In this blog, you’ll learn about:
- Snowflake data shares
- Considerations and complexities that can arise when “Snowflake data sharing” sensitive data
- How Immuta + Snowflake help simplify and scale sensitive data sharing for global organizations and can do the same for you!
What is a Data Share?
One of Snowflake’s major benefits is that you can point separate Snowflake accounts toward your data, without physically moving that data. This is called a “Snowflake Data Share.” Under the covers, the Snowflake compute (tied to the Snowflake account) is abstracted from the underlying data storage in the cloud, which makes this all possible. Let me explain…

This allows conglomerates comprising many disparate companies (through acquisitions and/or partnerships), or organizations that are managed separately due to legal obligations, to share data without sharing compute costs. In turn, this strategy enables multiple separately-managed Snowflake accounts, per organization/company, to leverage Snowflake data sharing (the Event Horizon) to share data across those organizations or between companies, and each can manage its own compute costs.
Cross-organizational data shares must be executed with care. Why? Because cross-organizational data access control requirements exist, and enforcement of those controls must be managed within each organization prior to sharing. This can require cross-organizational coordination and implementation of Snowflake governance controls on the data, per organization, to ensure all legal obligations are met.
The Challenge of Data Shares
For conglomerates with several brands or lines of business (LOBs), the ability to “fold” Snowflake accounts across the business helps accelerate data-driven initiatives (like the Event Horizon traveling faster than the speed of light!…but data sharing does operate within the boundaries of the speed of light).
However, not all data can be freely shared across brands or LOBs. Legal, compliance, and data sharing agreements must be adhered to in order to keep data secure, but they may be heterogeneous across the organization. Imagine having a standard set of data access policies in a single Snowflake account, but when sharing data, those policies must be tweaked in order to remain compliant, depending on the organization with which the data is being shared. This is the challenge of data access control with shares.
