
Enterprise organizations often use an array of products to store, manage, and analyze their data. These can exist within a single cloud provider’s ecosystem, or across multiple. But when organizations add more products with different functionalities to their data stacks, it becomes increasingly difficult to manage data access controls.
Data teams are then faced with the question of how to implement a scalable data governance solution – one that allows users appropriate access to the data they need – while still maintaining a secure environment.
For the many organizations that leverage Amazon EMR Spark to analyze data stored in Amazon S3, achieving consistent, manageable, and secure data access across both tools is key. In this blog, we’ll look at how Immuta’s integration with S3 Access Grants allows users to de-risk their AWS data while unlocking advanced analytics.
An Immuta + AWS Data Governance Primer
Amazon S3 is the most popular object storage platform in modern data stacks. By extension, EMR Spark is an integral platform that allows users to perform analyses with the troves of data stored in S3. But, when teams use EMR Spark to analyze data, their access levels must be aligned with the organization’s broader security frameworks. This means that data access across Amazon S3 and EMR Spark must be consistent and easy to manage.
Through a series of native integrations, Immuta enforces policies across multiple security models, including AWS-native services such as Amazon EMR Spark. Users leverage Immuta’s Amazon S3 integration to create access grants that enforce policies in EMR Spark. This provides policy enforcement consistency across S3 and EMR Spark, without additional overhead or manual effort required from data engineering or governance teams.
How Immuta Works with S3 Access Grants
In Q1 2024, Immuta launched a native integration with Amazon S3, which allows users to leverage S3 Access Grants to orchestrate policies across different platforms within the AWS ecosystem. An overview of this workflow is outlined below.
[Read More] The Amazon S3 Security & Access Handbook
1. When an organization is storing data in S3, a user responsible for policy orchestration configures the Amazon S3 integration in Immuta.
