
Modern enterprises rely on data to deliver insights across every line of business, from sales and marketing to finance and HR. Gone are the days when data use was limited in scope – today’s increasingly decentralized data initiatives and architectures require decentralized access management. Continuing to consolidate data stewardship within a single IT team puts organizations at risk of encountering bottlenecks as the number of data sources, users, and demands accelerate.
In this blog post, we’ll explain the concept of distributed data stewardship and its relationship to increasingly popular data mesh architectures. We’ll then explore how organizations can apply a distributed stewardship approach to build successful data mesh architecture, and efficiently maximize the value of their data.
What is Distributed Data Stewardship?
Amid the rise of distributed architectures, apps, operational and analytical data, and cloud architectures are becoming less centralized; and organizations’ silos exacerbate data sharing issues.
Distributed stewardship is an approach to data policy management that delegates responsibility to the stakeholders who understand the data’s full business context and access control requirements. It is a core tenet of data governance, as it gives custodianship of a company’s data to the people closest to that data.
What is a Data Mesh Architecture?
Data mesh architecture is an approach that applies the adaptable principles of distributed data management architectures to make data more accessible, faster. This framework directly connects data owners, data producers, and data consumers, removing manual IT efforts and eliminating bottlenecks. Therefore, decentralization and distribution of accountability lie at the heart of data mesh architectures.
How Does Distributed Data Stewardship Relate to Data Mesh?
One of the core principles in data mesh architecture is distributed data stewardship. Distributed stewardship enables power and control, while data mesh focuses on organizational change. If implemented together effectively, they will improve the business outcomes of data-centric solutions, as well as drive innovation and adoption of modern data architectures.
Organizations that follow the principle of distributed stewardship and make accountability for data definition, production, and use a driving factor in data governance, can get ahead of those that do not. Improving overall data efficiency and effectiveness requires a paradigm shift toward operating in a decentralized fashion that keeps operations within specific business domains and thereby narrows the impact of continuous change.
While there are many benefits to a data mesh architecture, it cannot be implemented at the expense of data access controls and data security. Ownership of data by a specific business domain may improve effectiveness, but it can also lead to data silos. Organizations need to balance the need for global governance policies and controls with the need to ensure each domain team retains the ability to define and implement these policies when developing and sharing their data products.
This is where distributed stewardship can prove effective for data mesh architectures. Good data governance requires business domain data owners to coordinate their activities across the organization. This coordination does not happen naturally and requires a deliberate effort to drive cooperation. Data stewardship responsibilities should be formalized in order to have effective data governance. Formalized accountability for data (stewardship), both within each individual business data domain and across business domains, is required to achieve the level of data-related behavior (governance) necessary to implement a fully controlled data landscape.
Enabling Distributed Data Stewardship for Data Mesh Architectures
Distributed data stewardship is a key enabler for data mesh architectures because it facilitates compliance with regulations, policies, and standards, without silos or complexity. This is achieved through appropriately governed data access policies and controls. To reap the full benefits, adopting a data access platform that enables scalable, dynamic data security is essential.
The diagram below illustrates distributed stewardship implementation with a data security platform where data access control policies are authored, enforced, and monitored. Distributed stewardship enables organizations to build integrated data products from multiple data sets with automated data policies. The distributed stewardship enables autonomy for the different domain teams.
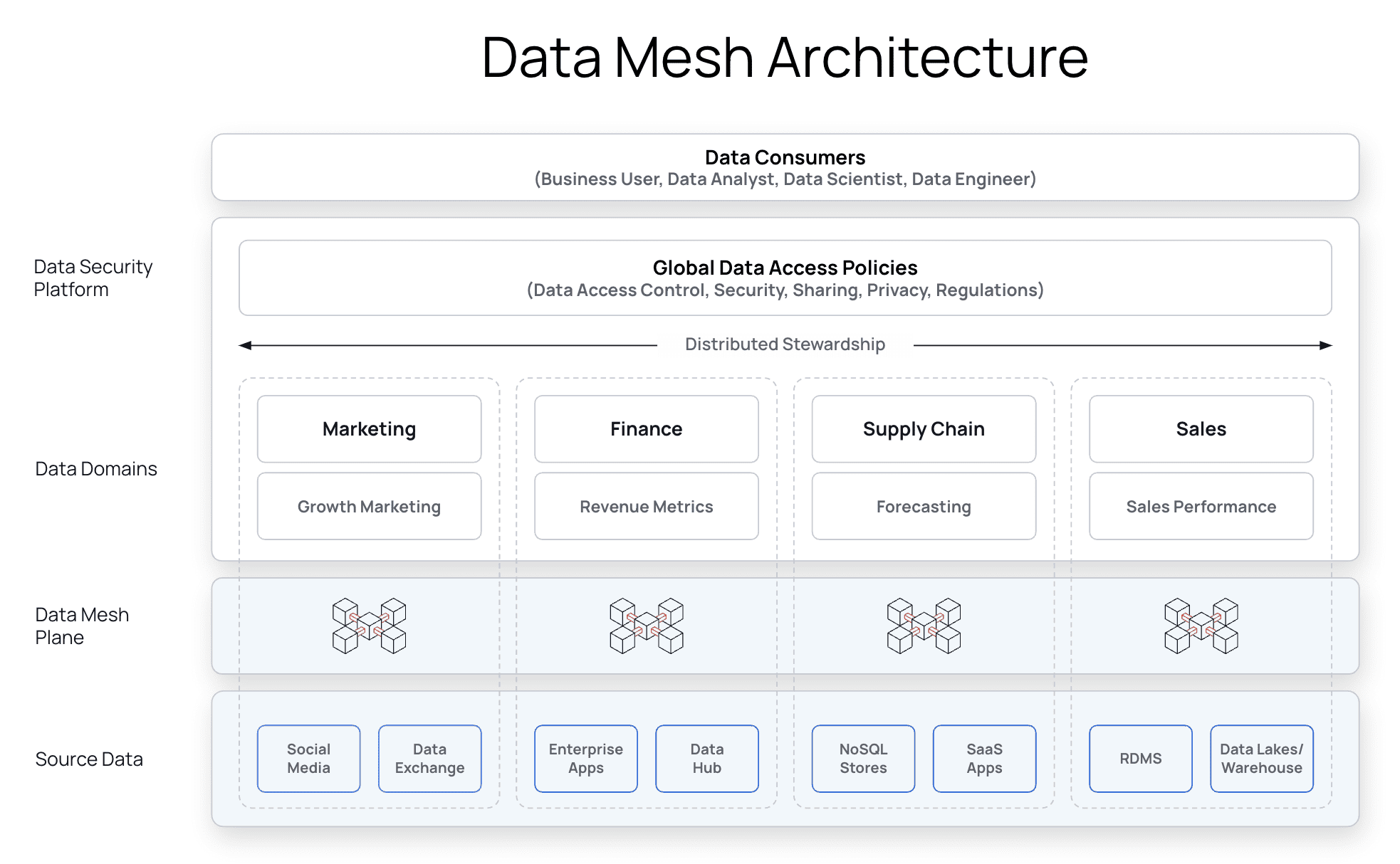
1. Plain Language Policy Authoring
Data policy authoring in plain language eliminates the need for specialized engineering resources, which increases efficiency and productivity. Policies should also be able to be managed as-code to streamline deployment processes in modern data stacks. With dynamic data access platforms such as Immuta’a Data Access platform, customers can reduce policy management burden by 75x.
2. Distributed Management Responsibility
Flexible and easy-to-use interfaces simplify distributed data policy and access management. Data infrastructure teams that oversee deployment and empower line of business stakeholders with self-service policy management have accelerated time to data access by 100x.
3. Easy Proof of Data Access Compliance
It’s critical for organizations and business domains to be able to answer simple questions from auditors or investigations, such as, “Who accessed PII or personal data in the last 30 days for fraud detection purposes?” The data access platform should centralize auditing and data monitoring at the self-serve infrastructure layer to enable supervision across an organization, while still empowering domains to respond to inquiries from policy drivers and data owners alike.
4. Flexibility to Support Attributes, Roles, and Purposes
Many data teams suffer from “role explosion” due to static, role-based policies, which require them to manually manage hundreds or thousands of user roles in specific tables or databases. This problem can be solved with attribute-based access control (ABAC). This approach uses dynamic user subject attributes, such as geography, time and date, clearance level, and purpose, represented as policy variables, to make context-aware decisions at query time. This means that a single ABAC policy can replace more than 100 roles, saving time and reducing security risks.
5. Integration with Modern Data Stacks
Solutions that enable distributed stewardship should easily integrate with third party systems like modern cloud data warehouses, data catalogs, IAMs, and business applications like HR systems, and allow data teams to write policies against those systems. Furthermore, they should not impact performance of the systems with which they integrate.
Benefits of Distributed Data Stewardship for Data Mesh Architectures
The benefits of distributed data stewardship for data mesh architectures include the following:
Accelerates Data Access Time
Powerful plain language policies enable self-service management for business and technical stakeholders who have business context over data access requests. In turn, data consumers benefit from faster speeds to data access and insights.
Improves Data Sharing, Security, and Management
Distributed stewardship allows line of business stakeholders to easily control and understand how data is shared and used based on domain-specific rules, which encourages data sharing across business lines and with third parties. With ABAC, key attributes are determined at query time to determine the validity of the access request. Contextual and purpose-based access controls can also be applied for enhanced security. This eliminates data leak risks when an employee changes roles or leaves the company since roles do not need to be manually managed for each user.
Removes Engineering Bottlenecks
Distributed ownership of data policy management by those who have business context over data use removes engineering bottlenecks and manual work. Engineering resources can instead focus on data product delivery.
Limits Data Use to Specific Purposes
New and expanding government regulations such as CCPA and the GDPR prevent analytics teams from legally using sensitive data without clear and intended purposes. Distributed stewardship provides easy-to-use consent workflows for data teams, allowing them to audit usage purposes and create attribute-based controls that enforce who can use what data and why. With streamlined workflows for consent, it’s easier to comply with legal guidelines and prove that compliance when necessary.
Promotes Secure Data Collaboration
Distributed stewardship’s policy-based approach enables secure data collaboration using data-level zones that manage read/write access across users with different permissions. These zones equalize access rights for all users, making it easy and safe to publish derived data sets without leaking data to users with different permissions.
Next Steps for Distributed Data Stewardship
With native cross-platform data access governance controls that act as the foundational building blocks for enabling federated governance, organizations can strike the right balance between allowing domain owners to easily define and apply their own fine-grained policies and having centrally-managed governance processes. Domain teams can discover and query the same data, and their resulting views change based on their role and the data’s sensitivity, drastically simplifying governance at scale, while still allowing teams to get value from their data.
Try it yourself.
To see how easy it is to start building policies with Immuta, check out our self-guided demo.