When creating a data share, the table must be represented as a Snowflake secure view in order to share it, and Snowflake row access and masking policies can limit which rows and columns various consuming organizations can see. To explain this, we will run through a concrete example.
In this example, we are going to restrict which country data users are allowed to access through a Snowflake row access policy. Due to data localization laws, you need to implement this policy not only for your cross-organizational shares, but also for your internal users. For instance the data owner needs to protect this data internally as well as externally, which is typical with sensitive data.
Using some (fake) credit card transaction data, here is a query against that table with no Snowflake row access policies applied:
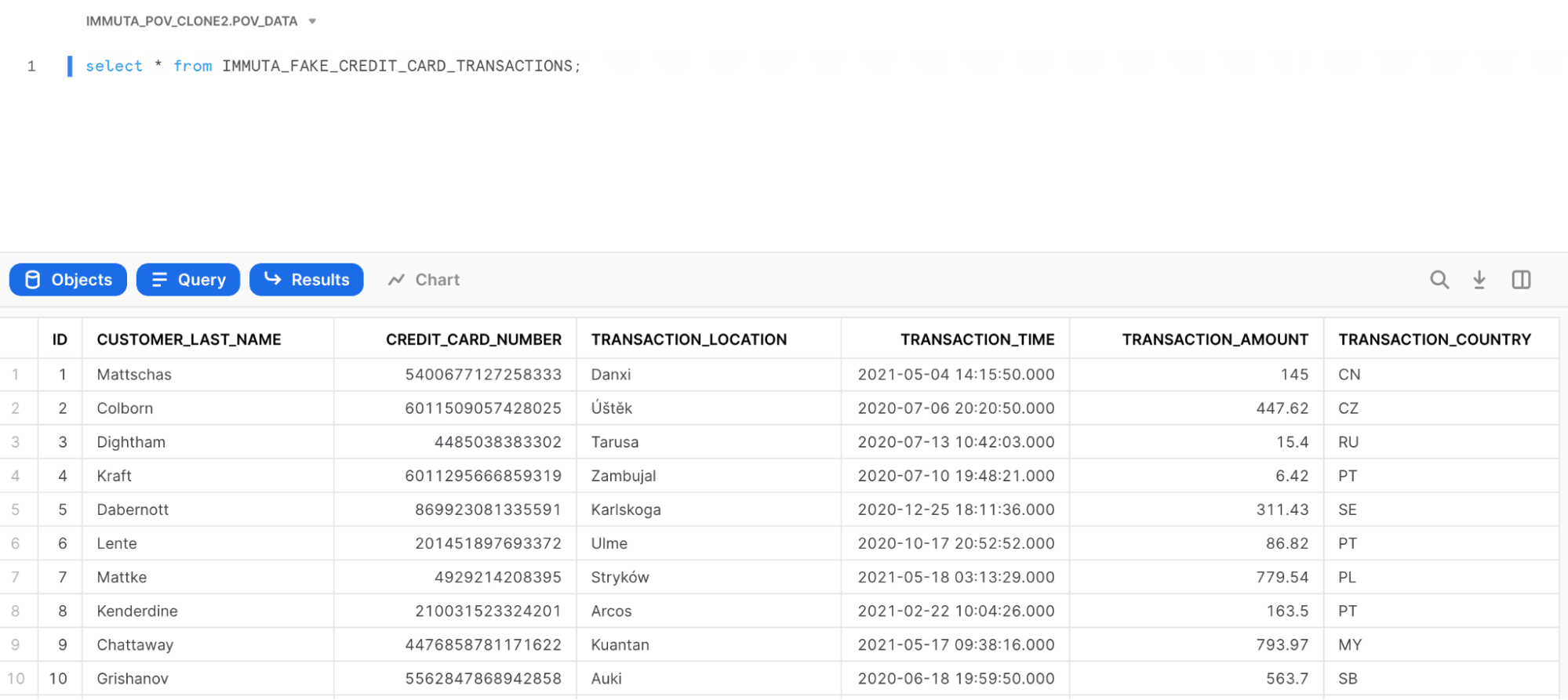
Without getting into the details of how Snowflake row access policies work, you could build a Snowflake row access policy that restricts users to certain countries. For example, my user only has access to US and JP data, so when I run the exact same query on that table, I now only see US and JP data (take note of the TRANSACTION_COUNTRY column):
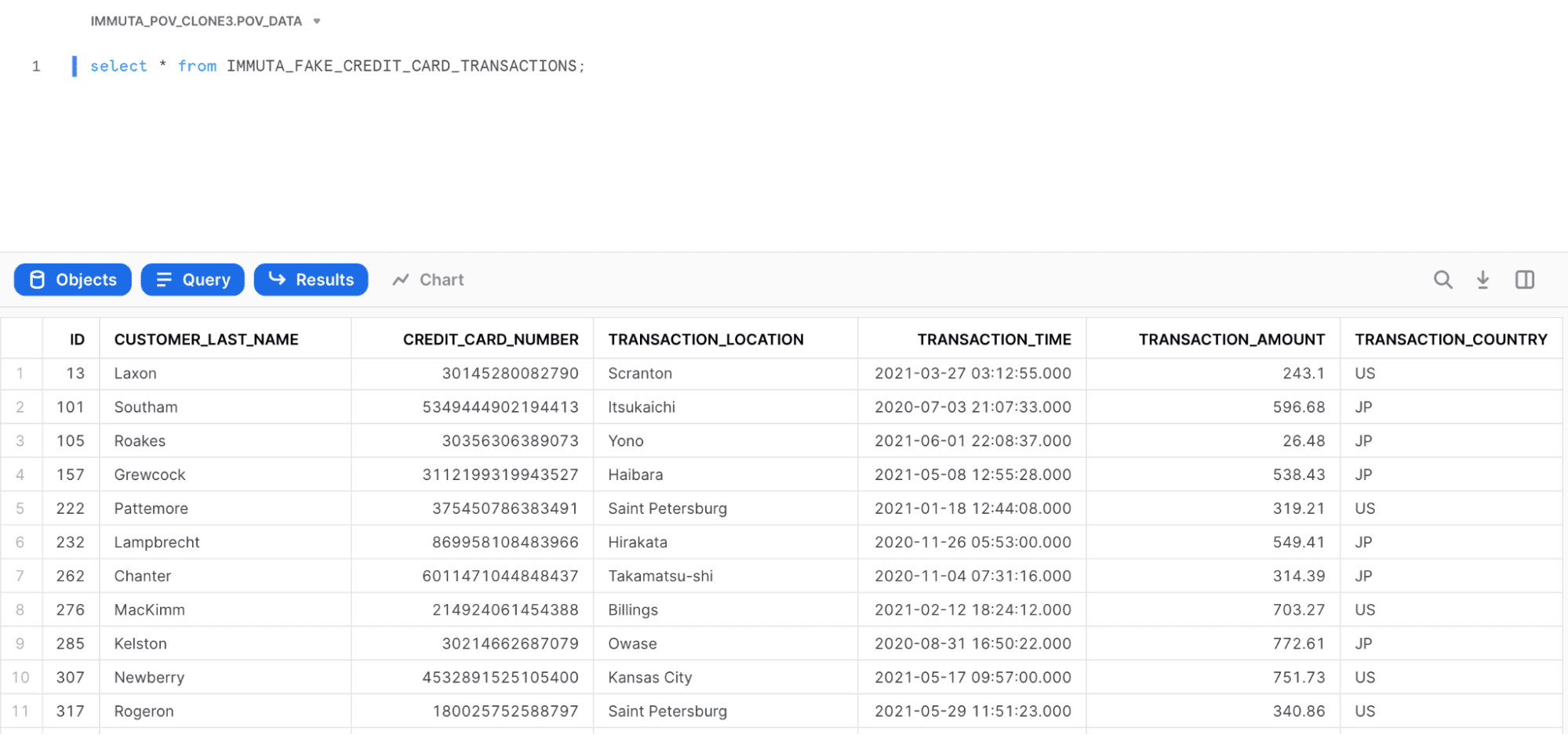
The challenge is, when you build policies in Snowflake (or anywhere, for that matter), they need to reference a role or some other reference to a user population in order to know what policy to enforce – you need to know who is reading the data in order to enforce the right thing. When sharing externally, however, you have no real user reference – it’s just an “external consumer.” This is intentional to protect the privacy of the users in the remote account, and to avoid the provider feeling that they can control which remote users can access what data, since the remote consuming account administrator is free to add, change, or re-define users at any time.
