
Pushes toward self-service data use, advancements in AI, and the demand for real time, granular data insights have led to a surge in unstructured data volumes and usage. Research shows that 90% of new enterprise data is unstructured, and it is growing at three times the rate of structured data.
This begs the question – does your approach to securing structured data work for unstructured data, or are you leaving gaps that could compromise your entire ecosystem?
Immuta’s native integration with Amazon S3 aims to answer that question and give you peace of mind that your data is protected, no matter its format or location. This marks our introduction to providing data security for data in both storage and compute layers, giving you control over access to all data using the same policies that govern your data lake or warehouse.
With fewer policies and less complexity to manage, your data team will be better able to design systems and workflows that allow end users to consume data quickly and securely. The net result? Faster data access, better utilization, and greater value from your data, with no performance, security, or compliance impacts.
Why did we make this change, and why now? To answer that, we need to look at cloud data security as a whole.
What Is Cloud Infrastructure Security?
Cloud infrastructure security comprises the processes, technologies, and policies that collectively aim to protect the components of a cloud computing environment, including data in storage and compute platforms. It helps organizations ensure that their cloud-based data and applications are protected, trustworthy, and accessible to the right people, at the right time, for the right purpose.
Although cloud infrastructure security broadly includes safeguards for network, virtualization, and physical components, we will focus specifically on security and governance for data access, use, and sharing. Why? Because the increasing volume of data and users requires a better approach to managing and monitoring who is accessing data and how they’re using it – and the growth in unstructured data use makes this even more urgent.
The Next Era of Cloud Infrastructure Security: Compute + Storage
Data as an Endpoint
Traditionally, organizations focused on endpoint security to create a fortified layer of protection around the devices that directly connect to a network. These include laptops and desktops, servers, personal devices, and printers, among others. Amid constant connectivity and increasing cyberattacks – which now occur an average of every 39 seconds – endpoint security remains an important element of an overall data security strategy. But as cloud data use evolves, so is the definition of an endpoint.
In today’s world, any user can hypothetically access data – it’s no longer limited to data engineering or IT teams. And at most data-driven organizations, that’s intentional. An employee making decisions based on data is more likely to be correct than one relying solely on instinct.
This requires a shift in how we think about data. Just as traditional endpoint security protects the devices through which users connect to a network, in the new era of data security we must treat and protect data as its own endpoint. After all, putting a fence around your house doesn’t necessarily mean the rooms inside are secure. You need to ensure that what’s inside your data ecosystem is also protected.
Security for Compute & Storage
The notion of data as an endpoint is even more salient when we consider the trends that are changing how it’s being accessed. Whereas compute platforms like Snowflake and Databricks allow consumers to access structured data for analytics, now most tools can also access storage platforms like Amazon S3, which house enormous amounts of structured and unstructured data. This gives users more avenues through which to access data, which requires more oversight as to when and how they can do so.
This is underscored by the surge in AI development and democratization. Unstructured data is the primary input for training and fine-tuning foundation and large language models (LLMs), supplemented by structured data. As a result, data in both formats must be protected in storage layers, as well as compute. Think of storage as a new age analytic repository.
The question is how to do this without spending massive amounts of time, money, and resources, impacting performance, and generally reinventing the wheel. And therein lies the reason why, after nearly 10 years, Immuta is shifting from supporting solely compute platforms to delivering security for both compute and storage.
Immuta + Amazon S3: Full-Spectrum Cloud Infrastructure Security
Working with customers across every industry and geography, it’s clear that organizations are focusing on streamlining operations and empowering their teams to innovate with data. And they’re relying on the top tools to do so. Amazon S3 has risen to the top of that list for storage, and it’s easy to see why – more than 350 trillion objects are stored in S3.
The sheer volume of S3 objects could make the thought of managing and enforcing fine-grained access controls dizzying. On top of that, research shows that legacy approaches like role-based access control (RBAC) are unable to scale in order to handle the demands of modern ecosystems. But what if you could extend the policies governing your compute data to your storage data?
