
What Is k-Anonymization?
Privacy preserving analytics attempt to enable the exploitation of data sets that include private and sensitive data in a manner which protects the disclosure and linkage of sensitive data to individuals. At a minimum, this means removing or obscuring all directly identifying attributes (DIs), which are defined as publicly known attributes unambiguously linked to an individual, within a data release. DIs include, but are not limited to, tax identification numbers, medical record numbers, and license numbers.
While addressing DIs is a necessary step, nearly all practical applications also require additional controls to be placed on publicly known attributes that are weakly associated with an individual. These attributes, known as indirect or quasi-identifiers (QIs), do not unambiguously identify an individual, but when combined with other QIs are strong indicators of identity. The canonical example of this was highlighted by Latanya Sweeney, et. al. In this result, researchers demonstrated that the combination of an individual’s US postal code, date of birth, and gender can uniquely identify approximately 87% of the United States population. As a result, a thorough approach to privacy preserving analytics requires protecting the privacy of QIs.
However, there is a problem with protecting privacy over QIs. While DIs contain little ancillary analytic value, QIs can often be useful in performing analytics. Gender, postal code, age, and occupation, among others, are all QIs that have analytic utility in a myriad of applications. To address this dilemma, Sweeney, et. al. proposed a property of a pseudo-anonymized data release called k-anonymity.
The k-anonymity of a data release is a measure of the smallest number of rows which contain a common set of QIs. It is achieved by splitting the records in a data release into non-overlapping groups, called cohorts, each of which contains only records that have a common set of QIs, meaning that the QIs of any single record cannot be distinguished from at least k-1 other records. This way, any individual in the data set will have identical quasi-identifiers with at least k-1 other people, making it ambiguous as to whether a record belongs to a specific person.
k-Anonymity as a Privacy Enhancing Technique
As stated earlier, k-anonymity is simply a metric of a data release, as opposed to a specific algorithm or privacy technique. However, using a combination of suppression and generalization can increase the k-anonymity of a data release. Suppressing a QI amounts to removing the value for that QI in a given cohort entirely, while generalizing it means relabeling the quasi-identifier with a label that is semantically similar, but less precise. An example of suppression is removing street names from a data release, and an example of the generalization is replacing exact postal codes with the state of the location.
Privacy preserving analytics defines a minimum value of k-anonymity, and QIs are suppressed and/or generalized until the desired value is achieved. For nearly any non-trivial data set, there are myriad ways to produce a data release that satisfies the k-anonymity constraint. The challenge is finding one that optimizes the data release’s utility while satisfying the k-anonymity constraint.
Defining a Rule Set for K-anonymity
Now that we understand the principles of k-anonymization, let’s see how it works in practice.
Utility, in an analytics environment, denotes the ability to exploit a data release to gain some insight. Given that the desired insights are application dependent, utility can be difficult to define in a general sense. Ideally, an algorithm could generate a set of generalization and suppression rules, collectively known as the data policy, which optimizes utility. Practically, such an optimization falls into a class of (nondeterministic polynomial) NP-hard problems, often making it computationally infeasible to find a globally optimal data policy.
Immuta’s approach is to look at which attribute values can be released in a way that optimizes the information content, while maintaining some minimal k-anonymity. Initially, all data in the release is suppressed. Then, a single attribute value, chosen to maximize information content, is released. This is repeated incrementally until an attribute value’s release would break the k-anonymity constraint.
The incremental process results in a decision tree object. In an effort to reduce information loss by k-anonymizing the data, Immuta incrementally discloses the most frequently occurring attribute value in a data set, partitioning the data into two non-overlapping subsets, and repeats this process until one of the set of termination conditions is met.
k-Anonymization Decision Tree Example
As an illustrative example of this process, consider the following sample data set, where the minimal cohort size is 2 (K=2):
| ID |
Occupation |
City |
State |
| 1 |
Lawyer |
Washington |
DC |
| 2 |
Lawyer |
Washington |
DC |
| 3 |
Lawyer |
Hamlet |
OH |
| 4 |
Accountant |
Hamlet |
OH |
| 5 |
Farmer |
Hamlet |
OH |
| 6 |
Farmer |
Hamlet |
OH |
| 7 |
Lawyer |
Columbus |
OH |
| 8 |
Accountant |
Withamsville |
OH |
| 9 |
Accountant |
Whately |
MA |
| 10 |
Accountant |
College Park |
MD |
| 11 |
Accountant |
Bellevue |
KY |
Table 1: Sample Data Set to be K-anonymized to (K=2).
