Implementing row- and cell-level security by hand can be a pain, whether that means maintaining an ETL pipeline to transform raw data into “clean” data that is viewable by analysts, or maintaining a system of GRANTs on views implementing the policies for an organization. This also does not factor in how the user base and policies change over time, meaning that the affected pipelines and GRANTs must always be manually kept up-to-date.
This article walks through how to use Immuta’s data access control capabilities to implement dynamic Databricks row-level security and cell-level security for data analytics and engineering teams.
Sample Sensitive Data Set for Databricks Row-Level Security
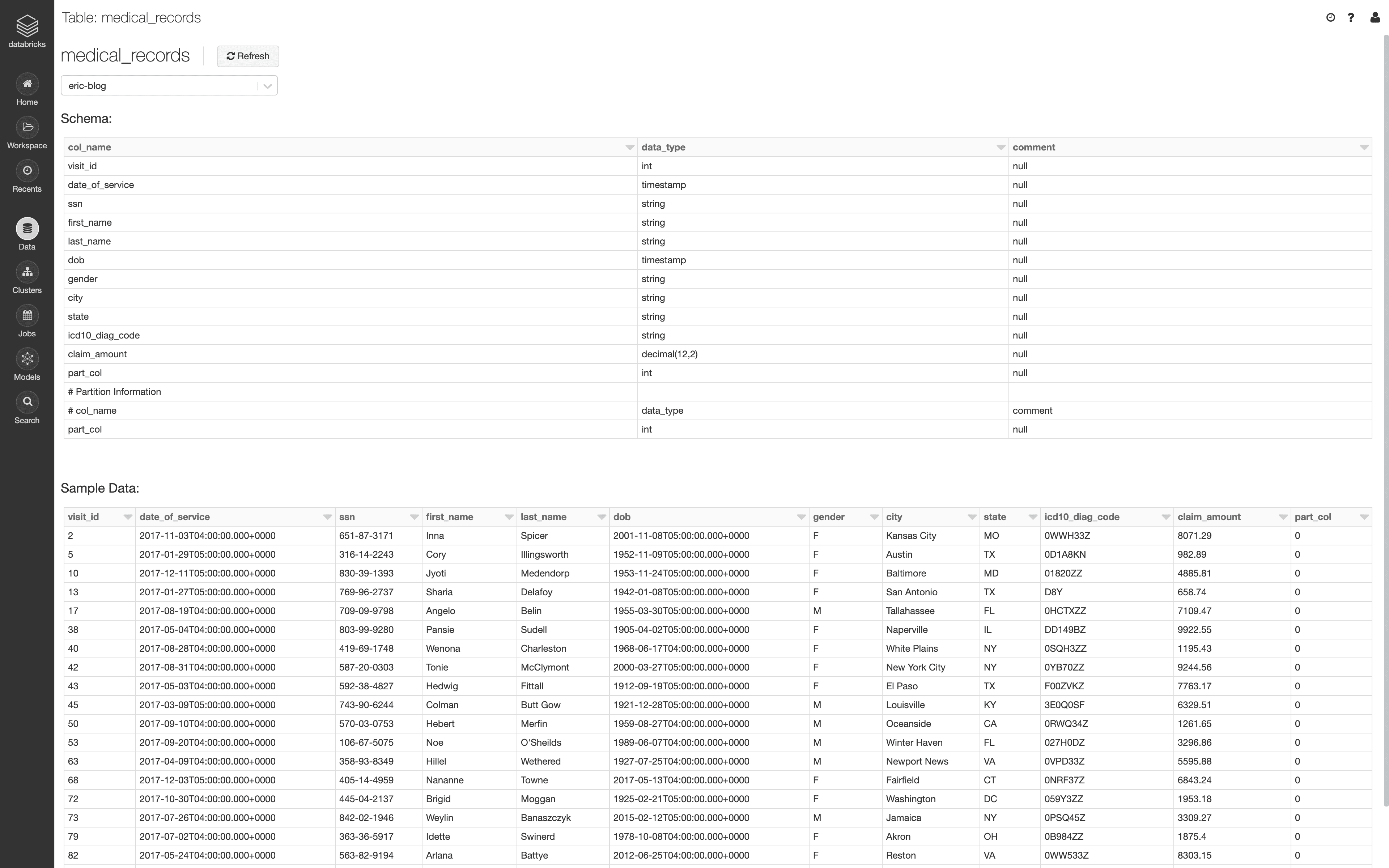
In this example, we will be exploring a sample data set called medical_records, which contains several forms of PHI. We will explore how data in the data set can be masked (column-level controls), as well as completely redacted (row-level controls).
We will then update the policies to allow access to sensitive data under specific conditions related to a user’s attributes in Immuta, as well as their purpose for accessing the data. This will enable us to expose data at the cell-level for users who need it, without exposing the entire data set.