To account for this, Snowflake provides some handy context functions like invoker_share() and current_account(). These can uniquely identify the external share name or account the share is being accessed from, which you need to account for in your Snowflake row access or masking policy. For example, here is a masking policy:
create or replace masking policy my_masking_policy as (val string) returns string -> CASEWHEN invoker_share() != null THEN '**MASKED**' WHEN current_role() = [the rest of your real masking policy] ELSE val
END;
Or…
create or replace masking policy my_masking_policy as (val string) returns string -> CASEWHEN current_account() != 'IMMUTA' THEN '**MASKED**' WHEN current_role() = [the rest of your real masking policy] ELSE val
END;
This workflow can become complex because you, the sharer must:
- Update the row access policy(ies) and/or masking policy(ies) every time you create a new share to account for the new INVOKER_SHARE/CURRENT_ACCOUNT
- Alternatively, use a more robust technique where the policy references a separate table that captures the required logic per share to inject into the policy, and you must update that table instead*. This policy lookup table technique requires tight coordination between the users creating the data shares and the users creating policies on the base tables (which are typically not the same users).
- Understand the goal of the policy and have the technical know-how to update the policy or policy lookup table.
- Have permission to update the policy or policy lookup table.
- Ensure that any time there’s a policy change to the original base table(s) that backs the shared secure view(s), the person making that base table policy change (which is likely not the original sharer) considers all the existing data shares that may also be impacted.
Scaling Snowflake Data Sharing with Immuta
How can Immuta make this more scalable and risk-free?
As discussed, without Immuta the data sharer must update all Snowflake data access policies (or policy lookup table(s)) for every share they create. With Immuta, when sharing data, you, the sharer, can simply describe what the consumer you are sharing with “looks like” relative to the existing Snowflake data access policies in order to enforce the appropriate controls. This is a more scalable solution because, you, the sharer:
- Understand the context of who you are sharing with.
- Only need limited knowledge of the existing policies’ context or goals.
- Don’t need to alter the policy or policy lookup table at all.
- Don’t need tight coordination with the users that are creating policies on the base tables that back the data shares.
- Can only share data that you are allowed to see – remembering it’s important that users who can create Data Shares shouldn’t necessarily be the same users that can make policy changes.
Let’s walk through these steps in Immuta:
Here is that same Snowflake row access policy defined through the Immuta plain language policy builder. This makes it easy to define scalable row access and column masking policies, which are administered directly in Snowflake to bolster its native Data Governance capabilities. In this case, Immuta is administering a Snowflake row access policy.
You’ll notice Immuta’s simple policy authoring technique dynamically injects the user country attribute at runtime to determine which rows they should see and which they should not. This is a technique termed attribute-based access control (ABAC). Explaining ABAC is out of scope for this blog, but you can read more about it here.
