On Immuta’s data team, we put metadata at the center of our access strategy from the beginning of our journey, and dbt has been central to our success. In addition to its primary role in driving data transformations, dbt serves as a metadata engine: it provides useful abstractions, easy ways to bulk apply tags and metadata, and well-organized artifacts that expose that data to the engineering team.
The magic happens when dbt’s metadata is coupled to Immuta’s policy engine to dynamically enforce user access and privacy transformations. In this post, I’m going to share specifically why this back and forth is powerful, and how we execute it.
Teasing apart value and governance transformations
A major reason for dbt’s surge in adoption is its simplicity: by forcing everything into SQL files and Jinja macros, the data team gets lineage, readable code, version control, and a clear development workflow. Building a data platform begins to feel like a team sport and the most complex modeling problems suddenly become tractable, even templated.
At first a data team’s top priority is delivering business value, and most of the data pipeline will be focused on supporting activities such as standardization, aggregation, integrating definitions, and calculating KPIs in a way that enables flexibility.
At a point soon afterwards, the team begins to think seriously about protecting this data: identifying who is allowed to use what aspects of the database and how to enforce rules. It’s very possible to do this with SQL and dbt, leveraging post-hooks and additional SQL statements to create roles and grants in the database. These actions are transformations of the data, but they are of a different kind than those deployed during most analytics engineering work.
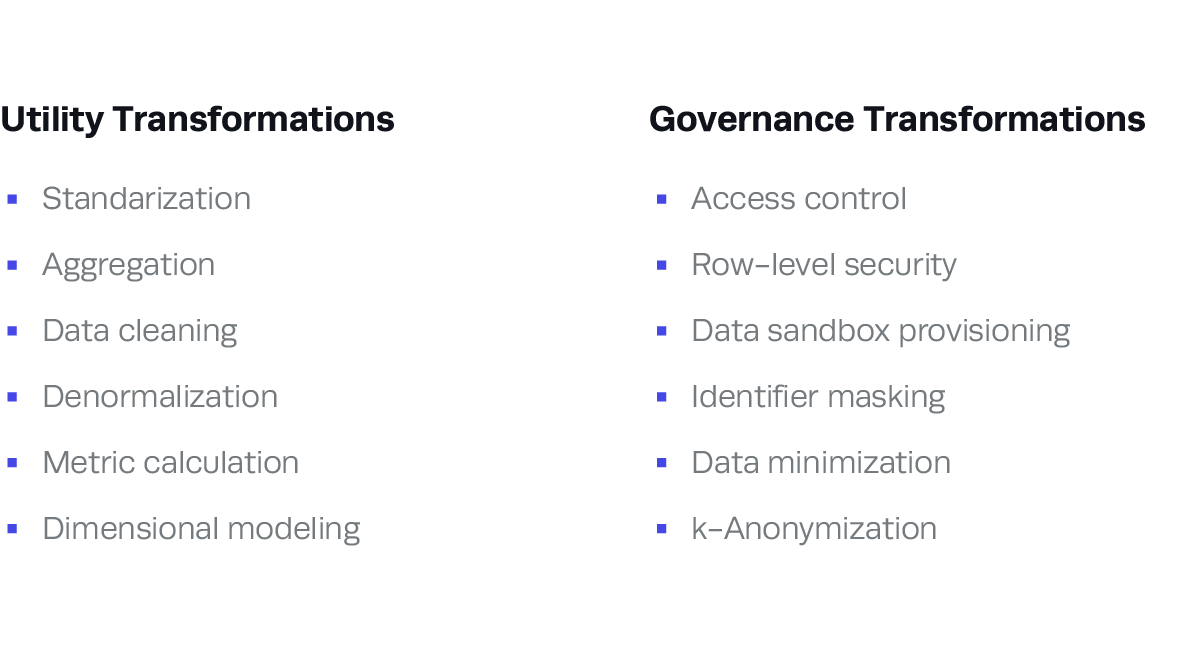
Value transformations have a persistent logic built into them: a model that makes sense today is likely to solve the same problem for other teams. Governance transformations are grounded in the release of the data and are heavily influenced by context: if your company experiences a reorganization, are all the grants to the “marketing_analytics_intern” role going to be relevant?
