As cloud data platform adoption accelerates and organizations become more reliant on data, teams using Databricks as the primary platform for ETL and data science must have a tool that enables dynamic data masking across Databricks and any other platform in their data stack. This article will walk through how Immuta delivers on this need with centralized, universal data access control, sensitive data detection and classification, and consistent data masking.
Regardless of what technologies you use, these concepts apply across cloud services such as Snowflake, Starburst, Amazon Redshift, Azure Synapse, and others, in addition to different relational databases hosted in AWS, Azure, or GCP.
Databricks Data Masking for Sensitive Data
Let’s assume that you have been asked to mask all personally identifiable information (PII) data in Databricks and across the cloud data ecosystem, which can be hundreds or thousands of tables. However, you also must include an exception for the HR department to see PII.
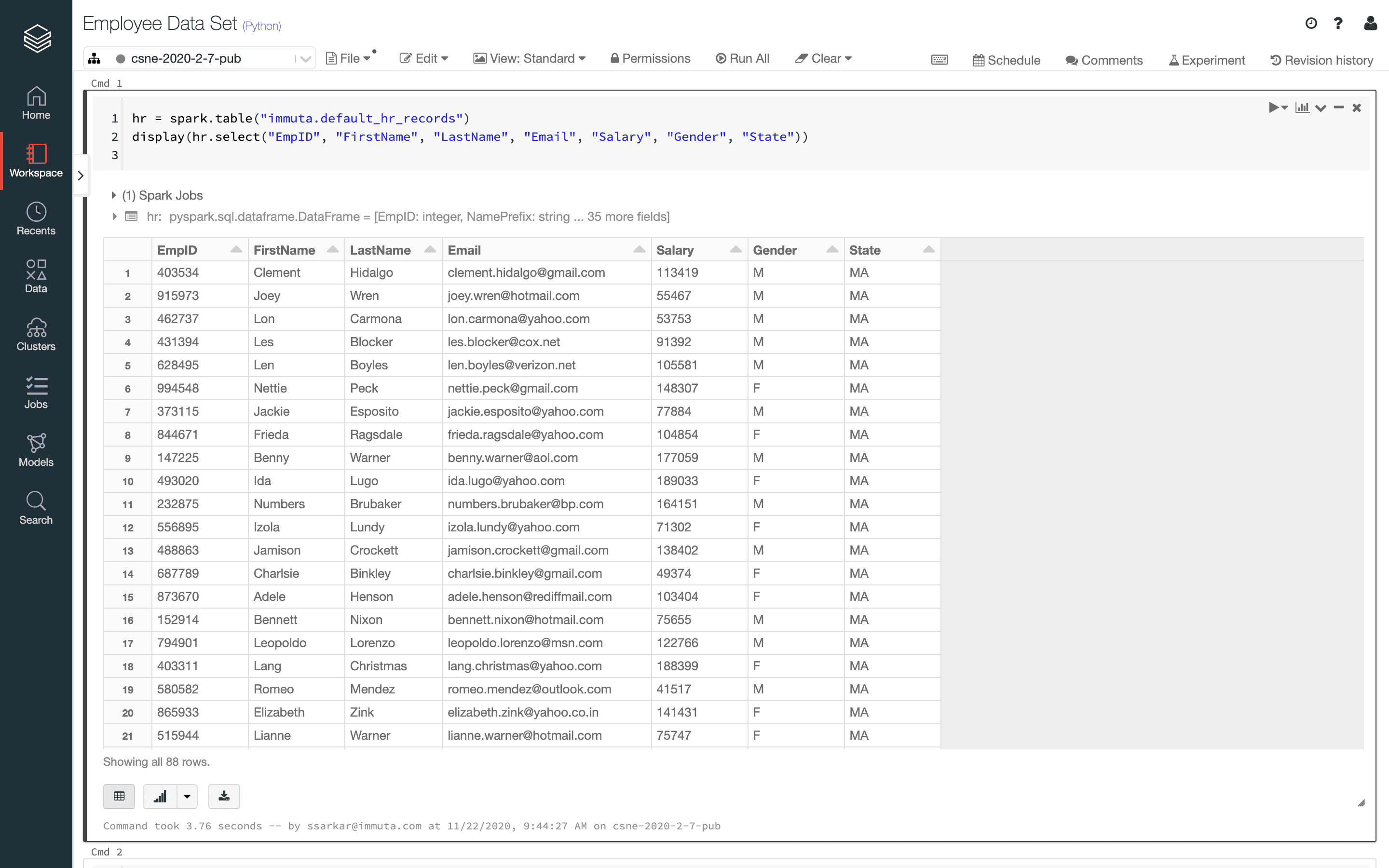
If you query the data from a Python notebook in Databricks, you can see some of the PII data, which is a mix of indirect identifiers, such as gender and state, and direct identifiers, such as name and email address. Running a query on another platform might also return results with direct and indirect identifiers.
