“Over the past few years, data privacy has evolved from ‘nice to have’ to a business imperative and critical boardroom issue,” states Cisco’s Data Privacy Benchmark Study.
As organizations adopt not just one, but multiple cloud data platforms, security and privacy are colliding and creating novel and often unanticipated challenges. Data teams increasingly need to find ways to adequately protect data privacy without negating its utility. Yet, with today’s advanced technologies and proliferation of sensitive data collection and use, a single layer of data protection — such as fine-grained data access control — is insufficient. Additional safeguards are imperative.
Immuta integrates with Databricks to provide automated data privacy controls that add a layer of protection on top of dynamic attribute-based access controls. This gives Databricks customers peace of mind that their data has privacy protection reinforcements against unauthorized access, data leaks, and re-identification.
A Guide to Data Access Governance with Immuta and Databricks demonstrates specifically how these automated data privacy controls work. But due to the growing threat of data breaches and leaks, here’s a preview of what Immuta’s native privacy controls in Databricks can mean for your data’s privacy.
Automated Privacy Control Options
Databricks users have two primary methods through which to automate security and privacy with Immuta’s native integration:
1. Sensitive Data Discovery
As new and potentially sensitive data is added to a database, automation is critical to not delaying data access or allowing sensitive data to go unchecked. Manual data discovery and classification is time-intensive and error prone, but Databricks customers can streamline the process with automated sensitive data discovery.
Once data has been registered with Immuta, Immuta’s sensitive data discovery flags and applies tags to sensitive data when it is uploaded to Databricks. With built-in tags for PII and PHI and the ability to create organization-specific tags, data engineers and architects can ensure all sensitive data maps to dynamic access control policies, which are applied at query time. This makes tasks like applying policies for CCPA and HIPAA compliance — for which Immuta provides starter policies — faster, easier, and less risk-prone.
2. De-identification
De-identification denotes the techniques used to protect direct and indirect identifiers that can be used to re-identify a data subject. The volume of personal information now being collected and used has necessitated de-identification as a way of guarding against linkage attacks and re-identification.
Databricks users can employ data masking or pseudonymization as a means of de-identifying sensitive personal information. While masking generalizes or suppresses identifiers so they’re obstructed, pseudonymization uses cryptographic hashing to replace sensitive direct identifiers with a unique non-sensitive value, which allows data subjects to remain distinct.
Automated Privacy Control Implementation
From data integration in Databricks, Immuta’s native integration streamlines privacy control implementation without requiring manual, risk-prone processes.
- When creating a data source, system admins navigate to the Advanced section to find sensitive data discovery settings.
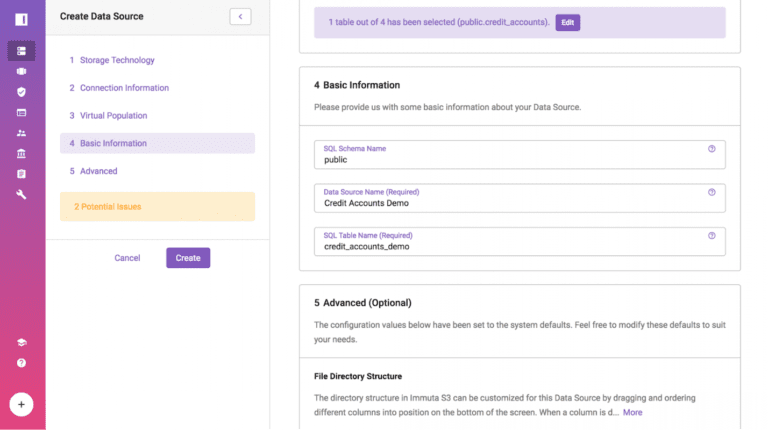
- Next, they select Enable Sensitive Data Detection and choose either Internal or External Sensitive Data Detection, depending upon whether data classification will be done internally by Immuta or externally by a third party managed by Immuta.
