Organizations with large workforces are increasingly analyzing employee data using cloud data platforms such as Databricks in order to optimize performance, engagement, and results. This trend necessitates a new approach to Databricks access control.
In this article, we’ll walk data engineering and operations teams through how to dynamically enforce k-anonymization on a data set for data scientists or analysts using Immuta’s automated approach to data access control for Databricks, including how to audit data use for a compliance team, DPO, or auditor.
[Tip] Explore the evolution of data access control in RBAC vs. ABAC: Future-Proofing Access Control.
K-anonymity is a data privacy preserving model and form of dynamic data masking that anonymizes indirect identifiers to prevent re-identification of individuals from threats such as linkage attacks. This method can be used in conjunction with other data de-identification techniques to further reduce risk of regulatory fines by making a data set exempt from regulations such as HIPAA or GDPR, depending on your use case.
Databricks Access Control with a Sample Human Resources Data Set
This is mock data stored in Databricks in a table named “hr_records” in the default database. It contains highly sensitive columns, including direct identifiers (such as Social Security number and email), indirect identifiers (such as location, start date, tenure, and gender), and sensitive data (such as salary and weight) that can identify an individual employee. In its current state, this may not be suitable to present to data scientists and analysts due to privacy concerns.
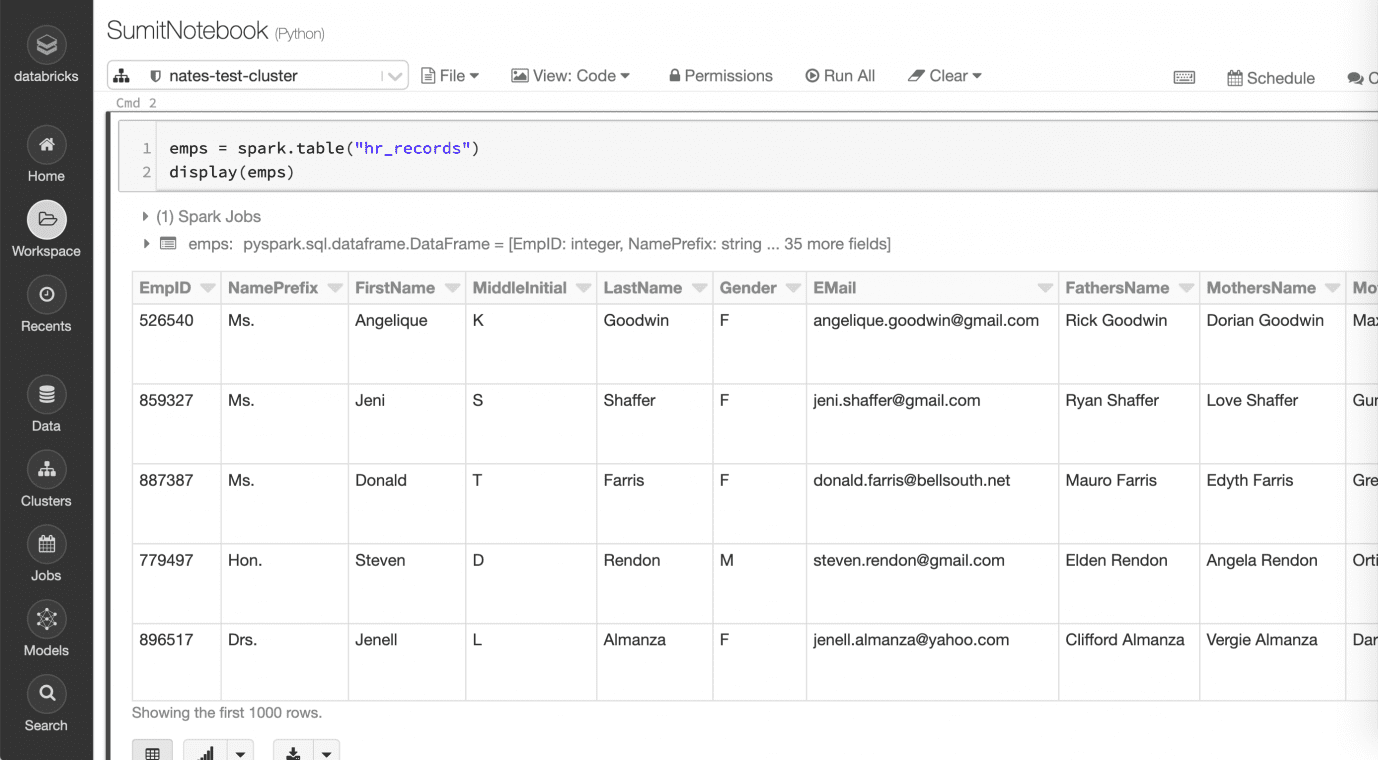
Register the Databricks Table with Immuta
After configuring the Immuta artifacts in Databricks, navigate from the Immuta console to the data sources icon on the left and click, + New Data Source, to create a new Databricks connection. Next, select the table “default.hr_records.” No data is ever stored in Immuta since this is a logical table. The fields can be tagged by running Immuta’s built-in sensitive data discovery, importing from existing data catalogs or manually tagging data. Below are example tags (in purple) for some of the identifiers in the table.
