Organizations are increasingly adopting data lakehouse architectures to reap the benefits of added flexibility, scalability, and cost-efficiency that they provide. But the need to consistently implement data access control across this open architecture approach can be elusive. Here, we’ll look step-by-step at how Immuta provides centralized, fine-grained access control across different cloud data platforms in a lakehouse architecture.
In this scenario, we’ll look to consistently segment HR data by state for all tables across an AWS data architecture with Redshift and Databricks, so that we can comply with internal data use rules. This is an example of segmenting data across platforms for multi-tenancy, in which each state is a tenant. In practice, we will aim to ensure that when users run the query below, they will only be able to see data from their own state.
Step 1: Discover and Tag Data
After registering a data source from Redshift or Databricks, we’ll first want to discover and tag the data to identify any sensitive attributes or categories, including state. This can be done by leveraging metadata from other sources, like an existing data catalog or other type of software in the data stack, and Immuta’s sensitive data discovery.
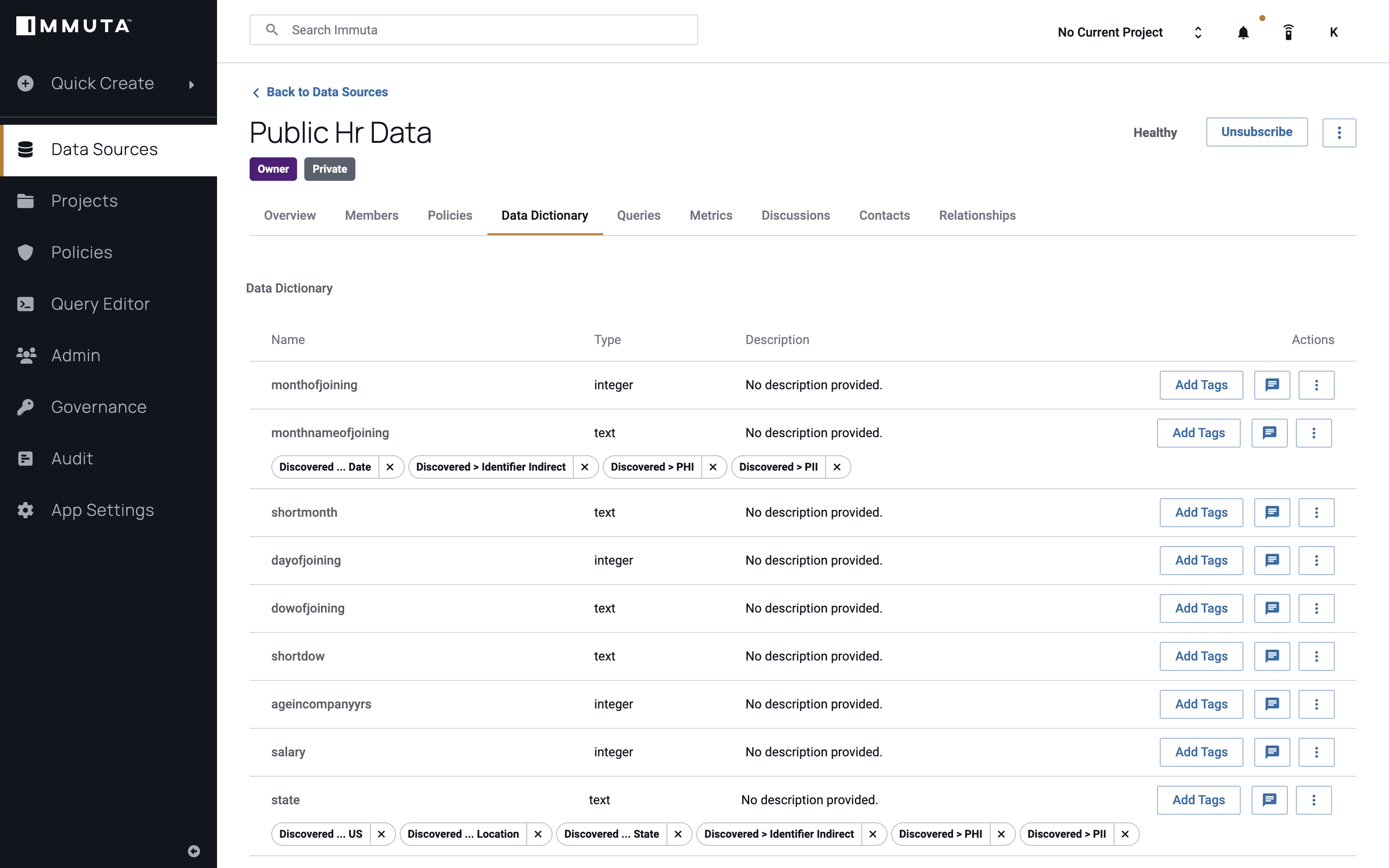
We’ll also look at the user instance to gain an understanding of what permissions they have, and thus what data they should be allowed to see. The user below has a state attribute that equals Massachusetts, which is hard coded in Immuta for this example scenario, but is typically pulled dynamically from any other system to make a policy decision.
