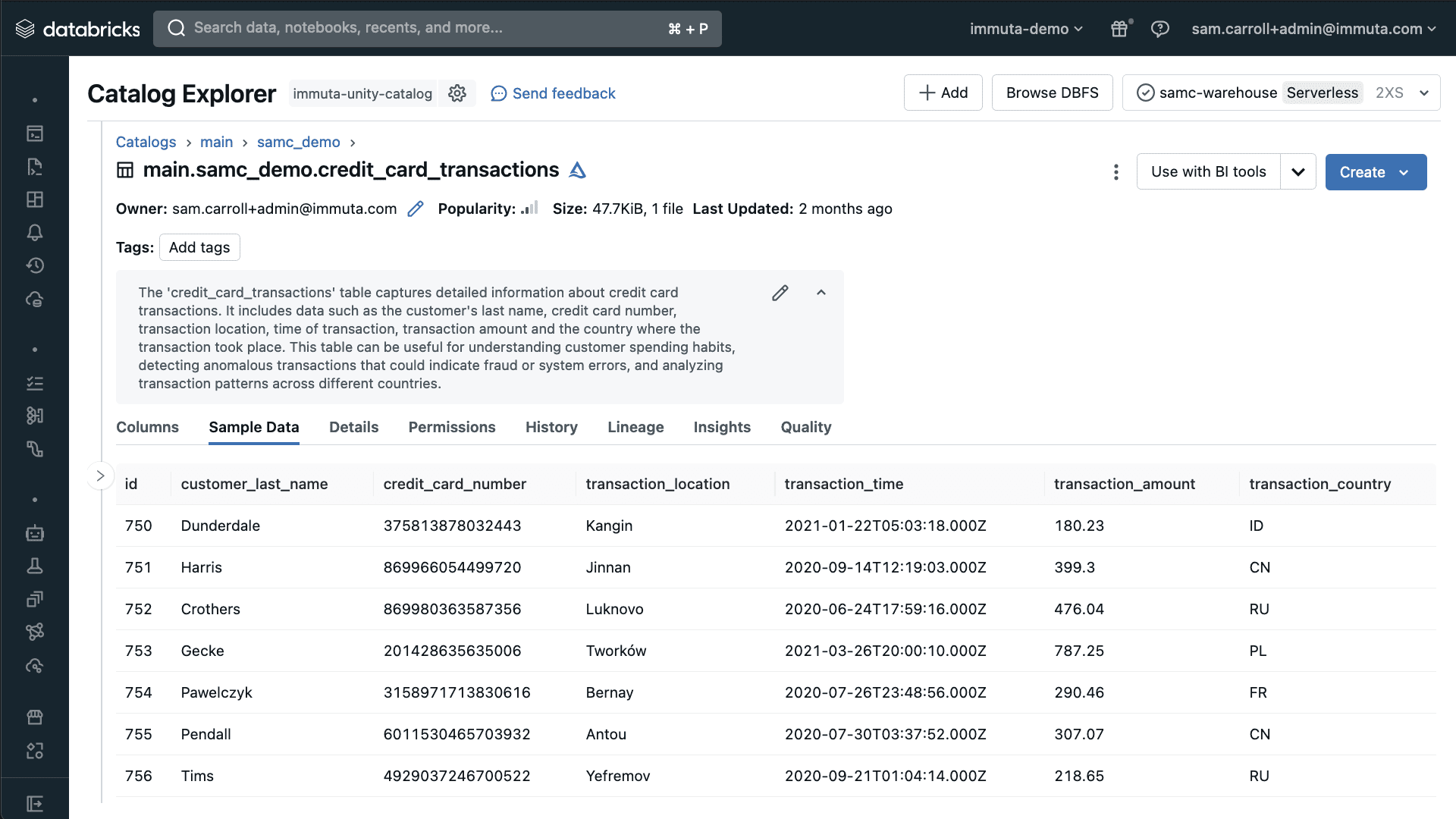
You can see that there is substantial sensitive data in this table, such as customer transaction details and credit card numbers.

Next, Immuta’s Overview page shows a breakdown of query activity over time in the Unity Catalog audit tables, which is monitored by Immuta Detect. Here, you can see the most commonly accessed data sources that Immuta has detected. Next, you can do a search for “Credit Card Number” within your discovered data sets.