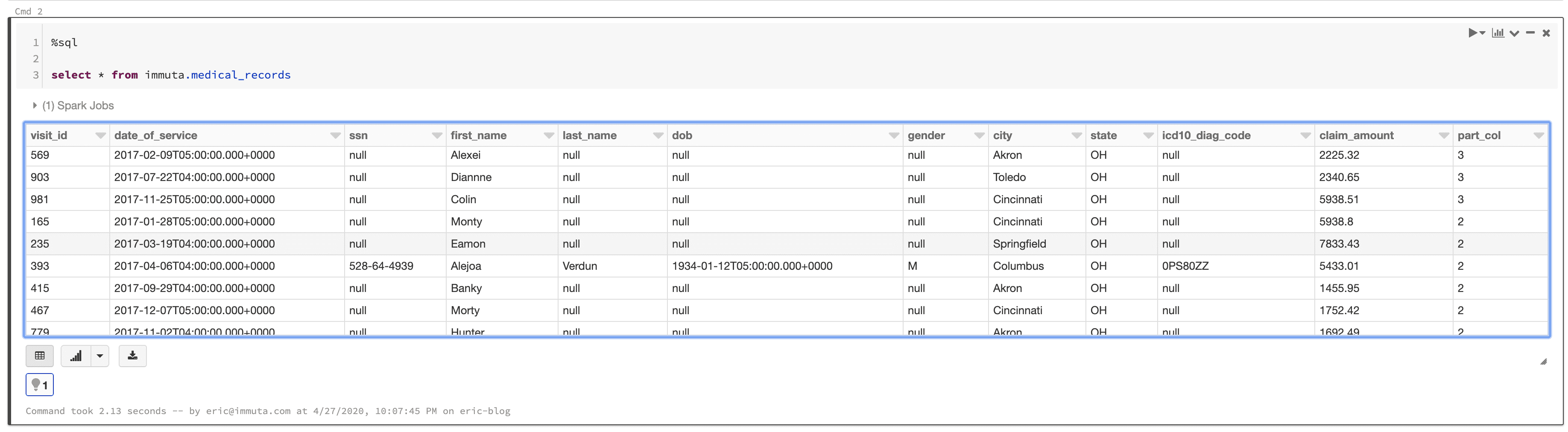
The following is a sample from the [medical_records] table:
Expose the Databricks Table as an Immuta Data Source
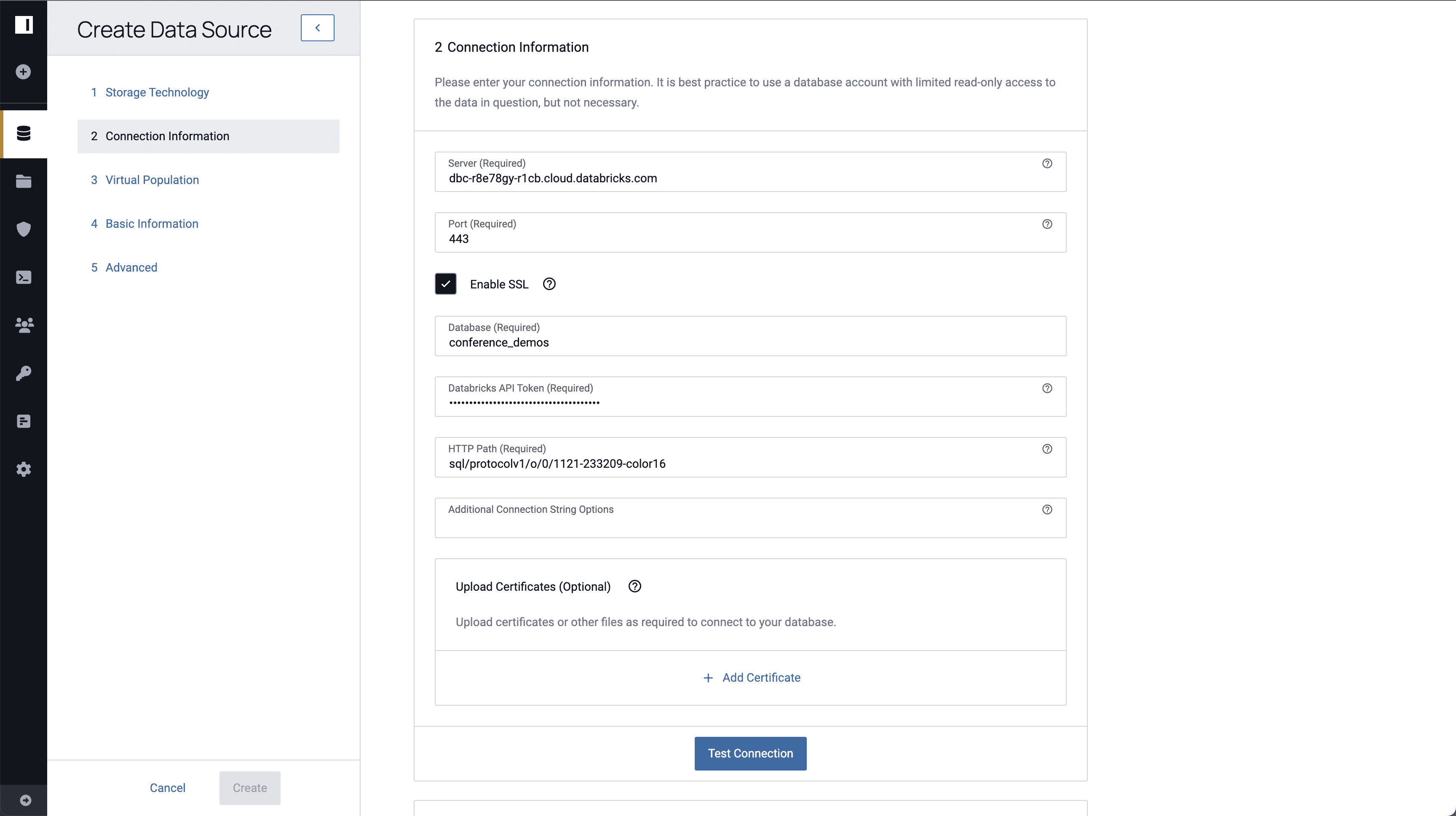
After configuring the Immuta artifacts in Databricks, click the data sources icon on the left hand side of the Immuta console and click + New Data Source. Select Databricks as the storage technology to create a new Databricks connection. Enter connection information and specify the [medical_records] table. For the purposes of this blog, a single table is being selected to create a data source, but Immuta supports importing an entire database to bulk-create Immuta data sources.
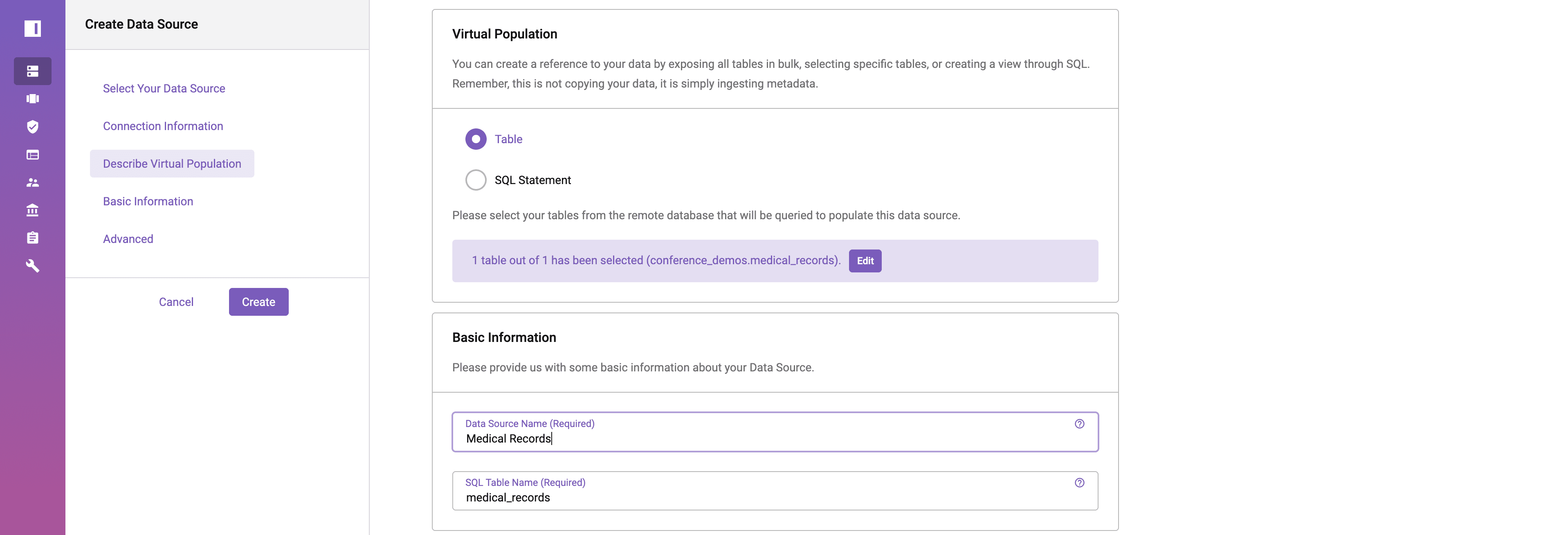
Once the table has been selected, specify a name for the data source in Immuta and press “Create.”