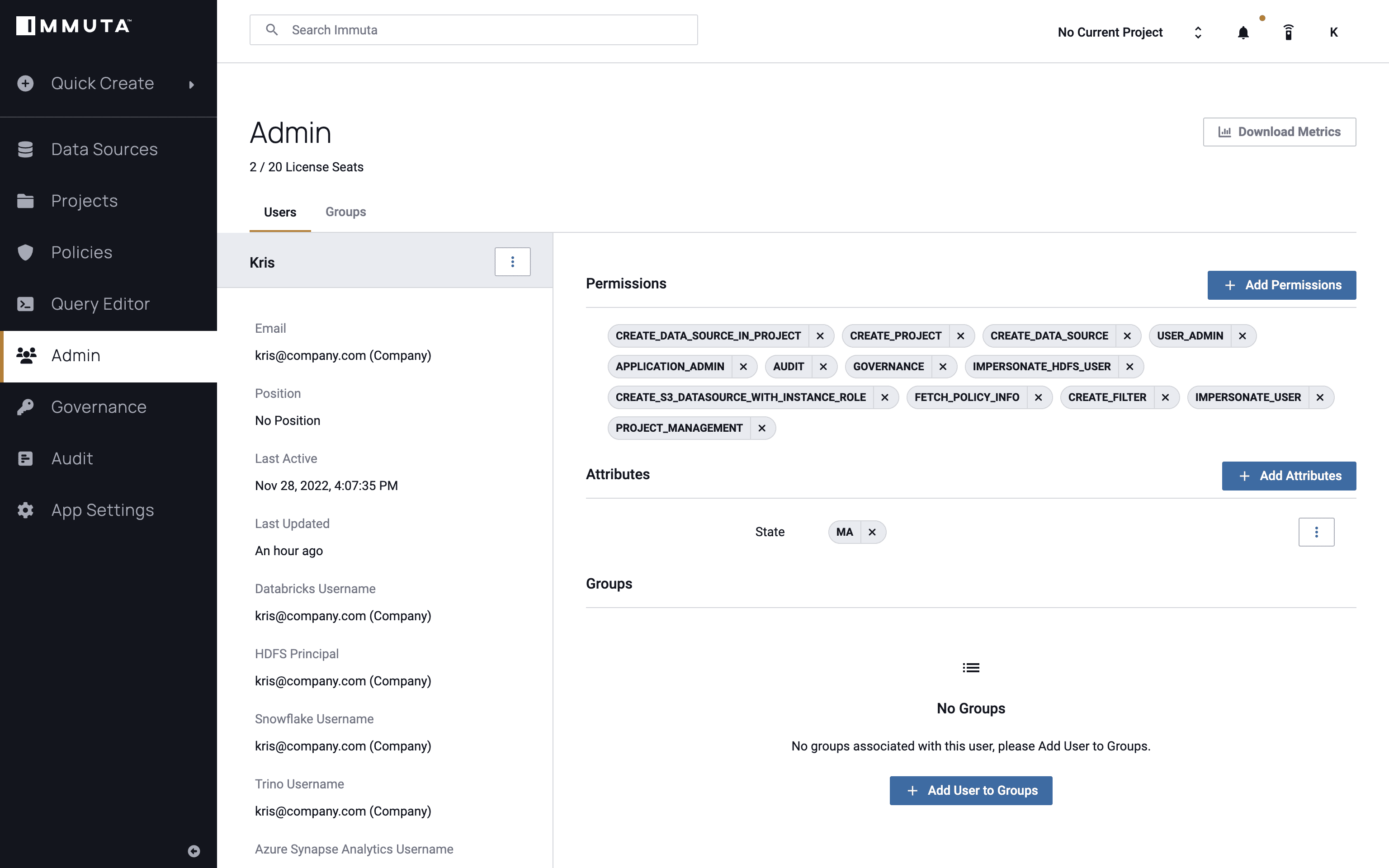
Immuta’s attribute-based access control (ABAC) approach allows policy decisions to be made at query time, so that the right data is available to the right people at the right time. The ABAC model enables scalability without causing role explosion – research from GigaOm found that Immuta reduced policy burden by 93x when tested head-to-head against role-based approaches.