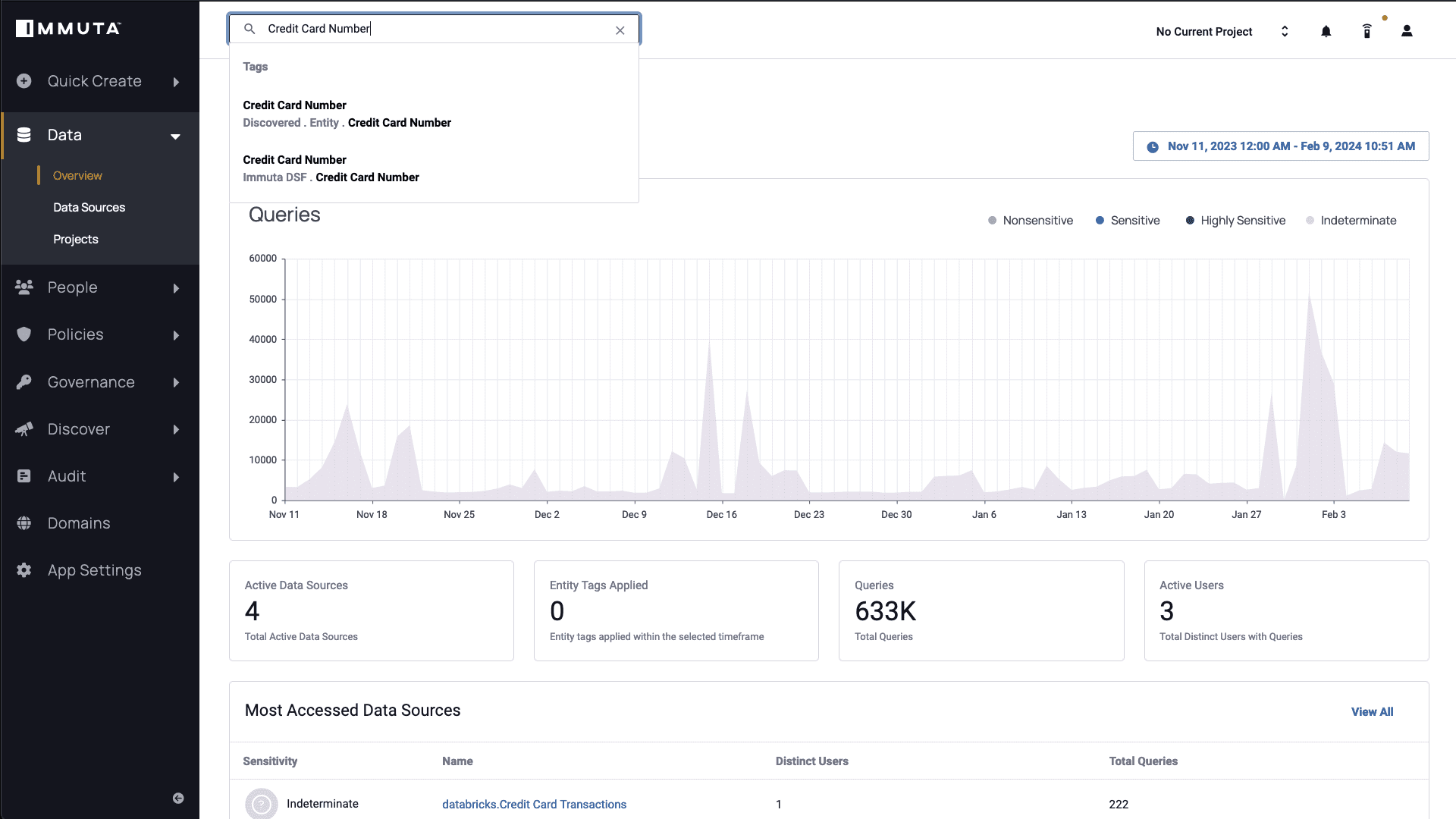
Note the “Discovered.Entity.Credit Card Number” tag. Data with a “Discovered” tag name has been automatically scanned by Immuta in Unity Catalog. These out-of-the-box classifiers can be extended by creating your own customized Discover Patterns within Immuta’s framework.
If you select the “Credit Card Number” tag, Immuta will give a list of any data source where this type of information has been identified.
