
Security is always a driving force, particularly for organizations making the move from on-premises Hadoop to cloud-based Spark providers such as Databricks where users outside of your organization (cloud provider and SaaS provider) need to be trusted. This massive shift to the cloud, with its security challenges, has been coupled with a rapid increase in privacy concerns.
According to Cisco’s 2020 Data Privacy Benchmark Study, “Over the past few years, data privacy has evolved from “nice to have” to a business imperative and critical boardroom issue.” Security and privacy are colliding in the cloud and creating new challenges – but also opportunities.
In that same Cisco report, organizations focusing on privacy:
- See “very positive returns on their privacy investments, and more than 40% are seeing benefits at least twice that of their privacy spend”
- Have “lower breach costs, shorter sales delays, and higher financial returns”
- “…receive significant business benefits from privacy (e.g., operational efficiency, agility, and innovation)”
While security and privacy do overlap significantly – without security, there is no privacy – there are distinct differences in how they are handled. Immuta’s native integration with Databricks lets organizations manage both security and privacy in Databricks in a scalable way for all data stakeholders.
To illustrate this, let’s focus on the newly enacted California Consumer Privacy Act (CCPA) which has several security and privacy measures. CCPA has been compared to Europe’s Global Data Protection Regulation (GDPR) and draws parallels to HIPAA Safe Harbor in terms of information masking.
Security: From CCPA: “1798.150: Any consumer whose nonencrypted and nonredacted personal information, as defined in subparagraph (A) of paragraph (1) of subdivision (d) of Section 1798.81.5, is subject to an unauthorized access and exfiltration, theft, or disclosure as a result of the business’s violation of the duty to implement and maintain reasonable security procedures and practices appropriate to the nature of the information to protect the personal information may institute a civil action”.
To boil this down: organizations may want to take measures to encrypt direct identifiers in-database on ingest (not to be confused with encryption at rest at the storage layer). This reduces the severity of security breaches and requires less trust for the cloud and database providers. Immuta allows the customer to do this, using their own encryption algorithms and encryption keys and dynamically decrypt on the fly based on Immuta policy. That decryption can occur on-premises while querying Databricks in the cloud, if desired. This results in the direct identifiers never being decrypted in the cloud and provides a strong security barrier for critical personal information (PI).
Privacy: Again, from CCPA: “1798.145(a)(5): The obligations imposed on businesses by this title shall not restrict a business’ ability to collect, use, retain, sell, or disclose consumer information that is deidentified or in the aggregate consumer information.”
This is the get out of jail free card – or put more appropriately, fair and ethical data processing. Should the organization de-identify the data well enough, it can be used outside the restrictions of CCPA for any purpose.
This is easier than it sounds.
PI is defined as information “that identifies, relates to, describes, is capable of being associated with, or could reasonably be linked.” Since the regulation includes terms like “associated with” or “relates to,” it is clear that PI extends beyond direct identifiers. The GDPR has similar language.
This means simply encrypting direct identifiers is not enough. You must also account for associated and related information of the user that could lead to their disclosure, known as a link attack.
Let’s say we had a table of customer loan information to include assets. You could potentially encrypt or mask the direct PI, but you also need to consider the other information related to the individual. Let’s say one customer in the data set owned a rare vehicle, such as a 1974 Volkswagen Rabbit. If an attacker knew who that person was, she could easily find their associated assets in the data using the VW Rabbit as the “link” to break privacy – a successful linkage attack. These indirect identifiers vulnerable to linkage attacks, like the rare vehicle, are termed quasi-identifiers.
To prevent privacy attacks, Immuta allows organizations to apply different levels of pseudonymization against quasi identifiers. Techniques such as generalization remove precision from numeric or timestamp values and K-anonymization supresses highly unique values like our 1974 Volkswagen Rabbit. Immuta can execute these privacy enhancing technologies (PETs) dynamically in Databricks – at query-time. This allows the organization to retain and utilize quasi-identifiers in Databricks and dynamically anonymize them based on who the user is and what they are doing.