2. Create a Global Policy
Next, we will create a global policy using the state attribute mentioned above to help ensure that users only see their own state’s data. We’ll call the policy “Row-Level Segmentation by State,” and we want to only show the rows where the user possesses that attribute of “State.” As previously mentioned, each state is considered a tenant in this scenario.
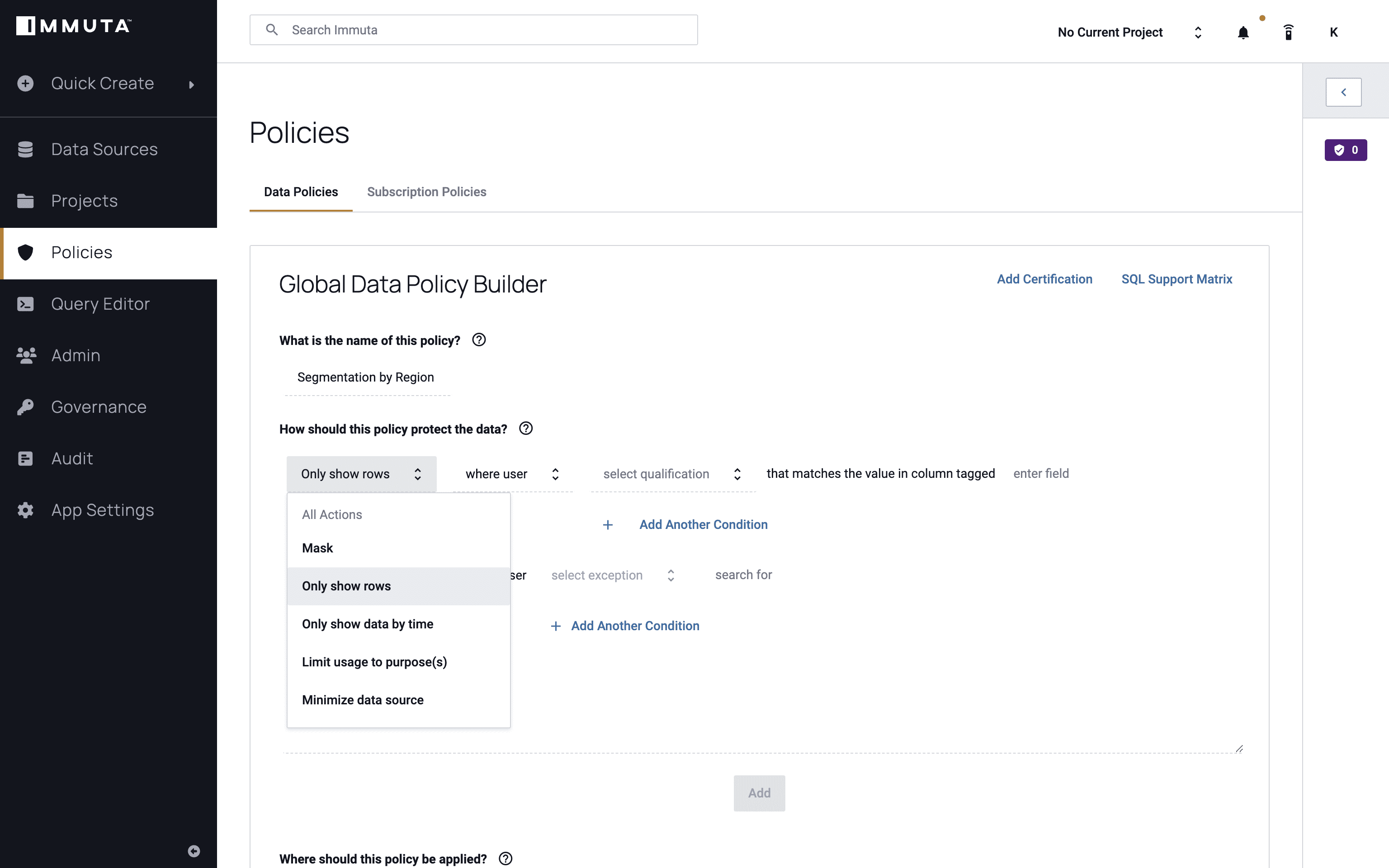
Finally, we’ll apply this policy to everyone and click “Add,” then “Create Policy.”
