Key Takeaways
- Data provisioning is the frontline of AI and analytics governance. It ensures that only the right data reaches models, dashboards, and business users — safely, efficiently, and compliantly.
- Operationalizing AI and analytics begins upstream. Governing the data pipeline via intelligent provisioning is key to embedding trust and compliance into every insight and decision.
- Legacy approaches to provisioning can’t keep up with AI demand. ETL pipelines and manual ticketing systems introduce latency and risk in environments that require real-time, scalable data access.
- Modern data provisioning must be metadata-driven, dynamic, and observable. Provisioning is about more than just enabling access. It works hand-in-hand with governance to control and monitor who gets what data, when, and why.
Technology is changing – and so is data use
Generative AI is no longer experimental. It’s powering product recommendations, fraud detection, customer service interactions, and internal copilots. But here’s the uncomfortable truth:
Most organizations still haven’t wrapped their arms around how AI systems use data, let alone access it.
In fact, 55% of data professionals say that their security strategy is failing to keep pace with the evolution of AI, and 39% report a shortage of skills needed to manage AI systems.
That’s why the success of AI projects and data initiatives depends on having a robust data provisioning strategy — one that makes governed, high-quality data available exactly when it’s needed.
What is data provisioning?
Data provisioning is the secure, policy-controlled delivery of data to consumers — human or machine — across data environments. It works hand-in-hand with data governance to ensure that the right data gets to the right users in as close to real time as possible.
Unlike traditional ETL, which is primarily focused on transforming and moving data, provisioning focuses on:
- Who is allowed to access the data
- What version or segment of the data they can see
- When and how they are granted access
- How that access aligns to governance policies
Consider a use case in which a data scientist is training a fraud detection model, and he only de-identified transaction data. Data is provisioned according to governance frameworks, with masking policies in place to ensure only the transaction data is exposed. This allows the data scientist to meet his objective, while adhering to compliance laws and regulations.
Why data provisioning, and why now?
The demand for real-time, governed data access has reached a tipping point: those who fail to enable it will fall behind those who implement an efficient, scalable solution.
With the right tools in place, data provisioning provides a streamlined path to make sure you’re the latter. And it’s now more important than ever because:
1. AI systems demand constant, contextual data
Every time an LLM writes code, an ML model predicts churn, or an image generator renders an ad, it consumes data. These systems don’t operate on a single, static dataset — they require continuous access to up-to-date, high-quality, and governed data to stay relevant and accurate.
Use case: A GenAI-powered customer support bot needs access to recent support tickets and product documentation. Real-time AI data provisioning ensures it only sees content classified as safe for external-facing applications.
2. Business users expect instant, self-service access
In today’s world, everyone from analysts to product managers is a data consumer. And they can’t wait weeks for approvals. They need a self-service way to request access to data, with approvals based on policies, not position in a backlog.
Use case: A marketing analyst wants to segment data by geography to analyze customer behavior. Automated provisioning ensures they can have self-service access to non-PII customer attributes while obscuring direct identifiers like email and phone numbers.
3. Regulatory standards are non-negotiable
GDPR, HIPAA, CCPA, and AI governance frameworks are not optional. Governed data provisioning provides both control and compliance by showing who accessed what data, under what policy, and for what purpose.
Use case: During a GDPR audit, a company shows that only authorized teams accessed European customer data, and all access was masked and timebound via provisioning logs.
Effective AI and analytics starts with data provisioning
Data provisioning is the mechanism that makes governed data available to AI systems and analytic platforms at scale. As AI adoption grows and analytics are embedded into every facet of every business, this means provisioning is not a nice-to-have — it’s foundational.
Here’s what goes wrong without an automated data provisioning workflow:
- A model trained on unfiltered PII creates blind spots and compliance risks.
- A dashboard pulls outdated or unauthorized data to generate a report.
- A BI tool shared across teams exposes sensitive data without appropriate redaction.
But, with robust provisioning:
- Models only ingest what they’re allowed to.
- Dashboards render based on the viewer’s access permissions.
- Data scientists work in secure sandboxes with policy-driven, purpose-based, and/or timebound access.
Use case: A financial institution provisions datasets for three audiences: risk teams get full transaction records; marketing sees aggregated insights; and AI development teams get masked training sets. Data is provisioned so that everyone gets what they need – no more, no less.
What makes a modern data provisioning system?
Let’s dig into the anatomy of an enterprise-grade data provisioning framework.
1. Automated data discovery and classification
Before a user requests access to a dataset, a modern data provisioning system must have a record of what data exists, where, and how it should be governed.