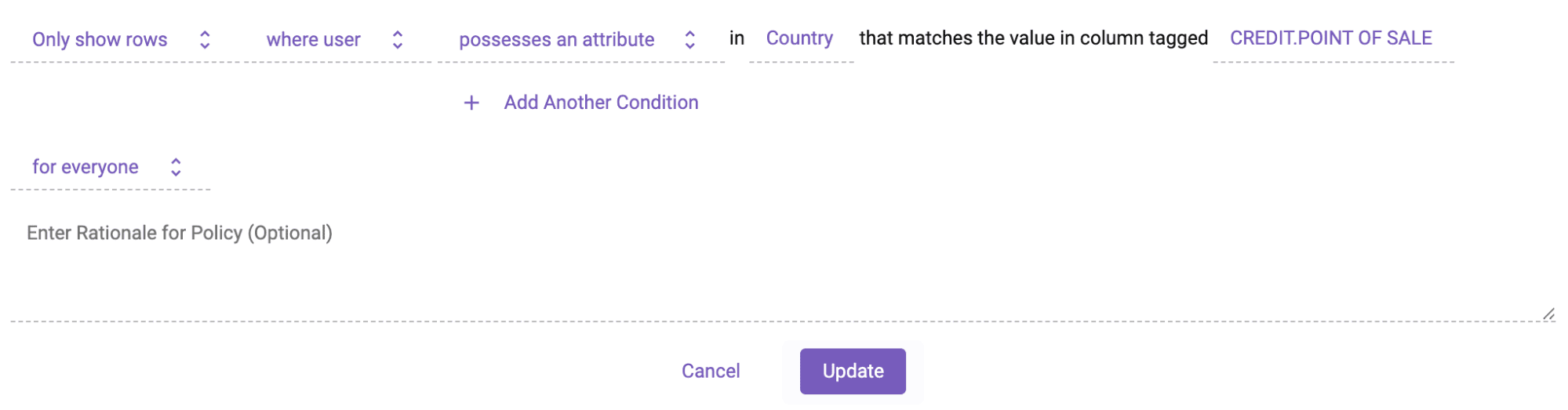
This policy would apply to all internal users in the company and could be authored by a policy owner other than you, the person attempting to create the cross-organizational data share. Continuing with our example from earlier, you as the user would be restricted to seeing only US and JP data, no matter what your query is.
Now let’s say that you want to share that credit card transactions table with your organization’s Japanese counterparts in a separate Snowflake account, understanding they should only see the JP data. To do this, you would create a Project in Immuta and add the credit card transactions table to it. Think of this Project as your “Data Share”:
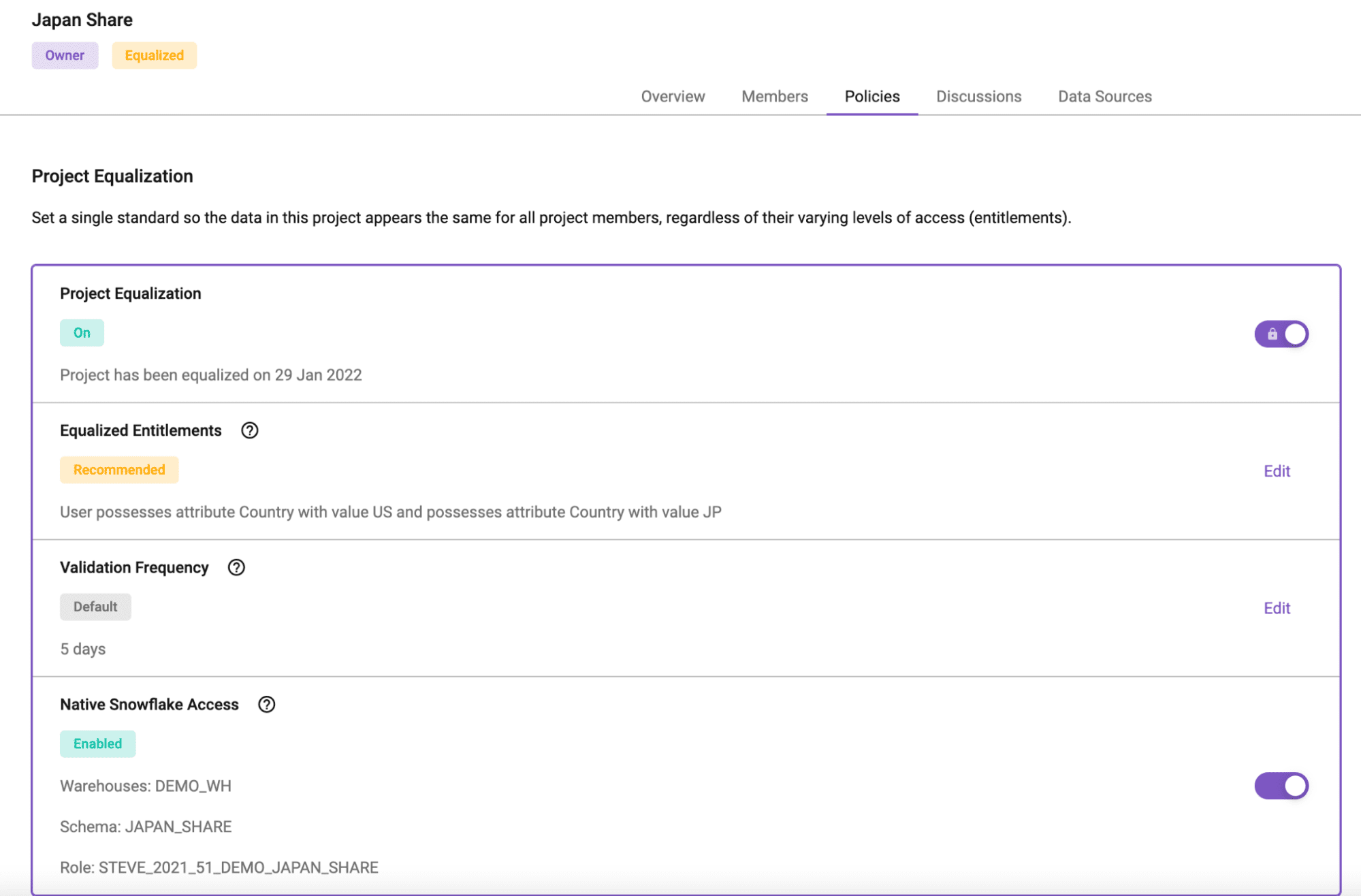
There are a few things to point out about this Project you just created, aka your Snowflake Data Share. First, at the bottom, you’ll see “Native Snowflake Access.” Here, you’ll see the Schema that was created for this Data Share (JAPAN_SHARE), as well as the Role (STEVE_2021_51_DEMO_JAPAN_SHARE) you would use to access the table(s) in the Data Share. Both are named based on the Project name and your Immuta configuration.
If we navigate to the JAPAN_SHARE schema in Snowflake using the STEVE_2021_51_DEMO_JAPAN_SHARE