RBAC vs. ABAC: Future-Proofing Access Control
Find out the secret to easy, scalable access control enforcement.

Writing or modifying scripts, managing templates, or creating policy for cloud data platforms is historically a manual process. Assuming there is very little maintenance, doing this process once may be sufficient — but that assumption is never realistic.
Complicating this further is the need to manually replicate this environment at scale to other regions and availability zones, as well as across test and development situations. And even testing can be fraught with a reasonable desire to run fully developed test setups in production — so-called “blue” environments — while keeping the current “green” environment running in parallel. This is especially for mission-critical data access control scenarios.
Vivek Rau, an engineer at Google, summed up this type of work as ‘toil’: “Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.” He goes on to point out how toil can cause career stagnation, low morale, confusion, process delays, negative precedents, attrition, and skepticism of overall processes.
Policy-as-code replaces the toil of building access control scripts, templates, and policies from scratch. But what exactly is policy-as-code, and would you benefit from using it? Let’s dive in deeper.
Policy-as-code refers to the process of authoring, implementing, and managing policies that are expressed as machine-readable code. This allows for automated and consistent policy enforcement, simplified auditing, and improved policy management across data infrastructure and ecosystems.
Policy-as-code is typically implemented using a DevOps type of continuous integration and delivery (CI/CD) pipeline, complete with version control repositories, validation, consistency, testing, committing, trunks, branching, and backporting. Additionally, it can also fit in with bigger DevOps processes and tooling for building and maintaining modern data stacks, powering a huge degree of automation.
Before policy-as-code, consistently managing critical policy on highly sensitive data with just the standard web interface GUI and no DevOps-style repository would be toil — a lot of toil. Correctly filtering records across different cloud availability zones and regions, production and non-production environments, geographies, and various cloud data platforms and services – against a growing set of access rules and without a documentable, automated change management process – is both toilsome and error prone.

Find out the secret to easy, scalable access control enforcement.
Policy-as-code offers three key advantages that can benefit data teams and, ultimately, business outcomes.
1. Consistency & Scalability: Expressing policies as code allows them to be consistently and dynamically applied across entire ecosystems, reducing the risk of errors and need for manual intervention.
2. Governance & Compliance: Machine-readable policies can be easily enforced, monitored, modified, and audited. This makes policies adaptable, provides clear data audit trails, and improves data security posture management, while also mitigating threats and risk of noncompliance.
3. Efficiency & Collaboration: Authoring policies as code allows different stakeholders, such as developers and data engineers, to define, manage, and understand their contents. At the same time, it eliminates the need for manual management and intervention.
There are many ways to approach policy-as-code, with different tools offering configuration management, CI/CD, and infrastructure-as-code (IaC) capabilities. Some popular solutions include Immuta, Terraform, GitLab, Chef, and AWS Config, among others. The most important considerations when choosing the right tool(s) are their compatibility with your existing tech stack, adaptability to your unique policy requirements, interoperability with your workflows.
Let’s take a look at what a policy-as-code approach means for stakeholders in a realistic scenario using Immuta’s command line interface (CLI). The CLI allows you to fully automate and scale sensitive data management into build pipelines by codifying policy configuration, eliminating a huge amount of toil.
This method aggregates all your policies, data sources, purposes, and projects defined in a git repository as a set of plain text, human readable, configuration YAML files. Existing change management systems, such as git workflows, can be used to request changes, track history, and get change approvals. The CLI can also be leveraged in your build pipeline to keep your Immuta instance in sync with your git repository after changes have been merged.
These capabilities allow for massive scalability, automation, and reliability. Using an existing starter policy — including auditing and tracking — you can create consistent policies across different AWS, GCP, or Azure zones, regions, or instances — without having to start from scratch. This also allows you to manage and automate those edits with other configuration automation tools in your data stack, such as Chef and Puppet.
With this feature, a baseline set of images for the data platform stack, with a set of baseline configurations, can have a baseline set of access controls applied. The result is end-to-end stability and efficiency across multiple heterogeneous data platform stacks, including data lakehouses.
Policy lacks portability and repeatability, with risk from drift, gaps, rework, and potential errors.

Centralized configuration(s) for multiple access control plane(s), providing consistent policy enforcement in differing regions, availability zones, and clouds.