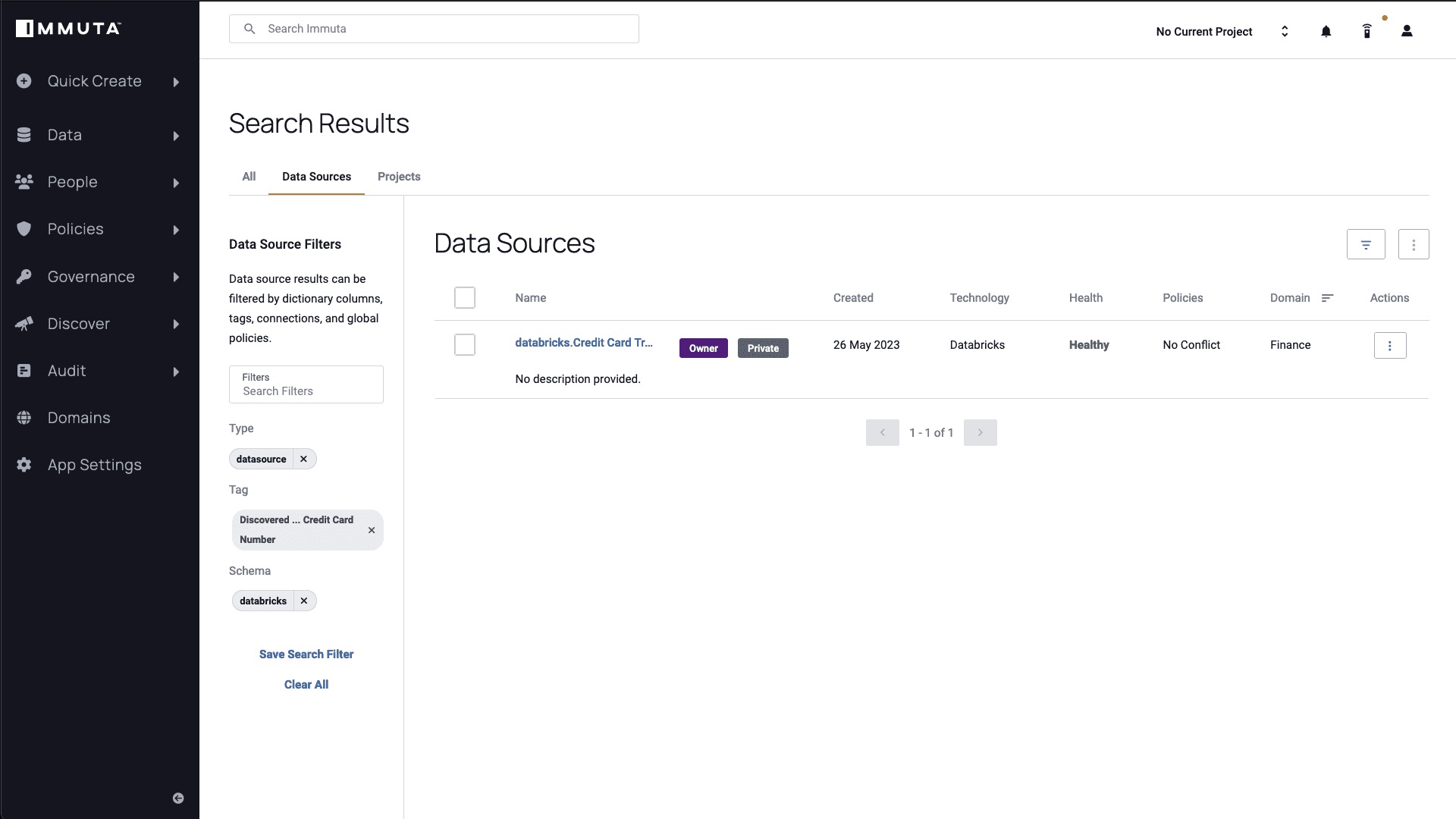
By selecting the “databricks.Credit Card Transactions” table, you will see a query activity overview for this particular table. This function is incredibly useful for determining who is using this data source. Since your AI tool is serving data to various transaction managers, having continuous visibility over query activity ensures consistent monitoring of all user activity, and gives you an understanding of any downstream impact that changing a policy might have.
If you take a look at Immuta’s data dictionary page, you’ll see tags that Immuta has automatically associated with the data you have scanned and classified using sensitive data discovery. Additional tags can be pulled and applied to your data by integrating third-party data catalogs such as Alation and Collibra. Discovery and tagging are crucial for secure AI model building and training – if you can’t track which data is being used in your models, how can you know if they are exposing sensitive information?