role, we will see a secure view there! It is named the same as the original table, but is in a different database (the Immuta database) and schema (created Project schema). This is the secure view that can be shared once you take a few more steps.
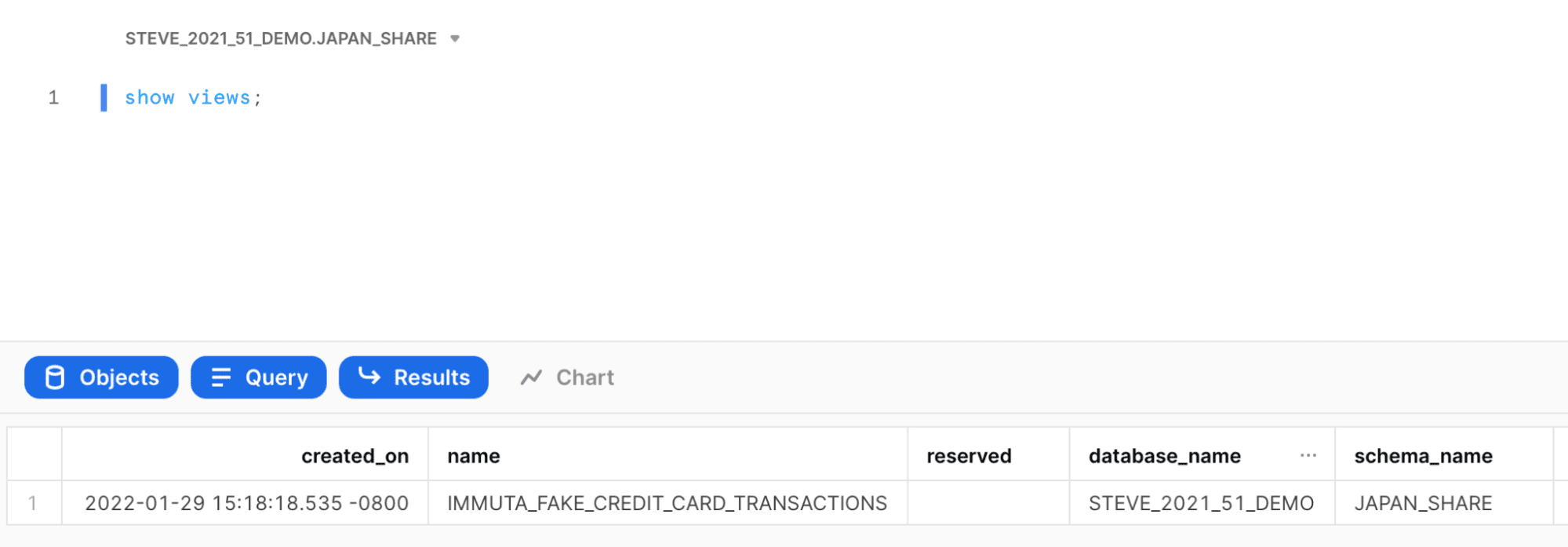
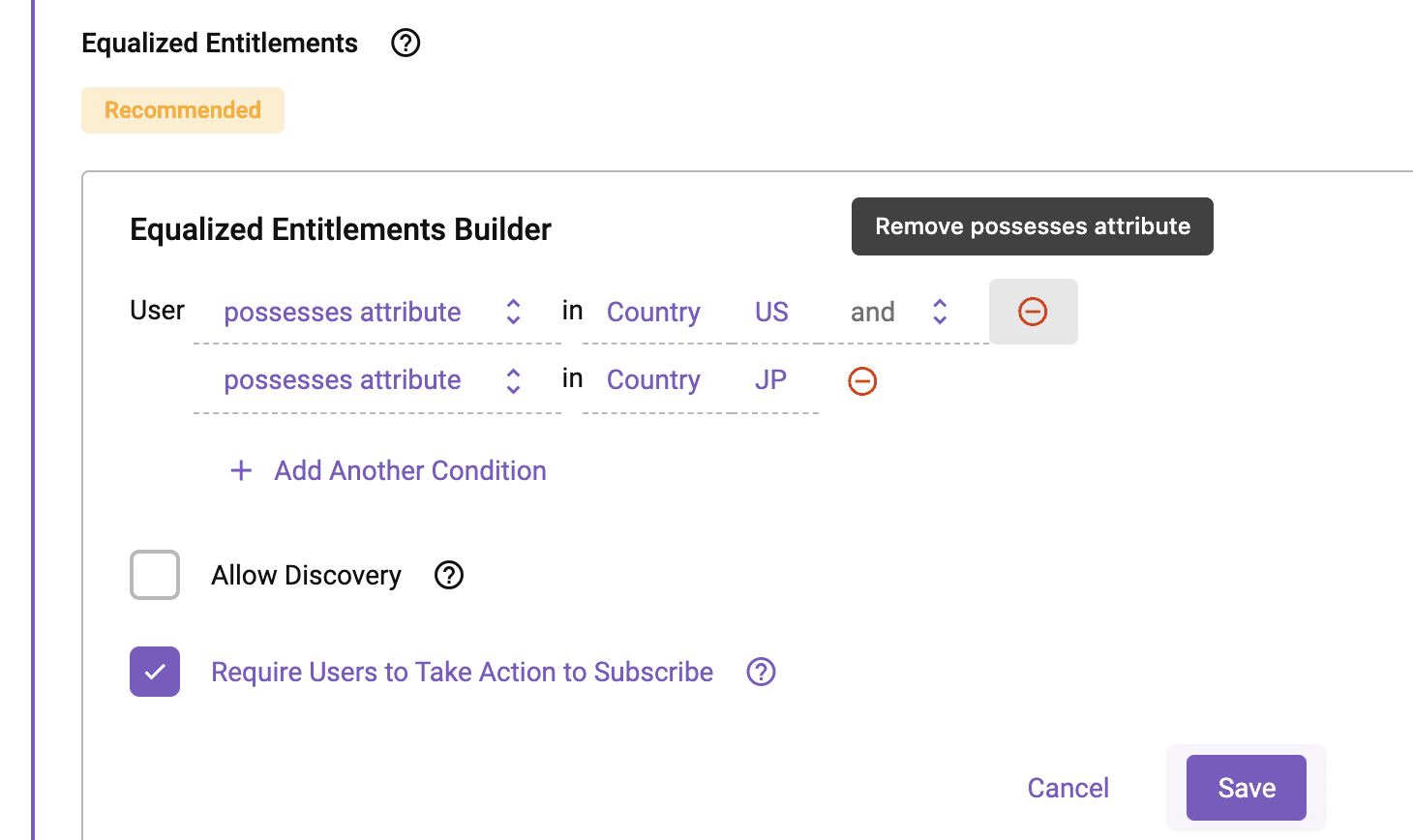
Remember, though, you want to share data with your Japanese counterparts. So, how do you do that if you can’t edit the generated secure view? Even if you could, would the sharer have the technical know-how? That’s where the “Equalized Entitlements” of your Data Share comes into play (see figures 4 and 6).