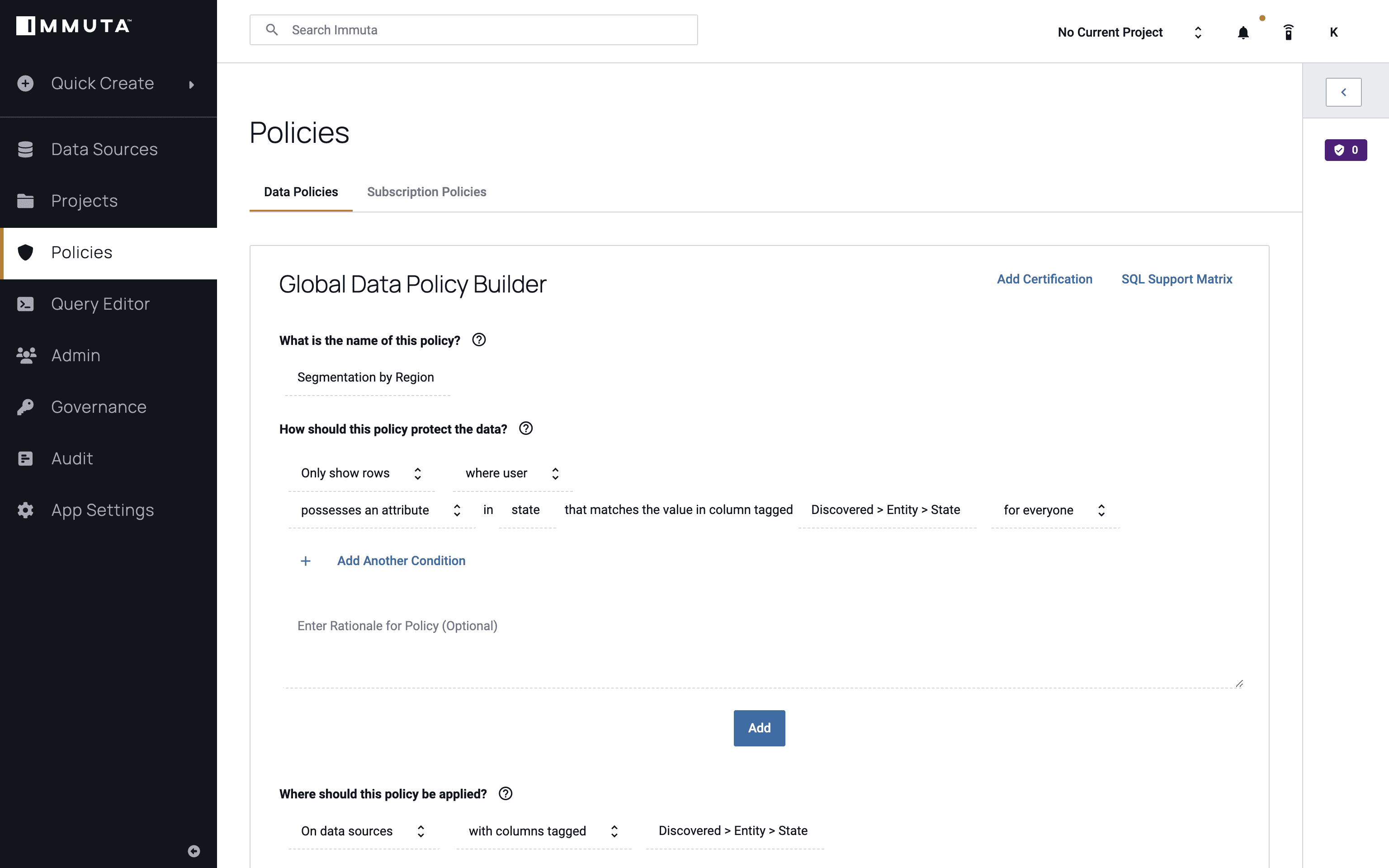
Once the global policy has been created and activated, it applies to all of the users and data sources registered in this Immuta instance.