To fulfill the request, you must identify and mask all of this PII data consistently across Databricks and any other platform that you may have or add to your tech stack.
Automate Sensitive Data Discovery & Classification

Immuta provides sensitive data discovery capabilities to automate the detection and classification of sensitive attributes across Databricks and your entire cloud data ecosystem. After registering data sources with Immuta, the catalog will standardize classification and tagging of direct, indirect, and sensitive identifiers consistently. This enables you to create policies in a dynamic and scalable way across Databricks and other data platforms.
Consistent Databricks Data Access Control
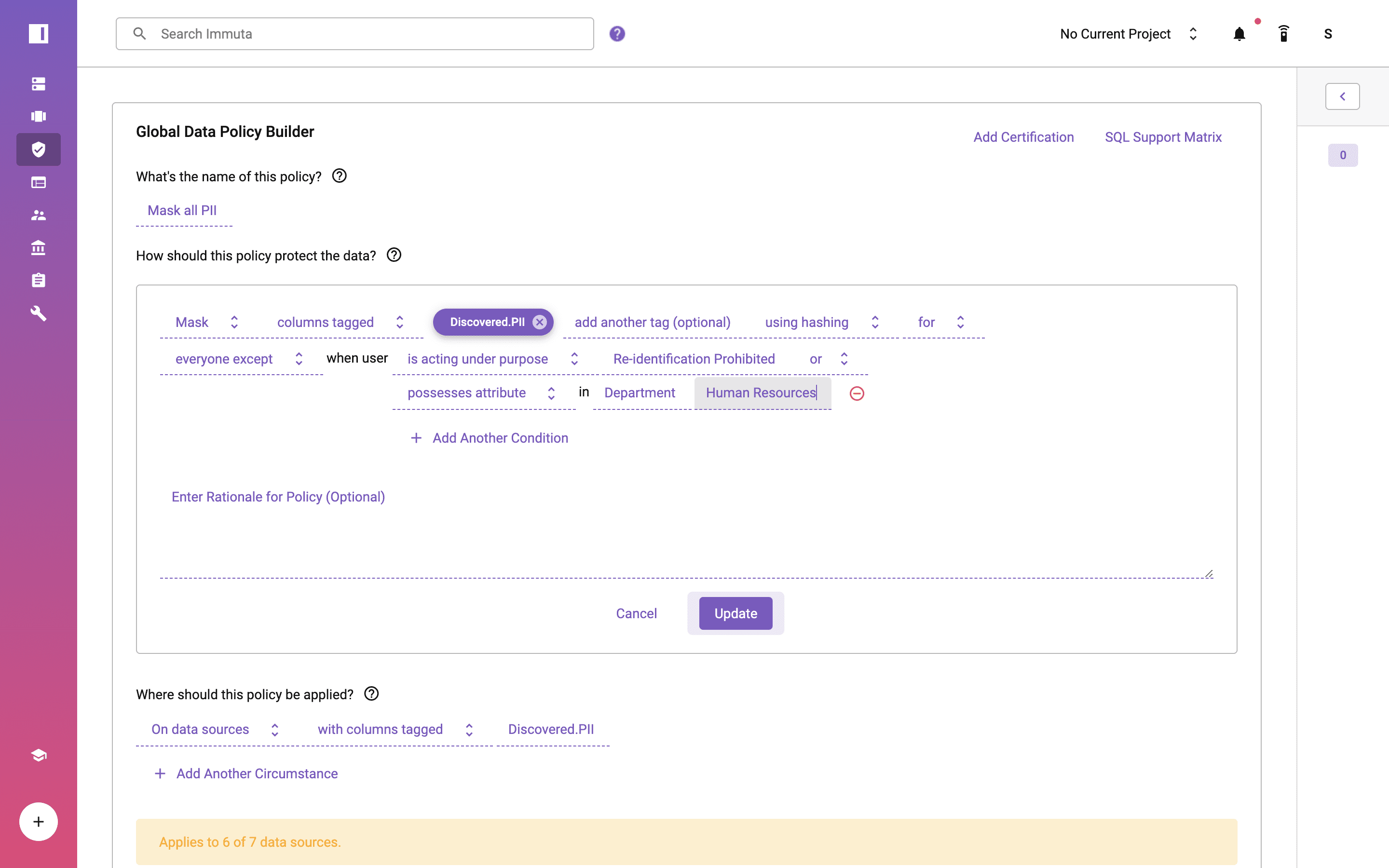
Using Immuta’s policy-as-code capabilities, you can create a global masking policy to apply dynamic data masking across all fields in Databricks and any other platform. This includes hashing, regular expression, rounding, conditional masking, replacing with null or constant, with reversibility, with format preserving masking, and with k-anonymization, as well as external masking.