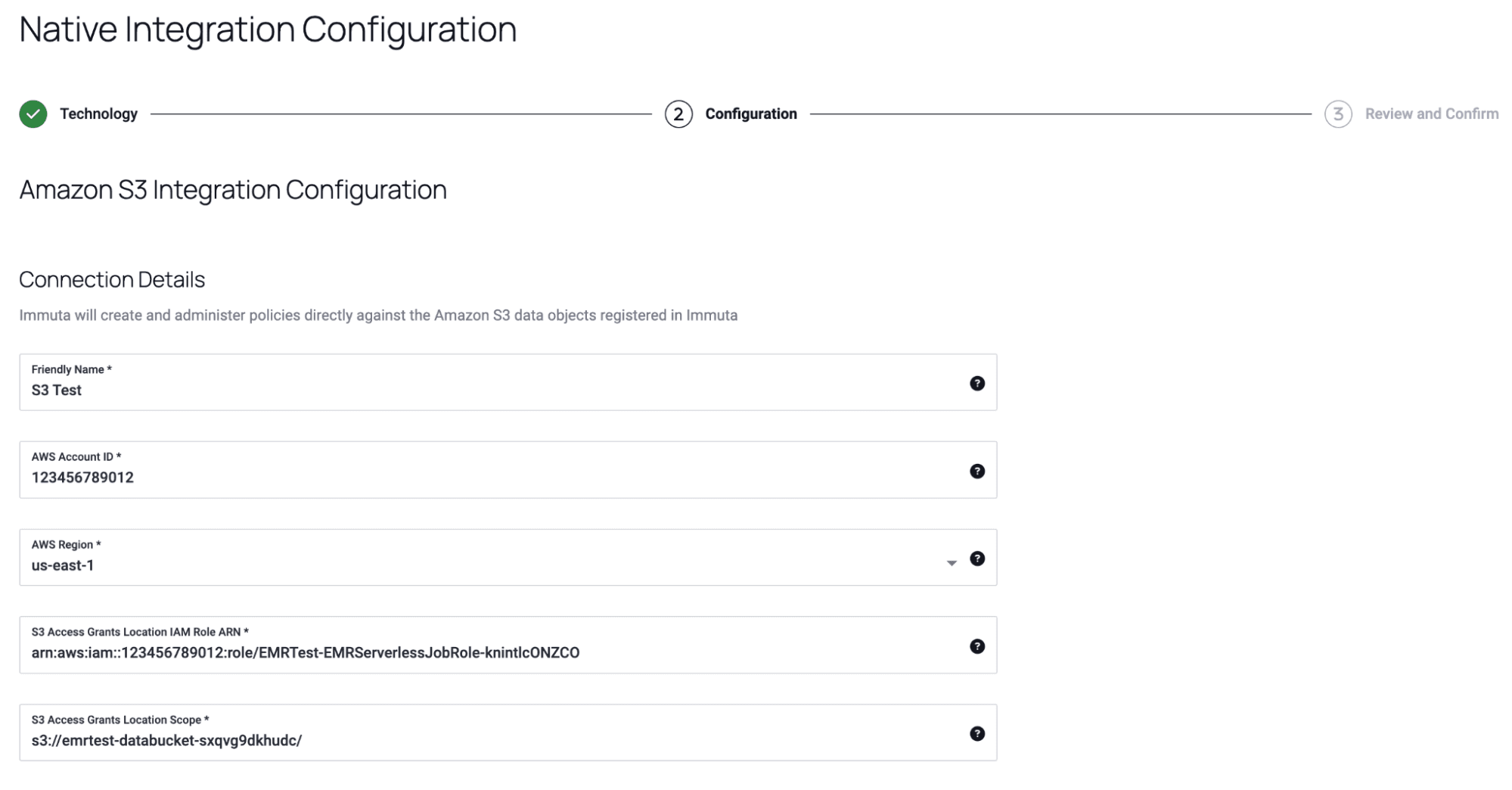
2. Once the integration is configured, the user adds the appropriate S3 data as data sources in Immuta.
3. On these data sources, the user adds any applicable tags. Note that these are Immuta tags, not tags that are carried over from S3.
