
Data governance teams are reviewing more access requests than ever, not just from employees, but from automated systems and now AI agents operating at machine speed. Manual reviews can’t keep up, and decentralized approvals often lead to inconsistent decisions and rising risk. Organizations need a way to make fast, accurate, and defensible access decisions without relying on a handful of experts. ReviewAssist was built to solve that challenge, and this latest update strengthens its intelligence so governed access can scale safely as demand accelerates.
What is ReviewAssist?
ReviewAssist is Immuta’s AI-powered recommendation engine designed to help organizations make faster, more consistent decisions on data access requests. As access requests flow in from a wide variety of users, teams, or AI Agents, ReviewAssist analyzes how your organization historically approved or denied requests with similar context and metadata. It then provides a recommended action, an AI-generated justification, and a clear risk rating for every new request. Approvers who may not be governance specialists gain expert-like confidence, reduce hesitation, and make decisions aligned with established patterns and policies. ReviewAssist ensures safe, predictable, and efficient data access without requiring deep governance expertise.
Why we built ReviewAssist (and how data access was handled before)
Before ReviewAssist, most organizations relied on approval workflows that simply could not scale as demand for data grew. Often, a small group of governance experts or committees reviewed most requests via ticket systems. These specialists lacked the details to make high-quality decisions and quickly became bottlenecks as access volumes increased, especially as data-driven initiatives expanded. Typical approval timelines ranged from 2-4 weeks.
To move faster, many organizations shifted approvals to data stewards and owners. While this decentralized approach helped throughput, it also introduced inconsistency. Approvers lacked the broader context of past decisions, struggled to assess risk effectively, and often operated with limited information. Some approved everything to avoid blocking work. Others denied requests out of caution. This resulted in an unpredictable process that slowed teams down and created governance gaps.
With agentic workflows and AI-driven systems now generating or orchestrating access requests at enormous scale, the old model is no longer viable. Organizations cannot route tens or hundreds of thousands of requests through experts, and unassisted stewards cannot be expected to reliably evaluate risk. ReviewAssist was created to bridge this gap by providing intelligence, consistency, and confidence to decentralized data access governance.
Introducing ReviewAssist 2.0
Although the original ReviewAssist delivered strong recommendations based on identity metadata and historical decisions, real-world governance often depends on more than who is requesting data. In many cases, the real deciding factor is why the requester needs it. Two people or AI agents with identical attributes may have very different intentions, and intent often determines the true risk.
ReviewAssist 2.0 addresses this by integrating Immuta Custom Forms with a new LLM-powered Topic Modeling engine. Custom Forms collect consistent information about why a user or system is requesting data. Topic Modeling interprets free-form responses and converts them into structured signals about the requester’s activity, which describes what they plan to do, and purpose, which describes why they need the data. This gives ReviewAssist the ability to evaluate intent with far greater nuance.

A real example: Turning text Into actionable insight
Imagine two employees who share the exact same identity metadata. They are both financial analysts on the corporate finance team, belong to the same security groups, have the same attributes, and historically have been granted access to similar datasets.
Now both submit requests for access to a sensitive customer dataset:
- Requester A: “I need this data to compile monthly financial performance reports for leadership.”
- Requester B: “I need to download all customer records for historical analysis.”
In ReviewAssist 1.0, these requests would look nearly identical because the identity-based metadata is the same. The reviewer could see their request form responses, but Review Assist had no visibility into purpose or intent, so it could only evaluate the request based on who they were, not what they planned to do.
ReviewAssist 2.0, however, understands the intent behind the language.
- Requester A describes a well-understood, historically approved reporting use case.
- Requester B uses ambiguous, higher-risk language that warrants closer review.
ReviewAssist 2.0 recommends a Low Risk approval for A and a High Risk for B based on purpose and intent, not just identity. This distinction is only possible because ReviewAssist 2.0 analyzes the meaning behind the request, not just the requester’s metadata.