3. Run a Query
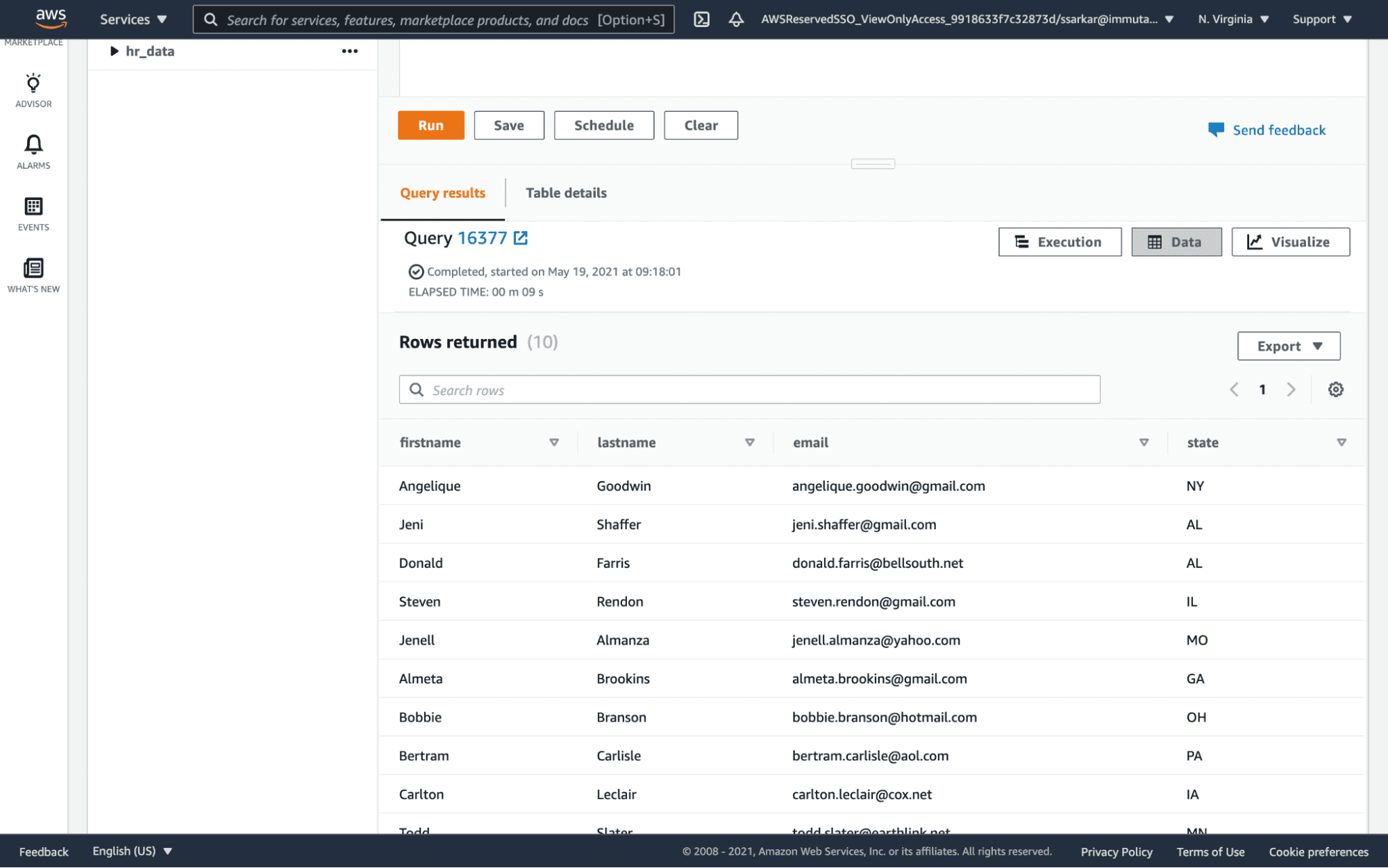
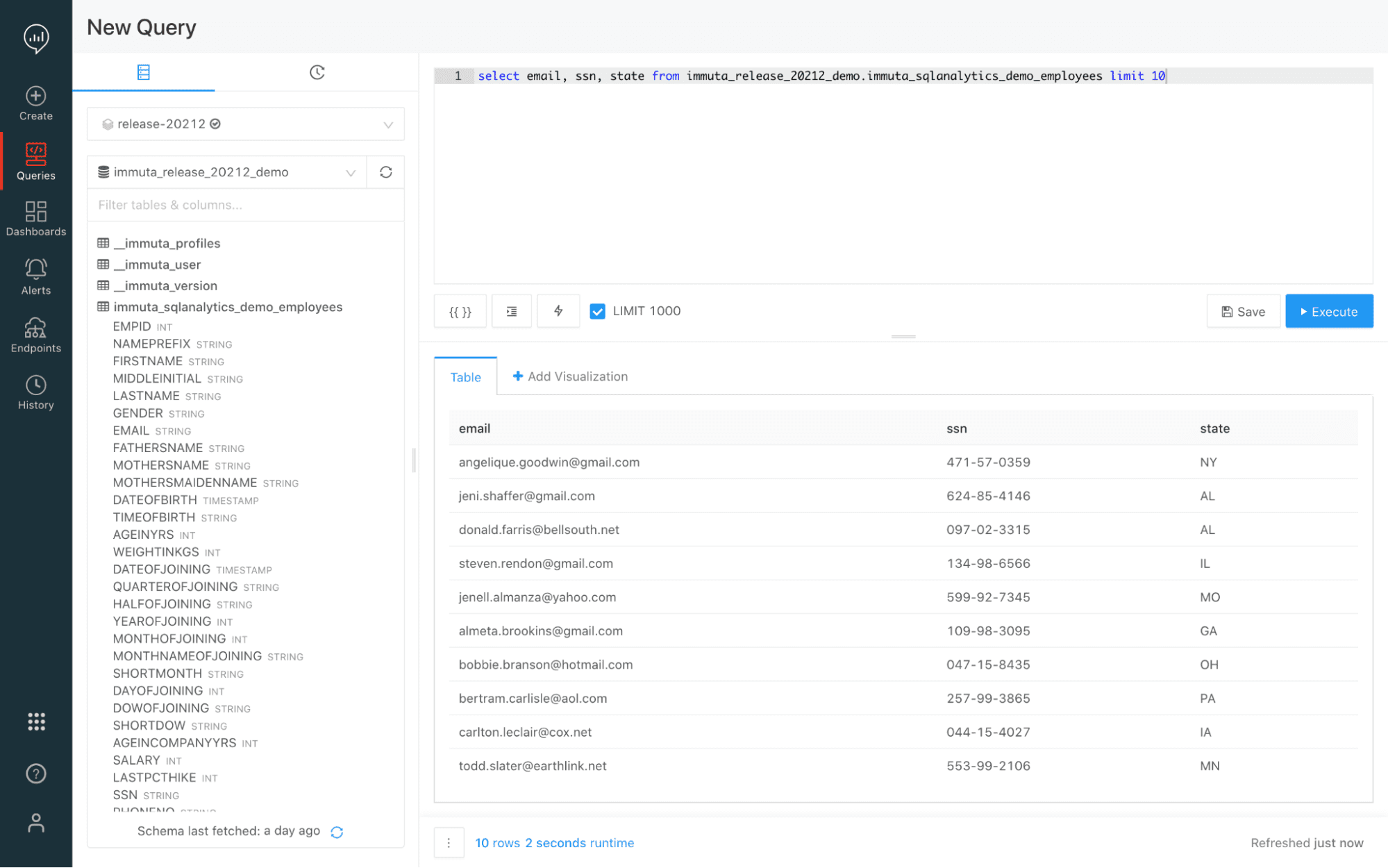
When we run a query in Redshift, we now only see data from the state of Massachusetts.
