2024 State of Data Security Report
700+ data leaders' perspectives on AI, data security, and governance.


There’s a lot of confusion in the market about attribute-based access control (ABAC) and what it actually is. This short blog will use a handy analogy to explain ABAC.
Many think that using tags on data to propagate policy is ABAC. For example, if you tagged all your columns containing personally identifiable information (PII) with a PII tag, you could then build a policy once that says “mask all columns tagged PII,” but apply it multiple places. While this approach is certainly critical to scaling data policy enforcement and management, it alone is not ABAC.
When describing ABAC, you must compare it to the legacy role-based access control (RBAC). You can read deeper dives comparing these forms of data access control in this ABAC vs. RBAC blog and white paper, but at a high level, role-based access control makes pre-computed decisions. It conflates what the users in that role have access to with the users that are members of that role.
ABAC is the inverse; it decouples who the user is from what they have access to, and instead makes the access decision at runtime. This allows for much more scalable policy management and avoids a common access control pitfall: “role explosion.” Clear as mud? We thought so, too…which is why we came up with a helpful analogy:

700+ data leaders' perspectives on AI, data security, and governance.
We’re all familiar with email distribution lists, which combine a bunch of email addresses into a single distro so you can email all the people on the list at once using a single email address. Sound familiar? This approach is akin to RBAC, because just as the role decides who should have access to data, the distro decides who gets the email. The individual emails in the distro are pre-determined. Riffing on this analogy a bit more:
So what’s the problem?
At Immuta, we have (at time of writing) 236 employees and 714 email distros. Yes, that’s correct – we have more than 3x the amount of email distros as we have employees!