The natural way to address governance transformations is to create a copy of the data that is suited for a purpose (“contacts_masked”, “contacts_masked_usa”, etc.) and grant it to a specific group of people. Although that solves today’s problem, it is neither scalable nor satisfying.
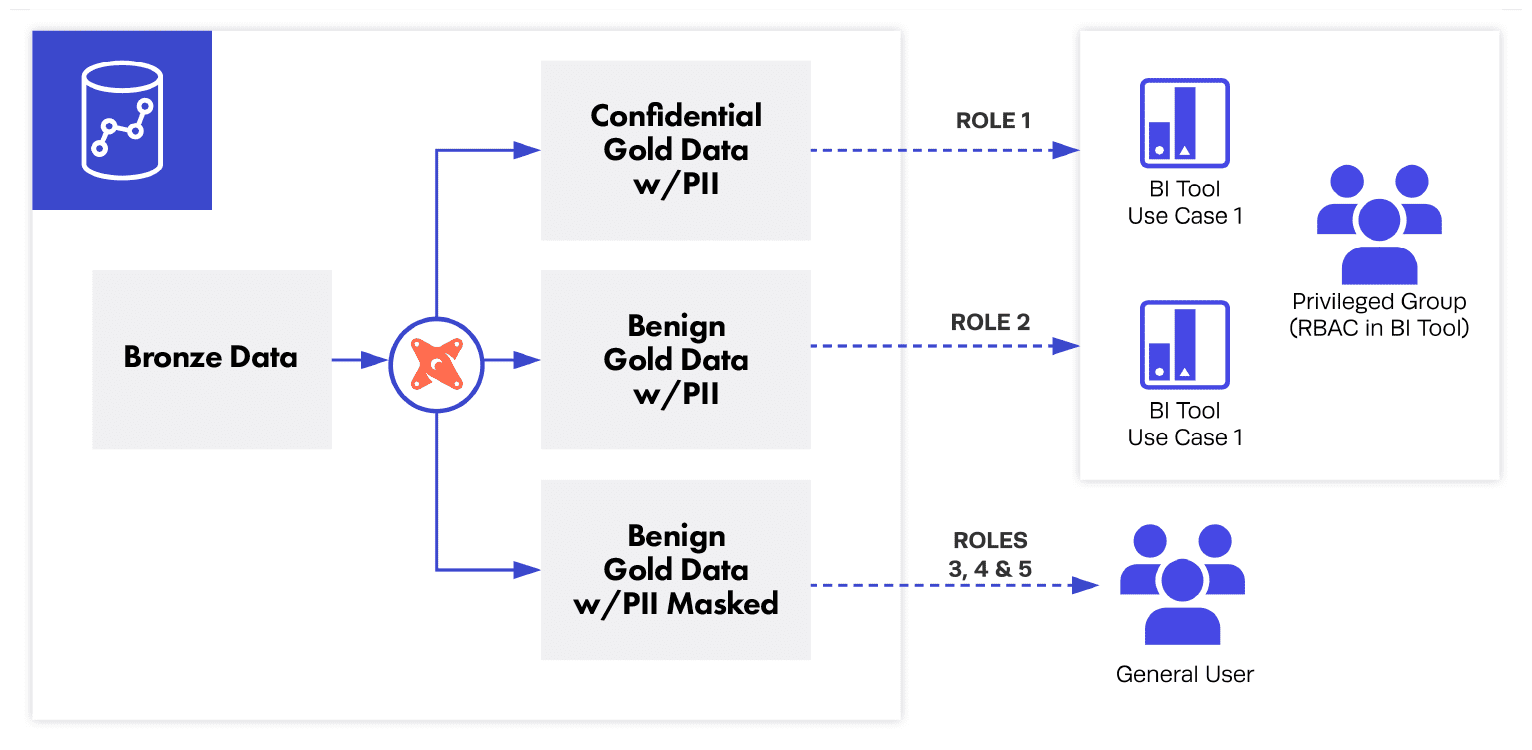
Baking governance transformations into the warehouse creates additional layers of logic that are unrelated to the data assets and likely to change over time for reasons external to the data.
