
As a company with over a million clients doing payroll for millions of people, ADP processes a large amount of data. Databricks helps us to manage that data and Immuta plays an important role in administering security and access control. As we look to innovate with new products and implement a multi-cloud strategy, we must treat the data properly – it must be governed.”
Jack Berkowitz, Chief Data Officer, ADP
The modern business is driven by data and AI. Decisions are no longer based on institutional knowledge or gut feel, and they’re not being made solely in the boardroom. Managers and individual contributors are expected to leverage data to make the day-to-day decisions they need to do their jobs, but faster and with better results.
In the age of the AI-augmented enterprise, cloud platforms like Databricks have allowed organizations globally to sharpen their insights, improve decision making, and unlock the power of machine learning and AI. But while democratizing access to data allows teams to scale and move at the speed of business, one challenge persists: ensuring that data is secure and accessible only by the right people, for the right reasons. Solving this issue is at the core of Immuta’s partnership with Databricks.
As we continue powering secure workloads for machine learning and AI, Databricks has invested in Immuta to strengthen our platforms’ integration and deliver an architecture built for the AI-augmented enterprise. This will allow joint users to simplify operations, improve data security, and unlock more Databricks data, so they can maximize the power of data and AI. But to truly understand why this is critical, we need to consider where cloud data use has been, and why the future requires a new approach.
The Three Pillars of Cloud Data Infrastructure
Cloud data infrastructure is designed to unify data across the enterprise, run data analysis at massive scale without exorbitant costs, and make it easy to share data with anyone inside or outside your organization. It allows a 100-year-old organization to do things only Google or Facebook could do 10 years ago. The challenge is that most data lives in thousands of separate apps, and it’s neither trivial nor cost effective to write code to access data in each one.
This was the impetus behind creating the three-pillar cloud infrastructure system we know today: the cloud data lake, cloud data warehouse, and data exchange. Unlike its legacy counterparts that were stymied by dependence on hardware resources, this model enables data processing and storage at scale, and is the only way thousands or hundreds of thousands of humans and machines can analyze and derive insights from enterprise data.
Bringing all enterprise data together creates incredible opportunities with AI, but it also creates perhaps the greatest security risk ever to the enterprise. How do you secure it? How can you handle those decisions at scale and at the speed of AI? This leads us to the fourth pillar: cloud data security.
The Fourth Pillar of Cloud Data: Cloud Data Security
Securing data is not a new problem, but the context in which it’s done is introducing new complexity.
It used to be that each user workflow could be proven to demonstrate control as to who has access to what because the access layer was hard-coded and the process was handled at the application layer. Security teams could run very primitive tests to ensure the security of its data in each app. But with cloud data infrastructure, the security paradigm of old breaks down quickly. Put simply, hard-coding security controls in cloud data infrastructure creates unmanageable complexity due to the sheer scale of users, data, and policies, and is bound to break.
This necessitates a fourth pillar of cloud data – cloud data security – and is the reason we created Immuta. Coming from the US Intelligence Community, we needed to fuse intelligence (data) quickly and at scale in order to enable fast decision making and information sharing. Legacy security paradigms could not keep up, leaving two choices: either don’t go to the cloud, or design a way to handle data security within the cloud. Achieving the latter required three fundamental philosophies:
- Separation of Policy from Platform: Controls must be separate from any one data system so rules can operate across cloud compute infrastructure without creating policy conflicts.
- Native: Data controls must be native, inside the native compute functionality of the cloud data infrastructure, in order to scale and avoid performance impacts.
- Attribute-Driven: Leveraging attributes instead of roles to tag data is the only way to scale policies as data sources grow. Doing so reduces the number of rules needed and the burden on data teams to understand how data is being controlled.