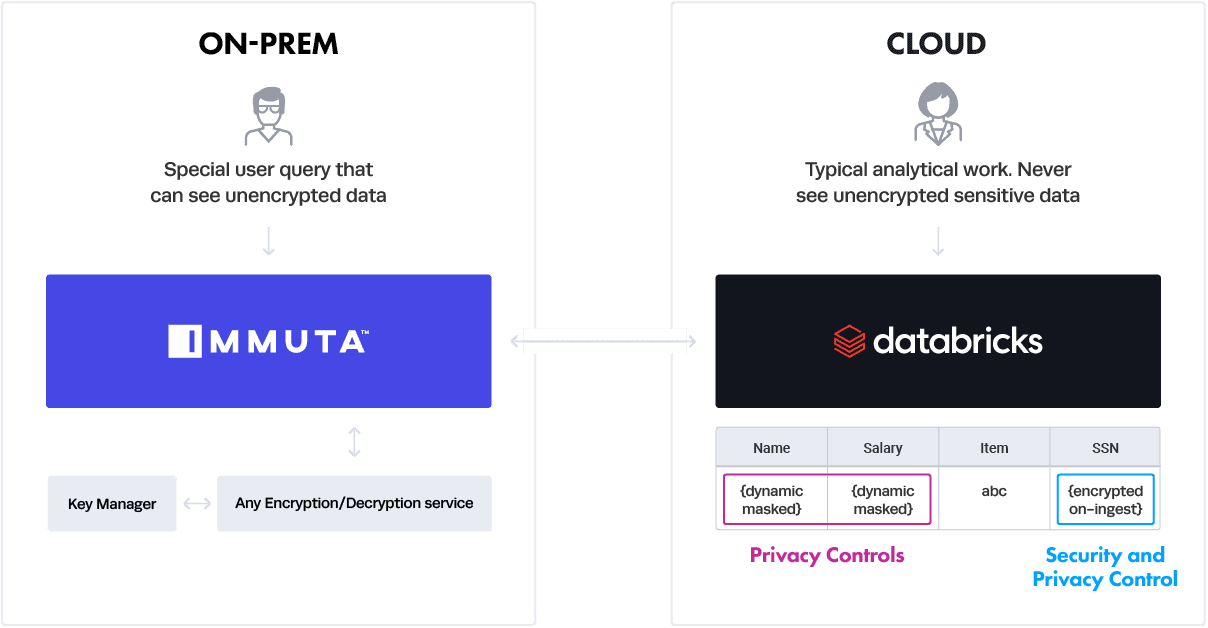
The above architecture diagram shows security and privacy controls in action across Databricks and Immuta. Fields such as Social Security Number (SSN) – a highly sensitive, direct identifier – are always encrypted on ingest to minimize the impact of a security breach. Analysts permitted to see SSN can view this data when necessary – without any additional approvals or manual manipulation of the data – based on a simple Immuta policy and the fact they are querying through the proxy, either on-premises or within their own VPC. The customer is also able to meet the de-identification demands of CCPA (or other regulations) in order to allow processing of the data collected on their data subjects by leveraging Immuta’s dynamic data masking techniques on quasi identifiers. This dynamic masking occurs natively in Databricks as the users query the data and there is no need for a proxy at all. Note that masking techniques can be done on direct identifiers as well, relieving the need for encrypting on-ingest. There are several functional benefits to taking this approach but it does have a security trade-off.
Taking this a step further, the organization can even apply dynamic masking techniques on top of the already encrypted data. For example, HIPAA Safe Harbor requires identifiers to be masked in an irreversible way – encryption alone isn’t good enough. Immuta would allow the organization to apply irreversible masking techniques on top of the encrypted data at query time to enable HIPAA compliant analytics on the data while still enabling the security measure of encrypting the data in-database.
Returning to our Cisco article, these measures should not be viewed as a barrier to data analytics. In fact, they are accelerants. With these controls in place, users can quickly access, analyze, and share data in a compliant way rather than requiring manual human approvals and long ETL processes to create “anonymized copies” of data for analysis.
Check out this quick demonstration to see our new native integration with Databricks in action:



