
Today’s technology moves data faster than ever before, but many organizations still rely on manual methods to control who can access what. At first, this feels manageable — simple, even.
But as the business scales and data governance requirements mature, cracks begin to show. It’s overwhelming for IT to manage, and the business’ needs keep piling up with no real solution in sight.
Manual policy enforcement may seem like an easy starting point, but it’s not built for long-term success. The very simplicity that once felt efficient quickly becomes a liability. So, where do you go from here?
Let’s look into what you’re probably doing today, why it’s not working, and how Immuta can help.
Schema-level access: The illusion of efficiency
Many teams begin their data governance journey by managing access at the schema level. It’s a seemingly efficient model:
- Create a group for a schema.
- Add users as they request access.
- Give them full visibility into every table within that schema.
For small datasets and basic access needs, this works fine. But the moment granularity is required — say, granting access to one table while restricting another — the cracks appear. You need to now create another group and manage this bespoke access request. I’m guessing your forms don’t currently handle this type of request, or you’re just using a text box.
The all-or-nothing schema model forces IT to build exceptions and custom workarounds. Over time, the once-straightforward access map becomes a tangled web of manual adjustments, inconsistent policies, and undocumented overrides.
By the time an audit rolls around, the “simple” system has evolved into something opaque and error-prone. What was once efficient is now a compliance risk.
Key takeaways:
- Schema-level groups offer speed at the expense of precision.
- Manual exceptions create inconsistency and audit challenges.
- Visibility into “who has access to what” quickly erodes over time.
Fine-grained access controls: Why the manual approach doesn’t scale
As data sensitivity grows, so does the need for precision (as we saw with the schema-level access approach). In response, organizations often attempt to implement fine-grained access manually — masking specific columns or filtering data based on user roles.
To meet these requirements, IT teams create countless “views” – virtual tables tailored to specific users, departments, or regions – or attempt to write their own UDFs (user defined functions) in cloud platforms. In extreme cases, this results in:
- Thousands of overlapping views and access groups.
- Manual tracking of every combination of permissions.
- Constant maintenance just to keep data consistent.
This approach drains time and resources, and it simply can’t scale. Each change to a dataset or business rule triggers a cascade of updates, creating operational friction and increasing risk. Whether you’re using views or UDFs, the complexity and management burden on IT are high.
If you’re using multiple data platforms, how are you keeping all of the rules consistent across all platforms? It’s near impossible, and it’s a tangled web that requires constant maintenance.
Key takeaways:
- Fine-grained control is essential but unsustainable when done manually.
- Every new use case compounds complexity.
- Manual views multiply risk and slow down data-driven work.
Slow-moving process can expose security gaps
Modern cloud data platforms are powerful and flexible — but they also demand careful governance. Many rely on roles and user-defined functions to enforce policies. As we explored with manual fine-grained access, these are useful tools, but they shift a heavy burden onto IT teams who must translate complex business logic into code.
The problem? Code doesn’t scale governance.
In fast-moving environments where new datasets and attributes are introduced daily, manual policy enforcement simply can’t keep up. Consider:
- A new sensitive column (e.g., SSN) is added to a table — but policies aren’t updated immediately.
- During that delay, unauthorized users may see data they shouldn’t.
- Routine ETL processes (like dropping and recreating tables) can strip away existing policies, leaving sensitive data temporarily exposed.
Each of these gaps represents not just operational inefficiency, but a real security threat. Relying on manual reapplication of policies isn’t just cumbersome — it’s a design flaw.
Are you writing code to monitor ETL operations and ensuring policy is being put back in place? If not, your data might be exposed right now.
Key takeaways:
- Manual policy updates can’t match the pace of modern data change.
- Policy loss during ETL processes creates hidden exposure windows.
- Every manual step adds opportunity for error and noncompliance.
Scaling policy automation with confidence
Platforms like Immuta replace fragile, manual ecosystems with automation and context-based data provisioning. Instead of writing and rewriting complex rules, you can define simple, universal policies — like “mask all PII” — and trust Immuta to handle the rest.