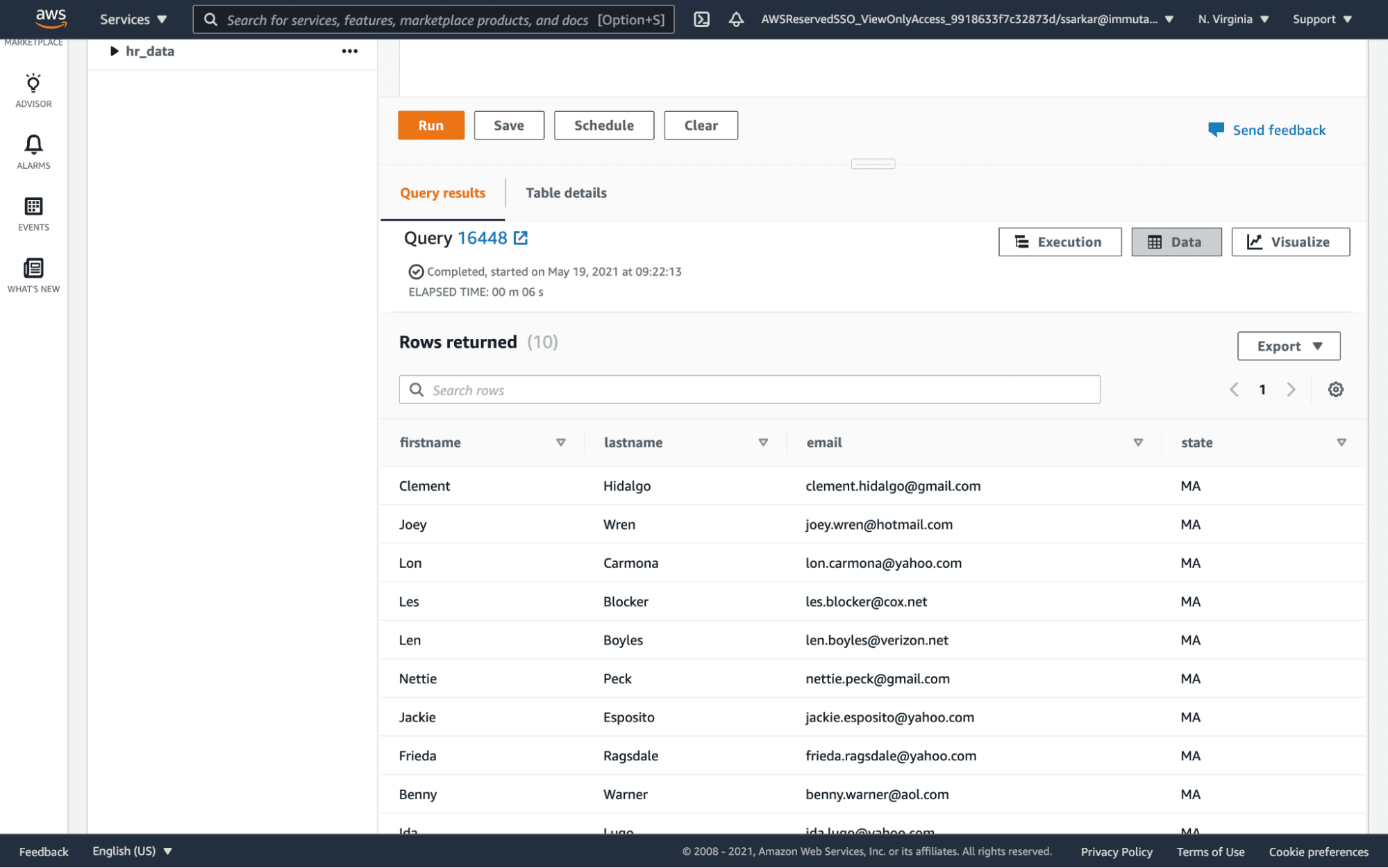
The policy is also enforced when we run the query in the Databricks SQL Analytics server.
