
The data security and privacy space continues to evolve to keep pace with the constantly changing data regulations, an evolving threat landscape, and increasing amounts of data and users with access to that data. Data security and privacy vendors need to be constantly innovating to keep pace with all the aforementioned changes.
With another quarter under our belt, we wanted to showcase some of the latest innovations that we have made to the Immuta platform that will help customers enhance their data security and data privacy posture – no matter their choice of data platform.
- Improved SaaS Instance Sizing
- Cross Regional Disaster Recovery (DR) for SaaS
- Column and Data Source Tags for Subscription Policy Variables
- Databricks Unity Catalog Integration
- Starburst (Trino) Improved Integration 2.0
- Audit Log Export to S3 for SaaS
SaaS Updates
Improved Instance Sizing
System disruption can be an Achilles heel for any business, so it is critical to have systems in place that are reliable and resilient to disruption.
With Immuta’s latest SaaS release, users can set resource limits for their instances to reduce any potential disruptions or downtime. Furthermore, users can alter metrics that change instance size based on their changing environment.
Cross-Regional Disaster Recover (DR)
Immuta continues to evolve its DR strategy to ensure business continuity through adequate recovery times in the event of system disruption. With that in mind, Immuta will consolidate and create cross-region replication of stateful services within each “legal” geography. In summary, backups will be replicated between two AWS regions within any given world geo due to an AWS regional event.
Audit Log Export to S3 for SaaS (Private Preview)
Immuta SaaS customers need a way to programmatically process structured audit logs that include what queries have been executed and which Immuta data policies have been applied. Exporting the audit data to cloud storage destinations makes integration with log monitoring services and data pipelines more convenient. The audit log data is now structured in a way that can be processed by standard log data processors and tools.
Platform Updates
Column and data source tags for subscription policy variables (Public Preview)
Until now, one of the challenges customers frequently faced was the tedious nature of leveraging tags in data source subscription policies at a global level. Policies would either need to be hard-coded, e.g. @hasAttribute(‘myAttributeKey’, ‘HardCodedTagName’)), or require complex group setups as a workaround.
Data owners can now build subscription policy conditions on matching data source (or column) tags and user attributes, without hard-coding the values. This new feature, along with pre-existing special subscription variables (e.g. @hostname, @database), will be moving into public preview in our next product release.
Some of the key advantages of this approach are:
- A reduction in the number of overall policies used through the use of policy variables
- Ease of applying exceptions to policies because there is no need for hard coding, and thus less overall effort required
- Easier migrations without downtime
Let’s say we create a global subscription policy with Immutable Domain Specific Language (DSL) – @hasTagAsAttribute(‘Exercise’, ‘dataSource’). Any users with attributes under the “Exercise” key, which is either a hierarchical parent OR an exact match to a given data source tag, will be subscribed to the data source. To better illustrate this behavior, see the subscription matrix below:
| User Attributes |
Data Source Tags |
Subscribed? |
Notes |
| ‘Exercise’: [‘Gym.Treadmill’, ‘Sports.Football.Quarterback’] |
[‘Athletes.Performance’, ‘Sports.Football.Quarterback’] |
Yes |
Exact match on ‘Sports.Football.Quarterback’ |
| ‘Exercise’: [‘Gym.Weightlifting’, ‘Sports.Football’] |
[‘Athletes.Performance’, ‘Sports.Football.Quarterback’] |
Yes |
User attribute ‘Sports.Football’ is a hierarchical parent of data source tag ‘Sports.Football.Quarterback’ |
| ‘News Articles’: [‘Gym.Weightlifting’, ‘Sports.Football’] |
[‘Athletes.Performance’, ‘Sports.Football.Quarterback’] |
No |
The policy is written to only match values under the ‘Exercise’ attribute key. Not ‘News Articles’. |
Immuta Integration Updates
Immuta continues to innovate together with its key partners to ensure customers have access to the latest features driving data security in the cloud. Some of the key integrations in this release include:
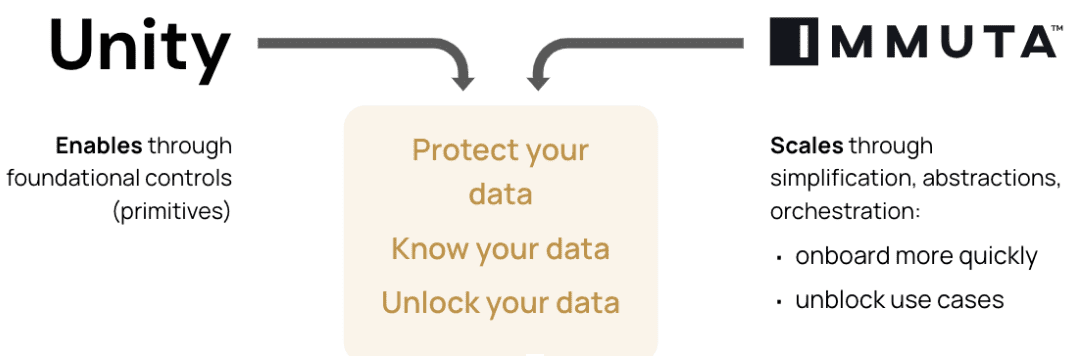
Databricks Unity Catalog Integration (Private Preview)
Immuta recently became the first Databricks Security Partner to integrate its policy engine with Databricks’ Unity Catalog data governance solution. Unity Catalog’s foundational governance capabilities allow consistent enforcement across languages/API and asset types, as well as improved governance infrastructure and opportunities like data lineage. When coupled with Immuta, data teams are able to add a slew of capabilities, such as data access control, scalable enterprise policy orchestration, intent and purpose-based policies, advanced auditing, and advanced discovery and classification.
Starburst (Trino) Improved Integration 2.0 (Private Preview)
Immuta’s engineering team has been diligently working to provide customers with a seamless policy orchestration experience on Starburst and Trino. Our initial 1.2 Trino connector relied on the creation of an Immuta catalog and required some work to rewrite workflows to point to the catalog. With the enhanced integration (2.0), Immuta offers a deeper native integration that no longer requires a catalog, since policies will be enforced at query time. If needed, the 2.0 integration can run concurrently with the 1.0 connector.
[Tip]: For more on Immuta’s integration with Starburst, check out this blog.
Next Steps
If you’re new to Immuta and want to quickly see how easy it is to discover and secure sensitive data, try our walkthrough demo or if you want a detailed rundown of the Immuta platform, request a demo today.