These systems must continuously scan data sources – including structured, semi-structured, and unstructured formats – to detect new datasets, profile their contents, classify sensitive attributes, and tag data, including for domain assignments (as shown below). This is key to eliminating blind spots and lays the foundation for automated policy enforcement.

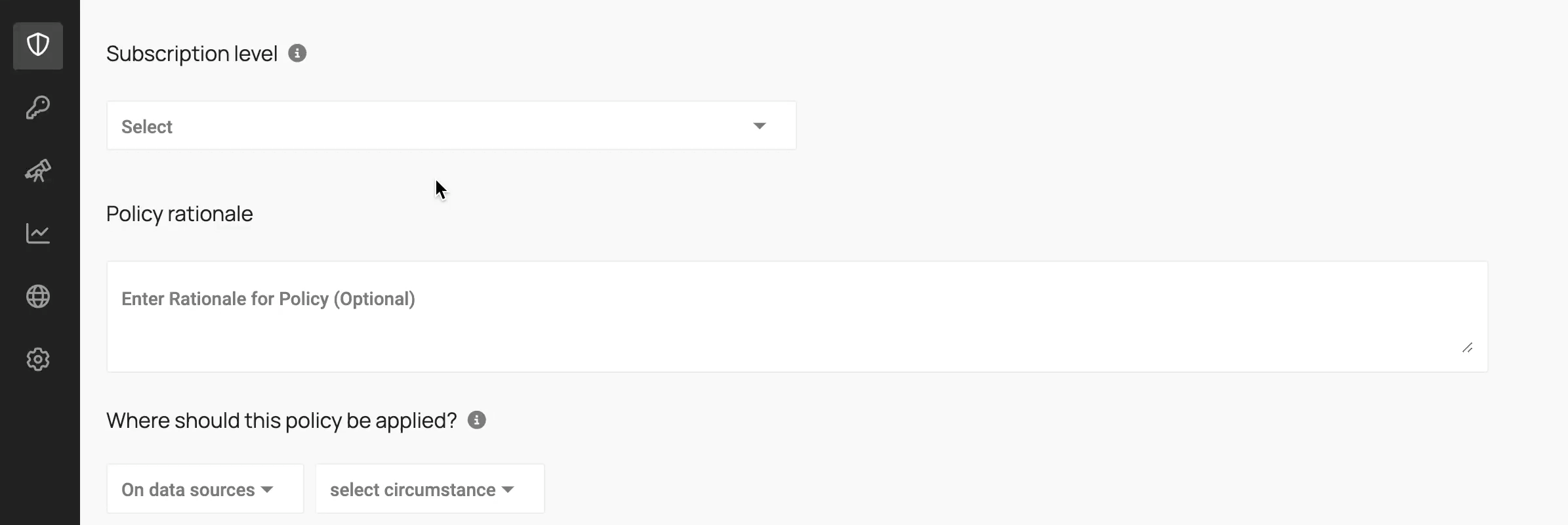