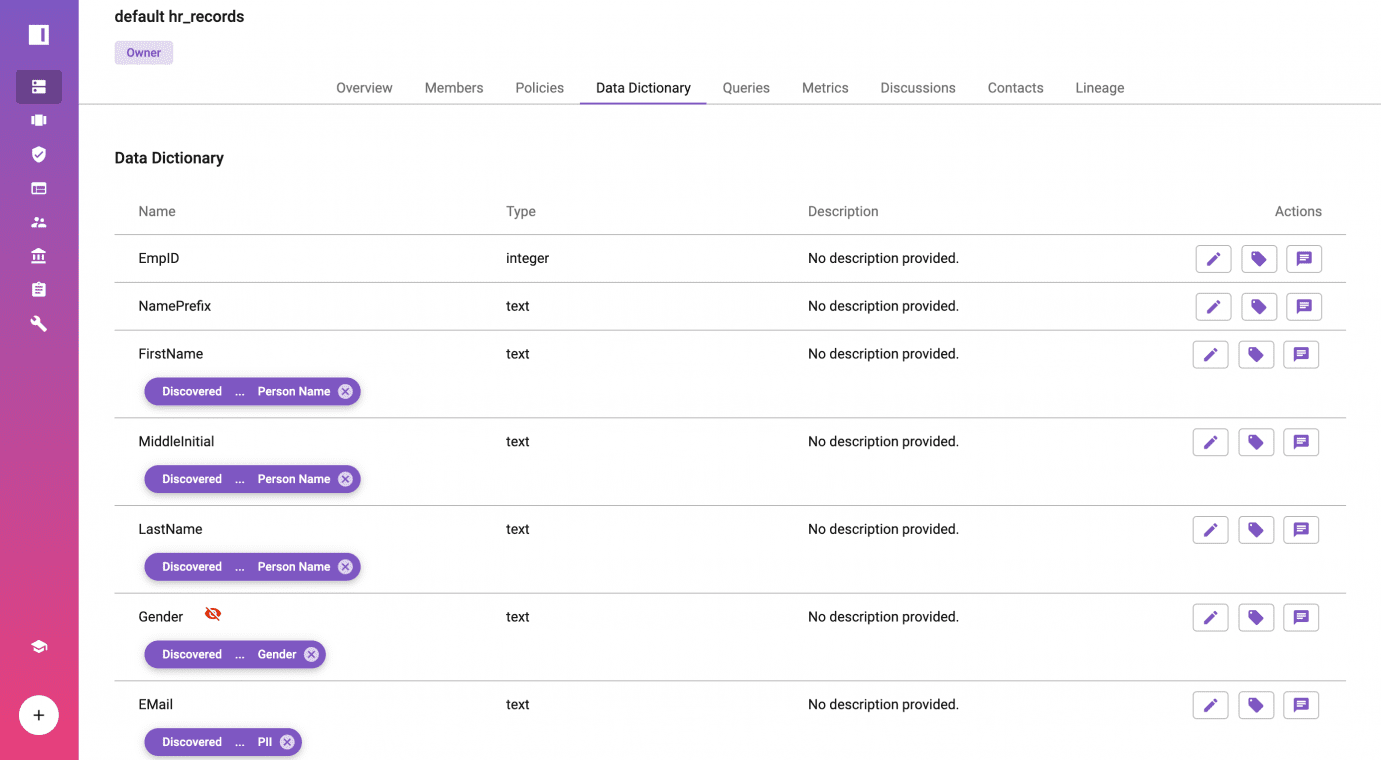
Create Dynamic K-anonymization Policy Without Code
There are two primary types of policies you can create to enforce Databricks access control: global policies apply across all data sources based on logical metadata (the tags); and local policies apply to specific data sources. In this example, we’ll enforce a local policy.
Click on policies from the “default_hr_records” data source, and create a new data policy using Immuta’s Policy-as-Code policy builder. This example enforces k-anonymity using the mask, or suppression method on the [state] and [gender] columns tagged in the previous step.
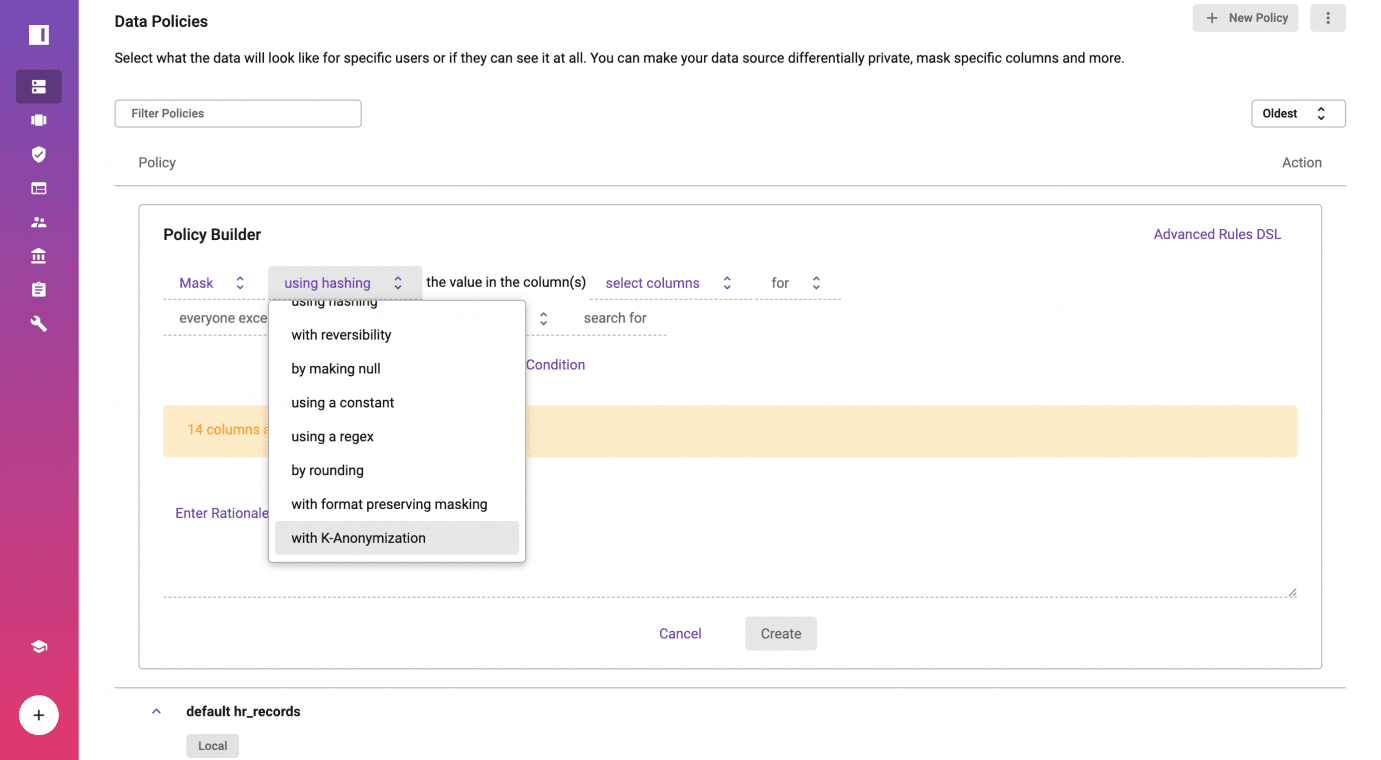
Save Policy to be Actively Enforced
At this point, a fingerprint has been run on the Databricks table to calculate the statistics required for k-anonymization. Users can either use a minimum group size, k, given by the fingerprint, or manually specify the value of k.
Upon policy creation, the fingerprint service will run a query against Databricks to get the counts for each possible group of values in the data source. The fingerprint service will then return the custom predicates for each column. In order to protect identities, the predicates will only contain a whitelist of the values users are allowed to see. We can now see the data policy applied to the Databricks table, default hr_records, that we registered in Immuta. The Policy-as-Code approach means your compliance team or DPO is able to understand the policy in plain English.