Governance transformations do have a persistent logic to them, but it is only apparent when expressed through a metadata vocabulary. A policy that states: “No employee should view unmasked customer personal information, except when authorized by a data governance officer” is a sensible policy that could stand the test of time and reorganizations. However, you need to have a consistent metadata framework, and data assets that adhere to it: identity management systems must identify “approved data governance officer,” data catalogs must know where “customer personal information” lives, and database engines must know under what circumstances to enforce that policy.
Using dbt and Immuta to enforce “policy as code”
With dbt and Immuta, our data team at Immuta has established a virtuous cycle between how data is organized in our dbt project and how it is protected across our user base. Specifically, the way that data assets are tagged in our internal dbt project determines the extent to which a user will have access to it. If a column is tagged as PII, only a subset of users will be able to view it unmasked; if a table is tagged as “privileged,” only privileged users will be able to access it. (And this happens with very limited role management.)
This approach makes handling access control as easy as adding a line in a YAML file. It simplifies safe onboarding of data: only when the appropriate tags are added to an asset will end users get access to it. This approach also creates a path for users to meaningfully request access to new data assets. Because rules are driven by metadata that anyone can understand, it becomes possible for teams to build proactive consensus on how to protect data, instead of refactoring models after the latest policy initiative.
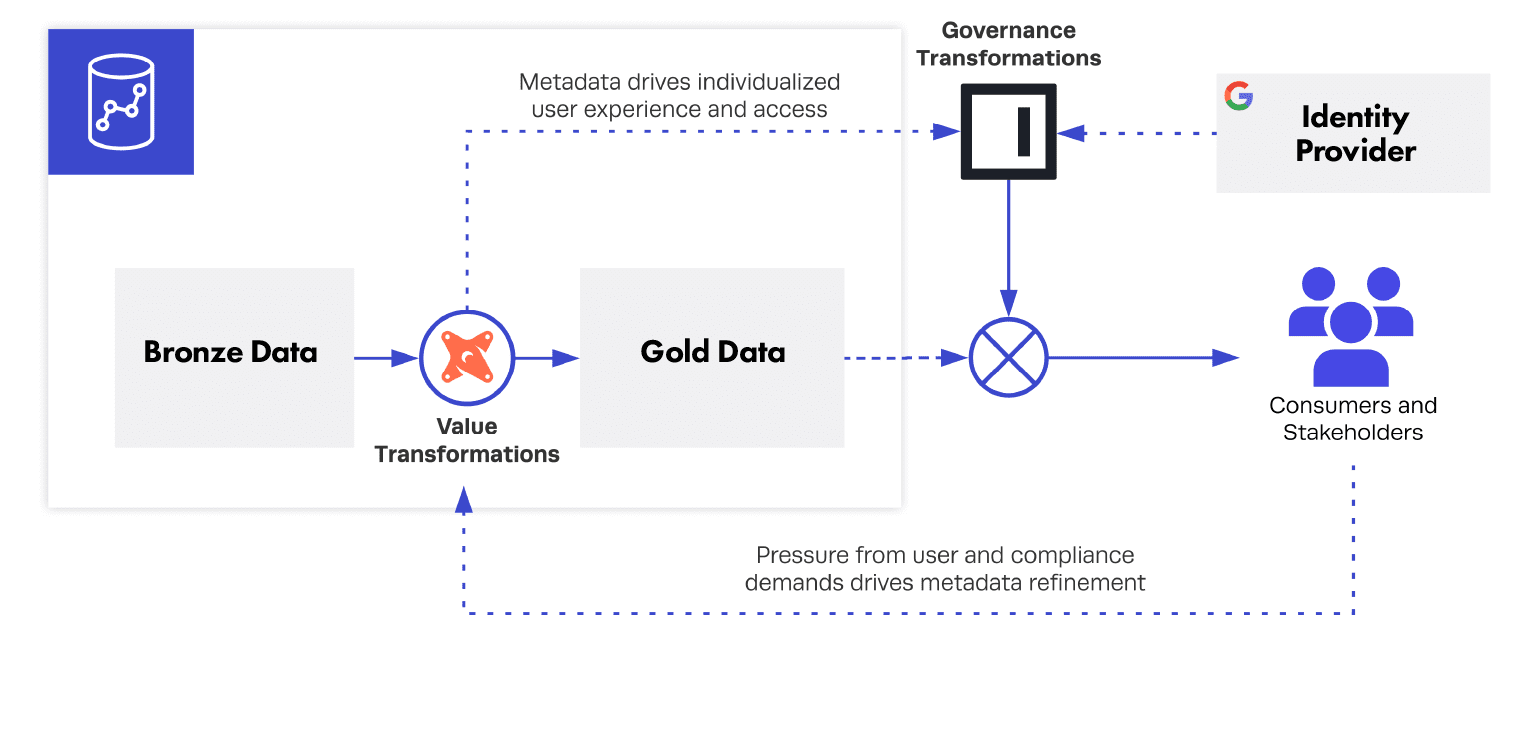
Abstracting the governance logic enables purer transformation logic, as well as a clear route for improving or changing metadata.
This abstraction to the Immuta layer is important because Immuta provides insight into who is going to use your data. Although there are clever ways to attack this problem, the ideal solution is to avoid refactoring the data layer at all, since it’s really contextual information that is changing. What’s more, separating these layers allows you to govern data even during development —- for example, by having developer sandboxes containing masked data, while the “system” dbt branch operates on unmasked data.