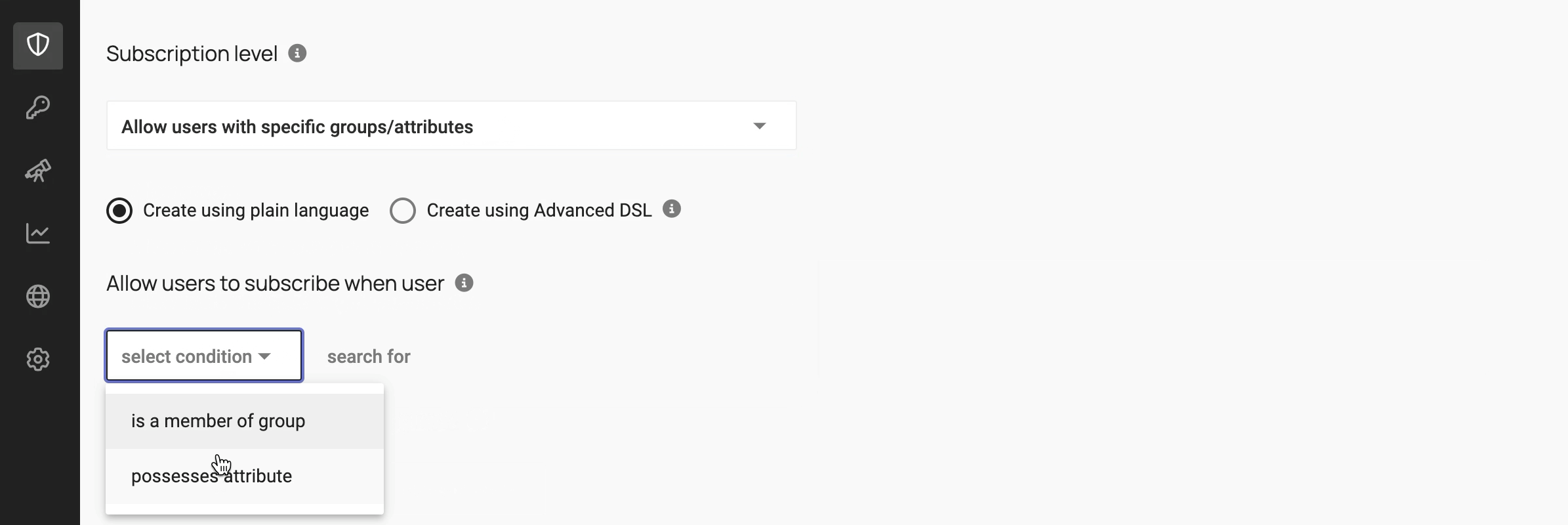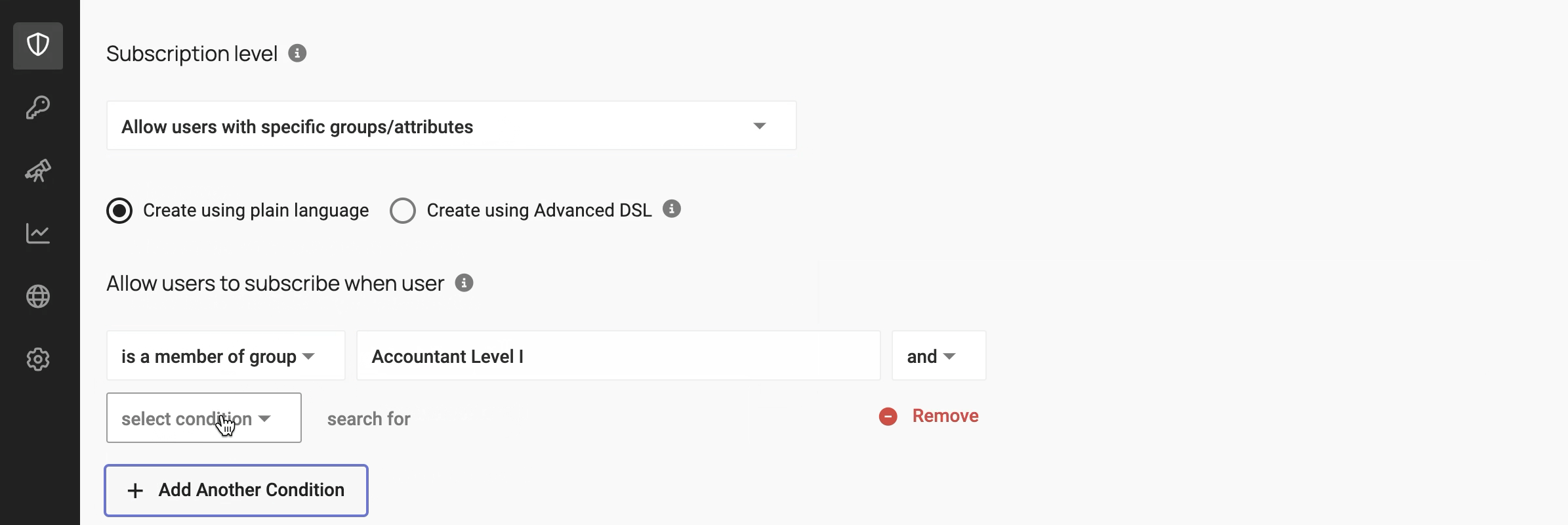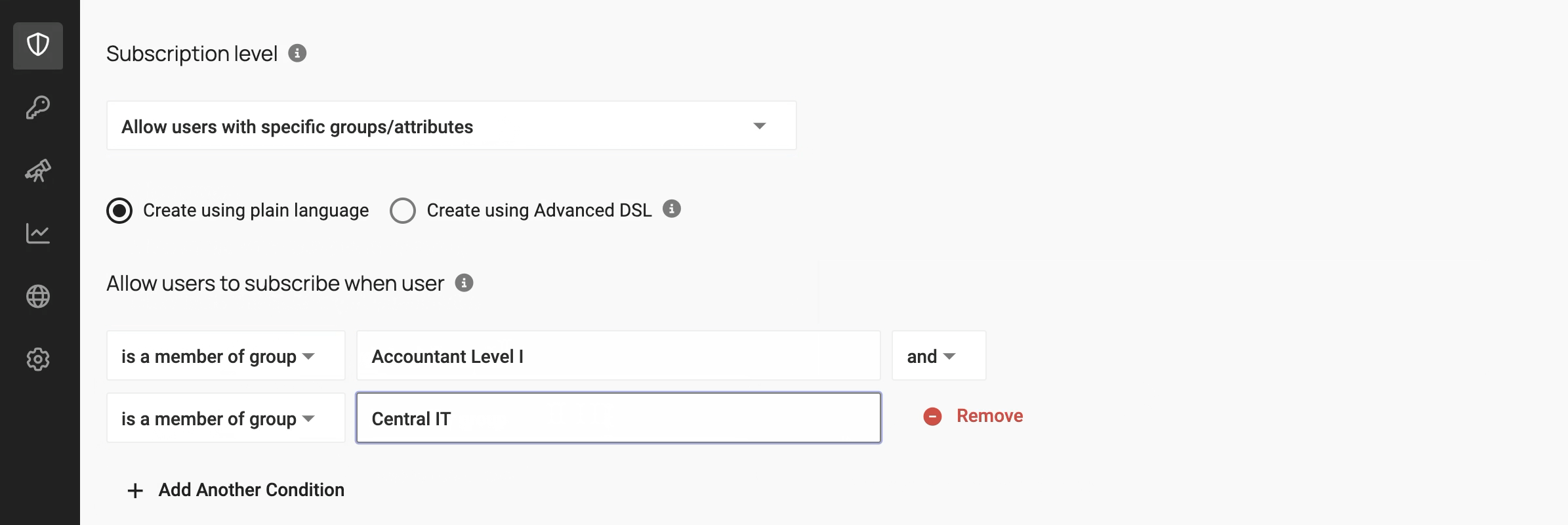
2. Metadata-driven policy engine
Data provisioning is powered by policies written against