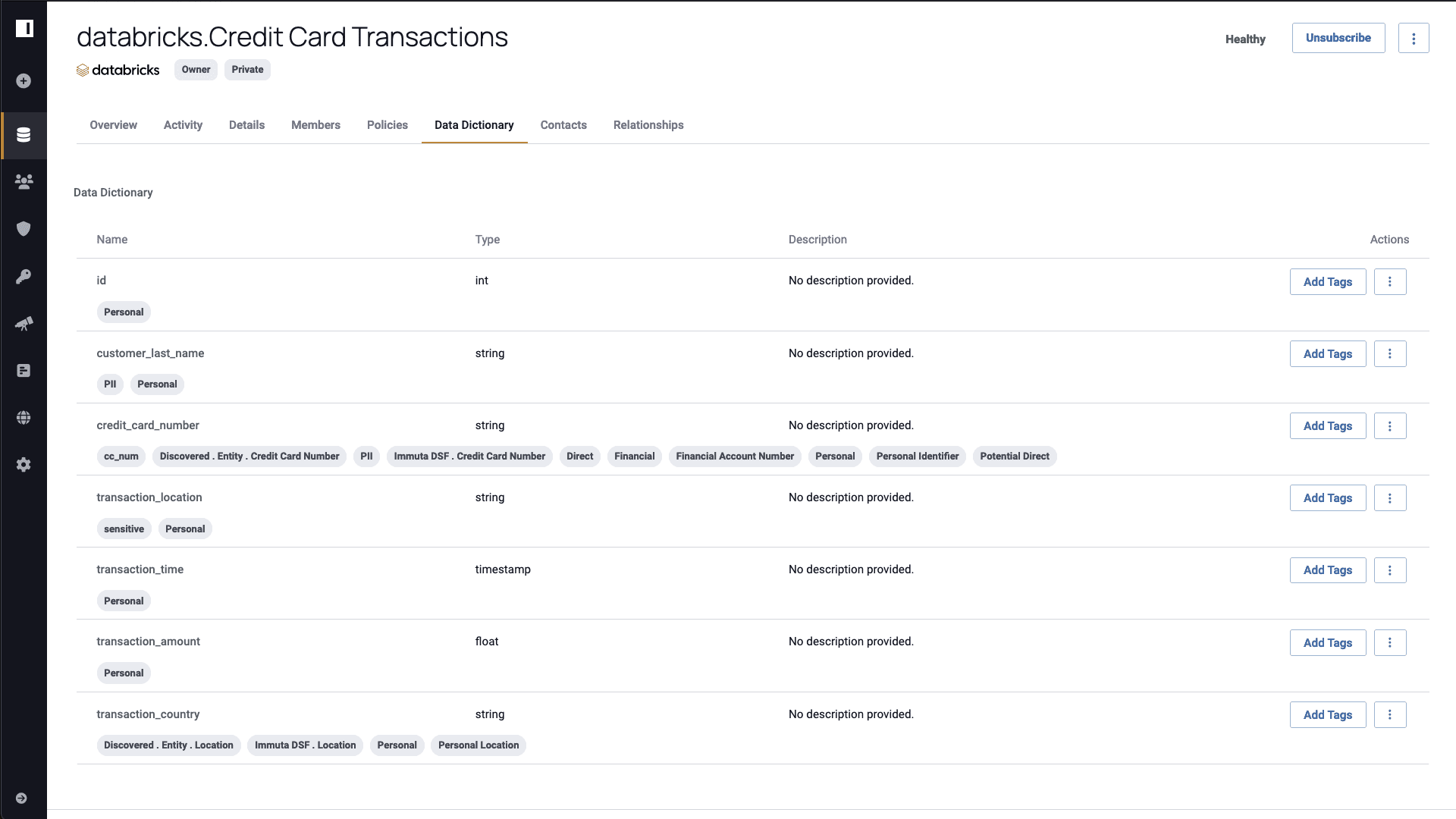
Effective tagging also enables your team to start defining policy based on the data context, instead of solely relying on rules based on tables and roles. Dynamic policies enable access permissions to be more granular, making it easier for anyone to understand who can see the data (transaction managers) and for which purposes (AI-driven personalized insights).
Subscription Policies: Granting or Denying User Access
Immuta has two types of policies: Subscription Policies and Data Policies. A subscription policy effectively grants SELECT access on tables based on conditions. If you were to log in to Databricks as a user who currently doesn’t have access to this credit card transactions table, you would not be able to see any of the sensitive credit card information. To grant this user access to this data, you could create a “Financial Subscription Policy” that reads “Allow users to subscribe when user possesses attribute Department with value Analytics or possesses attribute Department with value Finance.”
Immuta policies leverage user-level attributes from identity systems like Okta, easily granting any analytics or finance department users access to covered data, while blocking unauthorized users.
Once this policy is activated, a transaction manager user with the attribute “finance,” who didn’t have access earlier, will now be able to query the credit card table. This is because Immuta ran the necessary GRANT SELECT statements inside of Databricks Unity Catalog.
Data Policies: Protecting Sensitive Data Resources
To hide sensitive data, you’ll utilize Immuta’s data policies, which allow you to define row-, column-, and cell-level policies that will change what information someone can see when interacting with the data. A common use for data policies is to mask sensitive data. In the “Redact Sensitive Data” policy shown below, you’ll see how it will apply data masking to specific tagged data.