Here’s how:
Automated policy enforcement
You’re able to write policies in plain language or as code, and Immuta instantly applies and maintains them across platforms. The policy below scales very easily to only show rows for the country that the user is allowed to see. This can very easily be applied to other information like account numbers, line of business, or other codes that you may need to limit users’ access.
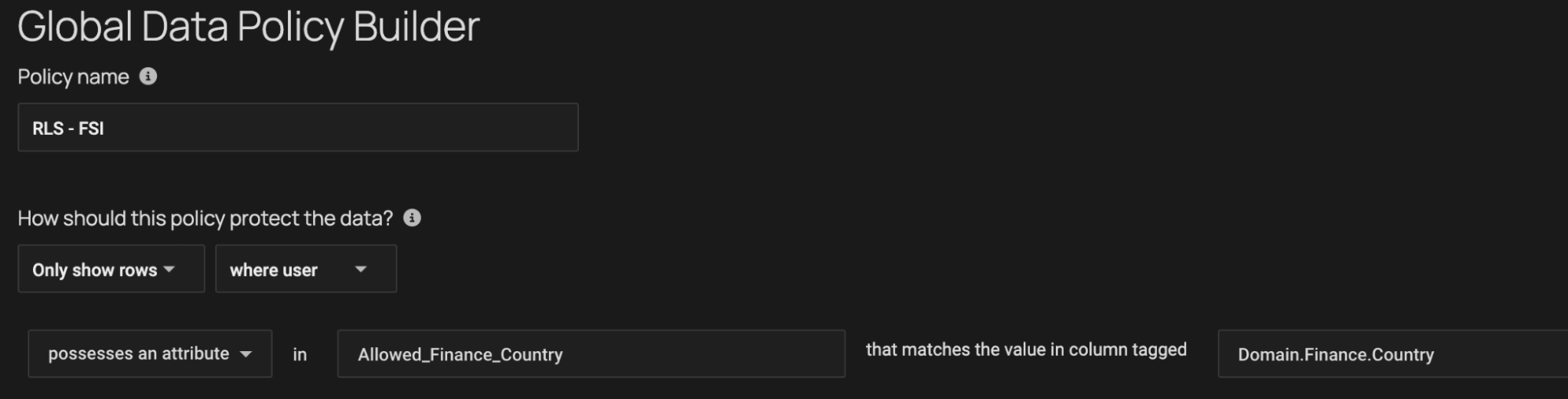
Integrated data discovery
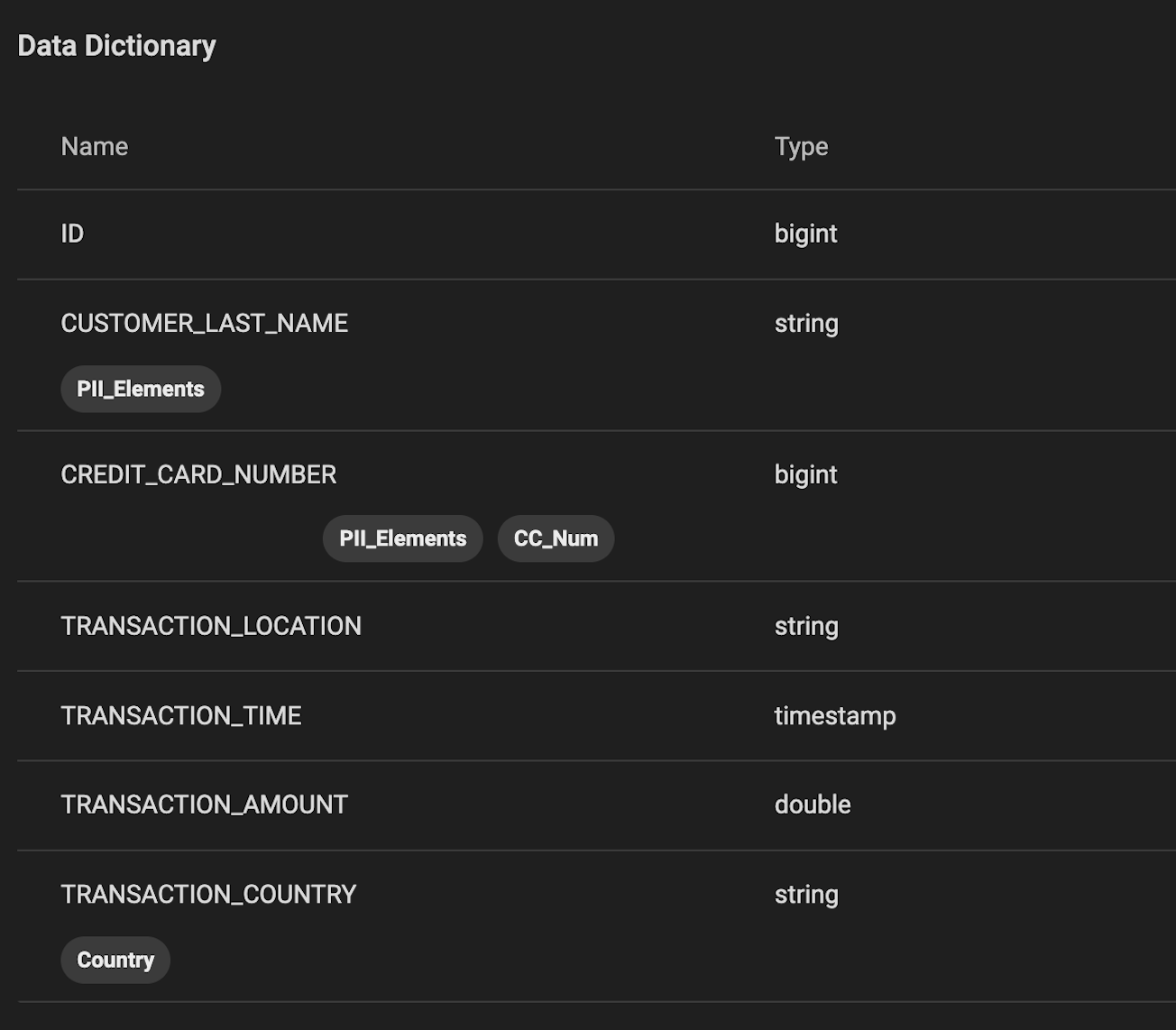
Immuta continuously scans for new data, and tags and classifies sensitive information like PII automatically for easy policy enforcement.
In the example below, Immuta scanned and found PII and PCI data. Since the country column is specified in the policy above, Immuta automatically tagged that attribute so the policy is applied.
Centralized/federated governance
Policies remain consistent, traceable, and auditable. You can centralize your policies with IT or governance teams. Alternatively, you can federate out to the data owners using Immuta Domains to scope the policies for each team.
Self-service access
Users can request to access or unmask data directly within Immuta — no tickets, no waiting, just faster insights.
Immuta doesn’t just automate — it transforms the entire data provisioning model by incorporating dynamic workflows and context-aware decision making. Policies adapt as data changes, you can maintain compliance and transparency without adding administrative overhead.
Key takeaways:
- Immuta automates policy enforcement from the table to the row level.
- By translating business logic into executable, auditable policies, Immuta balances precision and transparency.
- Organizations gain agility, security, and peace of mind, along with true self-service data access.
Final thoughts
Manual policy enforcement was never designed for modern data governance. It may work in the early stages, but it breaks at scale — creating risk, friction, and confusion.
By automating and centralizing policy enforcement, Immuta empowers you to securely share and leverage your data without compromising control or compliance.
When simplicity fails to scale, automation isn’t just the next step — it’s the only way forward.
The future of policy enforcement.
See how AI is helping users access data at an unprecedented scale.



