The data landscape is complex and always evolving – the sheer volume, variety, and velocity of data that organizations grapple with can be overwhelming. In response, data products have emerged as a structured, organized approach to harnessing data’s potential and driving business value.
However, the path to successful data product development and management has its own challenges. It requires a strategic mindset, a well-defined framework, and a commitment to continuous improvement.
Gartner outlined how to navigate the potential hurdles and implement a strong framework in its report, “Build Scalable Data Products With This Step-by-Step Framework.” The report emphasizes the need to shift from project-oriented thinking to product-oriented thinking, highlighting the iterative and user-centric nature of data product management.
In this blog, we will delve into Gartner’s framework, exploring each phase and providing practical guidance for data product owners, data stewards, and data governors. Following these steps, you’ll see how to put data products to work quickly, safely, and confidently – and start getting business results from your data.
The Pre-Work Phase: The foundation of effective data product management
Key Takeaway for Data Product Management: The pre-work phase sets the stage for the subsequent phases of development, ensuring that data products are aligned with business objectives, technically feasible, and user-centric. By investing time and effort in the pre-work phase, you can significantly increase the chances of delivering data products that meet user needs, drive business value, and stand the test of time.
—
As with any undertaking, thorough planning will separate a successful strategy from a failed one. When it comes to data product management, the pre-work is where the vision for the data product begins to come together, and potential roadblocks are proactively identified and addressed. Skipping or rushing through this phase may lead to costly missteps and delays down the line. Here are the steps involved in completing the pre-work.
Identify key roles and responsibilities
The first crucial activity in the pre-work phase is identifying key roles and responsibilities. The data product owner, acting as the orchestrator of the entire data product lifecycle, is critical in this stage. They verify that the product aligns with the organization’s strategic goals, coordinate cross-functional teams, and manage stakeholder expectations.
In addition to the data product owner, other key roles such as data governors and data stewards must participate in this stage in order to ensure smooth collaboration and efficient execution. You may also work with business and technology stakeholders, including data consumers, to make sure data products work across lines of business.
Define the scope
The next step is to define the scope of the data product. This involves identifying the target audience, use cases, and desired outcomes. Gartner advises against a “build it and they will come” approach – instead, you should understand the customer’s needs and pain points so that the data product delivers genuine value and addresses real-world challenges.
Articulating the scope also puts you in a position to accurately evaluate the data product’s effectiveness by setting measurable expectations from the outset.
Assess technical feasibility
To set yourself up for success and avoid frustration or delays in execution, assessing technical feasibility is another critical aspect of the pre-work phase. This involves evaluating the technical requirements, infrastructure, and tools needed to support the data product.
Factors such as scalability, security, and ability to integrate with your existing tech stack are all important to consider in this step. Having a realistic understanding of your organization’s technical capabilities will help you identify any potential gaps that need to be addressed.
Plan for packaging and delivery
The last step of the pre-work phase is to define the data product’s delivery and packaging models. This includes determining how the data product will be packaged (i.e. naming convention, description, quality score, and other relevant metadata), delivered (i.e. via data marketplaces, BI tools, etc.), and consumed by end-users.
The Gartner report highlights the importance of user experience, emphasizing that data products should be designed with the data consumer in mind. For instance, if your data product’s target audience leverages a data marketplace to find and access data, the marketplace should be a priority when planning the data product delivery model.
Planning and Design: Shaping the Data Product Vision
Key Takeaway for Data Product Management: The planning and design phase is where the blueprint for the data product is drawn. This is when you transform the initial concept of the data product into a tangible vision. In the planning and design phase, you’re tasked with developing a data product that’s not just innovative – it’s also feasible and aligned with your organization’s strategic goals and technical capabilities.
—
This phase is all about being realistic. Following the strategy you set out in the first phase is important, but doing so in a way that is actually achievable in practice will set you up for long-term success. Therefore, bringing cross-functional stakeholders into planning and design processes is critical to ensuring that your end product is viable – and more importantly, valuable.
Develop an MVP
The first step in the planning and design phase is to create a minimum viable product (MVP), a stripped-down version of the data product that is meant to deliver value without being fully developed.
The key to effectively using an MVP is starting small and iterating based on user feedback. This allows you to gain early validation of the concept, gather user feedback, and make informed decisions about the product’s future development – essentially testing the waters before diving headfirst into full-scale development. As a result, you’ll be better able to mitigate risks associated with the data product, and identify any gaps early on.
Design a blueprint
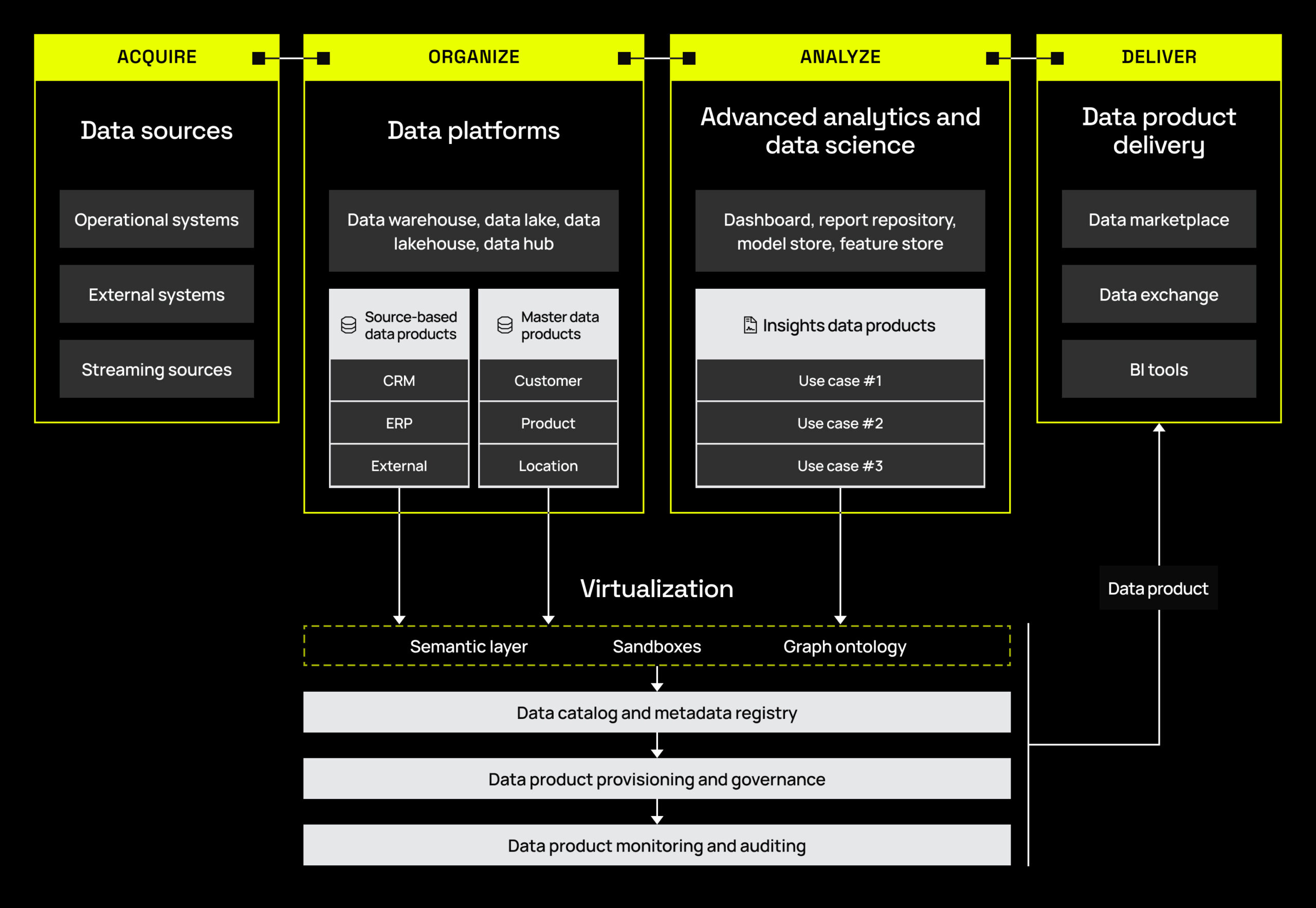
The next step is to design a data product reference architecture. This is the blueprint that shows how data products will operate within the ecosystem, including the necessary components, processes, and interactions.
Having a reference architecture is important because it serves as a guide for the development team, and ensures all stakeholders are on the same page about the products’ technical requirements and dependencies.
Here is an example of a data product reference architecture.