Query the Human Resources Data Set with K-anonymity Enforced on Read
The default_hr_records data source is exposed as a table in Databricks under the ‘immuta’ database cluster, and analysts or data scientists are now able to query the table. This is all enforced natively on read from Databricks, meaning that the underlying data is not being modified or copied, and the data access control policies are applied to the plan that Spark builds for a user’s query from the Notebook.
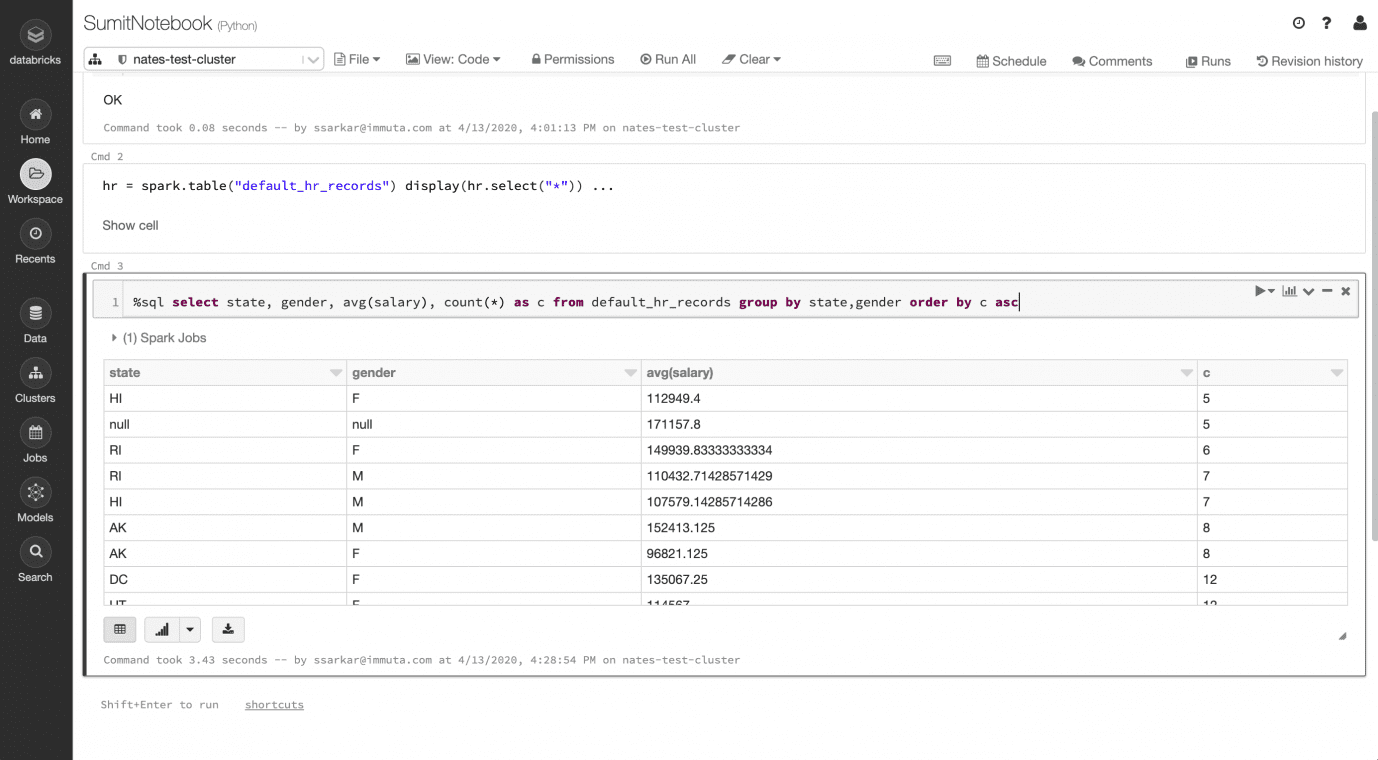
While different field groups get obfuscated per the dynamic k-anonymization policy, utility in the data is preserved. As an example, [state] and [gender] were suppressed as null in the sets of state+gender, where there was risk of re-identification. However, a statistically relevant number of [state] and [gender] combinations can still be analyzed (for example, to determine average salaries).
In this overly simplistic scenario, the k value is 5 and the average salary in Hawaii is $112,949.40. Note the null group for 5 records, where the masking policy is applied for employees that cannot be distinguished from at least k-1 other employees based on [gender] and [state]. This is because Delaware had only 1 male and 4 female employees in the raw data set.