For a more detailed breakdown of the data source creation process, please refer to the data source creation documentation.
Create an Attribute-Based Databricks Row-Level Security Data Policy
In this scenario, it is important that medical records are only visible to those who reside in the same city as the patient. For this reason, a policy must be created that forbids access to any users who live outside of the city and state present in each row of the table. There is a special exception to this rule, where users acting in the Billing Job Function can access all records in their state.
In Immuta’s policy builder, the row-level policy can be represented in plain language. This policy will use attributes from user accounts to restrict data returned based on the comparison between those user attributes and the city and state columns from the data source. We will also make a special exception for the Billing Job Function to only filter on state.
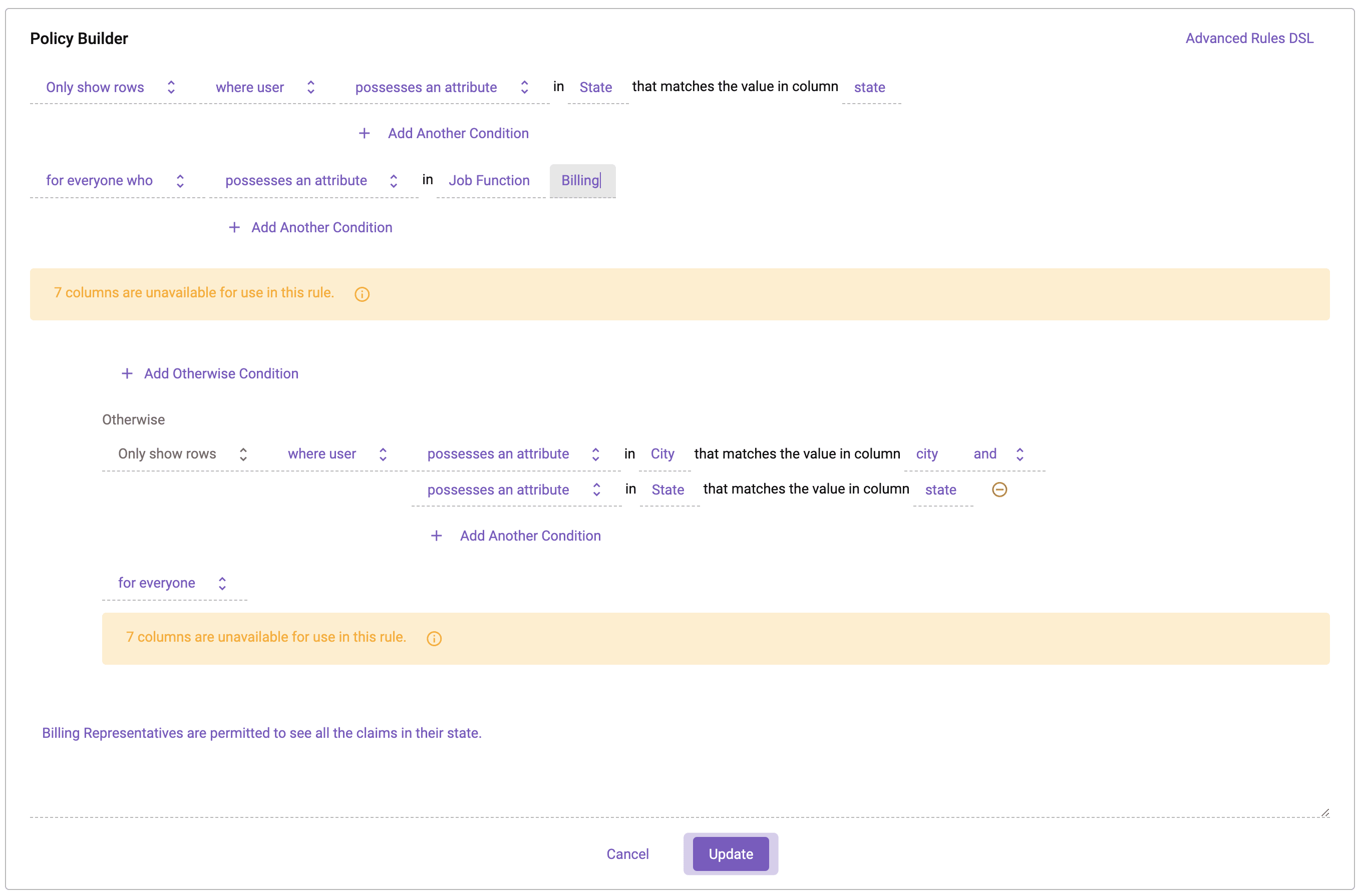
In this policy, the Job Function “Billing” is outlined first as a portion of the policy that only restricts based on the State attribute. In the builder, under the Otherwise clause, a policy is outlined that affects all users that DO NOT have the Billing Job Function attribute. This means that all other users in the system will have access to their specific city.
For good measure, since there is plenty of other sensitive information in this data set, a policy was added to null out the [dob], [gender], [ssn], [last_name], and [icd10_diag_code] columns for all users.