If we release the most frequently occurring attribute value (State = OH), the data set can be split into two partitions, rows where State = OH and State <> OH. We will label the first partition as D1 (containing 6 rows) and the second as D2 (containing 5 rows).
For rows in D1 we ignore State = OH because its complementary cohort is too small. In this same data set. We can release City=Hamlet for D1 rows, as the most frequently appearing, acceptable value in the dataset. For the set of rows where State = OH and City = Hamlet, we can also disclose Occupation = Farmer and still preserve 2-anonymity. For D2, rows where State <> OH, Occupation = Accountant can be released, but nothing else further. Doing this results in the tree shown in Figure 1:
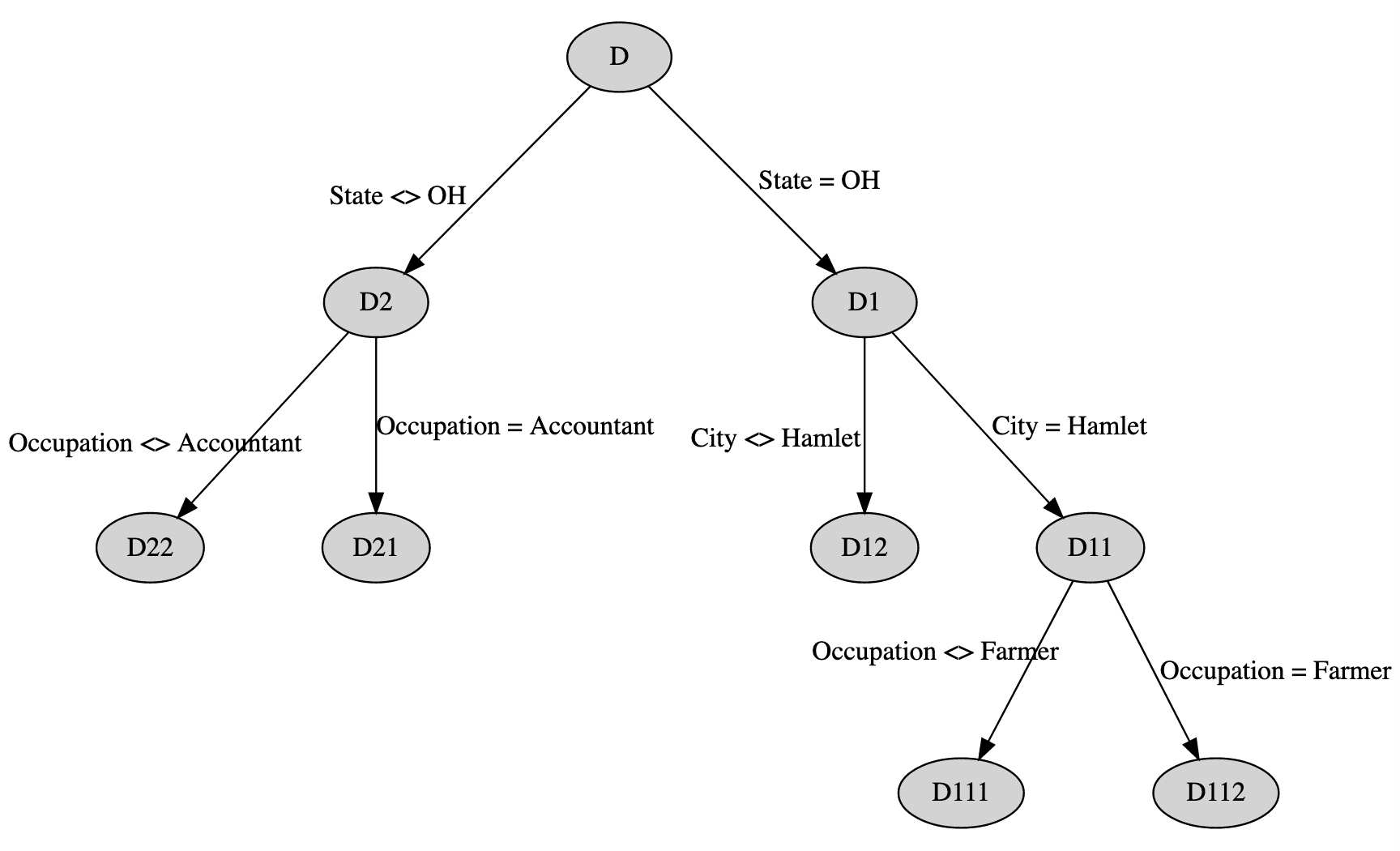
This results in five distinct cohorts. In order to enforce this tree in native SQL, we need to compile it into a series of simple boolean predicates, and inject those predicates anytime the data is queried. The predicate for any cohort can be found by taking the intersection of conditions along the path between a terminal node and the root node. This is shown in the table below:
| Partition ID |
Rule |
Release Occupation |
Release City |
Release State |
| D111 |
(STATE = OH) AND (CITY=Hamlet) AND
(OCCUPATION = Farmer) |
Yes |
Yes |
Yes |
| D112 |
(STATE = OH) AND (CITY=Hamlet) AND
(OCCUPATION <> Farmer) |
No |
Yes |
Yes |
| D12 |
(STATE = OH) AND
(CITY <> HAMLET) |
No |
No |
Yes |
| D21 |
(STATE <> OH) AND (OCCUPATION=Accountant) |
Yes |
No |
No |
| D22 |
(STATE <> OH) AND (OCCUPATION <> Accountant) |
No |
No |
No |
Table 3: Predicate for each cohort
Once in this form, Immuta simplifies the predicate and refactors it to a condition whether or not to disclose a specific attribute. For our sample data set this would be:
| Partition ID |
Rule |
| Occupation |
((STATE = OH) AND (CITY=Hamlet) AND (OCCUPATION = Farmer))
OR
((STATE <> OH) AND (OCCUPATION=Accountant)) |