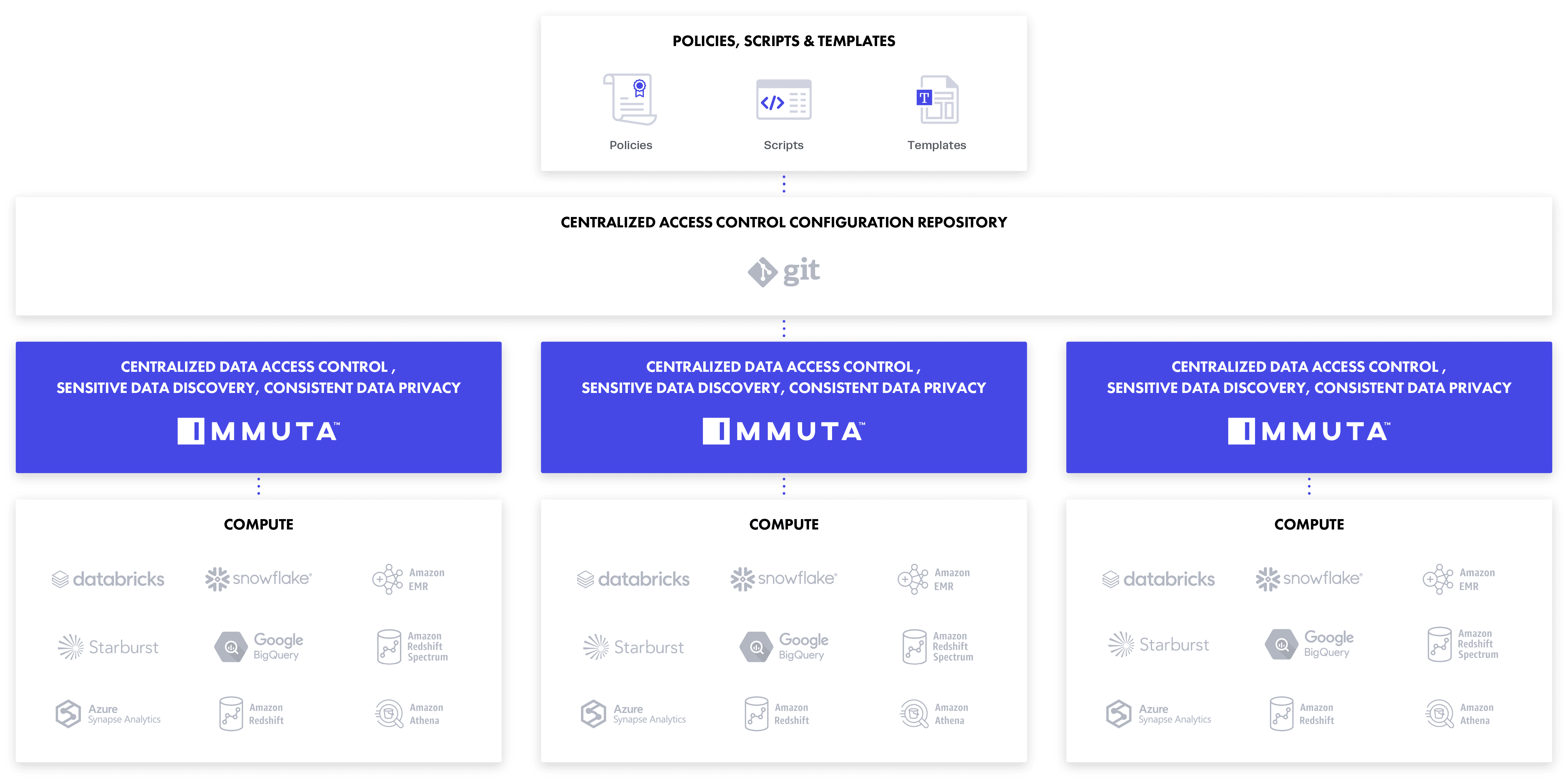
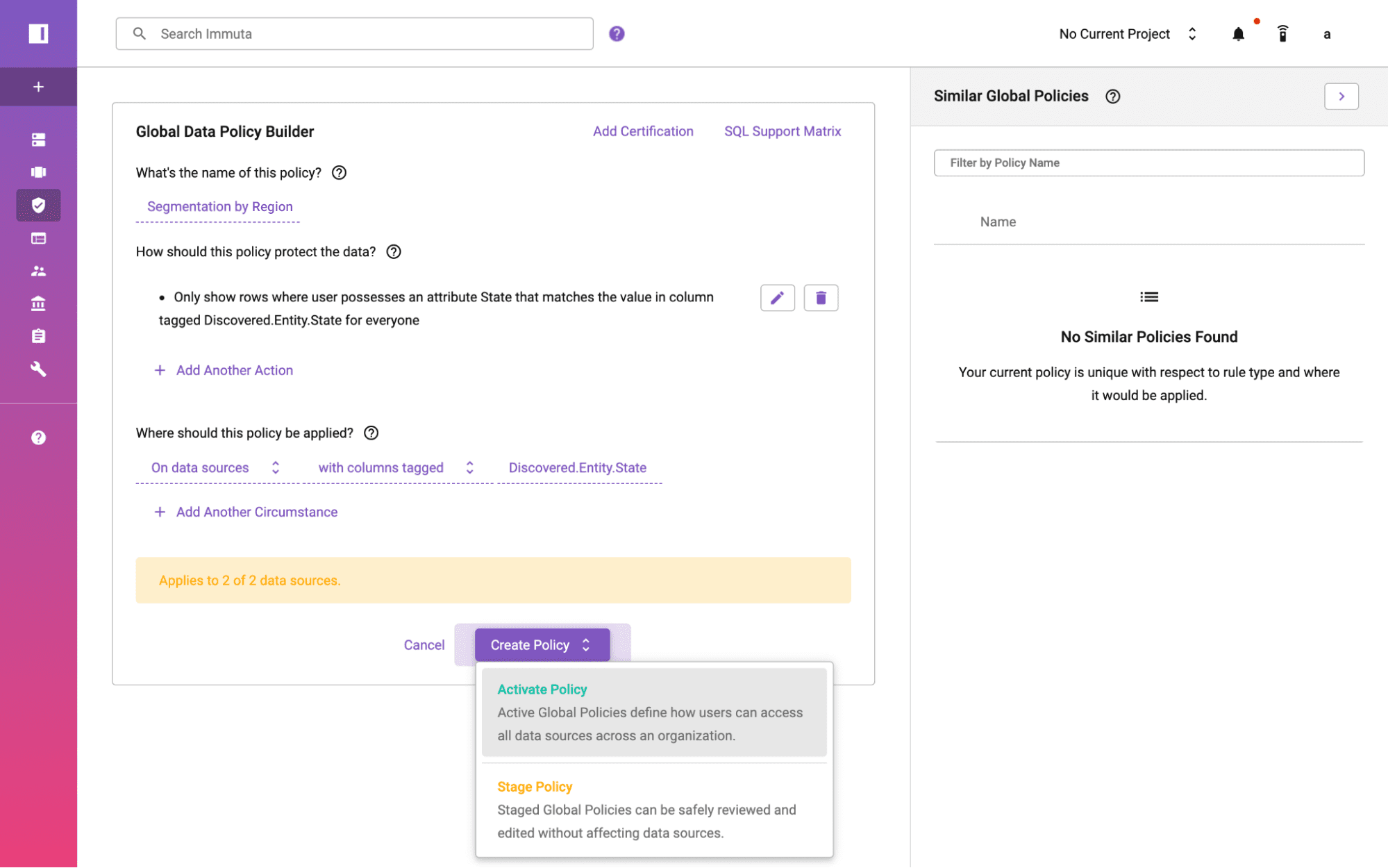
For data owners, domain teams, and legal and compliance stakeholders, a UI that enables plain language data policy authoring facilitates transparency and collaboration, with no technical expertise required.
For data engineering, architecture, and platform teams, writing policies as-code via a CLI is straightforward and automates the UI.