Equalized Entitlements allow you to force all users in the Project (the Data Share) to the “same level of access.” In this case, you’ll want to remove “US” from the equalized entitlements and only leave JP, effectively making your Data Share “JP only.” It’s important to note that when editing the entitlements:
- You cannot add entitlements you don’t possess, and
- The Equalized Entitlements screen only displays entitlements for edits relevant to the policies on the table(s) in the Project
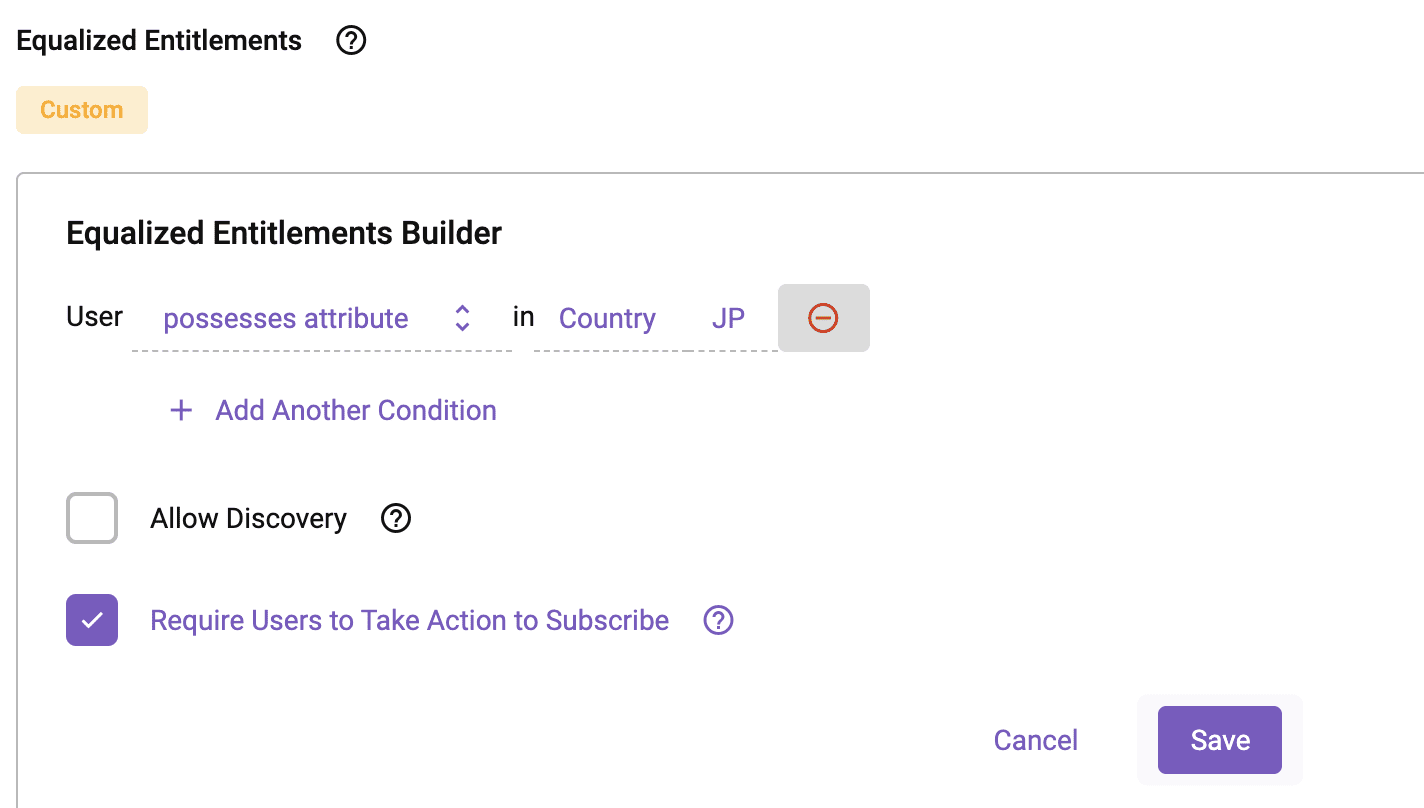
Once you remove “US” and save, the secure view in the JAPAN_SHARE schema will be updated to only show JP data.
Now, to create the data share, an ACCOUNTADMIN should take a look at your Project in Immuta and validate what is about to be shared. They can do so by examining any documentation you’ve written in the Immuta Project, as well as looking at your equalization setting. When satisfied, they can run these commands to create the share from your Project on your behalf:
CREATE SHARE COMMENT=''; GRANT USAGE ON DATABASE TO SHARE ; GRANT REFERENCE_USAGE ON DATABASE <database(s) with table(s) backing secure view(s)> TO SHARE ; GRANT USAGE ON SCHEMA . TO SHARE ; GRANT SELECT ON VIEW .. TO SHARE ;
Now the credit card transaction table has been successfully shared with only the JP data, and you have not had to edit any Snowflake access policies at all.
Executing Snowflake Data Sharing with Immuta
Immuta allows scalable Data Share management by empowering non-power users to create and manage shares without manually editing Snowflake data access policies (or policy lookup tables). This removes burden from the data platform team and lowers the risk of data leaks. Using this process, customers have been able to mitigate data sharing complexity while accelerating business initiatives and remaining compliant.