metadata: data classifications, user roles, purpose of access, and more. Think beyond “role-based” to attribute– or purpose-based access control.
The workflow below shows how to use metadata to write policies:
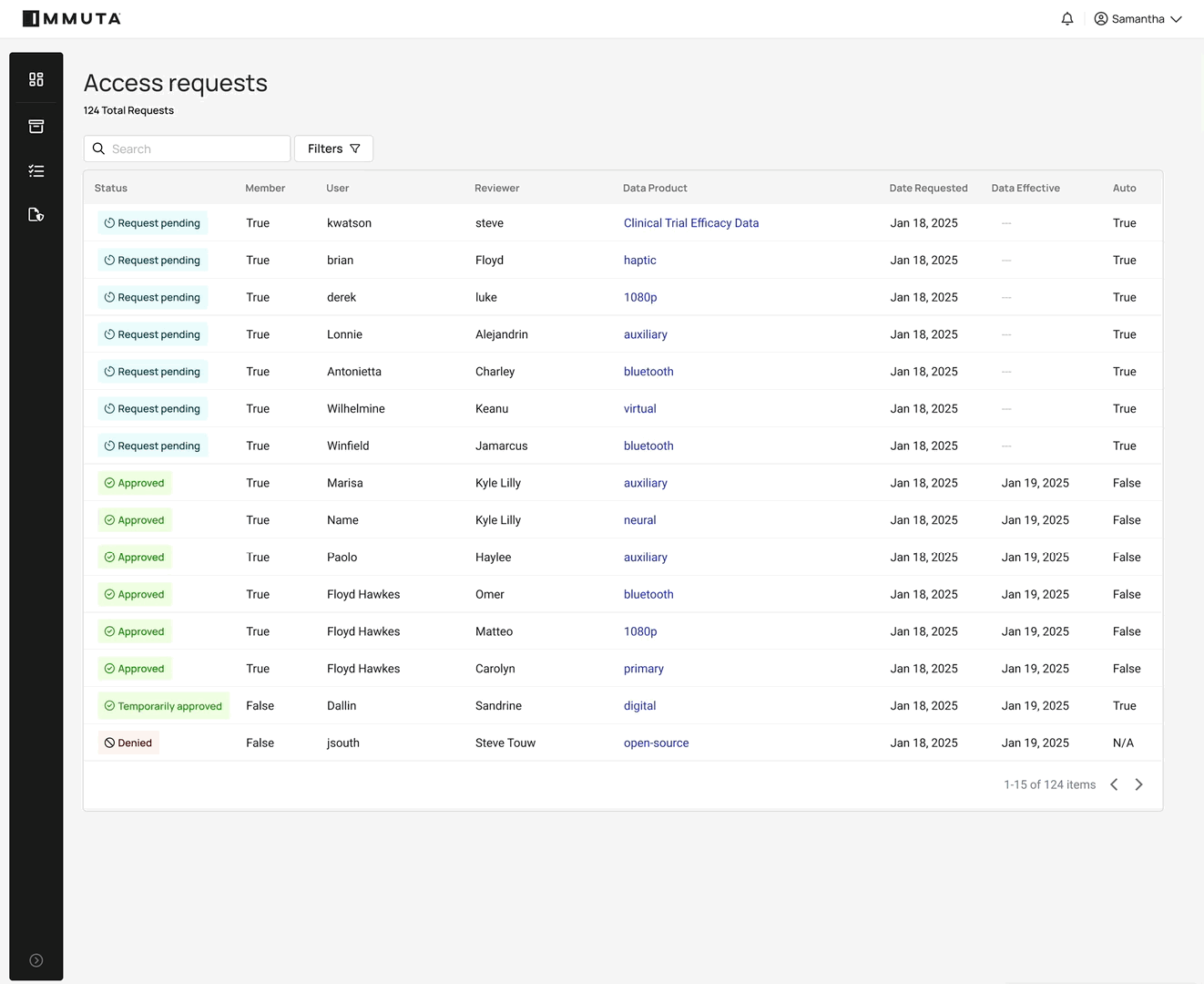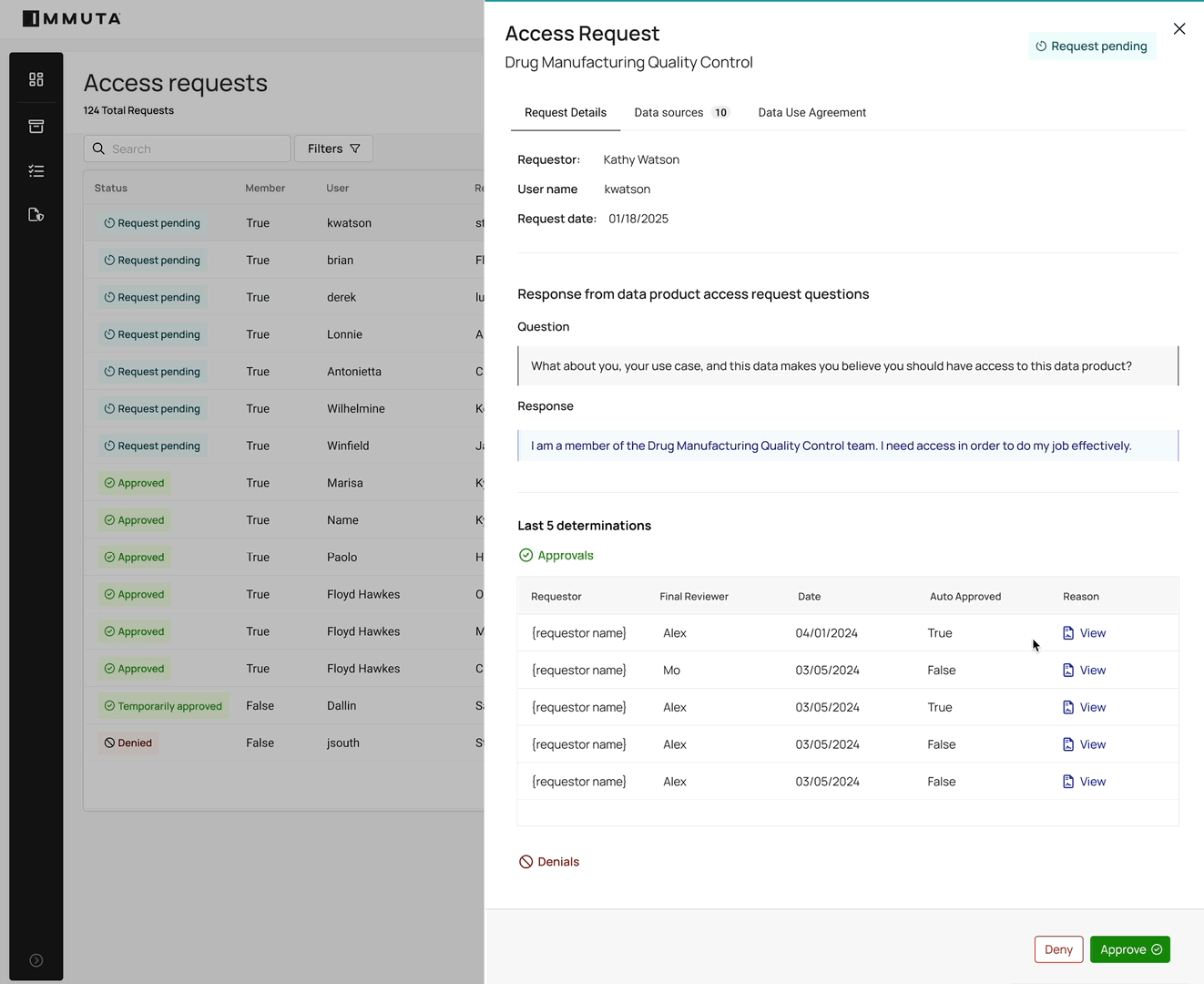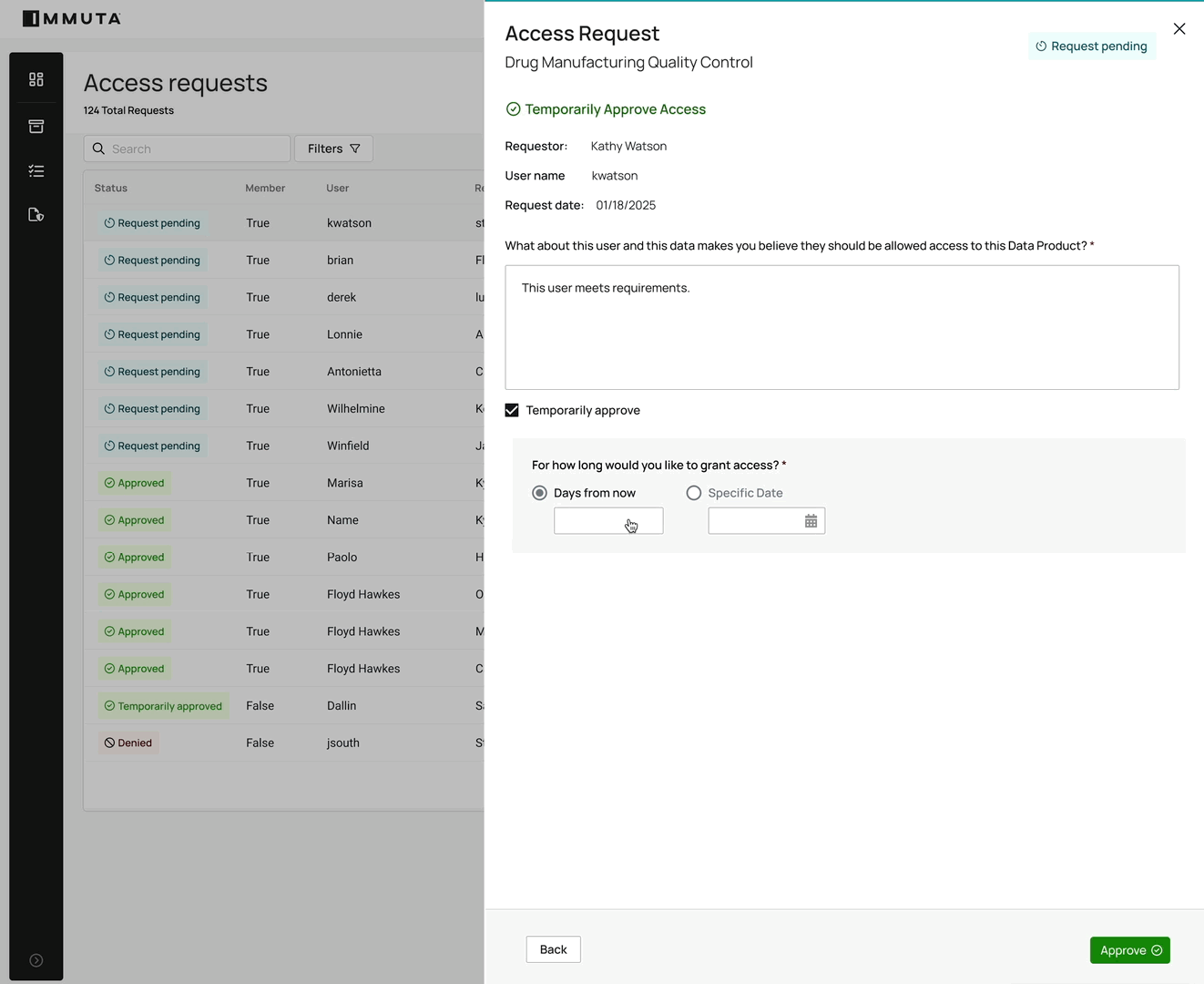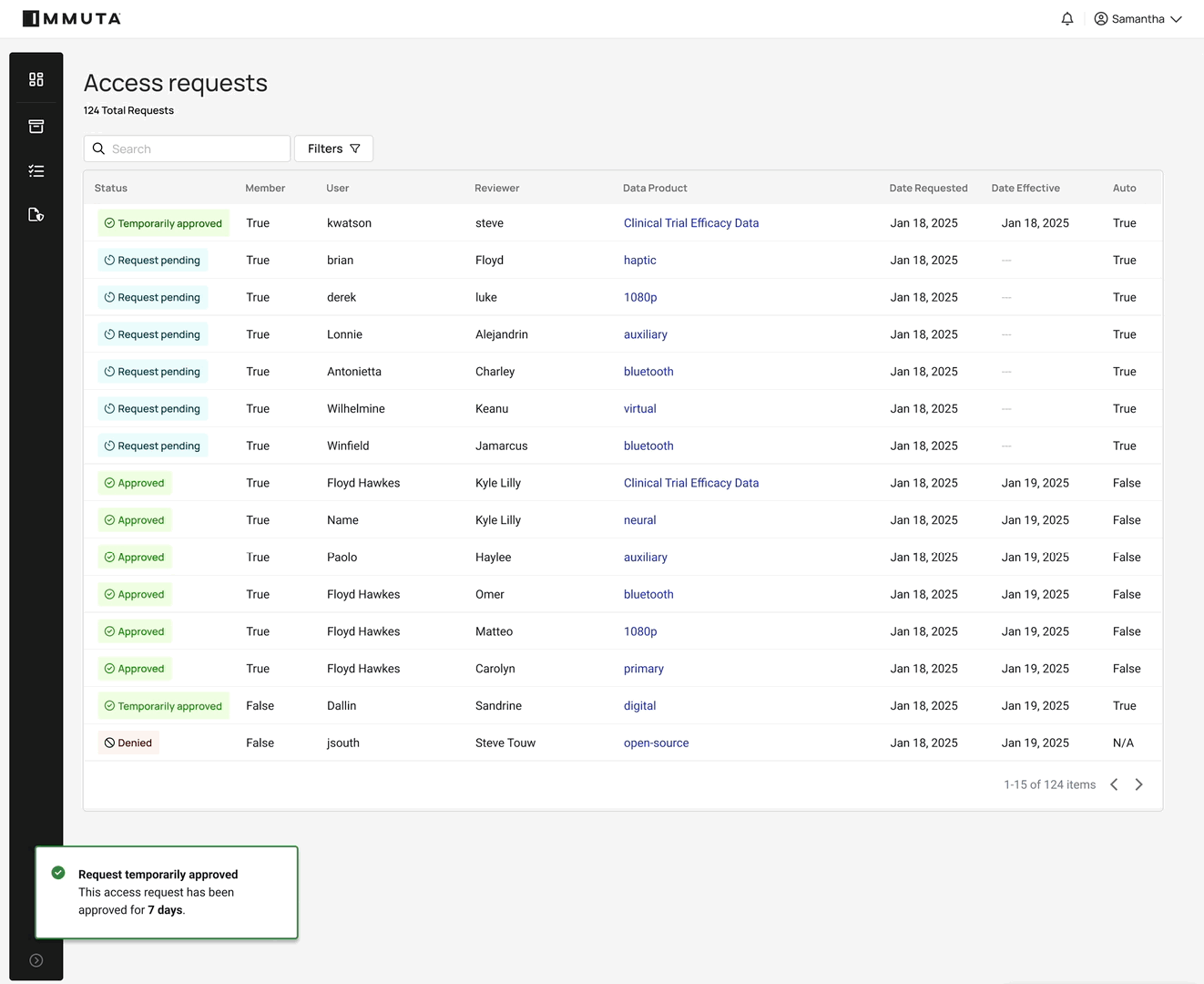
3. Immediate, timebound access
Automated data provisioning eliminates standing access and manual approvals of ad hoc requests. For the 37% of data professionals who wait at least a week to gain access after requesting it, this is a game-changer.