| City |
((STATE = OH) AND (CITY=Hamlet)) |
| State |
(STATE = OH) |
Table 3: Attribute Disclosure Rules
Once the attribute predicates have been simplified, the Immuta data policy enforcement engine will rewrite a query to enforce k-anonymity constraints. For example, the following query:
SELECT occupation, state, COUNT(*) as
group_count
FROM my_table
GROUP BY occupation, state;
Will automatically be rewritten as:
SELECT
CASE WHEN NOT (
(state <> ‘OH’ AND occupation =
‘Accountant’) OR
(state = ‘OH’ AND city = ‘Hamlet’
AND occupation = ‘Farmer’))
THEN NULL ELSE occupation END AS
occupation, CASE WHEN NOT (state = ‘OH’) THEN NULL ELSE state END AS state, COUNT(*) as group_count FROM my_table GROUP BY 1, 2;
Once these rules are in place, the k-anonymized table is shown below:
| ID |
Occupation |
City |
State |
| 1 |
|
|
|
| 2 |
|
|
|
| 3 |
|
Hamlet |
OH |
| 4 |
|
Hamlet |
OH |
| 5 |
Farmer |
Hamlet |
OH |
| 6 |
Farmer |
Hamlet |
OH |
| 7 |
|
|
OH |
| 8 |
|
|
OH |
| 9 |
Accountant |
|
|
| 10 |
Accountant |
|
|
| 11 |
Accountant |
|
|
Table 4: k-Anonymized Table
The resulting rules offer robust k-anonymization as new rows are added into the data set. Previously unobserved values will automatically be suppressed using the constructed rules. Consider two new rows (‘Accountant’, ‘New York’, ‘NY’) and (‘President of the United States of America’, ‘Washington’, ‘DC’). Using the attribute predicates, this would result in a released row of (‘Accountant’, NULL, NULL) and (NULL, NULL, NULL), respectively.
Another interesting artifact to note is that one set of rows with all NULL values will always exist. This cohort is considered a sacrificial cohort, absorbing any previously unobserved cohorts and thereby ensuring the robustness of k-anonymity protections.
Ready to see how Immuta streamlines and automates policy enforcement across all your data from a centralized plane? Try it for yourself in our walkthrough demo.