Why are there so many distros? The different combinations of people you may want to email is nearly limitless, and every time someone has a new meaningful combination of user groupings, a new distro must be created. This makes sending emails via a distro complicated because you don’t know which of the 714 to use (or even what they are called). Senders often either end up individually adding the users on the “to:” line or picking a role and hoping for the best.
Let’s say there’s a team happy hour in Immuta’s Boston office with an engineering speaker, so I want it to be in-person. I want to send an email invitation to everyone that’s an engineer in Boston, but when I start typing “Boston” into the “to:” line…204 results show up, and none seem to have the words “Boston” and “Engineering.”
So, I have two choices:
How does ABAC solve this problem? As we said earlier, ABAC decouples who the user is from what they have access to, and instead makes access decisions at runtime. With an “ABAC emailer,” I could instead send an email to everyone with:
Voila. My ABAC emailer finds out at runtime who should actually get the email based on those user attributes. The RBAC emailer with all the email distros pre-computed caused “distro explosion,” making it impossible to use. With RBAC emailing, I was either left with over- or undersharing; with ABAC emailing, the email got to the right people, without adding too many recipients or leaving any out. (Maybe someone should actually make an ABAC emailer?)
Now that we understand how ABAC works through our email example, let’s see how it simplifies fine-grained access control. Below are four real world policies you could create in Immuta using our ABAC model:
Table-level control:
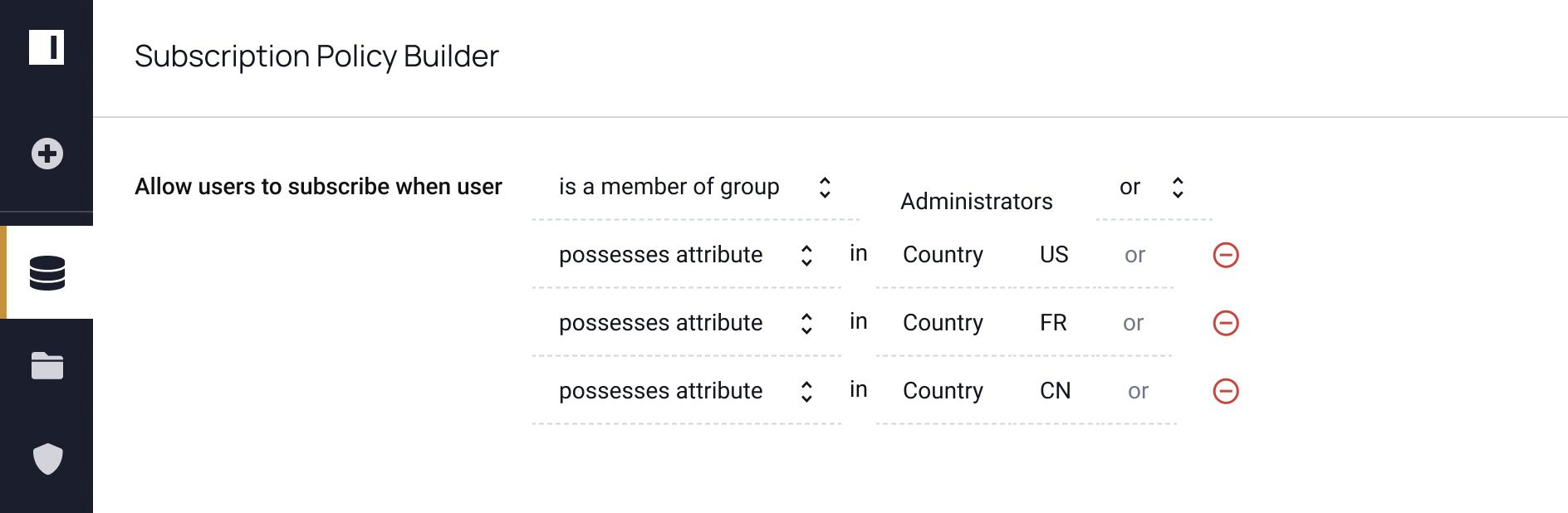
Masking policy 1:

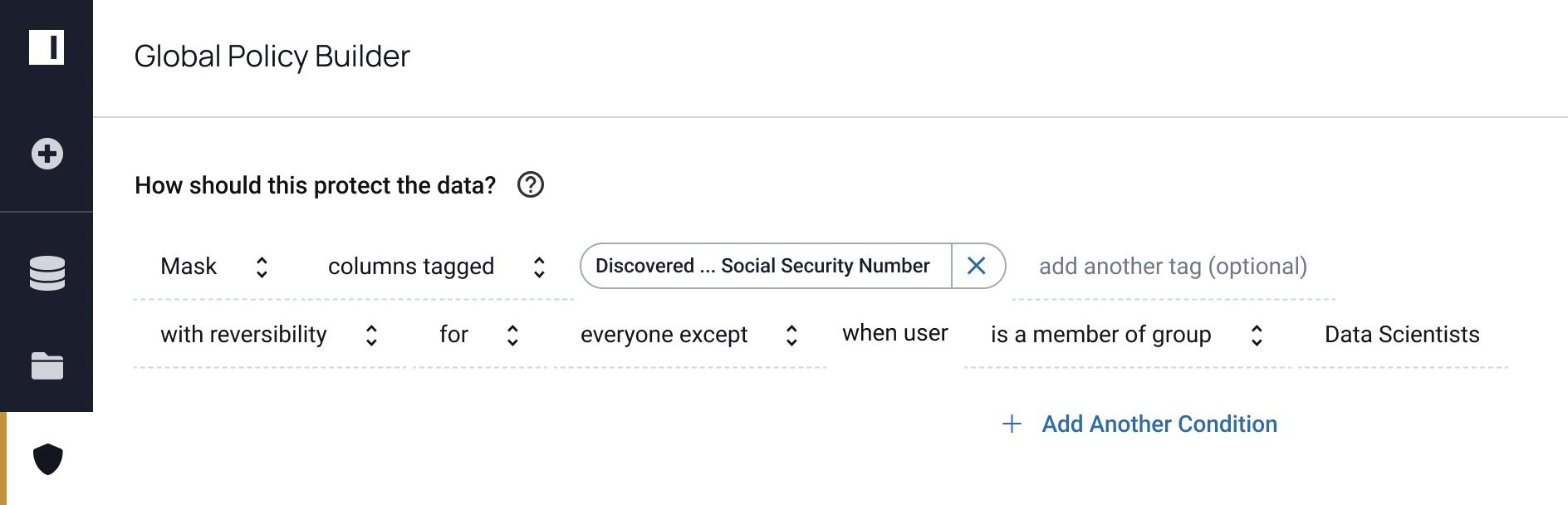
Masking policy 2 (note that Social Security Number is PII):
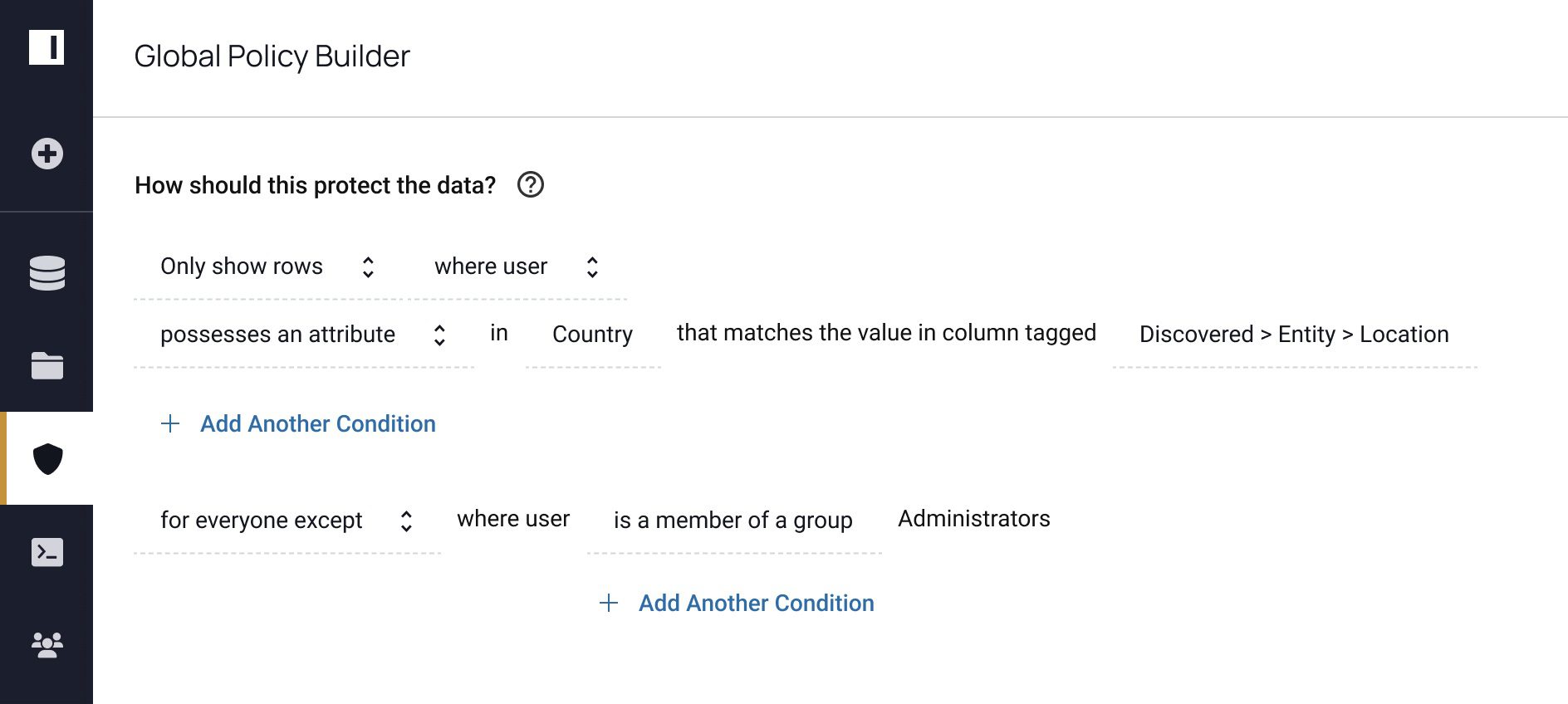
Row-level security policy:
All four of these policies could fall on the same table successfully. Considering that, this policy requires a matrix like the one below to determine access (the column headers are the user attributes):
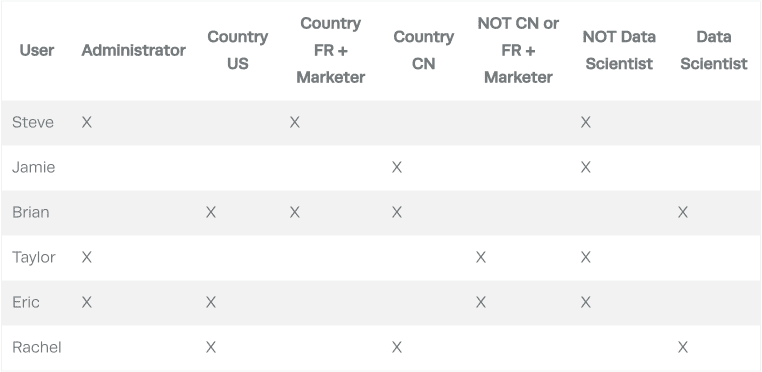