Users or systems request access and, if approved, policies dynamically grant it — immediately, and only for the duration needed. The workflow below shows how this works in practice:
4. Federated and multi-cloud reach
No two data teams are the same, and neither are their tools. Even within organizations, platforms may vary and governance may be handled on a department- or team-level basis. Data provisioning must therefore be platform-agnostic, so that policies are consistently enforced anywhere and everywhere data lives.
For example, the research arm of a global pharma company may have a division in the US that uses AWS, one in the EU that uses Databricks, and one in APJ that uses Snowflake. In order to enable efficient collaboration, the company must ensure that data is provisioned consistently across every platform in every division. A centralized policy enforcement engine with federated governance responsibilities is the most scalable, secure way to do so.
5. Auditability and observability
The data provisioning process isn’t over when the end user gets access. Every access event must be logged so data governance teams and auditors know who accessed what, when, why, and how. This visibility is critical for compliance, breach investigation, and governance reporting.
For organizations undergoing a SOC 2 audit, for example, producing logs showing that PII was only provisioned to authorized team members under approved policies is essential for ongoing compliance.
How to get started with data provisioning in 5 steps
Modernizing your data provisioning doesn’t require a massive overhaul. Here’s how to get started:
1. Audit your access paths and risk hotspots
Where is sensitive data exposed? What are the most common workarounds to access it? With 57% of data users resorting to quick fixes when they can’t access data through official processes, a strong provisioning strategy starts with finding out the answers to these questions and addressing them.
Map your current access methods — manual, automated, shadow — and identify gaps that could introduce risk.
2. Prioritize high-value, high-risk domains
Start with the data that’s both valuable and regulated. This may include customer, financial, health, or model training data.
Identify where this data lives, what restrictions must be put on it, and what regulatory requirements it is subject to so that you can adequately govern and efficiently provision it. You’ll get the fastest ROI and most impact with this approach.
3. Define and automate policies
Provisioning begins with governance. Governance begins with guardrails. Policies are those guardrails – you can’t provision data without them.
Translate governance and compliance needs into dynamic policies using metadata, attributes, and purpose or justification statements. These traits provide context that helps inform access decisions and automate provisioning, removing the burden on data governors and stewards to do so manually.
4. Implement monitoring and alerts
Continuously track data provisioning permissions and access activity to detect anomalies, like excessive access or policy violations. Set up alerts to ensure you are notified immediately of any questionable behavior, and integrate with SIEM tools if needed. This will help you proactively identify gaps in your provisioning strategy so you can address them and mitigate further risks.
5. Carve out space for AI agents
Whether you’ve already integrated non-human identities (NHIs) like AI agents, or are considering it for the future, now is the time to map out how to provision data to and through them – in a safe, governed manner.
Provisioning access to autonomous agents will likely look different than it does for human users, not to mention that the scale will be far greater. On the other hand, AI copilots will also be able to help make intelligent provisioning decisions to help take the load off of data governors and stewards.
As you establish data provisioning processes, be sure to keep these scenarios in mind so you can investigate and integrate solutions as soon as necessary.
Conclusion
Data provisioning may not be a new concept, but the way it’s being implemented is changing rapidly. To stay ahead of the growing need for real-time, scalable data access, you need to implement strategies now that ensure high quality, governed data can be provisioned as efficiently as possible.
To get our field CTO’s take on the debate between manual and automated data provisioning, check out this blog.
Data provisioning FAQs
Q: How does data provisioning differ from ETL or data integration?
A: ETL focuses on transforming and moving data between systems. Provisioning focuses on granting access to data – based on policy, context, and compliance – without needing to move or duplicate it.
Q: Can AI models and dashboards share the same provisioning layer?
A: Yes, and they should. Whether it’s a Tableau dashboard or an LLM, policies should extend across every data consumer, data source, and data platform.
Q: Can unstructured data be provisioned?
A: Yes. Data provisioning policies can be applied to logs, images, PDFs, and even natural language documents, which is especially important for GenAI use cases.
Q: How can I handle data provisioning in a multi-cloud or hybrid environment?
A: Use a centralized policy engine that can enforce rules across distributed data systems. This ensures consistency and auditability across environments.
Q: Is data virtualization part of provisioning?
A: It can be. Virtualization helps access data without moving it, while provisioning ensures only the right data is accessed, regardless of where it resides.