How It Works: Details on Intent Detection
ReviewAssist 2.0 uses large language models to interpret the free-text explanation a requester provides when asking for data. Instead of treating these responses as unstructured comments, ReviewAssist extracts two key signals:
- Action – what the requester is trying to do
- Purpose – why they need the data
The LLM analyzes the requester’s explanation and identifies the core verb or action (for example: analyze, compile, monitor, validate), along with the general domain and target of that action. It performs a similar process for the requester’s purpose, capturing the business context behind the request. If the model cannot determine a clear action or purpose, it assigns an “unknown” label so every response maps to a usable, discrete value.
After classification, the LLM also calculates a simple Maliciousness Score as a final safety check. This score evaluates the verb used, flags clearly harmful or suspicious phrasing, and increases slightly when the purpose or action is unclear. While not part of the primary scoring model, it ensures that requests containing obviously risky language are surfaced for additional attention.
These extracted signals become structured metadata that flows directly into ReviewAssist’s decision tree which already includes the requesting identities’ metadata. The model evaluates how similar actions and purposes were handled historically and combines that with identity metadata to determine the most appropriate outcome. By incorporating intent into the scoring model, ReviewAssist can differentiate between similar users who have very different reasons for accessing the same data.
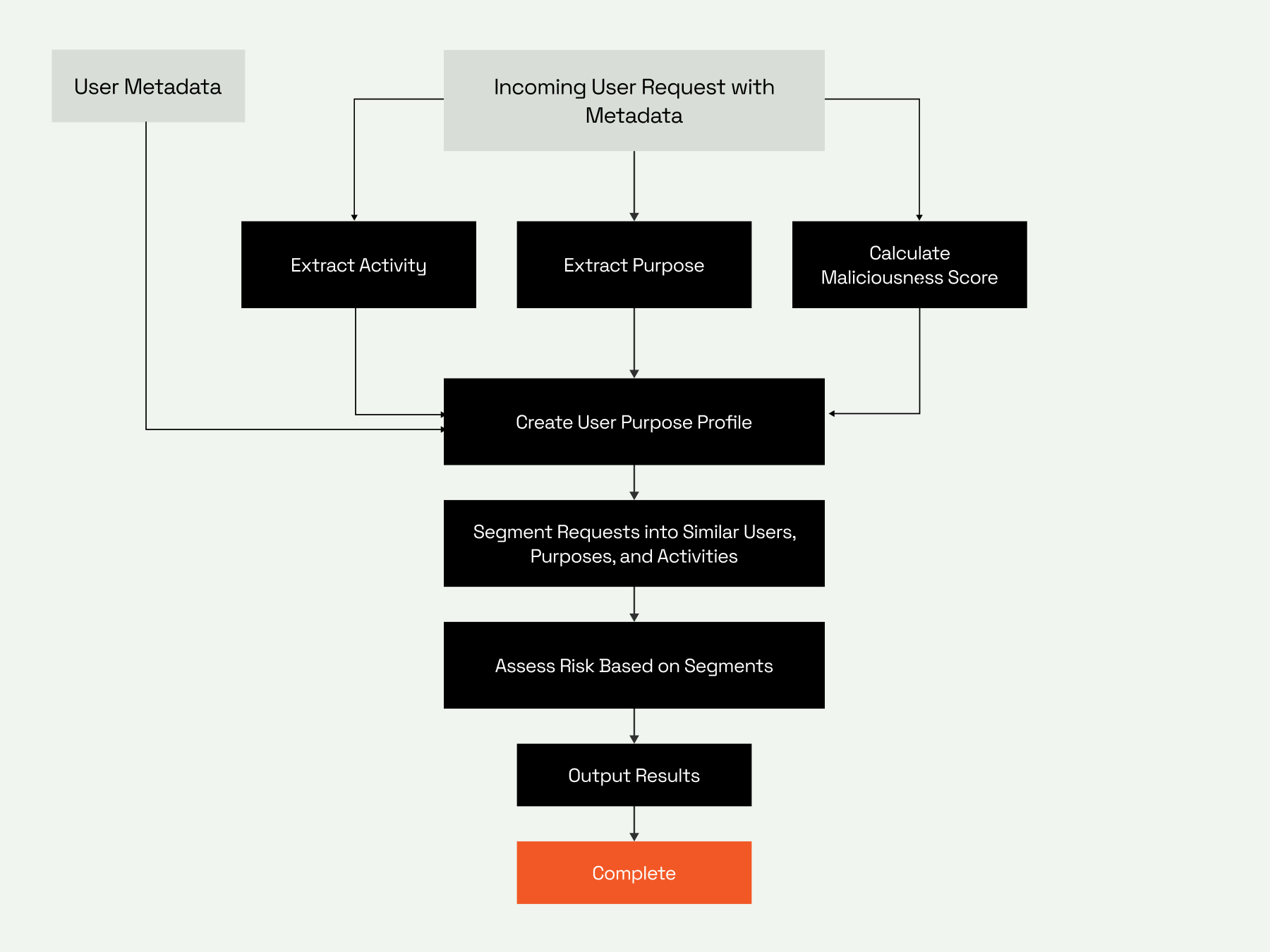
The result is a far more accurate and transparent assessment for every request. ReviewAssist 2.0 scores all requests — from humans or AI agents — with a richer understanding of what the requester intends to do. This gives organizations the metadata they need to build smarter, purpose-aware approval workflows that scale to both human and machine-speed environments.
Why This Matters as AI Agents Proliferate
The shift from human-driven access requests to AI-driven behavior fundamentally changes the operating model for data governance. Traditional workflows assumed human pacing, where delays of days or weeks were normal. AI agents operate continuously at machine speed and expect access decisions in seconds or less. This exponential increase in speed and volume amplifies the impact of potential mistakes, requiring governance that can operate at the same velocity.
AI agents also introduce new classes of risk. When operating autonomously, they can:
- Generate unclear, vague, or incomplete access justifications