These philosophies shifted the security paradigm from application middleware to native, inside each cloud pillar:
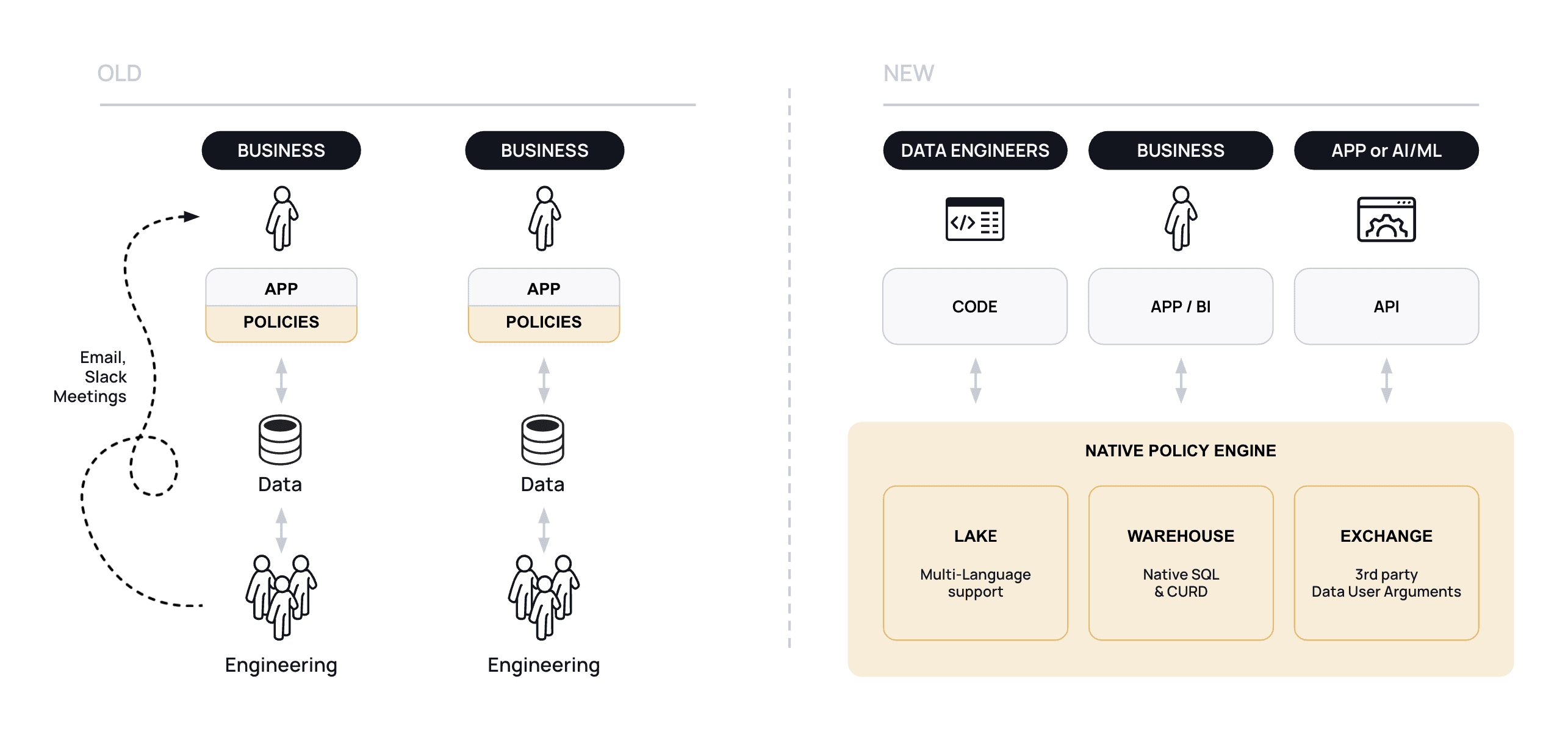
Drawing on these philosophies, Immuta is the Data Security Platform built specifically for the cloud. With automated data discovery and classification, security and access control, and data monitoring and detection, this new cloud middleware is an essential piece of the AI-enterprise architecture. It allows CIOs, CDOs, and CISOs to work together, virtually and symbiotically, to expose all of its enterprise data to any potential user, anywhere, without exposing their enterprise to unmeasurable risks.