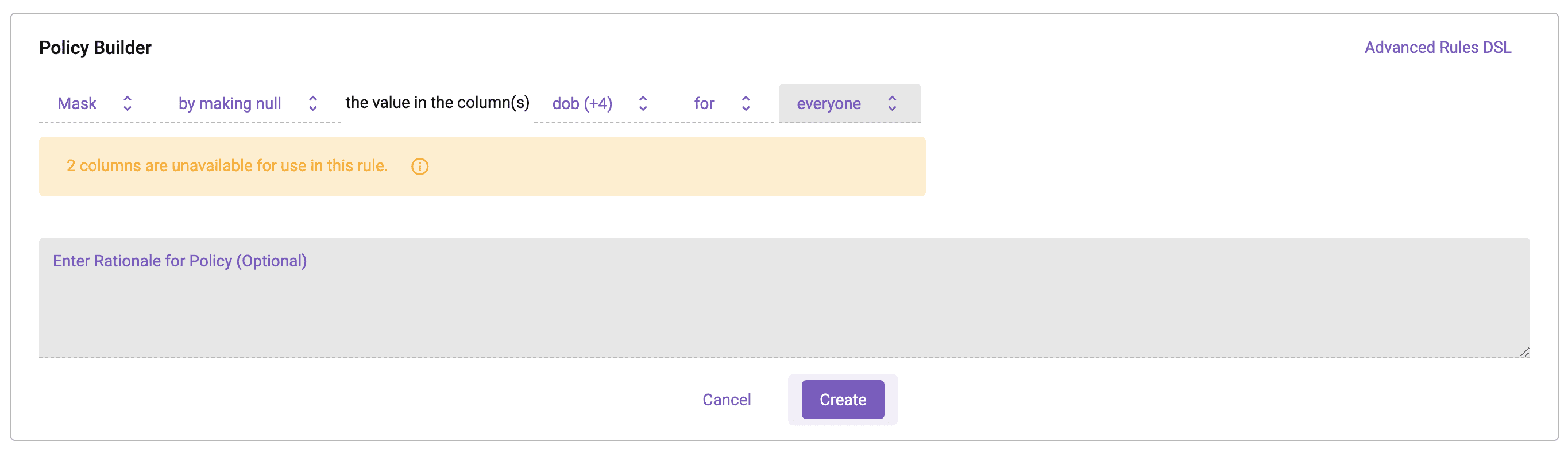
In the following Databricks notebook, the logged-in user is an Immuta user with the Billing Job Function who resides in Ohio. When querying the data set, they see all records from Ohio. Notice also that the sensitive columns have been nulled.
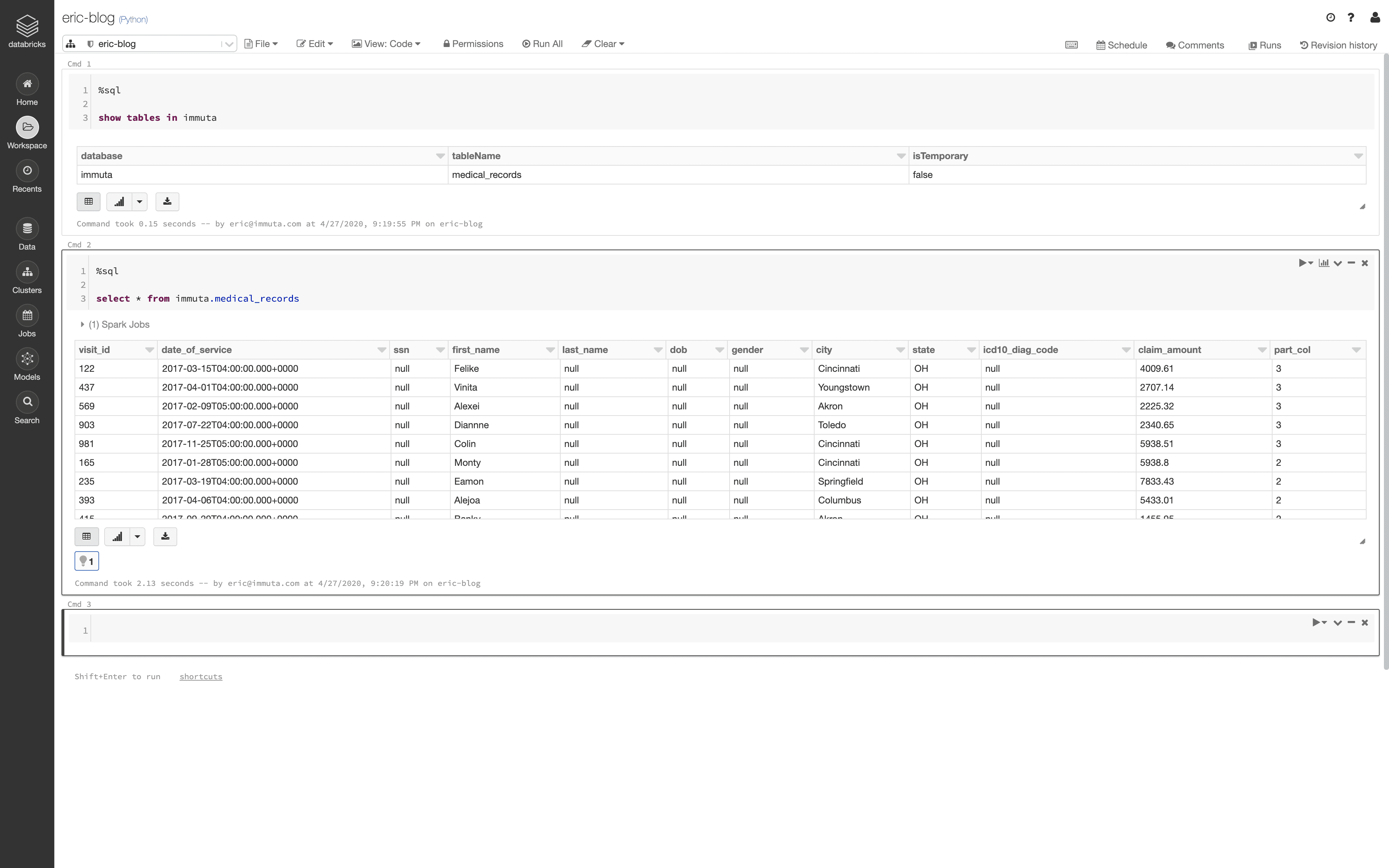
As a user without the Billing Job Function who resides in Las Vegas, Nevada, the query returns the following information:
Use a Purpose-Based Policy for Context Awareness
Let’s assume the situation has now evolved, and there are users in the organization who must be able to see a portion of the PHI from the data set in specific cases. The team performing Fraud Prevention must be allowed to see data from across the country, but they can only see it after agreeing to the Fraud Prevention data usage policy.
