Announcement
Immuta is happy to announce our 2.1 release which includes native SparkSQL policy enforcement. With this new capability, Immuta can now enforce all the same policies historically available through Immuta while allowing massive scale processing in Spark. This includes row and column level controls, time windowing, minimization, purpose limitations (critical to GDPR), as well as differential privacy.
Why is this important? There’s no limit to how much data you can process, secure, and audit with Immuta policies. The new Immuta SparkSQL layer allows access data on-cluster, and joins with data external of the cluster without the need to configure drivers in SparkSQL. With Immuta, all your data is made immediately available from within Spark – even if it doesn’t live on your cluster.
What Problem Are We Solving?
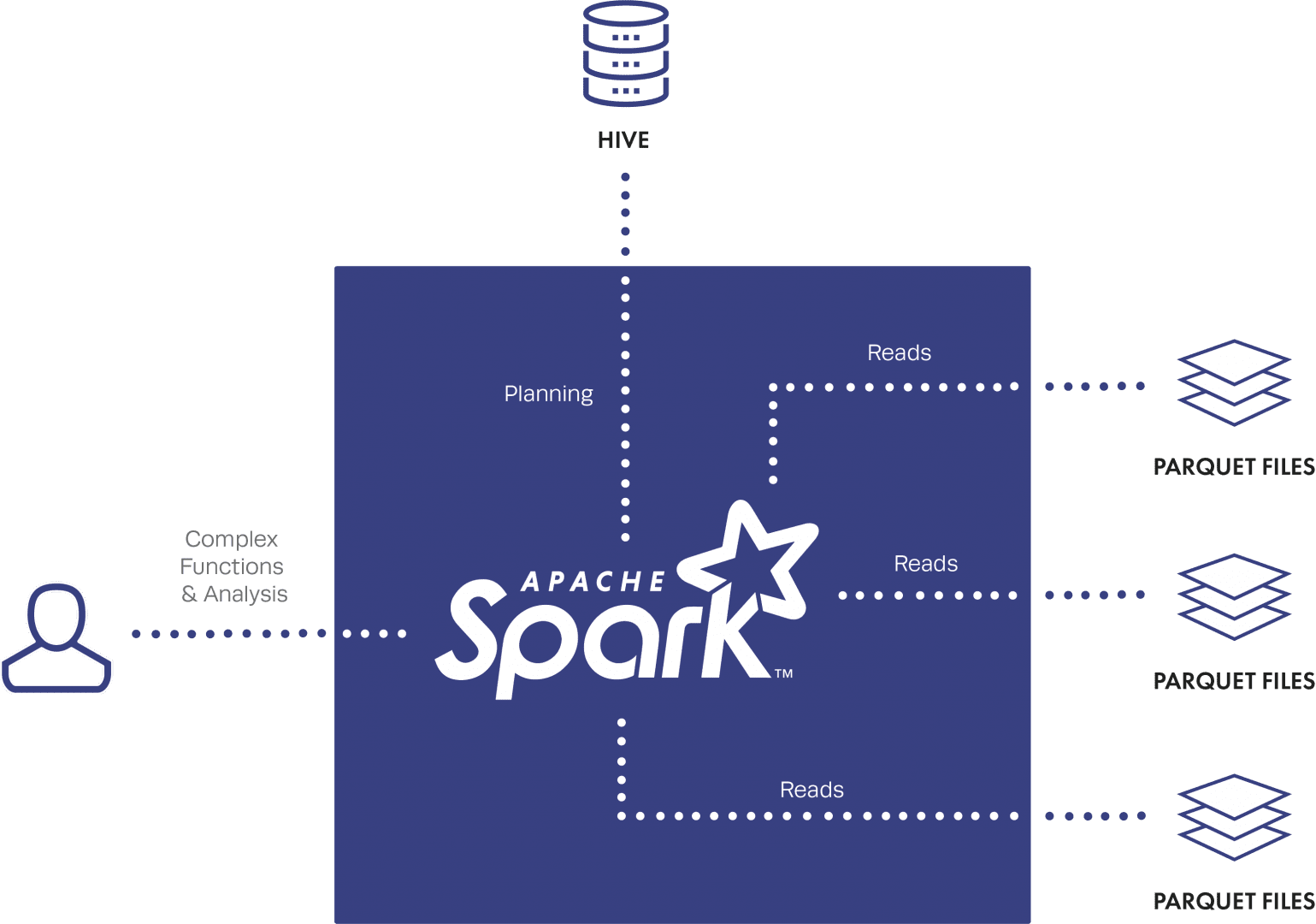
What makes SparkSQL so fast is even though you are “reading” from Hive or Impala tables, SparkSQL takes that query plan and runs your query as jobs on the raw files stored in HDFS; it does not go through Hive or Impala at all for data reads, rather it only uses the metadata from the tables for planning purposes. This is great for speed, but really bad for security – why? Because any user running a SparkSQL job needs underlying read access to the raw files in HDFS, no matter the policies configured on the Hive or Impala tables. We’ll refer to this as the “HDFS raw file read” problem.