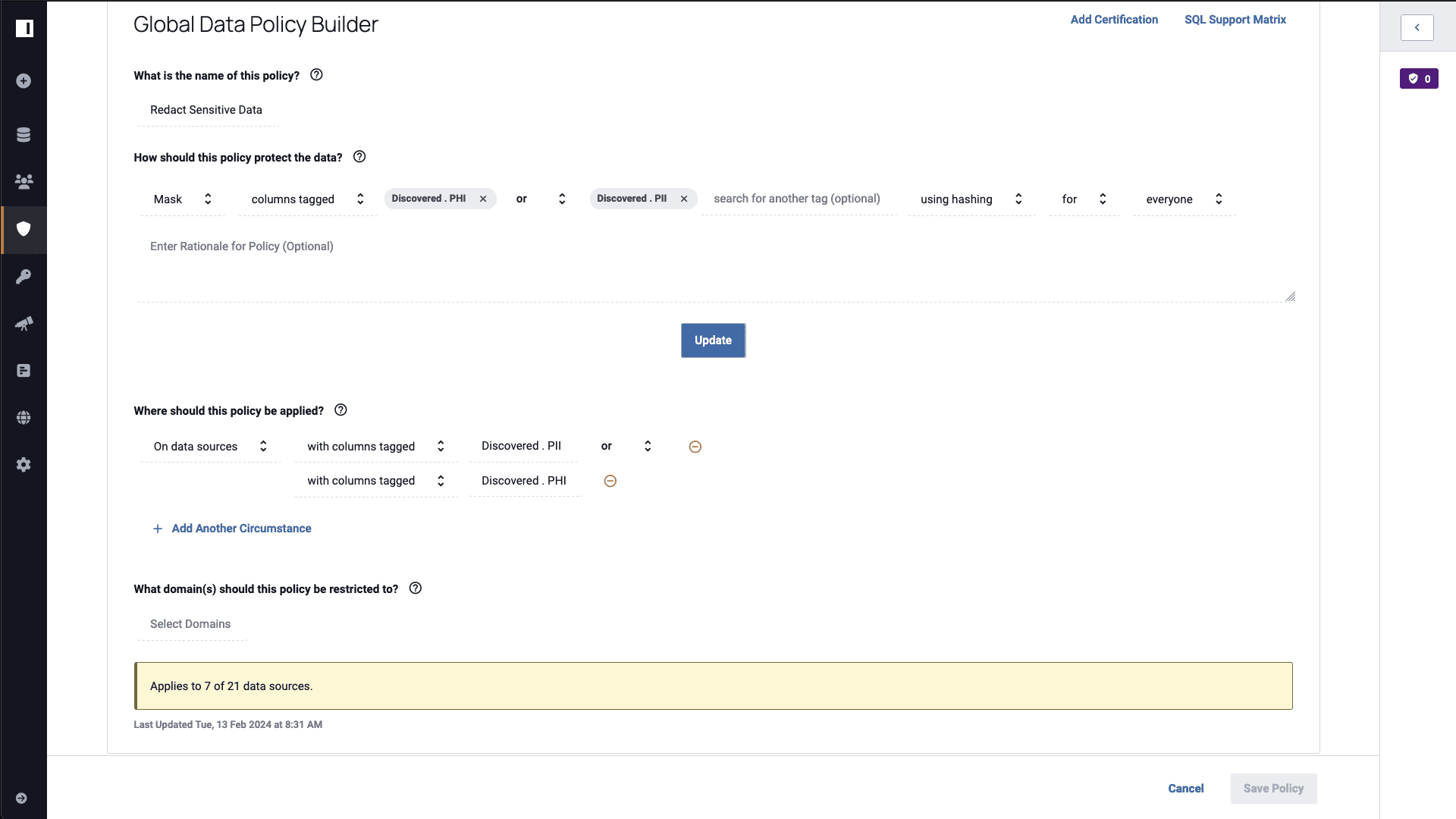
At the bottom of the policy, you can tell Immuta where to apply it. In this case, you’ll apply a masking policy to any column in any data source that contains PHI or PII, which will in turn mask relevant data using a hashing algorithm. After enabling this policy, the aforementioned “finance” user can run a query and see masked data in their credit card transactions table:
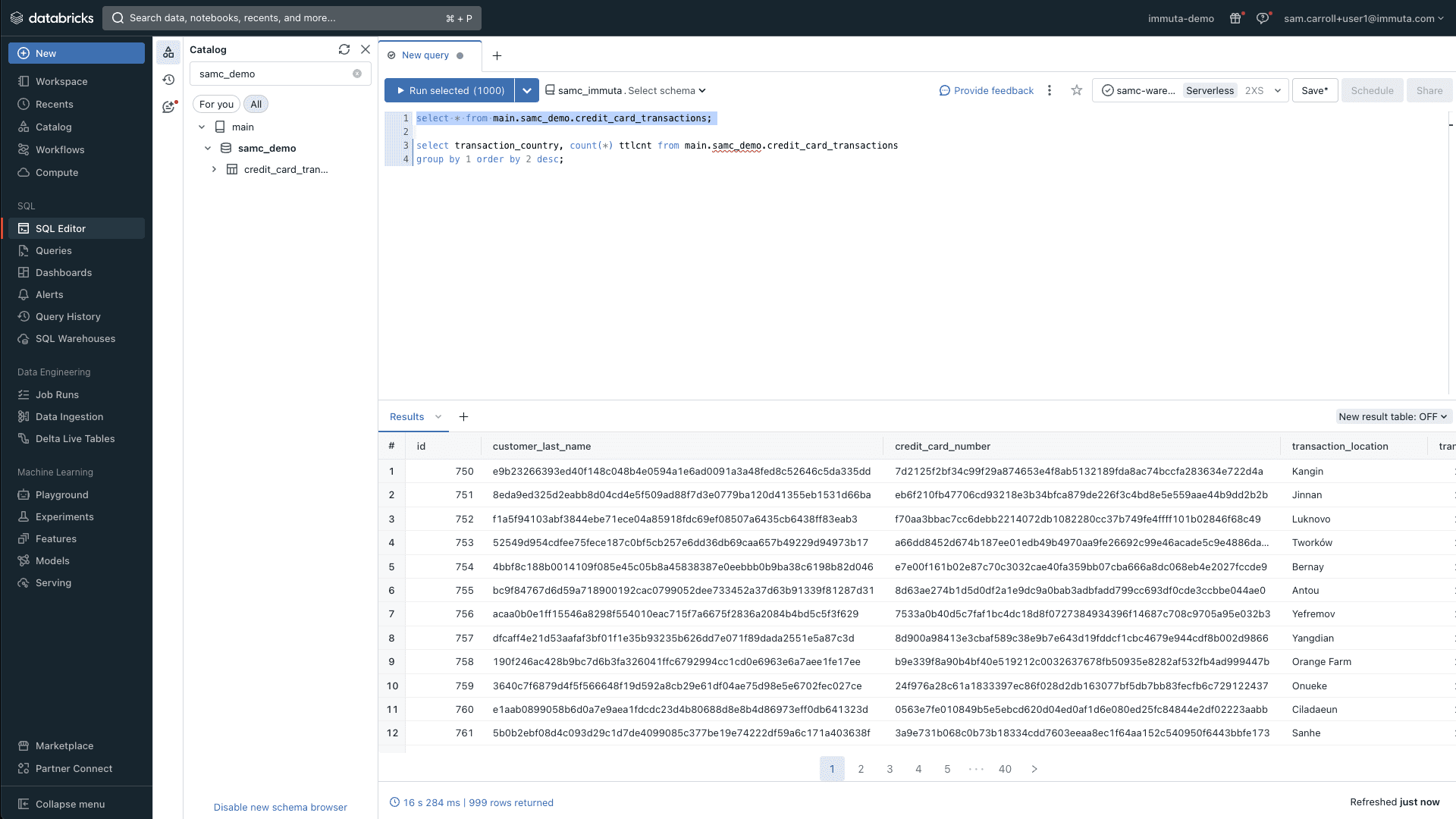
Note how the customer_last_name and credit_card_number are now both masked using a hash, due to the classification they were assigned. Behind the scenes, Immuta created and applied native Unity Catalog masking policies on the columns that met the classification criteria.
It is possible to manually build these kinds of policies in Unity Catalog (shown below), but it’s a less scalable model – especially if policy will need to increase incrementally to account for incremental tools or users.
CREATE FUNCTION ssn_mask(ssn STRING)
RETURN CASE WHEN is_member(Billing) THEN ssn
CASE WHEN is_member('InternalMediciine') THEN RIGHT(ssn, 4)
CASE WHEN is_member('Lab') THEN '***-**-****' ELSE null END;While you could manage this yourself to a certain point, it requires data engineers who have permissions to create policy in Unity Catalog. If your business determined that a redacted constant was preferred over masking, a data engineer would need to manually find all the masking policies they created and recreate them, then alter all the columns that meet the masking criteria. With Immuta, a user just changes the logic and applies the change in order to have it reflected across all relevant platforms.