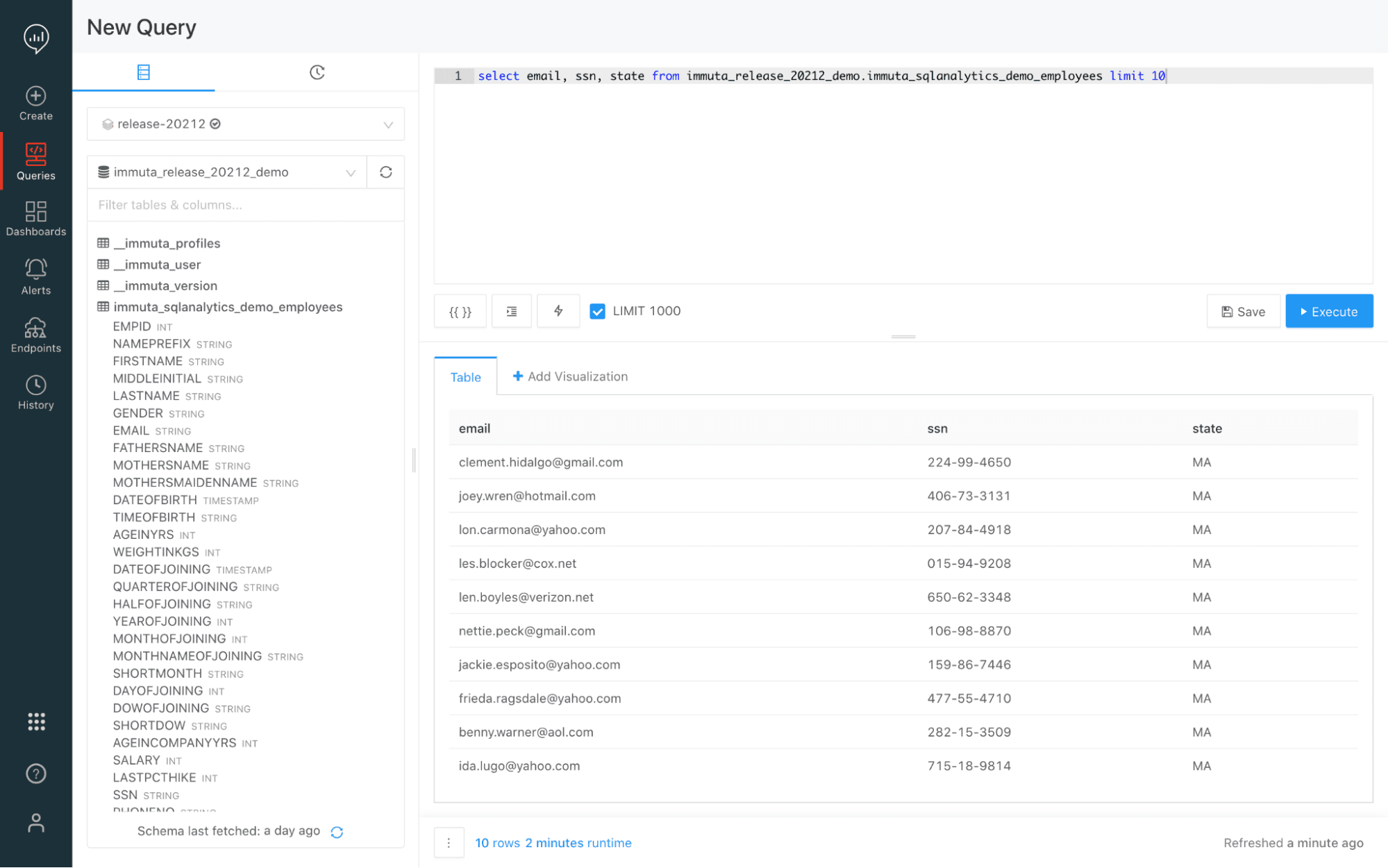
These same steps can be automated using Immuta’s command line interface (CLI) so that we can deploy into our production pipelines as-code.
Conclusion
Scaling role and view management manually across cloud data platforms in an AWS lakehouse architecture can result in hundreds or thousands of roles and views. This is not just time- and labor-intensive, but it also creates a large surface area for risk.
However, Immuta’s automated privacy and security controls allow users to create global and local policies to segment data for multi-tenancy and manage access seamlessly across platforms, with all query processing being done 100% in each platform. No other solutions can automate data security consistently across more than one cloud data platform, and the alternative is significant data engineering time and resources spent managing and creating rows, views, and tables, and manually tagging attributes and sensitive information.
Interested in seeing how to leverage Immuta’s data security capabilities across your data lakehouse? Request a demo of Immuta today.