Specifically, this example demonstrates that the user creating the share only has to understand what the external consumer “looks like” (JP only) and is able to easily administer the secure view ready for sharing without having to update any native Snowflake policies.
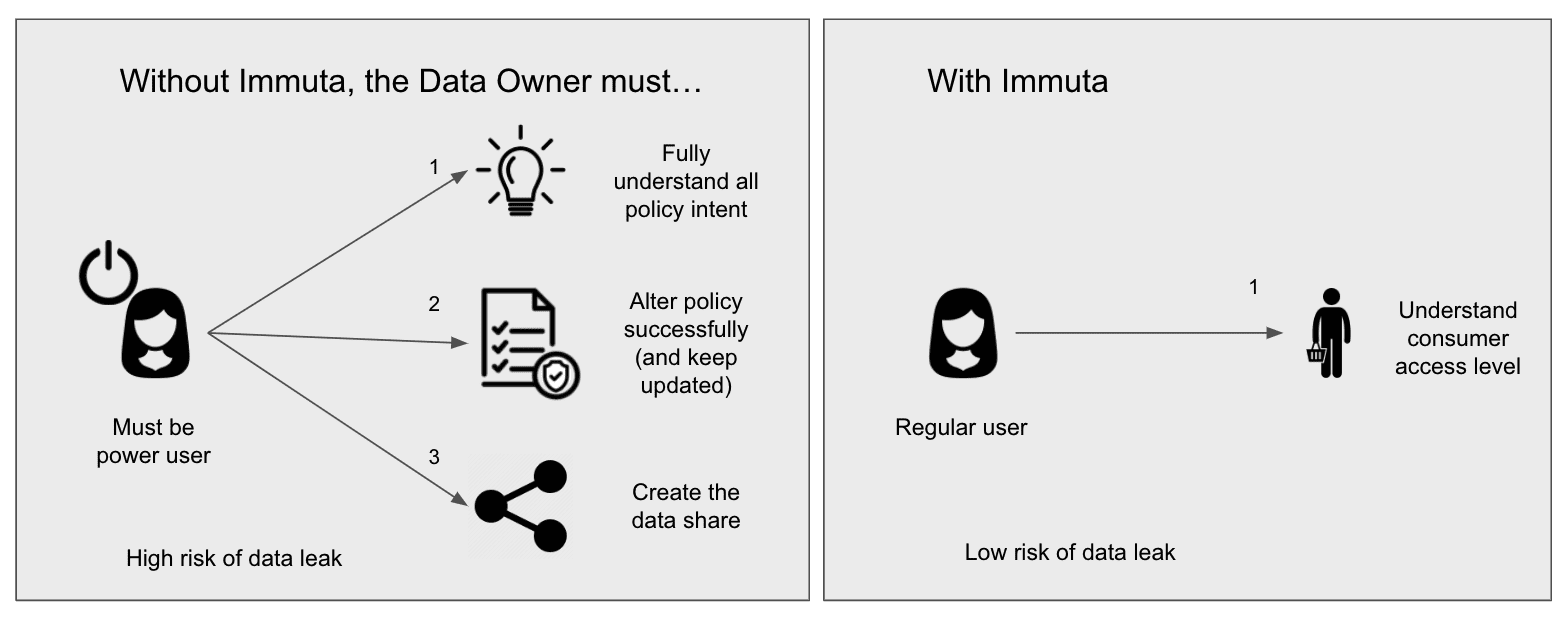
^ this analogy was inspired by this LinkedIn post by Mike Renwick.
* example row access policy using a lookup table approach:
create or replace table rap_db.rap_schema.rap_control (type varchar(200), id varchar(200), c_code varchar(200));
insert into rap_db.rap_schema.rap_control select 'ACCOUNT','IMMUTA','JP';
insert into rap_db.rap_schema.rap_control select 'ACCOUNT','AUTO_INSR_SUB','US';
insert into rap_db.rap_schema.rap_control select 'ACCOUNT','AUTO_INSR_SUB','MX';
insert into rap_db.rap_schema.rap_control select 'ROLE','KOREA_USERS','KR';
insert into rap_db.rap_schema.rap_control select 'ROLE','CANADIANS','CA';
create or replace row access policy rap_db.rap_schema.rap_rap as (country string) returns boolean ->
exists (select country from rap_db.rap_schema.rap_control where
country = c_code
and (( current_role() = id and type = 'ROLE')
or ( current_account() = id and type = 'ACCOUNT')));
alter table rap_db.rap_schema.table1 add row access policy rap_db.rap_schema.rap_rap on (country);
alter table rap_db.rap_schema.table2 add row access policy rap_db.rap_schema.rap_rap on (country);