Refining Granular Data Access
Now, let’s take a look at the country codes that are contained in this data set:
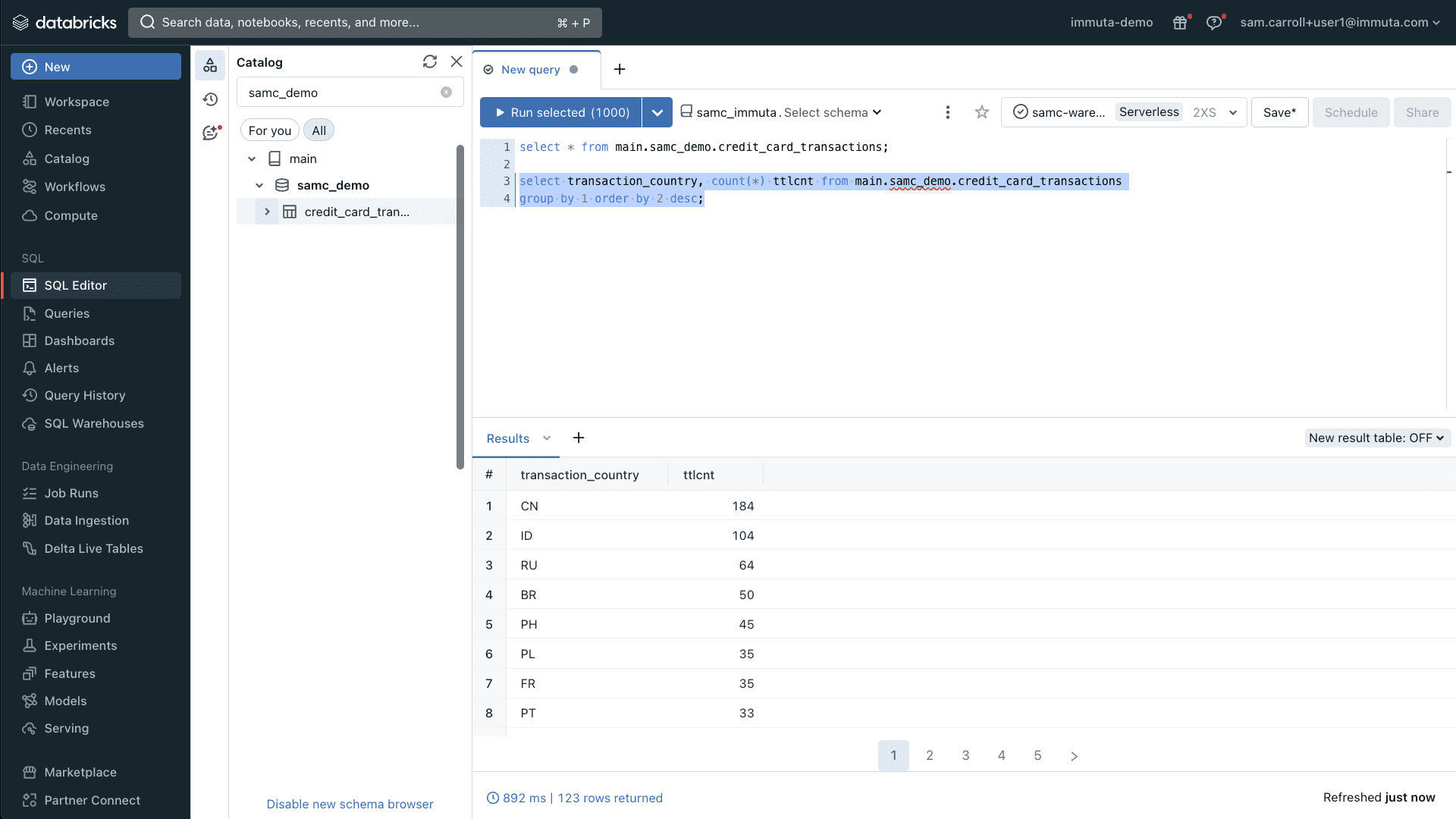
Here, you can see the output of a basic group by query. This query shows the countries with the most transactions sorted in descending order. In this scenario, we have three users who need to access this data:
- Global Transactions Manager
- North American Transactions Manager
- EMEA Transactions Manager
To leverage this data safely, users should only be allowed to see the countries in which they have management authorization. Without user attributes, a role hierarchy would need to be built in the identity management system, such as the following:
1. Global Transaction Managers
1a. North American Transaction Managers
1b. EMEA Transaction Managers
The global transaction managers should be able to see data associated with all country codes, whereas the North American and EMEA managers need to see the countries in their region. While it’s possible to do this in Databricks using a row filter user-defined function (UDF), users would need to create the roles, manage the user membership, and then create a CASE statement in the Unity Catalog row filter to determine who can see what. It’s easy to see how quickly this would become a maintenance challenge that forces more data engineering time to build the policy.