Success with Databricks: Setting the Stage for the AI-Augmented Enterprise
Immuta’s partnership with Databricks began many years ago, but much like any other good B2B company, we’re constantly listening to our customers and looking for ways to evolve. As the AI-augmented enterprise has become the focus for many organizations, our customers invested in Databricks, initially through Delta Lake for data engineering needs and cloud migrations, and then Databricks SQL to shift reporting and business intelligence operations to the cloud. As their data processes matured into cloud-enabled processes, these customers began to run much more complicated workloads like machine learning and AI.
Throughout the journey, our customers’ needs evolved. At first, it was basic data security requirements. Then, we saw a pattern of customers needing the ability to run data workloads at scale, across clouds, globally, while being simple and performant. For example, ADP must operate across nearly all global markets using multiple clouds. Doing so requires a system that can handle massive both volumes of data and critical security needs:
Cloud metadata management systems did not allow for either Databricks or Immuta to solve that problem elegantly. Enter Unity Catalog. Databricks adapted its compute platform to manage metadata in a single metastore across all workspaces, so that queries do not have to make non-performant calls to external systems. Immuta has been able to take that single metastore and centralize policy enforcement across both interactive clusters and Databricks SQL:
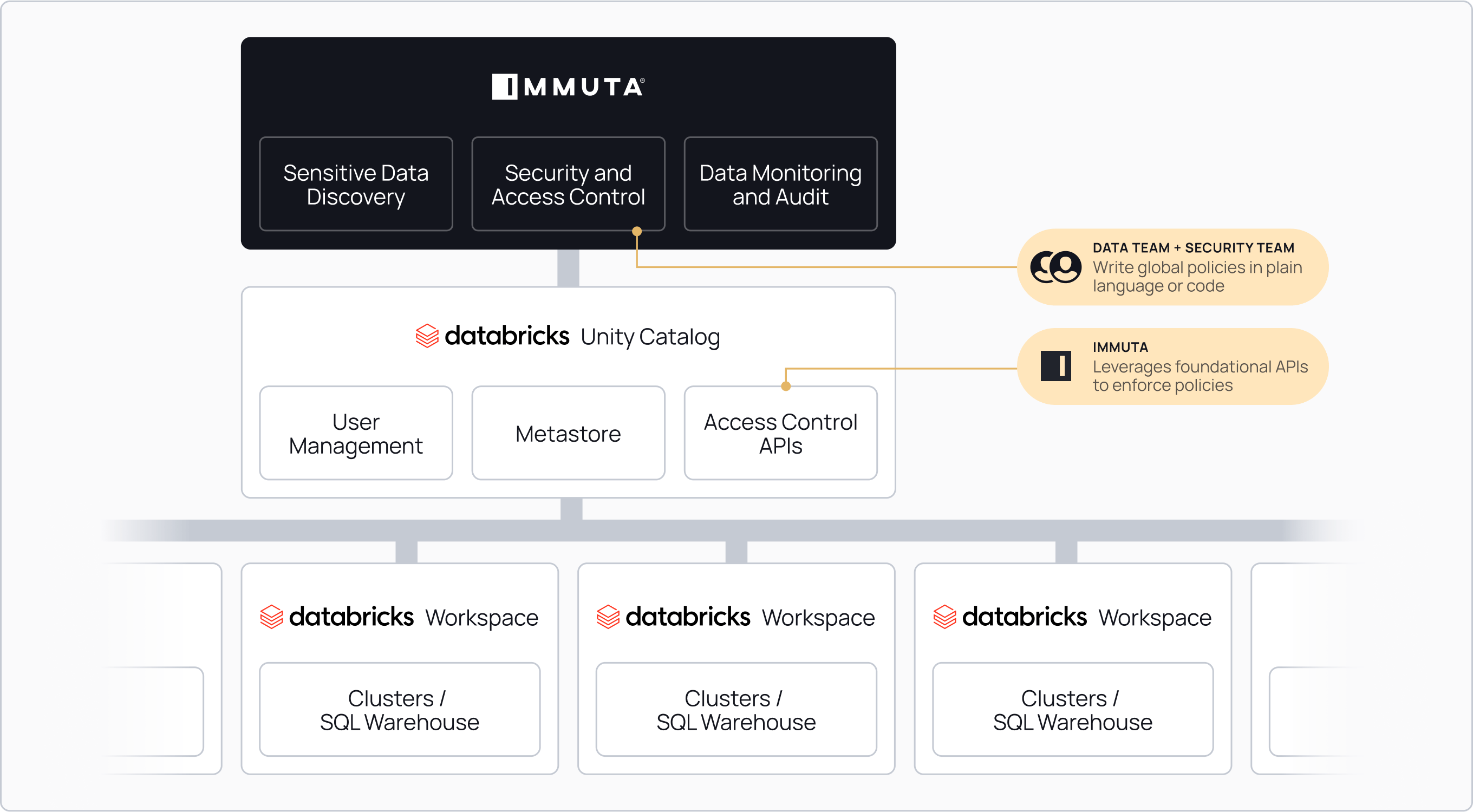