Read More: How to Anonymize Sensitive Data with Databricks Access Control
Note that the policy applies to “everyone except” those possessing an attribute where “Department” is “Human Resources,” which is pulled from an external system. This dynamic approach is also known as attribute-based access control, and it can reduce roles by 100x, making data more manageable and reducing risk for data engineers and architects.
In addition to column controls, Immuta supports row-level filtering and dynamic privacy-enhancing technologies (PETs), such as differential privacy or randomized response.
Natively Enforced Databricks Data Masking Policy
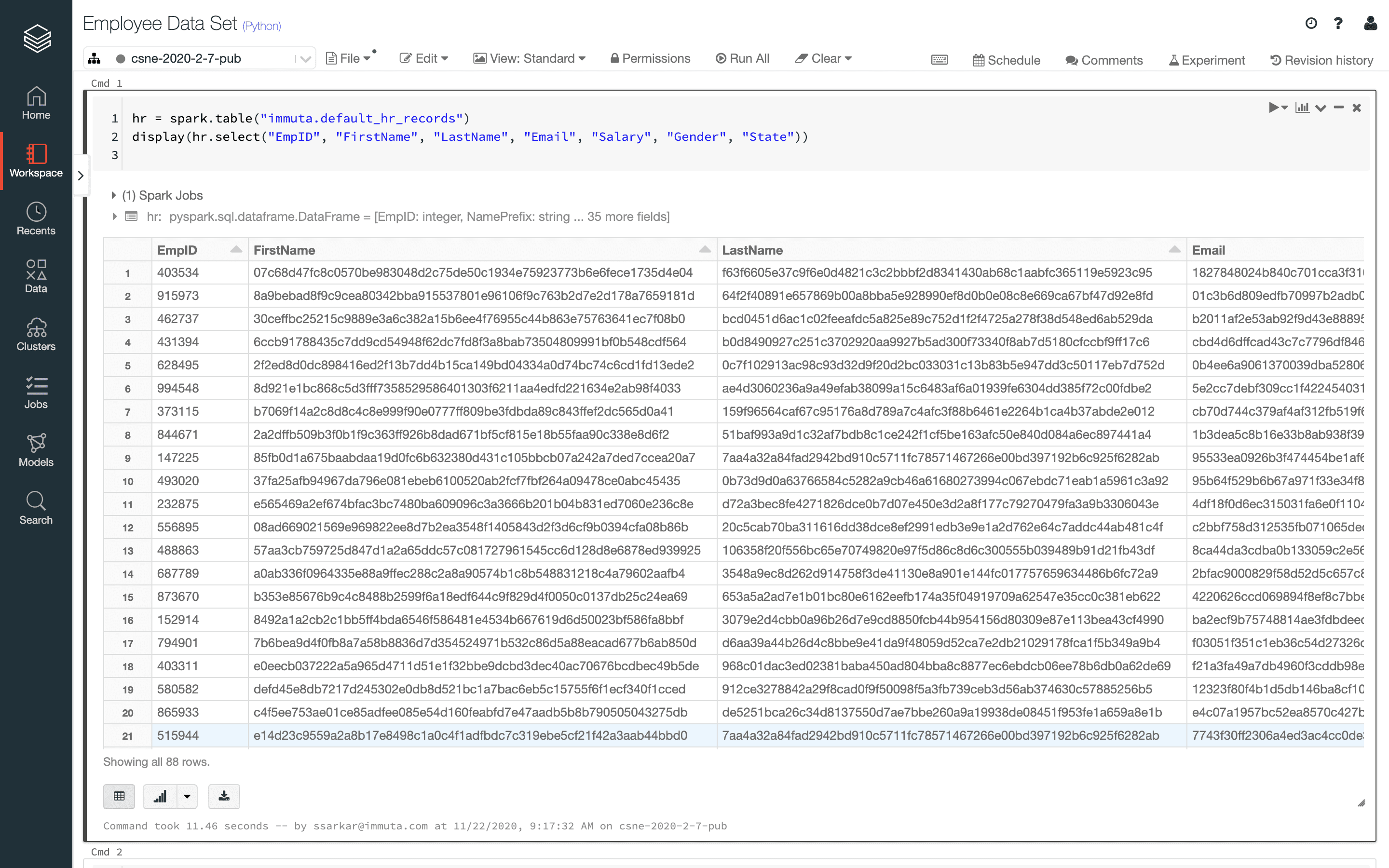
If you run the notebook from Databricks, you will now see that all of the columns tagged as PII during the sensitive data discovery stage are dynamically masked without having to make copies or create and manage views. This policy is enforced natively on Spark jobs in Databricks, which means the underlying data is not being copied or modified. This is important because it allows you to maintain a single source of truth in data management and avoid risk and confusion associated with multiple data copies.