Because Immuta uses attributes, policies are defined by the countries that someone has authorization to see. Whether these attributes are coming from the identity system or another third-party system like Workday, you can use them to build a row filter policy that dynamically shows the appropriate countries to authorized users:
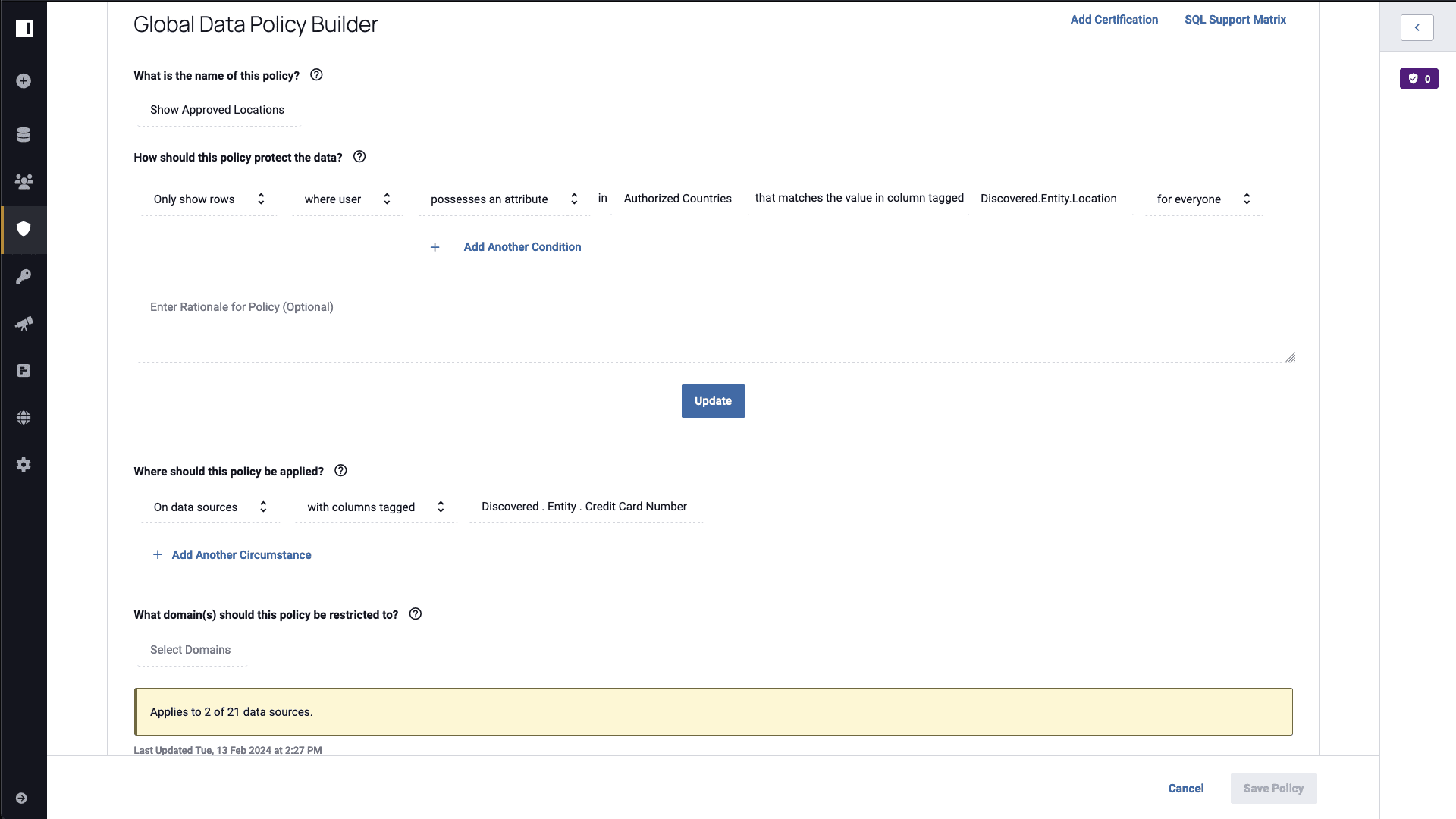
After enabling this policy, a user will now see only the approved countries they have listed on their user attributes when querying data:

Getting Started with Immuta + Unity Catalog
As demonstrated in the example above, leveraging the Immuta Data Security Platform in conjunction with the capabilities of Databricks Unity Catalog empowers you with streamlined and secure data security. You’ll easily write and apply dynamic policies that enable both high-level and granular access controls, ensuring that only the right users are seeing the data they have the right to see – especially when dealing with an increasingly large number of AI and ML platforms.
For a more in-depth demonstration of Immuta + Unity Catalog in action, you can watch the Foolproof Your Unity Catalog Upgrade webinar on-demand. To learn even more about this integration, read our Immuta + Unity Catalog white paper today.

Immuta + Unity Catalog White Paper
The Next Frontier of Scalable Data Security