Assess data product types and organizational maturity
Choosing the right data product type is another critical decision in this phase. The report outlines three primary types, depending on the specific use case and your organization’s data maturity:
- Source-based data products integrate data from various sources, both internal and external. The key benefit is that you can immediately benefit users who already leverage these data sources, so it works well for organizations of any maturity level.
- Master data products offer a centralized view of critical business data related to customers, products, and suppliers, to name a few. They are a viable starting point because all organizations collect and use this type of data, but are particularly well suited for those that already have established data management practices.
- Insights-based data products deliver insights from data that are continuous, actionable, and meant to enable decision-making. They are often best for organizations on the more mature end of the data spectrum, and can be used across different business domains.
Finally, the planning and design phase involves assessing organizational maturity. This entails evaluating your company’s existing data governance, infrastructure, and technical skills, so you can identify any readiness gaps and set realistic expectations. The Gartner report underscores the importance of aligning data products’ complexity and sophistication with your organization’s existing capabilities, so you can build a data product that’s feasible to effectively implement and maintain.
Engineering and Operationalization: Making Your Data Product a Reality
Key Takeaway for Data Product Management: The engineering and operationalization phase is where the rubber meets the road in data product management. It’s about translating the blueprint from the planning and design phase into a functional and scalable data product. This phase demands technical expertise, meticulous execution, and a focus on data quality and governance.
—
This stage includes a combination of technical and conceptual tasks that will take you from vision to reality. Baked in is a fair amount of complexity, so it’s best practice to work hand-in-hand with data product owners, data IT teams, and data governors, so that all processes that are put into practice work as intended with existing infrastructure.
While these steps may involve systems or processes that are already in place, use this time to reevaluate established components to ensure they fit with your future vision.
Optimize data pipelines
Data pipelines are the lifelines of data products, responsible for ingesting, processing, and transforming raw data into usable formats. Optimizing these pipelines is crucial for ensuring that trustworthy data products are delivered quickly.
It’s critical in this stage to carefully assess data quality, integration techniques, and transformation processes to ensure that upstream checks and balances support downstream functionality and reliability.
The report also highlights the importance of choosing the right data types (structured, semi-structured, or unstructured) based on the specific requirements of the data product. For instance, source-based and master data products may primarily use structured data, while insights-based data products may ingest and analyze both structured and unstructured data.
Implement active metadata management
Metadata is the “data about data,” providing essential information about the data product’s content, quality, lineage, and usage guidelines. Active metadata management, through a metadata registry for instance, ensures that metadata is not just collected, but is also actively used to enhance the data product’s discoverability, usability, and reliability.
With a metadata registry, users can easily find, understand, and trust the data with which they are working. For data governors and stewards specifically, metadata helps determine what controls should be applied to the data, so that data product usage is authorized and compliant. This eliminates the need to manually inspect all data products, which in turn accelerates secure access.
Enforce data governance
Data governance is the framework of policies, procedures, and standards that ensure responsible and ethical data usage. In the context of data product management, it involves establishing clear rules and guidelines for data access, security, and compliance.
It’s critical to govern both the data included within the data product, and how the data product itself is put to use. This ensures that data products are not only valuable, but also trustworthy and compliant with regulations.
In whole, the engineering and operationalization phase is a critical juncture in the data product lifecycle. It’s where the vision takes shape and becomes a reality. By focusing on optimizing data pipelines, leveraging data virtualization as needed, implementing active metadata management, and enforcing data governance, you can build data products that are not only functional and scalable, but also reliable, high quality, and secure.
Packaging and Delivery: Deploying Data Products for End Users
Key Takeaway for Data Product Management: Effectively packaging and delivering data products is crucial for ensuring that they reach the right users – and more importantly, deliver value to them. The best-practice approach involves creating a data product template, choosing the right delivery method, implementing release management, and establishing a decommissioning strategy.
—
Let’s imagine that your data product is an app. You’ve spent time building, testing, and refining it, and now it’s ready for production – until you realize that you haven’t made a plan to publish them on the app stores. Sounds outlandish, right?
That’s because it is. Planning a delivery protocol for your product is one of the most essential steps in deploying and getting value from it – and that’s true whether “it” is an app, data product, or any other item or service. This stage requires its own planning and standardization for the entire data product lifecycle.
Create a data product template
Data product templates act as frameworks for delivering data products to users. In order to maximize utility for data consumers, these templates should include components such as a user interface design, key product feature descriptions, version number, tags, and intended use cases, among others. These components may also change depending upon whether the data product is intended primarily for internal or external use.