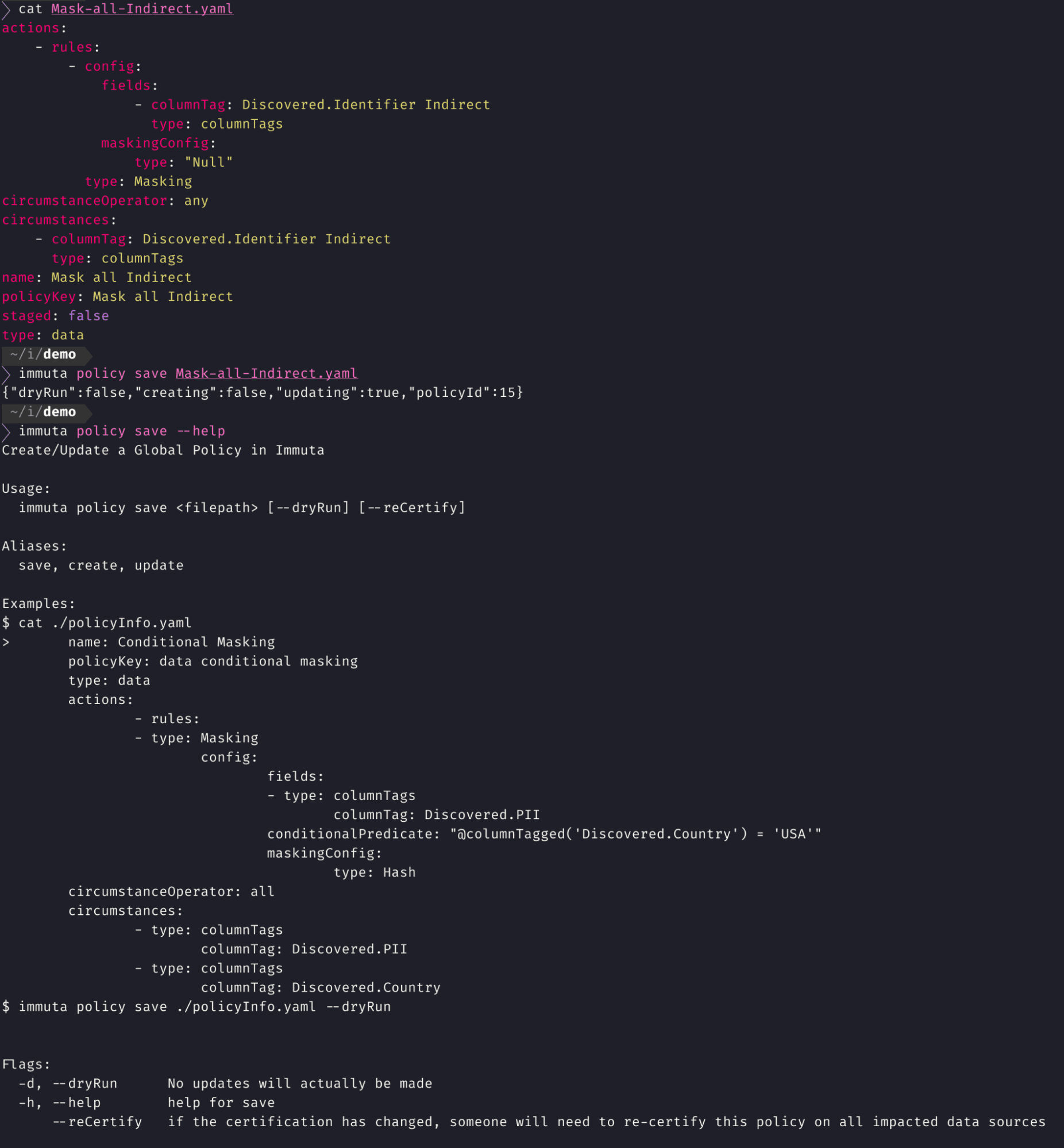
This approach to policy-as-code allows you to:
Programmatically integrating plain language policies and using easy-to-understand declarative files in DataOps tool chains means you can:
Policy-as-code is a reliable, automated, low-error, highly scalable, and ultimately low-toil way of managing access control across many cloud platforms and geographies. The ability to industrialize data platform builds by hooking into other automation tools allows you to leverage best-of-breed technologies without additional manual processes and toil.
Check out this recorded demo showing the Immuta CLI in action, managing a cross-platform policy that segments and masks data by the user’s region.
Get an up-close look at Immuta.


