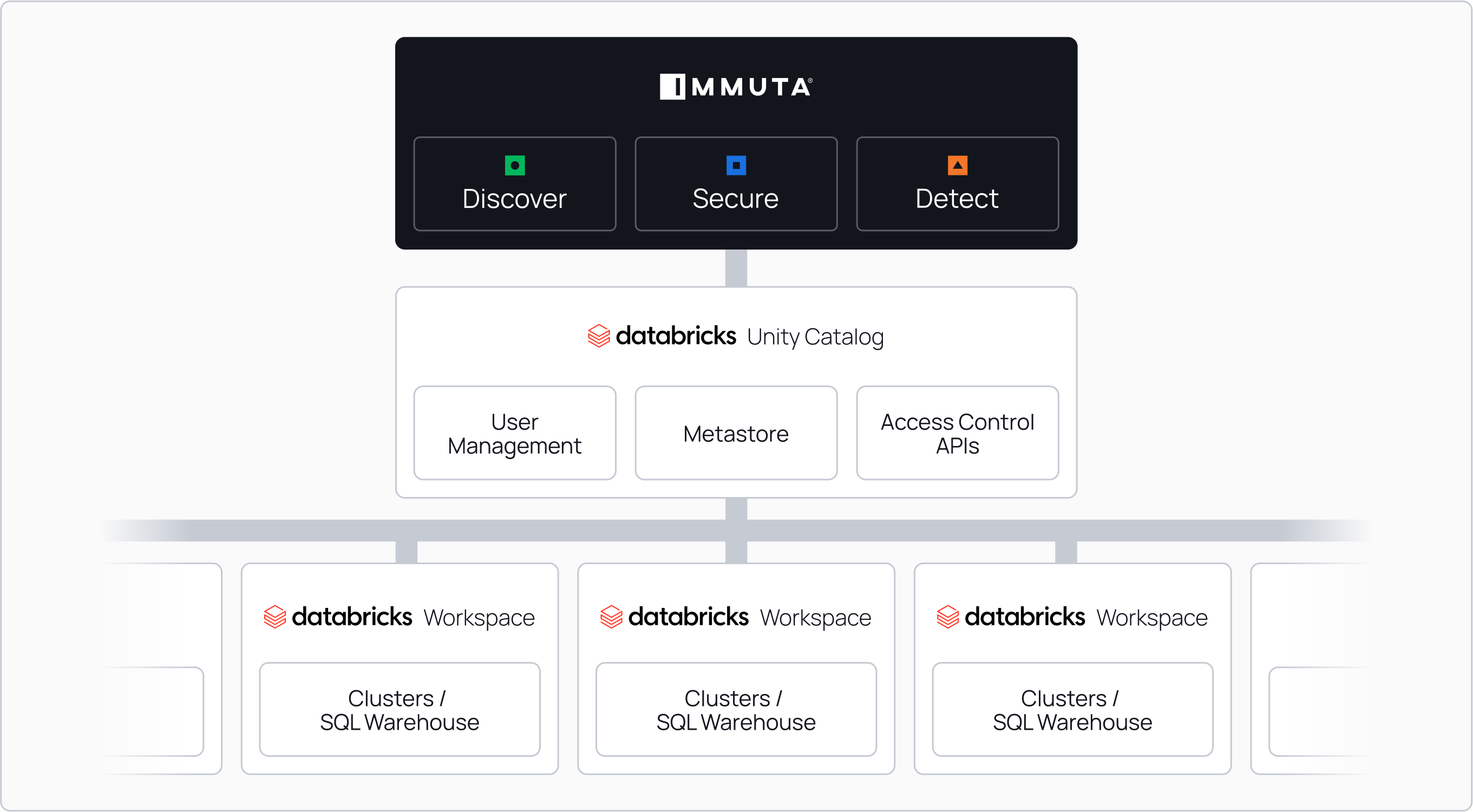
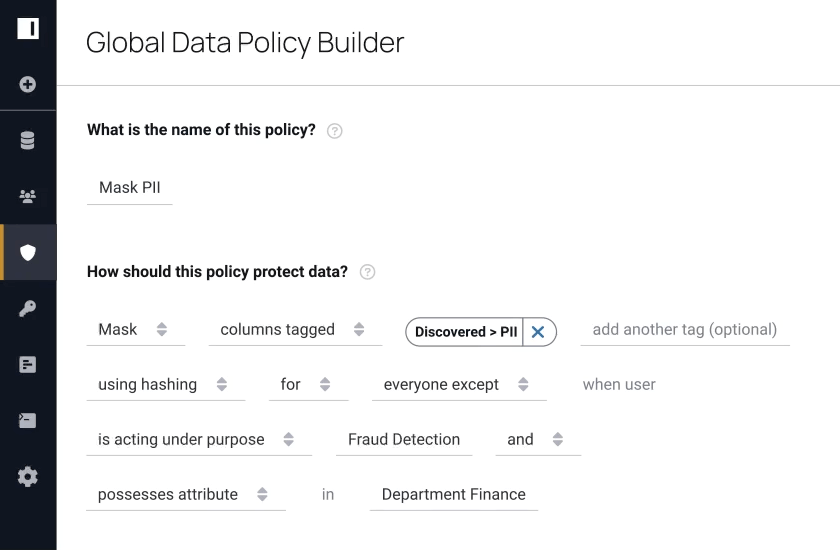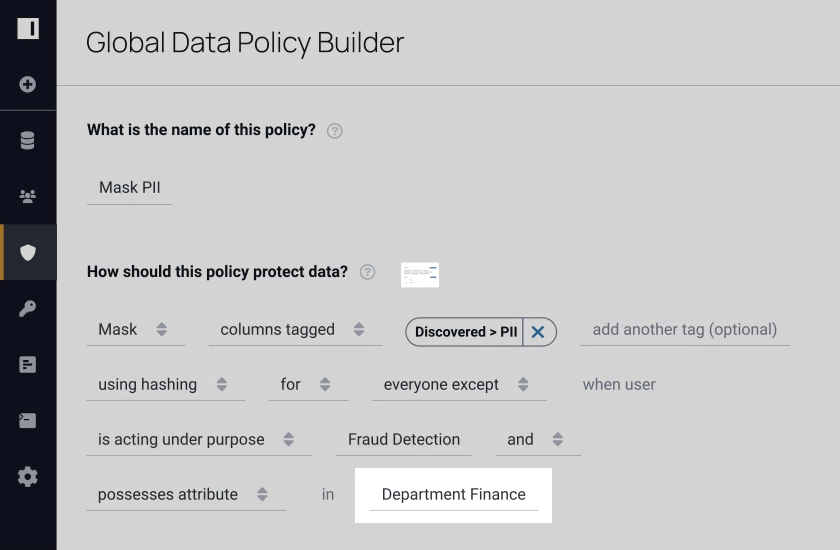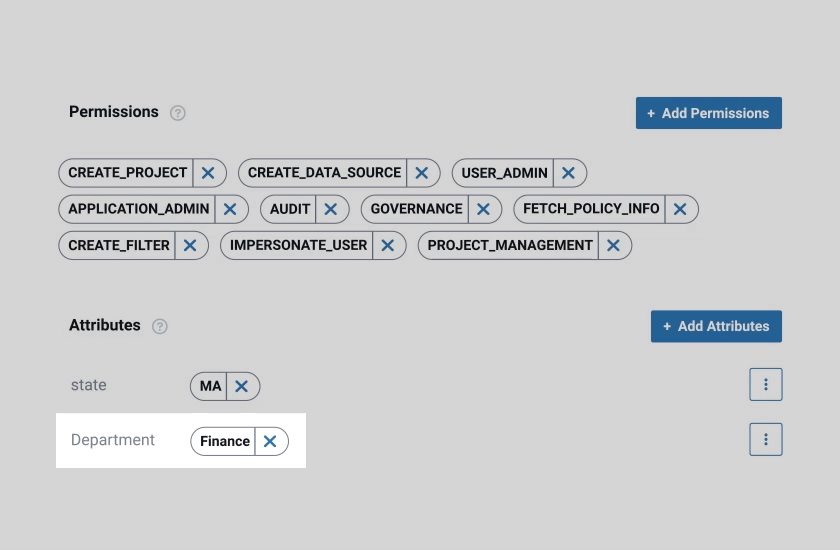