- Hallucinate new tasks or infer unintended access needs
- Request large volumes of sensitive data in very short periods
- Accidentally escalate privileges due to misinterpreted prompts
- Misread instructions, policies, or context
- Become vulnerable to prompt injection or manipulation
At human-scale, such issues might surface slowly and be caught manually. At machine-scale, a single misaligned agent could generate thousands of risky requests before detection. This is why understanding intent is essential. It is no longer enough to know who the agent represents or the sensitivity of the data. We must understand why the agent is requesting access and whether the behavior aligns with safe patterns.
ReviewAssist 2.0 provides exactly this by generating richer metadata and more accurate risk scores for every request. These signals give enterprises the intelligence needed to build approval workflows that adapt dynamically to the nature of each request.
Why it’s better (and the big so what)
ReviewAssist 2.0 represents a significant advancement in the intelligence and precision behind Immuta’s access recommendations. By incorporating purpose detection, activity classification, and maliciousness scoring, ReviewAssist now understands not only who is requesting data but also why they need it and whether that intent carries risk. This added context strengthens every decision and ensures that approvals align with real governance expectations, not guesswork or inconsistent human judgment.
The enhanced intelligence in ReviewAssist 2.0 also creates a clearer boundary between what can be safely automated and what requires human review. When intent is well understood, organizations can confidently accelerate access through automated or delegated approvals. When intent is unclear or suspicious, ReviewAssist flags it before data moves, delivering a more trustworthy path to decentralization and dramatically improving throughput.
By combining generative AI, intent modeling, and intelligent risk scoring, ReviewAssist 2.0 empowers organizations to confidently leverage high-volume agentic data ecosystems while maintaining safety, consistency, and trust at every step.
Most importantly, ReviewAssist 2.0 positions Immuta for the next era of agentic data governance. As AI-driven access workflows become the norm and millions of requests flow through enterprise systems at all hours, organizations need deeper metadata and more context to assess risk accurately. Manual review is impossible at that scale, and static rules cannot capture the complexity of intent.
The latest in data provisioning.
Take a closer look at all of our data provisioning updates.