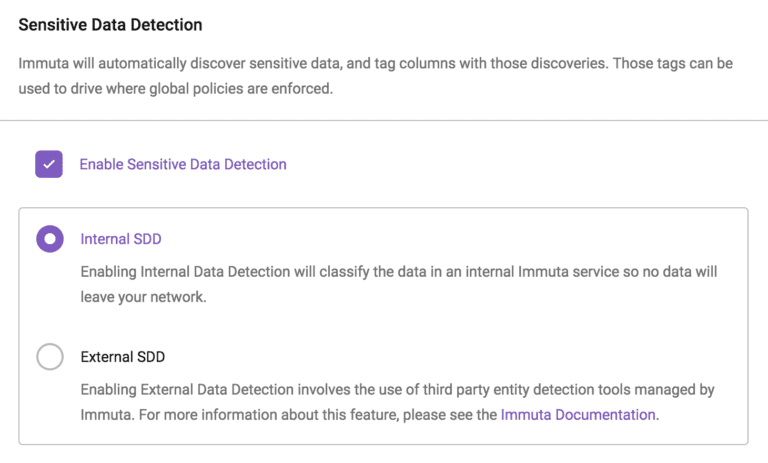
- Now, when data sources are created, pre-configured tags are automatically applied. Data users can still disable auto-tagging for specific data sources and data governors are able to override unwanted tags to prevent future auto-tagging.
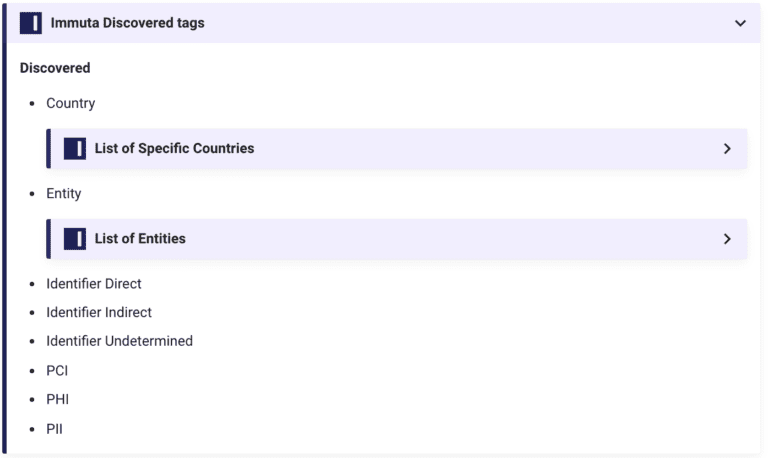
- When creating a policy in Immuta’s Policy Builder, Databricks users can assign a de-identification function, like masking, to a specific tagging category.
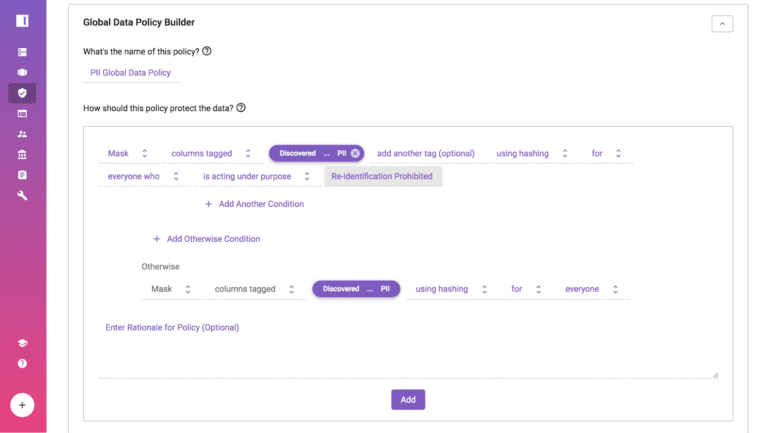
This process means that necessary data privacy controls are automatically applied at query time and are implemented consistently across all Databricks data sets. Based on user attributes, sensitive data tags, and privacy controls, data users will see only the data they are authorized to see and that is needed to to answer their specific query. Consequently, data teams can efficiently discover and apply adequate protections to sensitive data in a way that is uniform and scalable.
To learn more about data privacy controls and the other capabilities of Immuta’s native integration with Databricks, download A Guide to Data Access Governance with Immuta and Databricks.
If you’re a Databricks user, experience Immuta for yourself with a personalized demo.
Try demo