A data product template is important because it helps deliver a consistent user experience across an organization’s various data products. This makes data consumers more productive, streamlines processes for other data product stakeholders, and increases the impact that data products have on the business.
Choose the right delivery method
Data product managers must collaborate with data consumers to identify the most effective delivery methods for their data products. This may include internal data marketplaces, data exchanges, or business intelligence tools.
The choice of delivery method depends on the target audience, use cases, and business goals. For instance, a pharmaceutical company may leverage an internal data marketplace to develop new therapeutic products across its lines of business, while a cloud services provider makes its data products available in an external data exchange, so customers can pay a fee to use them across their own platforms.
Implement release management
Release management involves planning, scheduling, and coordinating the release of data products to end users. This helps make data consumers aware of new data products that they can potentially leverage by providing information about version control, testing, and deployment.
Effective release management ensures that data products are delivered in a timely and controlled manner, minimizing disruptions for users. It also allows you to keep tabs on how the data product has changed over time, ensure ongoing alignment with evolving organizational priorities, and track adoption.
Establish a decommissioning strategy
Identifying and deprecating data products that are no longer relevant keeps your data product ecosystem organized and efficient. This involves auditing data products to find those that are outdated or redundant, then properly retiring and disposing of them.
An often overlooked benefit of this step is that it makes more resources available for high-priority tasks. For instance, storage space can be used for innovative new data products, and data product owners can focus on more relevant initiatives.
Furthermore, just as shredding old documents helps you avoid losing track of your sensitive personal information, decommissioning old data products helps mitigate the risk of data exposure, breaches, or noncompliance.
By carefully considering these aspects of packaging and delivery, you can provide users with a seamless and valuable experience, ensuring that data products are accessible, user-friendly, and deliver on their intended value proposition.
Monitoring and Maintenance: Managing High Performance Data Products
Key Takeaway for Data Product Management: Monitoring data product performance is crucial for ensuring their quality, reliability, and optimization throughout their lifecycle. This involves implementing data observability, tracking performance, and gathering user feedback, so that the data products your organization builds and deploys deliver business value and results.
—
Once you’ve put in the work to build a valuable data product, it’s time to make sure it thrives in the real world. This is where ongoing monitoring and observation come in. Think of it as a regular health checkup for your data product, ensuring it operates effectively and continues to deliver value.
By keeping a close eye on how your data product is performing, you can identify potential issues, optimize performance, and ensure it continues to meet the evolving needs of your users.
Implement data observability
Data observability is key to keeping tabs on data products and ensuring that they deliver high quality and performance, and are reliable for end users.
With sound data observability practices in place, you are better able to track the health of data pipelines, data sources, and internal data infrastructure. This provides invaluable details about issues that could be impacting data product integrity, so that you can mitigate them and optimize data product performance.
Track data product performance
Monitoring and analyzing how your data products are performing helps you accurately assess user satisfaction, adoption, and overall impact of the data products. Approaching this step with a combination of qualitative and quantitative metrics will give you the best outcomes.
For instance, gathering feedback from users, analyzing usage patterns such as speed to access, and measuring KPIs relevant to a data product’s objectives will give you a holistic sense of whether or not a data product is providing business value. Gartner recommends leveraging the AARRR model, which measures effectiveness by rates of acquisition, activation, retention, referral, and revenue. Read more about it here.
Gather user feedback
Even data product owners can’t provide an accurate and objective assessment of how their data products work in the real world. For that, you need to solicit feedback from data consumers.
These end users can tell you how they access, share, and use data products, as well as the pain points they face in doing so. This will help you drive continuous improvement, optimize the user journey, and maximize the potential of your data products.
Regularly leveraging these steps throughout the data product lifecycle will keep your operation running smoothly and providing value, even as your organization grows and evolves.
Conclusion
Data product management is a critical discipline for organizations looking to put their data assets to work. By following a structured framework and adopting best practices, you can build and manage data products that deliver value, drive innovation, and support informed decision-making.
Regardless of what stage you’re at, remember that data product management is a journey of continuous improvement. Like most organizational priorities, once it’s implemented, it’s expected to evolve with the needs of the business.
By staying on top of industry trends, embracing new technologies like the Immuta Data Marketplace solution, and actively listening to user feedback, organizations can ensure that their data products remain relevant and impactful in the ever-evolving data landscape.
To see how to put data products to work using Immuta, try this self-guided tour.