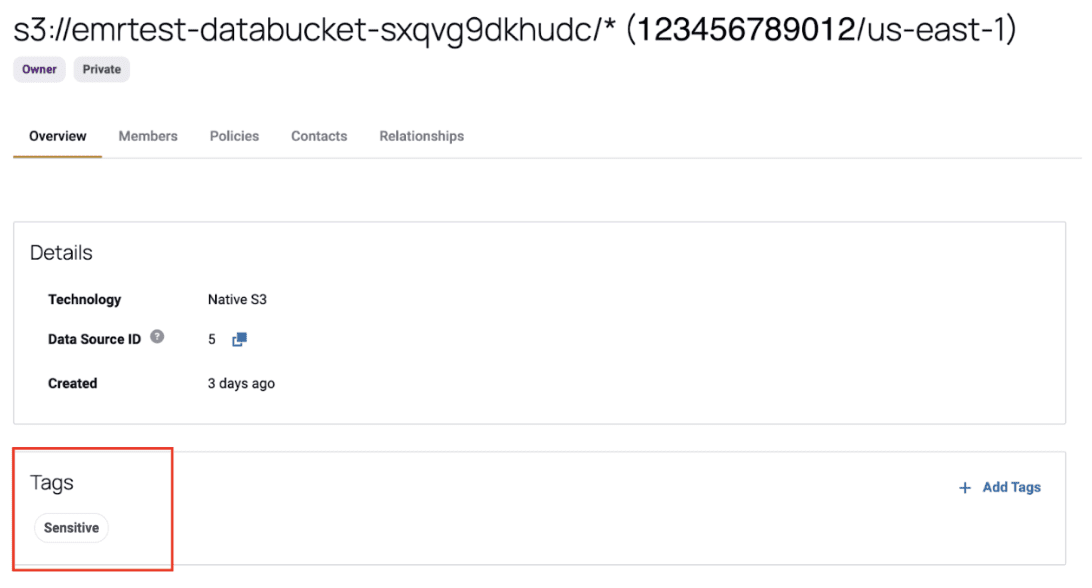
4. Then, the user implements a policy in Immuta.
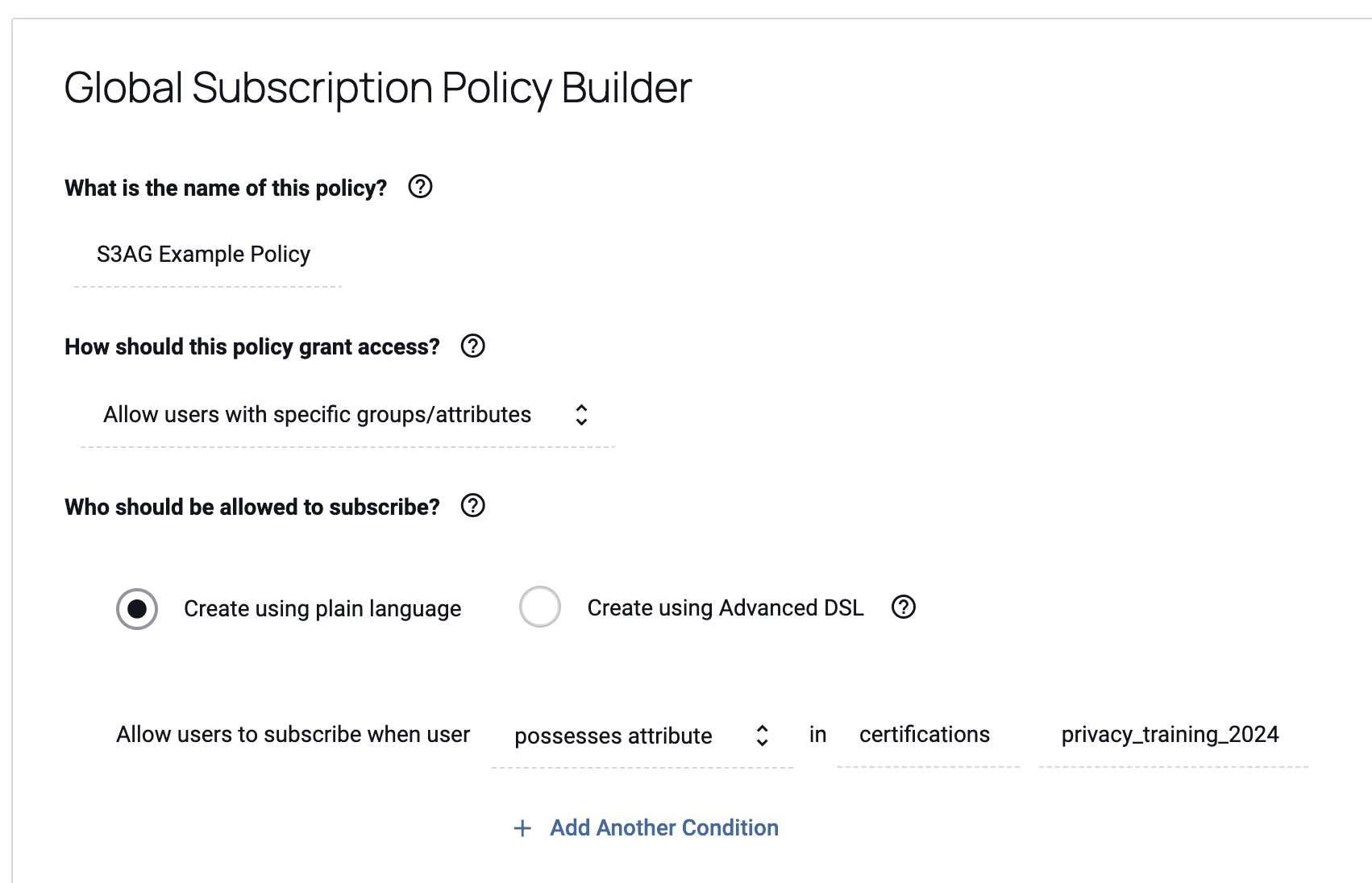
When the user implements a policy, Immuta creates an access grant through S3 Access Grants. This access grant gives the appropriate users access to the S3 data.
How S3 Access Grants Works with EMR Spark
EMR Spark analyzes data that is stored in S3, so it’s important to ensure the same access control policies are enforced across both platforms. Users can enable S3 Access Grants within their EMR instance, which allows EMR Spark to enforce the Immuta policies set in S3 Access Grants.
To configure Amazon EMR Spark to leverage S3 Access Grants, follow the steps below that are applicable to the EMR instance type you currently have, or would like to configure.
EMR Serverless
1. Set up a job execution role for your EMR Serverless application. Include the IAM permissions that you will need to run Spark jobs.
a. Note that if you specify IAM roles for job execution that have additional permissions to access S3 directly, then users will be able to access the data permitted by the role, even if they don’t have permission from S3 Access Grants.
{
"Effect": "Allow",
"Action": [
"s3:GetDataAccess",
"s3:GetAccessGrantsInstanceForPrefix"
],
"Resource": [ //LIST ALL INSTANCE ARNS THAT THE ROLE IS ALLOWED TO QUERY
"arn:aws_partition:s3:Region:account-id1:access-grants/default",
"arn:aws_partition:s3:Region:account-id2:access-grants/default"
]
}2. Launch your EMR Serverless application. This must have a release label of 6.15.0 or higher, as well as the spark-defaults classification.
aws emr-serverless start-job-run \
--application-id application-id \
--execution-role-arn job-role-arn \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://us-east-1.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py",
"entryPointArguments": ["s3://DOC-EXAMPLE-BUCKET-OUTPUT/wordcount_output"],
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}' \
--configuration-overrides '{
"applicationConfiguration": [{
"classification": "spark-defaults",
"properties": {
"spark.hadoop.fs.s3.s3AccessGrants.enabled": "true",
"spark.hadoop.fs.s3.s3AccessGrants.fallbackToIAM": "false"
}
}]
}'EMR on EKS
1. Set up a job execution role for your EMR on EKS cluster. Include the IAM permissions that you will need to run Spark jobs.
a. Note that if you specify IAM roles for job execution that have additional permissions to access S3 directly, then users will be able to access the data permitted by the role, even if they don’t have permission from S3 Access Grants.