Using the Amazon S3 Access Grants feature, we built a GUI that controls S3 prefixes and objects directly through the Immuta Data Security Platform. This allows you to grant or restrict access to S3 objects via dynamic attribute-based access control (ABAC) policies, which can be built based on granular details like purpose or location. Additionally, Immuta uses metadata from enterprise data catalogs and data discovery tools like BigID and Amazon Macie to streamline consistent policy enforcement across storage and compute platforms.
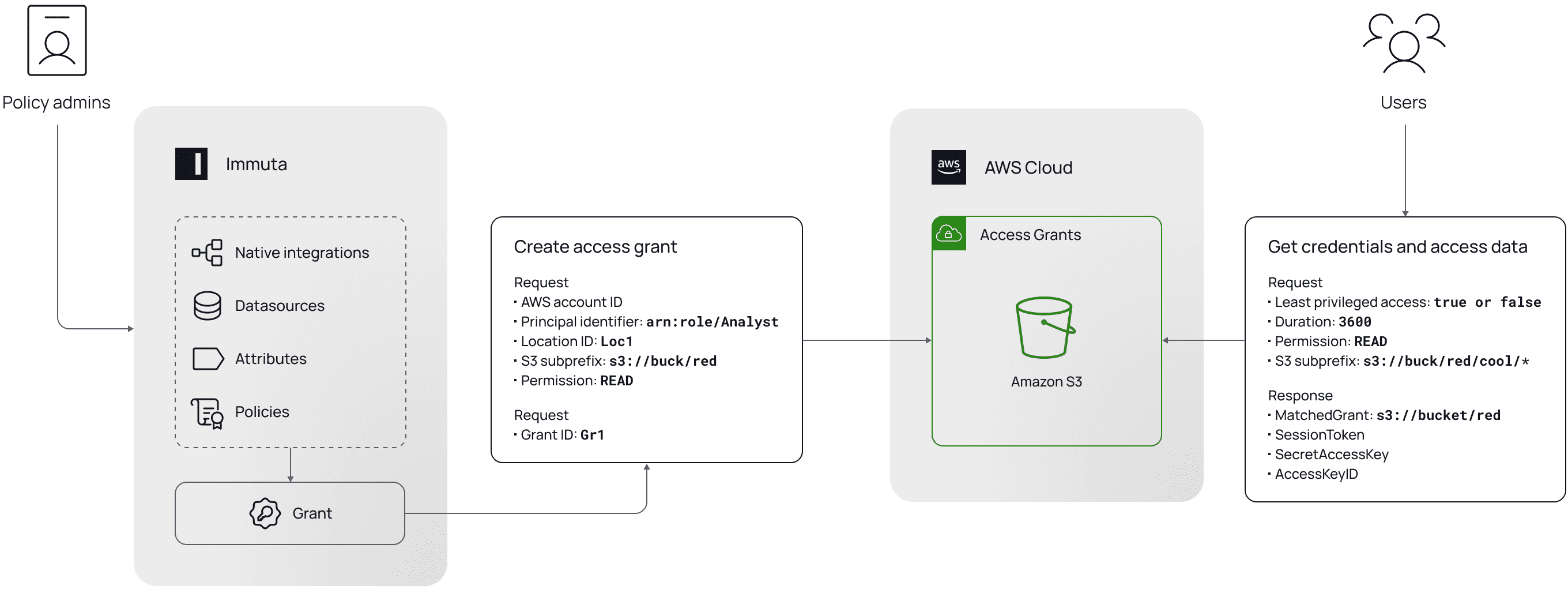
Removing the need to write different access policies for each S3 object, cloud data platform, regulatory requirement, organizational change, or any other shift within the ecosystem saves substantial time and effort, without sacrificing security or performance. In short, your cloud infrastructure security becomes significantly stronger without creating an equally significant burden on your data team.
Moving at the speed of data requires constantly adapting to new ways that customers are leveraging that data. Delivering centralized, dynamic security for structured and unstructured data, regardless of where it lives, is the latest proof point of our pursuit of that goal.
Learn more about Immuta’s S3 integration.
See how they work together.