More On the Solution
With Immuta, you can enforce all its advanced policies on SparkSQL raw file access. In other words, SparkSQL is still doing its raw read from the HDFS files AND enforcing the Immuta controls. This means you have the scale and speed of SparkSQL combined with the policy enforcement, entitlements and auditing provided by Immuta, thus solving the HDFS raw file read problem. The policy enforcement happens dynamically at read-time, there’s no need for pre-creating “anonymized versions” of data, which is a storage and ETL nightmare. Specifically, as the data is read through the Immuta SparkSQL context, the data is dynamically masked, redacted, and/or perturbed on-the-fly natively in Spark (no need for deamons running on HDFS nodes). No Hadoop out-of-the-box tools exist to dynamically enforce this type of control to enable Spark in highly regulated environments.
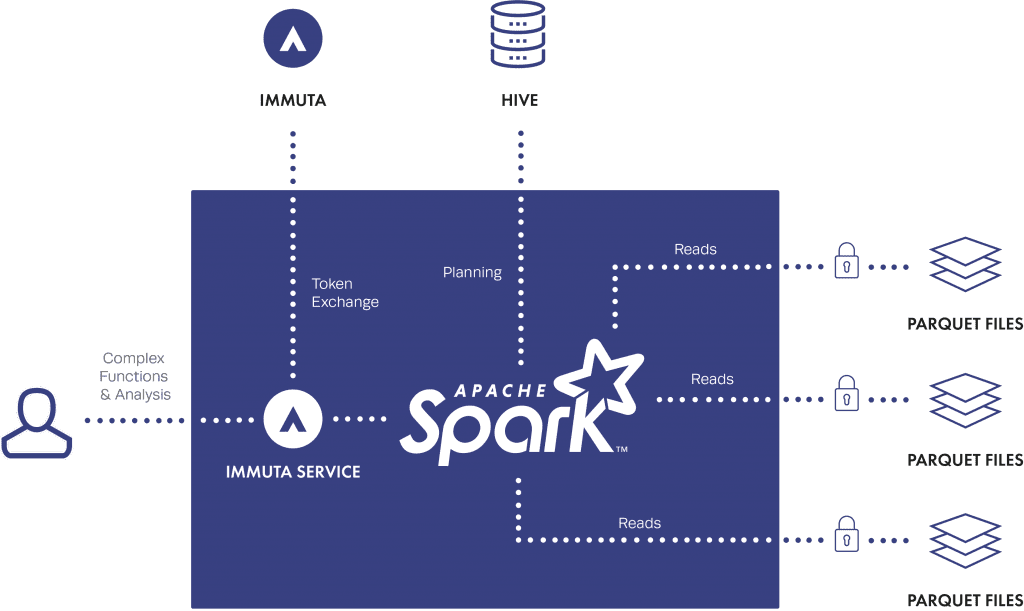
It’s also impossible for users to bypass the Immuta SparkSQL context. Once a file in HDFS is protected by Immuta, the Immuta SparkSQL context must be used to access that data (unless the user is configured as an ignored user in Immuta, such as an Administrator). Attempts to read files through the HDFS command line interface, or using the regular SparkSQL/HiveContext context will be denied. Note that it is also possible to control file-level access in Immuta which would allow MapReduce or Spark processing against the data.
Legal and Compliance
Immuta also has the compliance and legal users in mind with its features rather than just the database administrator and analysts. Immuta provides the ability for anyone to author data policies in natural language. The enforcement and legibility of the policies allows compliance and legal to not only understand exactly how policies are being enforced, but also can author the policies themselves easily. Policy authoring is quite burdensome in most Hadoop out-of-the-box tools, and unlike Immuta there is no concept of entitlement workflows to gain access to tables in those tools.
Also new to Immuta 2.1 is a report generation tool, this allows compliance and legal to generate common reports based on the Immuta audit logs rather than having to rely on IT to comb the audit logs. This is critical to prove compliance to outside auditors and regulations such as GDPR. This also includes notifications, both in the app and over email, to critical activities occuring in the platform, such as entitlement workflow actions, policy changes, and new data being exposed.
Demo
The following demo provides an overview of the features discussed above and a bit more details on the types of complex policies you can create in Immuta.