Enhanced Audit Logging for Anonymization in Databricks
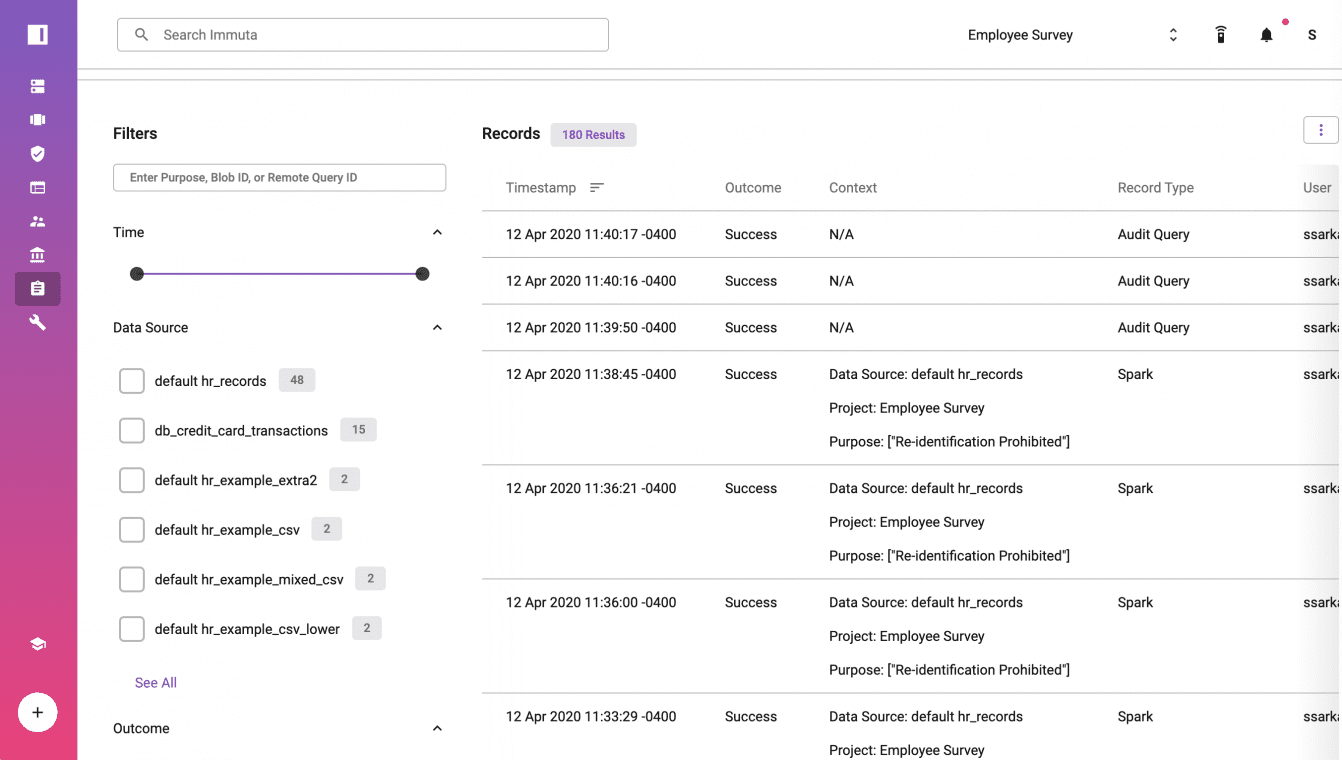
Within Immuta, click on Audit to see a report of all of the steps and details. The Spark plan for each query, user, and purpose/intent are available to rapidly demonstrate k-anonymization across [state] and [gender].
Additional Databricks Access Control Resources
This Databricks access control solution was developed by our expert teams of software engineers, legal engineers (legal nerds), and statisticians (math geeks). In addition to dynamic k-anonymization, Immuta automates fine-grained access controls and includes a suite of additional privacy and dynamic data masking techniques for Databricks.
There are OSS solutions available for a static k-anonymization implementation with Apache Spark. This is a simple example for one table, one rule, and one role, without a specific regulation in mind. Our commercial approach using a dynamic implementation (no data copies or ETL) is best suited for data teams working in regulated industries and/or with sensitive data in complex environments, where automation and prebuilt auditing is required to manage data sets, rules, and access at scale.