I’ve been having the same conversation for months now. Whether I’m in Hyderabad, London, or San Francisco, when I ask data leaders “How’s provisioning access to data going?” the response is universal: a groan, followed by “managing tickets is painful.”
And it is painful. One pharmaceutical giant told me they have eight data governors managing nearly 100,000 access requests per year. Eight people. More than one hundred thousand tickets. Do the math – that’s over 12,000 requests per person per year — and on some days, well over 100. It’s not sustainable, it’s not scalable, and it’s definitely not the future.
Which is exactly why we built a solution that is. And today, we’ve taken a big step toward that – streamlining data access with intelligent automation.
We've reached a breaking point
When we started Immuta, we recognized a fundamental problem: The people who understood data policies AND could write code to implement them were unicorns. If you were lucky, there were maybe a handful in any enterprise. That was the first crack in the traditional model.
But the real breaking point? The GenAI boom changed everything.
Suddenly, the technical barrier to data consumption was gone. Before, maybe you had 1,000 or 2,000 people in your organization who could write SQL. Now? Anyone can prompt AI to write code and analyze or access data through a dashboard. We’ve gone from thousands of potential data consumers to hundreds of thousands – overnight.
The old model of manual reviews, ticket systems, and governance meetings wasn’t built for this. You can’t have a governance team of 10 people processing thousands of tickets through meetings and emails. As we saw earlier, the math doesn’t work.
From human-driven to software-enabled
Here’s what most people get wrong about where we’re headed: this isn’t about replacing governance. It’s about fundamentally shifting from human-driven operations to software based, AI-powered workflows and automation.
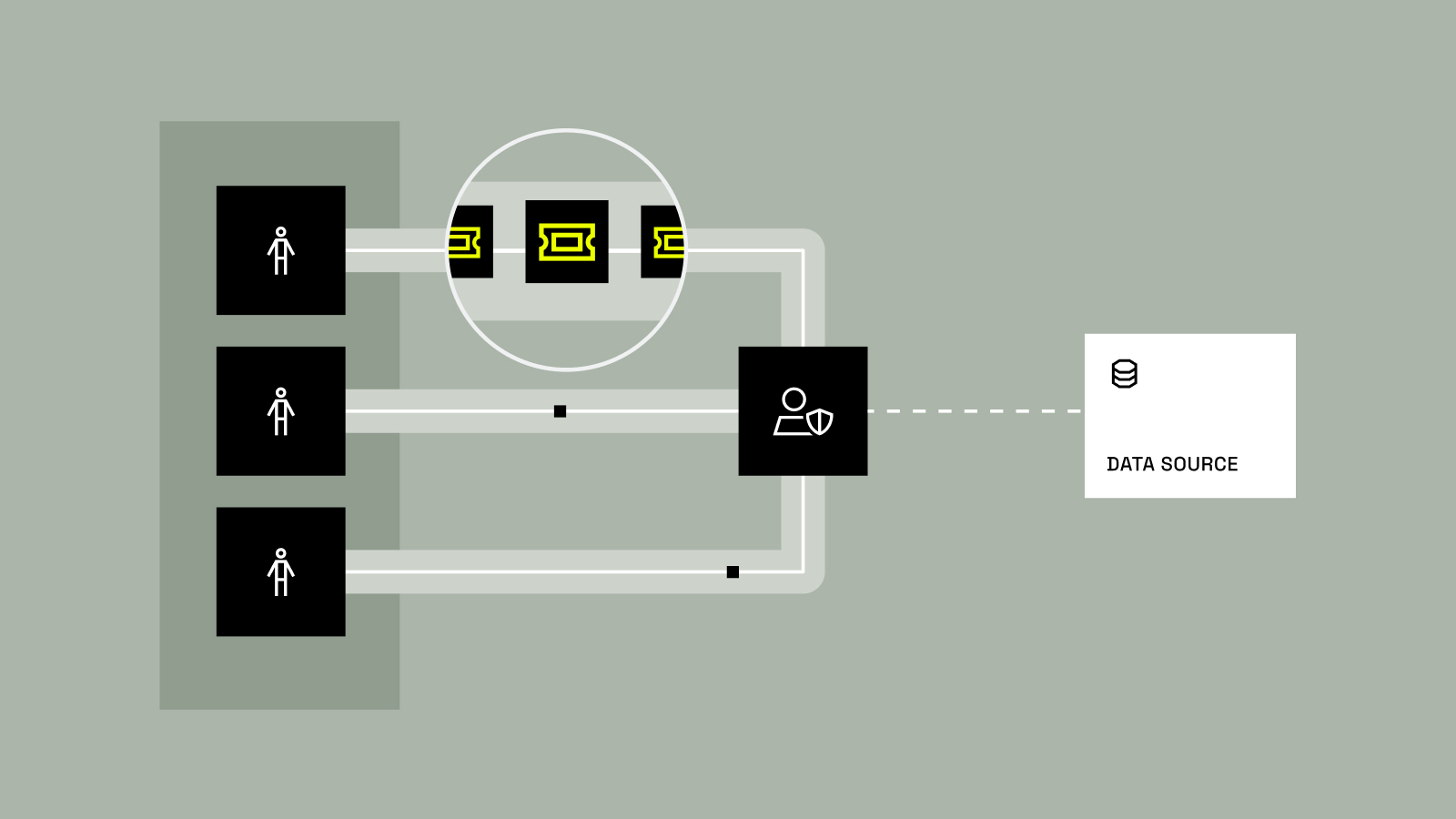
Today, data access looks like this: You write up a requirement. IT and governance get together to codify it. Governance is assigned a ticket, security is assigned a ticket, IT is assigned a ticket. They meet, build requirements documents, go off and do their tasks, check back in, have more meetings, and maybe – finally – you get access to the data.