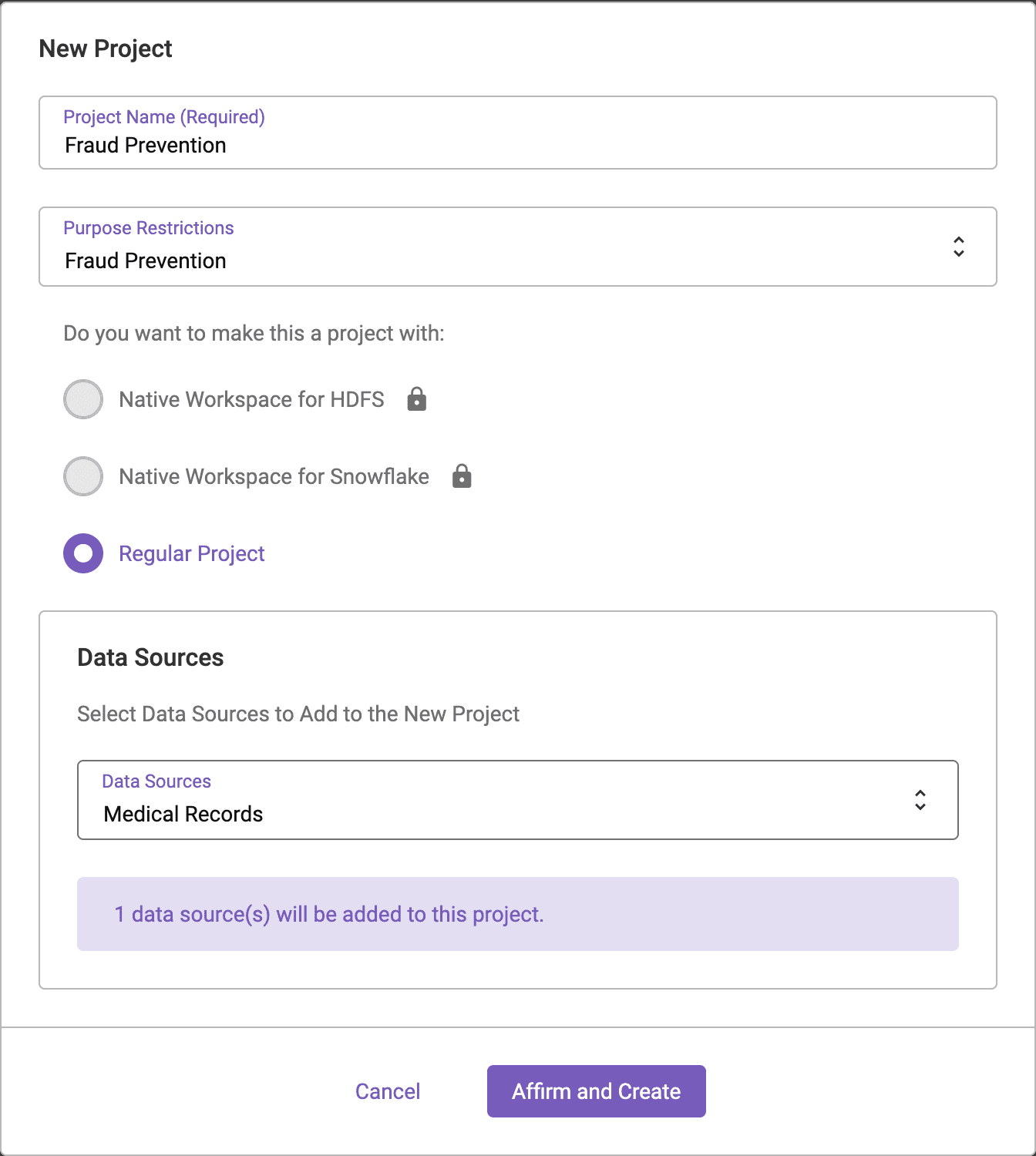
This can be accomplished in Immuta by creating a Project and associating the Fraud Prevention Purpose to the Project. Click the Projects button on the left hand side of the screen and click the + button to create a New Project. When creating the project, associate the Fraud Prevention Purpose to the Project. The Fraud Prevention Purpose must be created by a user with the GOVERNANCE permission in Immuta before it can be associated with a Project.
Once this project has been created, the row-level policy in our data source can be updated to include an exception for users acting under the Fraud Prevention purpose.
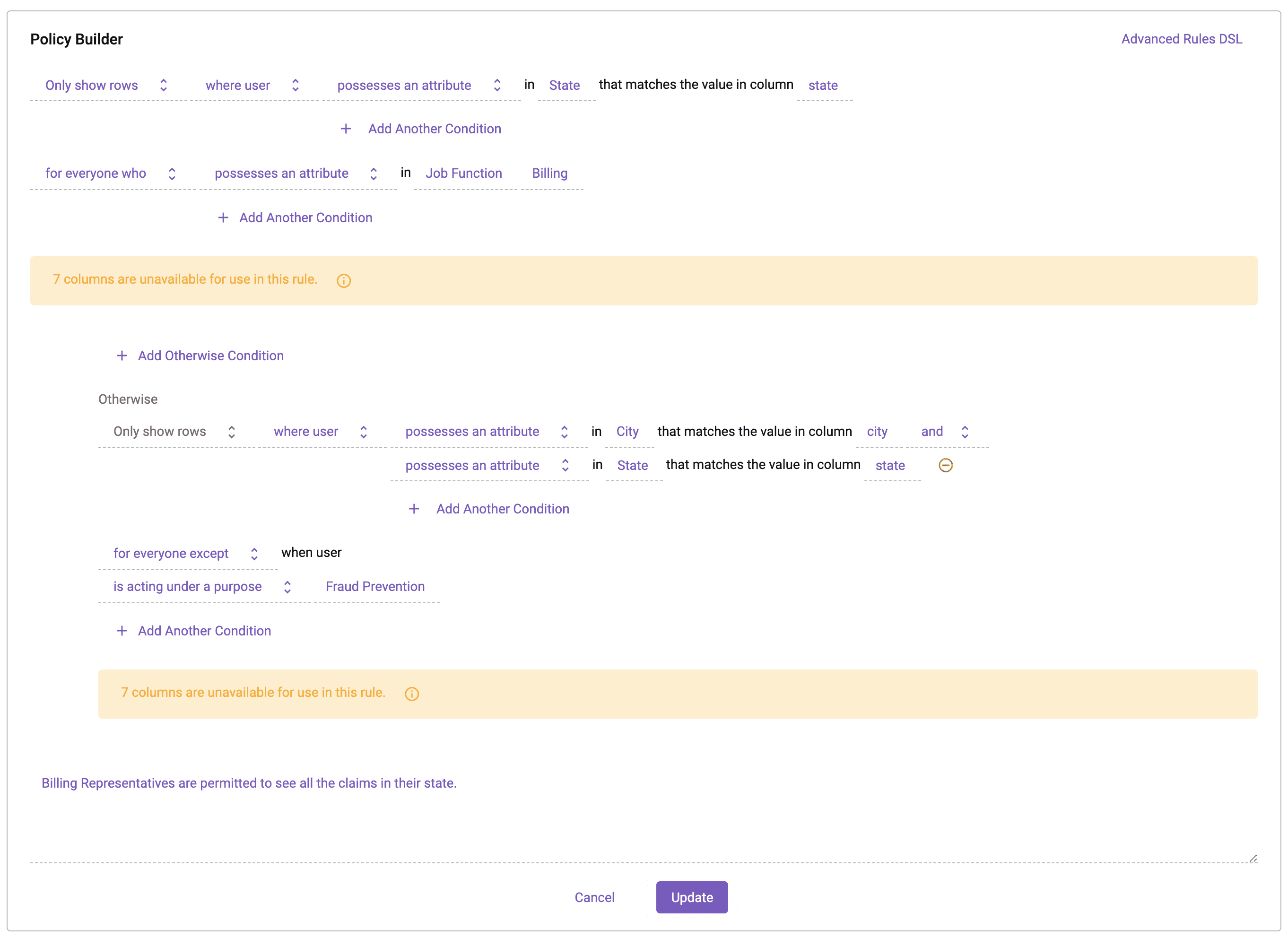