With enough users, attributes/groups, and policy complexity, the matrix becomes very sparse. As you can see, no single user has anything in common with another user.
RBAC systems like Apache Ranger conflate these users into roles to provide them the appropriate access. Depending on how many users you have, this could result in literally thousands of roles. As you keep piling on policies, the complexity grows and your role count explodes, just as new combinations of people you need to email explodes the amount of email distros you need. At some point, the data platform team gives up and is left with the same decision we were left with when trying to email the Boston Engineers:
Additionally, with RBAC you must remember to add new users to the correct roles as they are onboarded to ensure policies are enforced correctly, just as you must add new employees to the appropriate email distros to ensure they get all the right emails.
ABAC solves both problems.
First, it abstracts that matrix completely because it is a runtime comparison, avoiding the need to map that (sparse) matrix to roles. Users can build policies simply in Immuta and it all “just works,” without any role explosion.
Second, ABAC minimizes the problem of having to know what roles to add new or updated users to, because using authoritative attributes to describe users is obvious. Deciding which roles/email distros they should belong in is closer to guessing than anything, unless you were the original author of the roles/distros. In this way, ABAC is future-proof.
With ABAC, the data platform team can quickly and easily share and manage data policies, accelerating time to data and increasing data volume to users. In fact, GigaOm published a study comparing various platforms’ RBAC to Immuta’s ABAC, which concluded in the same findings: a set of pretty simplistic policy scenarios resulted in 93x more policy changes (including creation of roles) with RBAC than with Immuta’s ABAC approach.
ABAC is the key to scaling data policy management.
Give Immuta a shot yourself. We have deep integrations with Databricks, Snowflake, Trino, Starburst, Amazon Redshift, and Azure Synapse (SQL), which allows you to inject our ABAC control model directly into those platforms.