DIY Approaches for Databricks Data Masking
If you want to take a more DIY approach to Databricks data masking, you are able to do so by writing ETL code in Python using Spark UDFs to apply policies to specific columns and replicate the data for all users except the HR department, who will access the raw data.
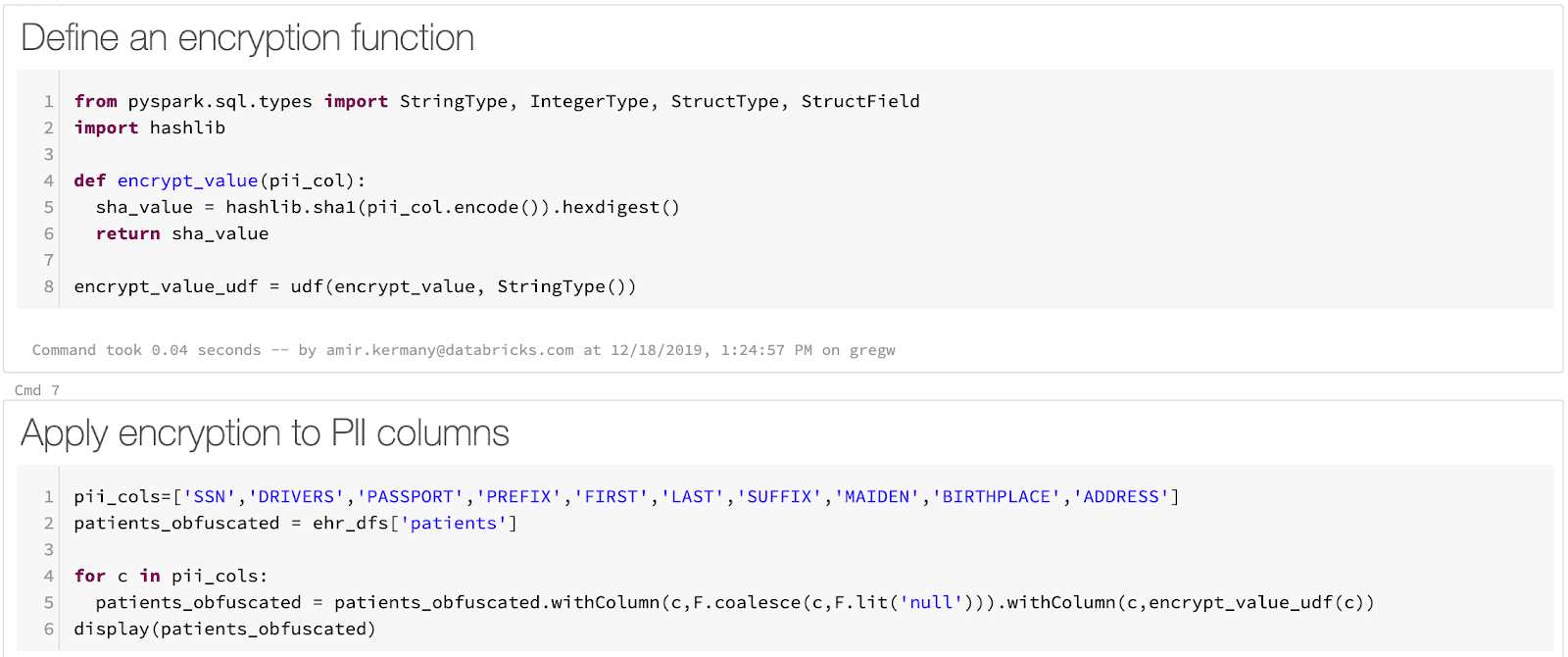
(Example from Databricks Engineering Blog)
Controlling access to sensitive data in the cloud can be challenging as the amount of data, users, and cloud platforms grows. The DIY example above is specific to a table and requires very different approaches among Databricks and any other platforms in your data ecosystem. Immuta provides a consistent way to automate these steps in a consistent, secure way across your cloud data ecosystem.
You can explore Databricks data masking capabilities in Immuta further when you request a demo.