Notice the language has changed in the Otherwise clause from “for everyone” to “for everyone except when user is acting under a Purpose Fraud Prevention”. This now excludes users in the Fraud Prevention project from this policy.
The user from Las Vegas, Nevada has been added to the Fraud Prevention team, and upon accessing the project is presented with the following prompt:
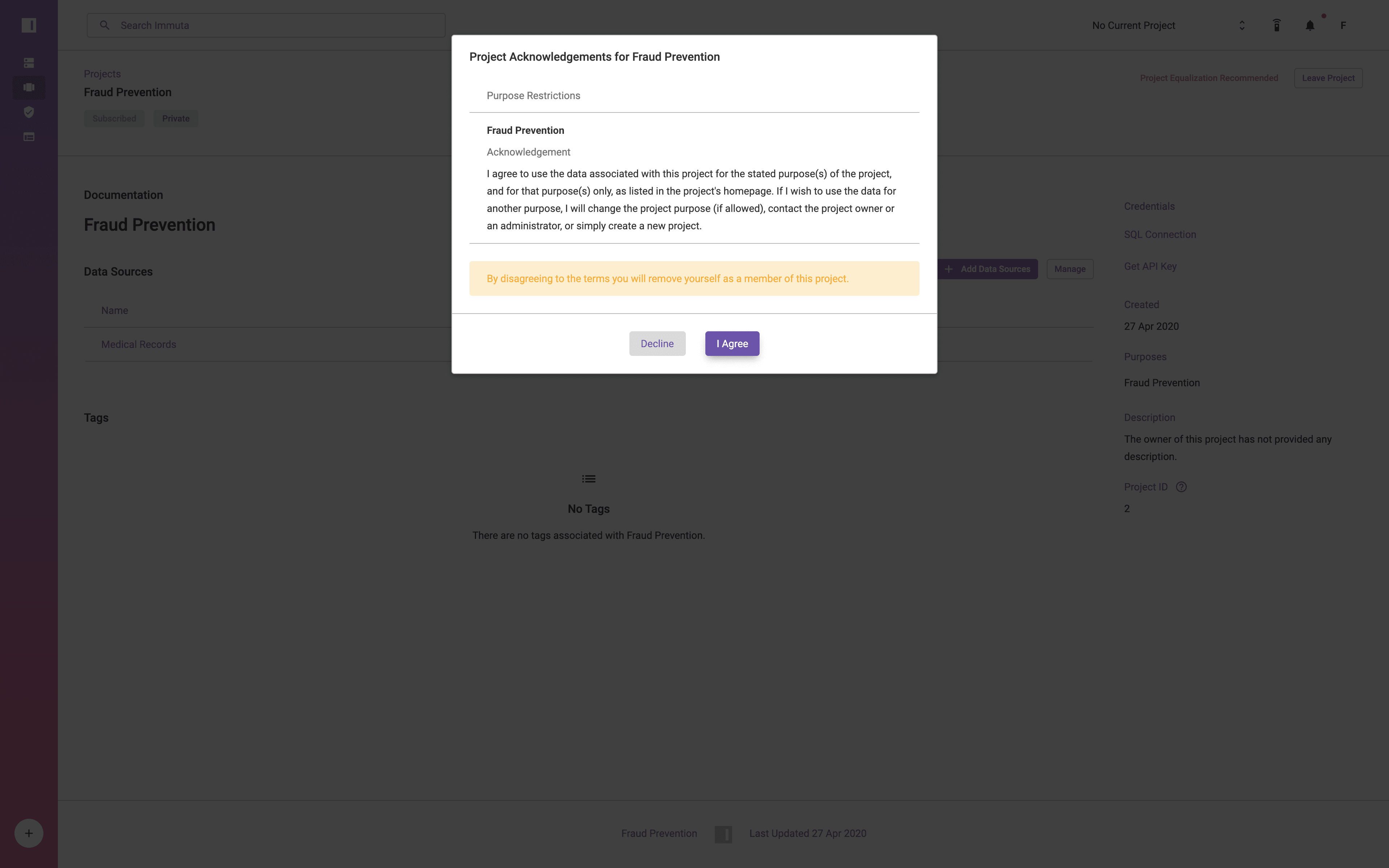
Once accepted, the user can set their Current Project to Fraud Prevention in the Project selector on the upper right hand side of the screen. When their project has been set, they are acting under the Fraud Prevention purpose and can see the following result set in Databricks:
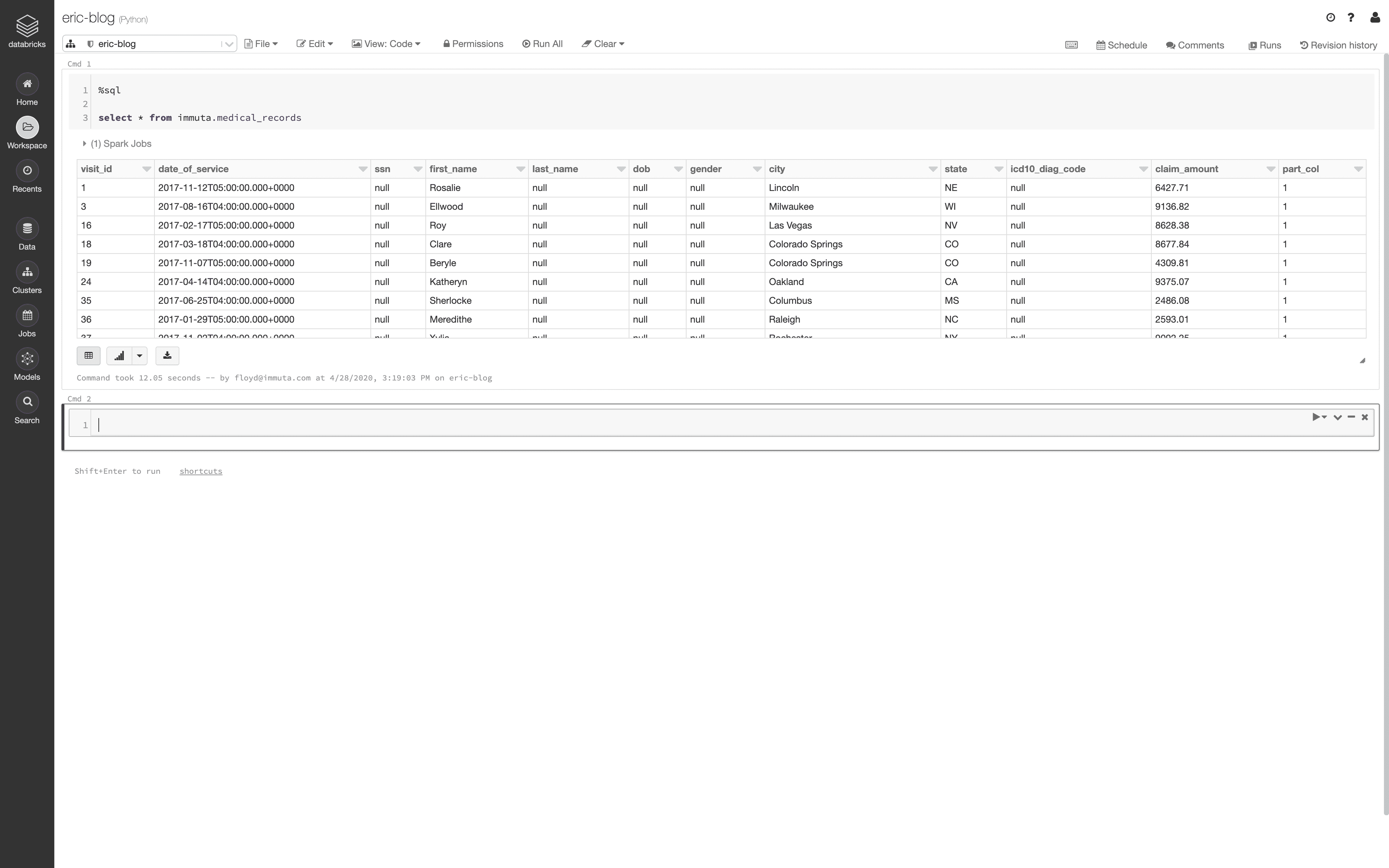
Notice that the same user now has access to data beyond Las Vegas, Nevada.