To execute the integration, our data team has built a simple tool to convert the dbt artifacts into simple YAML files that can be pushed to Immuta’s API. We implement logic to automatically add metadata from the following data sources into their Immuta counterparts after running dbt in our pipelines, which in turn invokes our pre-defined organizational policies. Each of the dbt objects (sources, seeds, models, snapshots) are mapped to their counterparts in Immuta and augmented with information about the folder structure and resource type, along with any explicitly defined metadata. We also use the new dbt Exposures object, which allows users to define a downstream use of a dbt project. Exposures are mapped to Immuta projects, which can be easily turned into data “clean rooms.”
An example of an Immuta project generated from a dbt Exposure in Immuta, as created in Immuta.
The “metadata push” paradigm was so compelling in our internal use case that we streamlined our own product’s API to make it easier to bulk update tags and metadata from tools like dbt. By streamlining the way objects in Immuta’s metadata layer can be updated, it is much easier to push metadata from dbt artifacts (or other processes) into Immuta, triggering immediate updates to how data can be accessed.
Conclusion
In this work, we shared the Immuta data team’s approach to separating value and governance transformations by integrating dbt and Immuta. The way data is organized and tagged in our dbt project fundamentally influences the way we expose data, to whom, and with what protections. Furthermore, the process reinforces itself, making the metadata framework a crucial conversation — rather than an afterthought to be addressed by an Important Data Access Control Project that is separate from the fundamental data workflows.
Access control is only one component of a team’s metadata initiatives, but it is one of the most important, especially as data teams face rapid growth in the volume of data and breadth of reach. By putting your metadata to work early on, data teams can set themselves up to augment their platform with additional capabilities over time.
To learn more about how we use Immuta at Immuta, check out this blog on dogfooding data access control.
Interested in trying Immuta for yourself? Get in touch with us today.