{
"Effect": "Allow",
"Action": [
"s3:GetDataAccess",
"s3:GetAccessGrantsInstanceForPrefix"
],
"Resource": [ //LIST ALL INSTANCE ARNS THAT THE ROLE IS ALLOWED TO QUERY
"arn:aws_partition:s3:Region:account-id1:access-grants/default",
"arn:aws_partition:s3:Region:account-id2:access-grants/default"
]
}2. Submit a job to your Amazon EMR on EKS cluster. This must have a release label of 6.15.0 or higher, as well as the emrfs-site classification.
{
"name": "myjob",
"virtualClusterId": "123456",
"executionRoleArn": "iam_role_name_for_job_execution",
"releaseLabel": "emr-7.0.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "entryPoint_location",
"entryPointArguments": ["argument1", "argument2"],
"sparkSubmitParameters": "--class main_class"
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "emrfs-site",
"properties": {
"fs.s3.s3AccessGrants.enabled": "true",
"fs.s3.s3AccessGrants.fallbackToIAM": "false"
}
}
],
}
}EMR on EC2
1. Set up a job execution role for your EMR on EC2. Include the IAM permissions that you will need to run Spark jobs.
a. Note that if you specify IAM roles for job execution that have additional permissions to access S3 directly, then users will be able to access the data permitted by the role, even if they don’t have permission from S3 Access Grants.
{
"Effect": "Allow",
"Action": [
"s3:GetDataAccess",
"s3:GetAccessGrantsInstanceForPrefix"
],
"Resource": [ //LIST ALL INSTANCE ARNS THAT THE ROLE IS ALLOWED TO QUERY
"arn:aws_partition:s3:Region:account-id1:access-grants/default",
"arn:aws_partition:s3:Region:account-id2:access-grants/default"
]
}2. Use the AWS CLI to launch a cluster. This must have AWS EMR 6.15.0 or higher, and the emrfs-site classification.
aws emr create-cluster
--release-label emr-6.15.0 \
--instance-count 3 \
--instance-type m5.xlarge \
--configurations '[{"Classification":"emrfs-site", "Properties":{"fs.s3.s3AccessGrants.enabled":"true", "fs.s3.s3AccessGrants.fallbackToIAM":"false"}}]'Additional considerations for using Amazon EMR with S3 Access Grants can be found here.
How Immuta Protects EMR Spark Through S3 Access Grants
Here, we piece together how Immuta protects EMR Spark with table-level security through our S3 integration. Building off of the example above:
- An Immuta policy has been configured to manage access controls on S3 data, and it has been deployed and enforced through S3 Access Grants.
- Your EMR instance has been configured to leverage S3 Access Grants.
With the following two conditions being true, a policy set in Immuta can now be applied from Immuta to S3, then S3 to EMR Spark. This means that when a user is trying to access data through EMR Spark, they can run a Spark job that requests credentials to access S3 data. If a user has access to the requested data (which is dictated by the Immuta policy), then the Spark job will return temporary credentials for that user, scoped to the specific S3 location in which the data is stored.
The exact process to read S3 data through EMR Spark will vary depending on how your EMR application is configured (i.e. running on EC2, an EKS cluster, or serverless). Instructions for each of these configurations are outlined in the AWS blog and demo here.
Immuta’s Impact
This solution gives governance teams a streamlined method of managing access controls across the AWS ecosystem. In this scenario, governance teams are able to confidently implement a single policy in Immuta knowing it will apply to data in S3, regardless of how users try to access it (either directly through S3, or through EMR Spark).
At the same time, end users still maintain autonomy as to how they are accessing this data. They are able to use EMR Spark to retrieve credentials and perform analyses, rather than needing to go through their governance teams for access, which delays speed to access and insights.
Immuta’s integrations provide a centralized governance control plane, streamlining the policy orchestration process and securing data across your organization’s ecosystem. By de-risking data in S3 and EMR Spark, Immuta gives you the freedom to analyze, innovate, share, and deliver more value from your AWS data.