Use a WHERE Clause to Create a Cell-Level Policy with User Attributes
The situation has changed again, and policies now permit users in the Billing Job Function to see the sensitive information for claimants in their city. This means that data does not need to be masked when both the City and State from the data match a user’s attributes.
In Immuta, this policy can be implemented by adding a condition to the existing dynamic data masking policy.
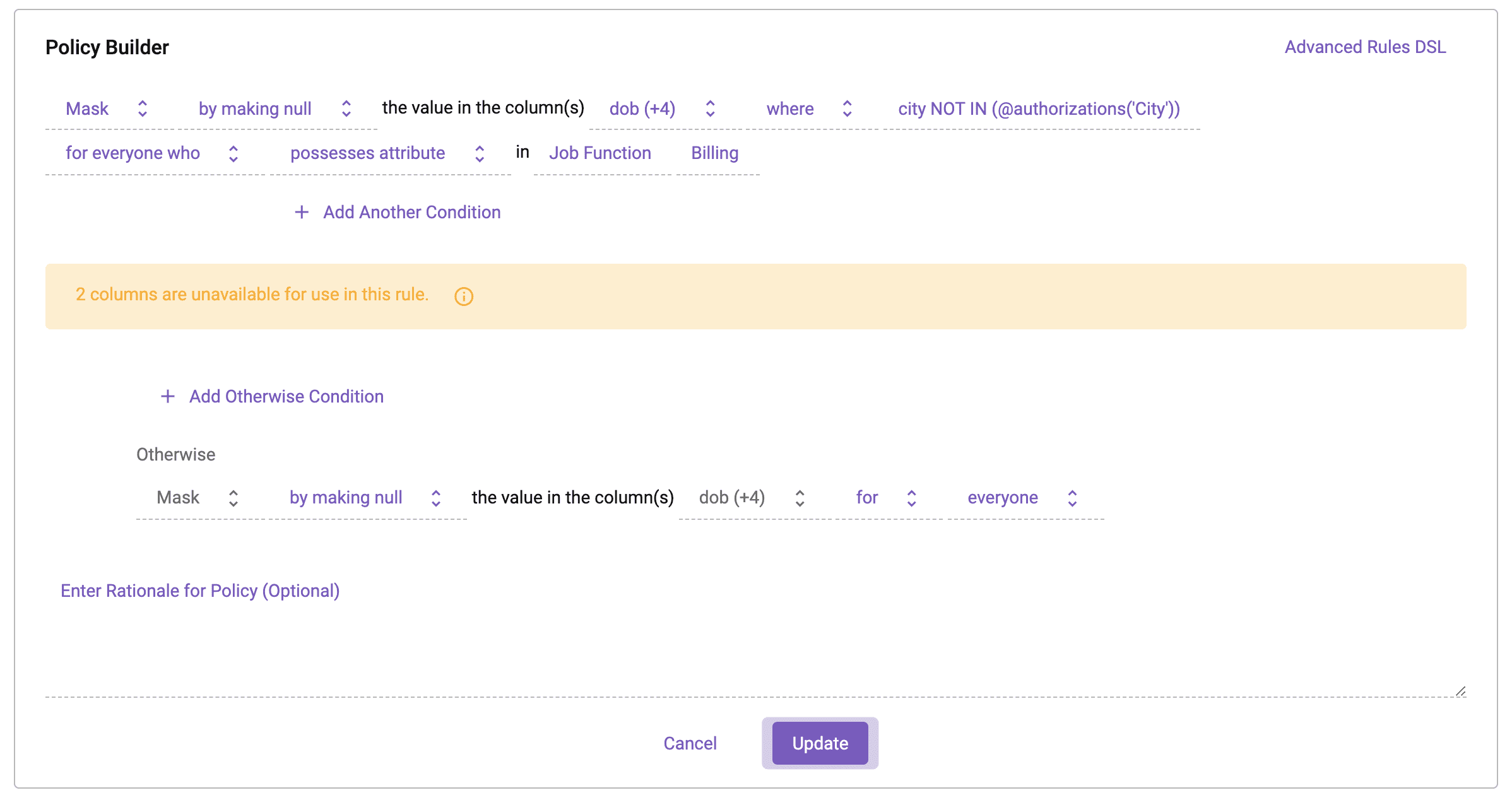
You’ll notice that the policy language now states that the columns are masked to null when the [city] column does not match the user’s City authorization. This applies to users who have the Billing Job Function attribute. For everyone else, the columns are masked at all times.