Weeks or even months later.
What if you could discover the data you need, request access with a clear justification, and if there are existing policies blocking your access, request specific exceptions? What if the right approver could just click a couple of buttons and be done, rather than having to chase down details about your request? What if data access took moments, not months?
When I describe this to customers, their first reaction is always: “I don’t believe it. That doesn’t exist.”
But it does. And we’re shipping it today.
A major step toward intelligent data provisioning
Today, we’re announcing three industry-first AI capabilities in the Immuta AI layer that move us from that painful, manual world to an intelligent, automated future:
Review Assist automatically classifies every data access request as low, medium, or high risk based on historical data patterns, user roles, and policy sensitivity. But here’s the key – it doesn’t just give you a risk score. It provides an AI-generated rationale explaining exactly why that request received that classification.
Think about our pharma customer with eight governors and 100,000 requests. With Review Assist, they can now filter to see 500 low-risk approvals, review the AI’s reasoning, and approve them in bulk. What used to take days now takes minutes. Our platform learns from every approval and denial, getting smarter about what constitutes acceptable risk in your specific environment. It considers factors like the requestor’s role, historical access patterns, and data sensitivity levels, as well as the business context of the request. The result? Recommendations that are consistent, accurate, compliant, and refreshingly free of toil – and give data governors confidence that their decisions align with their peers’.
This isn’t just automation – it’s intelligent augmentation that makes your governance team exponentially more effective while maintaining the oversight and control they need.

Masking Exception Requests solves another massive friction point. Users can now see exactly which parts of a dataset are masked by policy, and submit targeted requests – accompanied by a clear business justification – to unmask specific data. No more guessing. No more back-and-forth. Just transparency and context for fast, informed decisions.
In a typical scenario, users request access to an entire dataset only to discover it’s heavily masked–forcing them back into the ticket queue. With data unmasking requests, they can now see the masking upfront and request precisely what they need. The system shows them sample data with masking applied, explains which policies are causing the masking, and lets them request specific exceptions with a business justification. Approvers see exactly what’s being requested and why, with full context about potential impact.
This targeted approach reduces approval times from weeks to hours, while actually improving security posture by ensuring users only get access to the minimum data they truly need for their specific use case. It also enables teams to publish a single version of a data product while managing exceptions at a granular level–no forks, no duplications, just smarter control.
Support for third-party agents via Model Context Protocol (MCP) is where things get really interesting. We’ve made it possible for AI agents and assistants to request and manage data access directly in the Immuta Platform, leveraging our risk analysis to make real-time provisioning decisions. This is critical because it enables seamless integration between AI agents and your data governance infrastructure through the Model Context Protocol (MCP).
When agents need data access, they can now programmatically request it while providing context about their task and requirements. The system leverages the risk scoring and analysis from Review Assist to help automate these decisions, reducing the need for human intervention on routine requests. For appropriate low-risk scenarios identified by our AI layer, agents can receive faster approvals – or help data governors filter and triage requests more efficiently, offering additional insight into how to handle them without the delays of manual review.
This integration enables data provisioning to scale with your AI initiatives. As agent usage grows, the system can keep pace without overwhelming your governance team. The result is a foundation that bridges today’s enterprise governance needs with tomorrow’s agentic workflows, ensuring your AI agents can access the data they need while maintaining the proper oversight and compliance.
Agents will be here sooner than you think
Here’s my prediction: by June 2026, the agentic revolution in data access will be at full production scale.
I’m being precise about this timeline because I see what’s happening. Major players are building agent capabilities, pushing out development tools that cater to them, and partnering for broad-scale agents.
In a year, your average employee won’t have one or two dashboards – they’ll have 10, 15, maybe 20 agents working for them. If you have 100,000 employees each with 10 agents, you’re looking at a million data consumers in your enterprise. And these aren’t patient humans who will wait weeks for access. They’re software agents that expect millisecond responses.
This changes everything about how we think about data provisioning. We have to move from deterministic, rules-based to non-deterministic risk-based decisions.
Humans grow up with rules. Our parents set rules. Schools have rules. Companies have policies. But software doesn’t think that way. Software has a task to accomplish. It thinks in terms of risk trade-offs.
When an agent says, “I can’t get a count on this masked column, and I need it to perform this task,” we need systems smart enough to evaluate:
- Can we provide format-preserving encryption instead?
- What’s the actual risk?
- Do we need human oversight for this specific request?
Data provisioning is becoming an actuarial science – quantifiable, automated, and intelligent.
How to move toward agentic provisioning
If you’re leading data governance efforts and still operating with the legacy models I called out earlier, here’s what you need to do:
- Define your domains and subdomains. Who owns the data?
- Establish approval workflows. Who needs to approve access?
- Simplify data sensitivity classification. Take a red, yellow, green approach. Simplify it.
Focusing on these three steps is a significant leap forward in maturity. You’ve just built the framework to automate data access and move away from mundane tickets and human-driven processes.
The choice is simple: keep drowning in tickets, burning out the governance team, and watching innovation stall as requests pile up. Or, embrace software-enabled provisioning that’s intelligent, automated, and built for the scale that’s coming.
Read more.
Learn about Immuta AI features.