By adapting to this paradigm, our customers are now able to enforce complex security controls across any Databricks workspace, globally, without performance degradation or audit loss. Furthermore, this architecture enables corporations to begin designing AI in ways that were not possible before. With the ability to run and train AI against data in many workspaces, it’s possible to comply with data sovereignty laws and guarantee raw results will not be exposed to third parties. For example, Swedbank must keep data separated across its 33 subsidiaries throughout the Baltics but still leverage each data set to build and train its Anti-Money Laundering algorithms. Databricks and Immuta made this possible:
Swedbank needed to build an enterprise-scale advanced analytics platform that would also enforce trust in our security, management, and access to data internally, while protecting our customers’ assets and data. Immuta and Databricks have been instrumental in helping us build that vision and we are excited to see their partnership go to the next level.”
Vineeth Menon, Head of Data Lake Engineering
Together, Databricks and Immuta provide a secure, distributed platform for regulated industries to enter the age of the AI-augmented enterprise; thereby creating a foundation for the rapid acceleration in the development of secure enterprise AI.
The Future: Adaptive Data Security
To date, data security is purely deterministic: a business sets a series of rules based on attributes, roles, and groups. It’s completely reactive. Such a model works and can scale if solely focused on an internal set of systems and users, but as third-party users and AI models are introduced into enterprise data ecosystems, there is a breakdown in a deterministic approach – ultimately, it’s impossible to secure data.
Multi-party environments, including data exchange and shared AI modeling, require a shift in the way we do access rights today. We must move from deterministic to non-deterministic access rights. This requires a “zero trust” mindset where continuous monitoring and behavior analysis drives access rights to enterprise data, versus using a pre-built set of rules.
