
If you’ve ever struggled to balance fast data access, compliance, and governance, you’re not alone. Sixty-four percent of data teams face significant challenges provisioning real-time access to data consumers, and 62% say data governance processes are to blame.
As more users – and AI agents – become empowered as data consumers, approvers have reached a tipping point. How can they keep up with an exponentially greater volume of requests without either creating risk or delaying access?
Immuta’s integration with Databricks Unity Catalog makes it possible to achieve both: fast data access to data and strong governance. In this blog, I’ll show you how to put this into action with a step-by-step guide to:
- Defining data domains to streamline federated governance
- Automating data discovery and classification to accelerate data provisioning
- Creating and enforcing scalable, dynamic access policies
- Building data products that maximize value and foster collaboration
- Continuously refining governance and provisioning through iteration and insight
A primer on Immuta’s native integration with Unity Catalog
Before diving in, it’s essential to understand how Immuta works with Databricks Unity Catalog.
Unity Catalog is Databricks’ unified governance solution for all data assets, including files, tables, machine learning models, and dashboards. It provides a centralized metadata layer that simplifies governance across your data lakehouse for both structured and unstructured data.
Immuta builds on these capabilities, providing a centralized data governance and provisioning hub that connects directly to Unity Catalog. With Immuta, you’re able to:
- Manage policies centrally while leveraging Unity Catalog metadata and lineage
- Accelerate access to Databricks data with automation and dynamic controls
- Focus on delivering value instead of wrestling with complex, manual workflows
Step 1: Define data domains to scale governance
In large organizations, organizing data into data domains is a best practice for scalability. A data domain groups data by business function, project, or type. This allows data management responsibilities to sit with specific business units or subject matter experts, which reduces the burden on centralized IT teams.
In Immuta, you can create data domains that mirror organizational structures, then delegate policy management to domain owners while maintaining centralized oversight.
Data teams that use a domain-based governance approach are able to:
- Simplify policy management: Policies are customizable per domain, adapting to the unique compliance needs of different teams or data categories.
- Delegate clear ownership: Assigning domain owners – who are often closest to the data to begin with, which promotes accountability and faster responses to governance issues.
- Scale effectively: As new data assets are added, they automatically inherit domain policies, ensuring consistent governance at scale.
Let’s look at how you can create a domain in Immuta and set the foundation for faster, more consistent access decisions.
Step 2: Automate sensitive data discovery
Once you’ve logged in to your Databricks and Immuta platforms, the first step to provisioning secure access is knowing what data needs to be governed in the first place. It may seem obvious, but this is one of the most time-consuming and error-prone aspects of data governance. If one data asset falls through the cracks, the ripple effect could be devastating.
Immuta’s automated data discovery drastically reduces this burden by:
- Scanning data assets: Immuta connects directly to your Unity Catalog metadata, and scans registered tables and files for sensitive information patterns.
- Identifying sensitive fields: Using advanced algorithms and predefined data classifiers, Immuta detects PII, PHI, and other types of sensitive data.
- Tagging and classifying: Once detected, Immuta tags and classifies sensitive fields, making it easy to apply targeted policies.
Automation ensures your governance policies are always based on accurate, up-to-date data classifications, reducing risk and improving compliance with regulations such as GDPR, HIPAA, and CCPA.
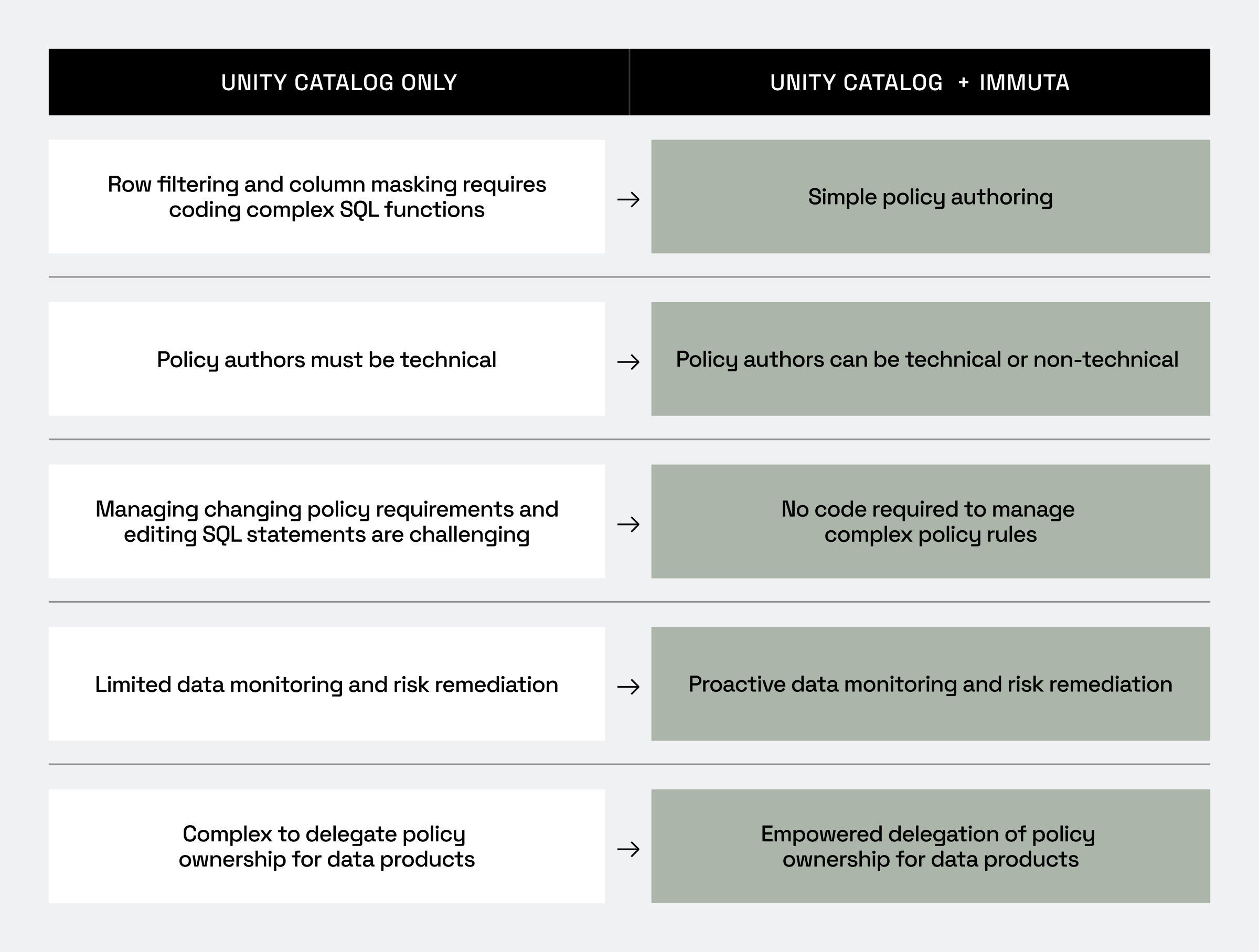
Step 3: Create dynamic policies to provision access
For the enterprise organizations that rely on Databricks to power their data and AI initiatives, static controls no longer cut it. Our partnership with Databricks was based on this premise: You can’t provision data efficiently or scalably using rigid, outdated policies.