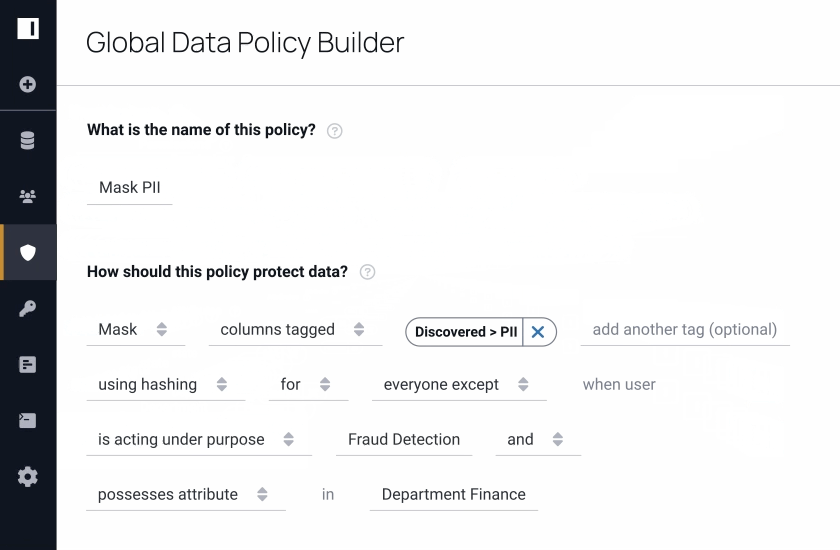
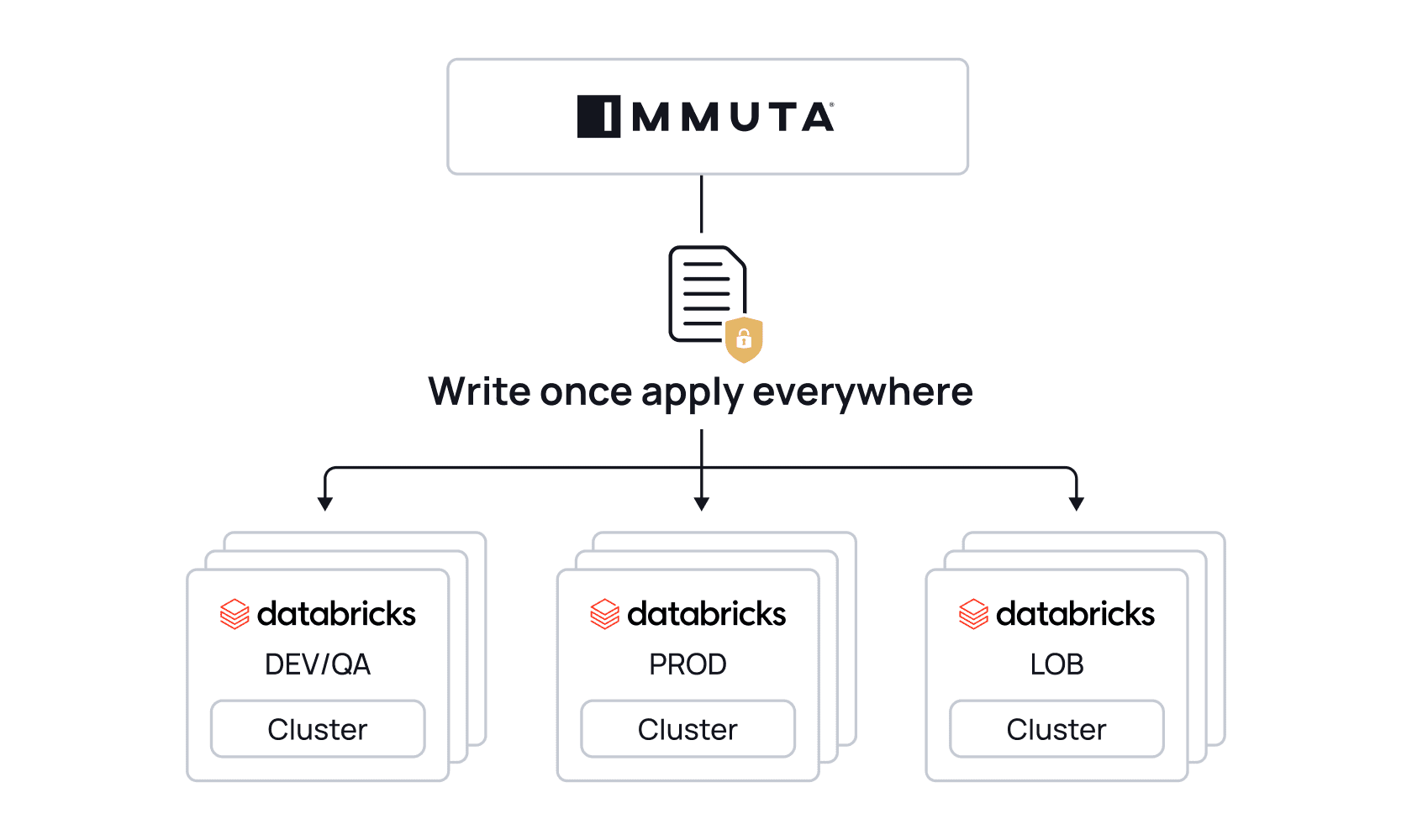
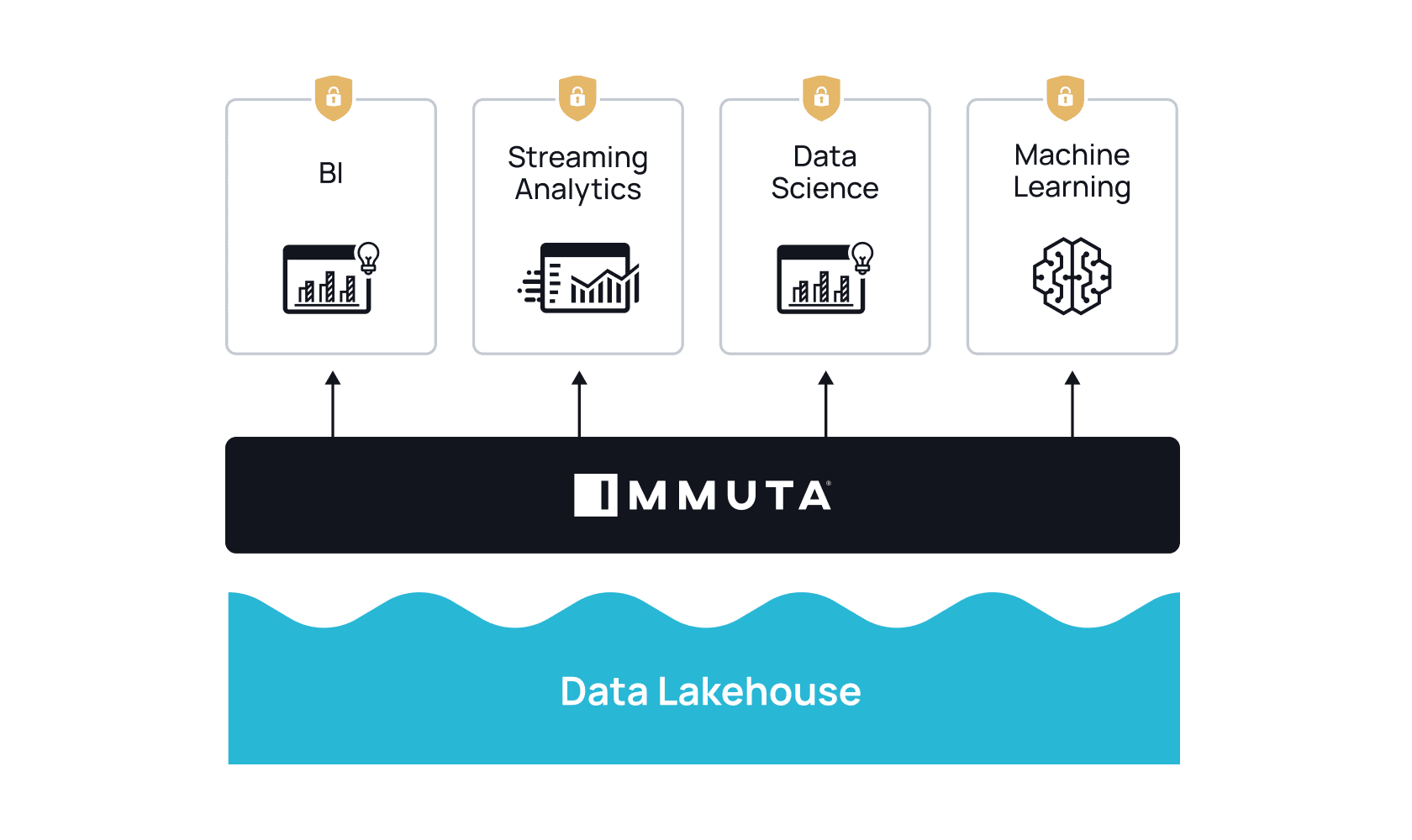




“Databricks and Immuta open up many opportunities for self-service data analytics, data science, and enterprise reporting.”
Immuta’s automated and secure data policy engine is a key piece of this data governance puzzle, and we are thrilled to be joining forces to help in our effort of simplifying the process of securing and governing data and AI assets across multiple clouds.