That is why Immuta has built Detect. Leveraging Databricks Unity Catalog, we are able to assess every query, human or machine, and determine change in risk. Detect can then report on these issues and adapt access rights. Here is an example of a security posture assessment in Immuta:
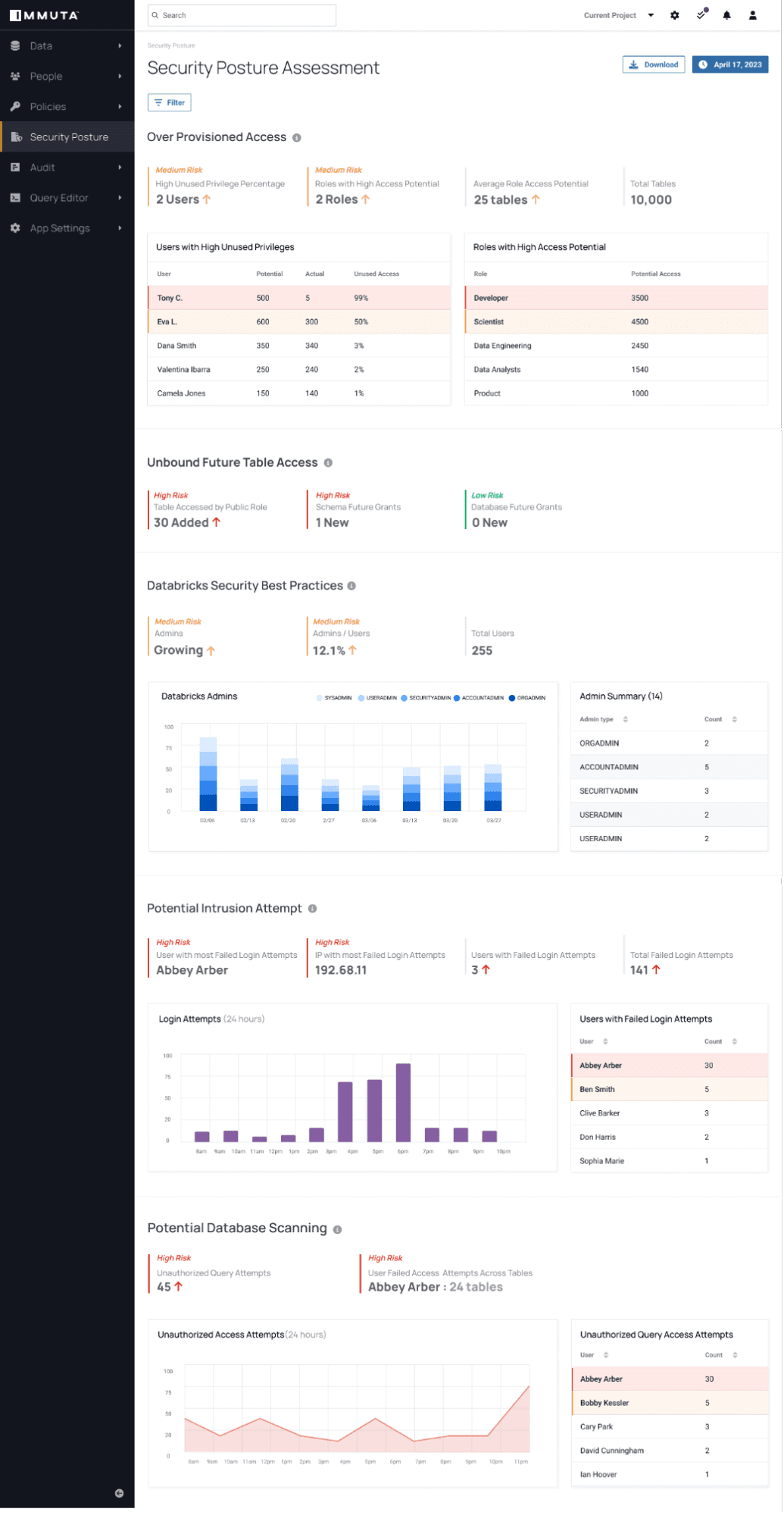
This capability, built in coordination with Databricks, allows our joint customers to secure their AI through data security posture management, a first of its kind; thereby allowing the CISO, CDO, and CIO to have a single plane to oversee and control data use as they build their AI-augmented enterprise.
Closing Thoughts
I am thrilled to see the long-lasting impact of the partnership between Immuta and Databricks as we continue to explore and push the boundaries of what can be achieved with data.
If you’re interested in learning more about how Immuta works with Databricks, you can learn more here.
Immuta + Unity Catalog
See what you can do with the combined power of Immuta and Databricks Unity Catalog.