Immuta’s dynamic policies are enforced at query runtime, enabling real-time, context-aware authorization based on various user and data attributes – not solely on user roles. And since policies can be authored as-code or in plain language, technical and non-technical users alike can create and manage them.
Here’s how to create dynamic policies for in Immuta that are directly applied via Unity Catalog:
- Define attributes: Import or sync user metadata such as department, role, clearance level, and geographic location, as well as data metadata, such as sensitivity level and format.
- Set policy conditions: Create policies that grant or restrict access based on these attributes. For example, only users in the finance department can access financial data. You’re also able to have users acknowledge usage purpose statements (i.e. for HIPAA and GDPR compliance), and set time-bound approvals for temporary access needs.
- Apply data masking and row-level security: For highly sensitive data, leverage advanced techniques like data masking or restricting specific rows based on user context. This helps ensure that users aren’t fully blocked from certain datasets, but that data isn’t over-provisioned and inappropriately exposed.
- Test and validate: Verify that your policies behave as expected before deployment.
Dynamic policies reduce the need for manual approvals and help your organization maintain compliance effortlessly, even as users and data evolve. And with Immuta Copilot, you’re able to enter a text-based prompt that is transformed into a policy using embedded AI capabilities.
Step 4: Build data products for enhanced collaboration
Enabling your teams to quickly access and share the data they need is crucial for driving business value and maximizing Databricks ROI. Immuta empowers data owners to create curated data products that are discoverable, governed, and accessible.
You can create data products in Immuta by:
- Selecting data assets: Choose tables or datasets from Unity Catalog that you want to package as a product.
- Apply governance policies: Attach the appropriate access controls, masking rules, and audit logging.
- Define metadata and documentation: Add descriptions, tags, and usage guidelines to help consumers understand the data product.
- Publish and promote: Make the data product visible within the Immuta marketplace so authorized users can easily discover and request access to it.
By circulating data products via a data marketplace, you create a self-service environment where data consumers can find trustworthy data products quickly, accelerating analytics and innovation.
Step 5: Continuously iterate and optimize
Practical application and ongoing dialogue are key to mastering data governance. Engaging with real-world use cases helps you understand how to tailor policies and workflows to your unique organizational needs.
When implementing Immuta with Databricks, consider scenarios such as:
- Regulating access to customer PII across marketing and sales teams.
- Ensuring compliance with HIPAA for healthcare data shared among researchers.
- Managing data access for global teams with varying regulatory requirements.
Soliciting feedback from other data experts and governors – both internally and externally – allows you to ask questions, share challenges, and learn from peers. This continuous learning approach ensures your governance strategy remains effective and adaptive.
Accelerate your data governance journey with Immuta and Databricks
Amid an influx of data users and demands, managing data governance and provisioning at scale is not an option – it’s a mandate. But, it doesn’t need to be a daunting task thanks to Immuta’s native integration with Databricks Unity Catalog.
By automating sensitive data discovery, structuring governance through data domains, enforcing dynamic policies, and creating accessible data products, you can empower your organization to put more Databricks data to work while maintaining strict compliance and oversight. Whether you’re just starting or looking to enhance your current workflows, embracing these best practices will help you build a resilient data governance framework that scales with your business.
Ready to take the next step? Dive in, experiment with the tools, and watch how streamlined governance can drive secure access and innovation across your organization.
More about Immuta + Databricks.
Take a closer look at provisioning data access for Unity Catalog.