When querying the data now we see the following in Databricks:
Auditing User Access
Each query executed in Databricks against an Immuta data source is audited. The audit logs show not only the user that executed the query, but also the purpose under which the user was acting. Notice that the user acting under the Fraud Prevention project has been tagged as executing queries with that purpose.
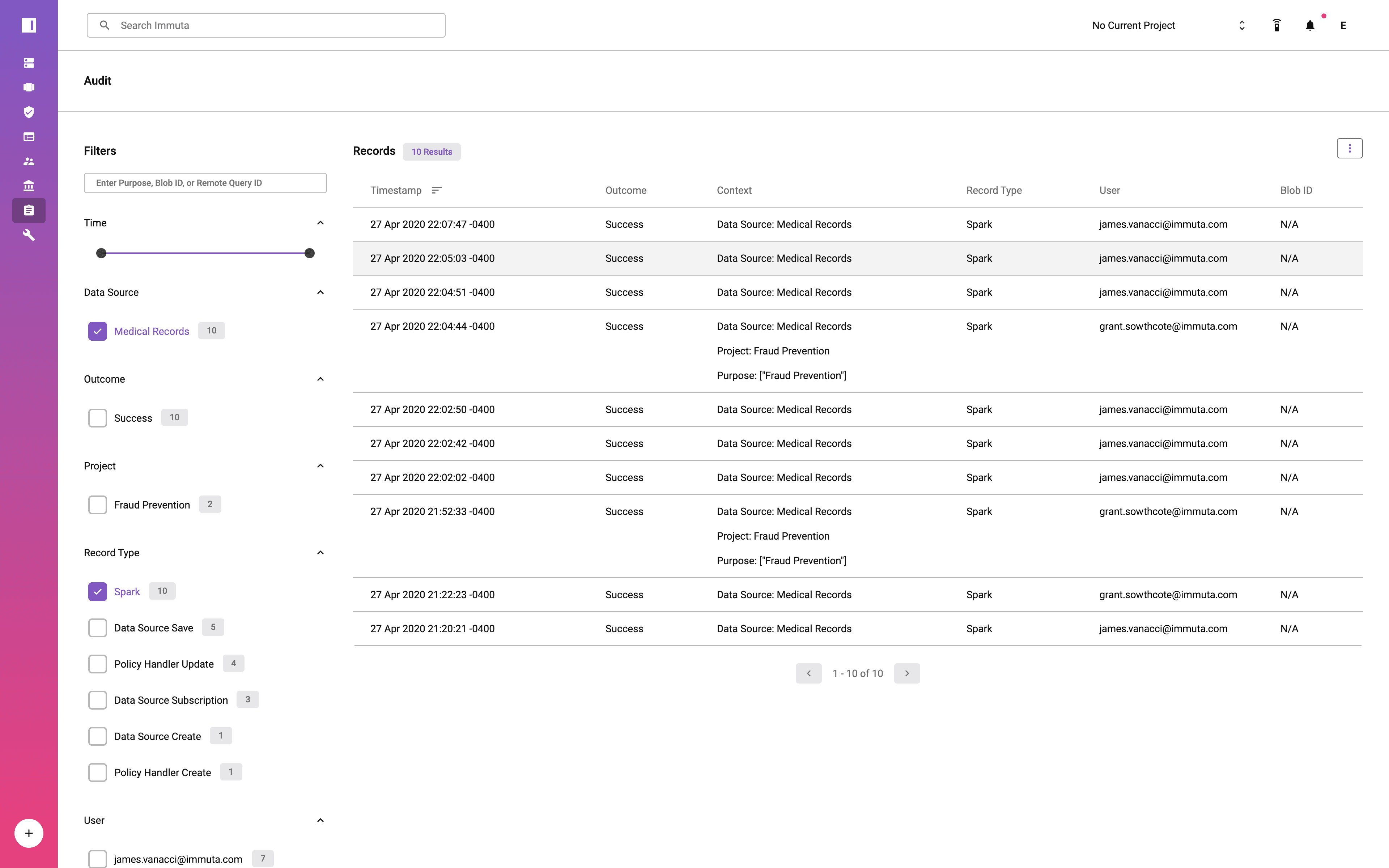
Immuta’s audit logs are viewable via the Audit page and are also saved in a parseable format on disk that can be shipped to a central auditing and monitoring system.
Additional Resources
This solution was developed by our expert teams of software engineers, legal engineers, and statisticians in order to streamline data security for Databricks users. In addition to dynamic data masking, row-level security, and column-level security, Immuta automates a number of other advanced policies to comply with the regulatory and compliance needs of any organization.
As mentioned previously, Databricks row-level security, column-level security, and cell-level access controls can be achieved with static data and maintained using a combination of ETL pipelines and metadata management. In the ever-changing landscape of compliance laws and regulations, it is important for organizations to be able to react rapidly and cost-effectively, which is why Immuta’s dynamic policy building and enforcement was created.
If you find value in this approach, you can request a demo with our team.