Key Takeaways
- Immuta’s identifiers in domains feature is now generally available to all global customers.
- It addresses a critical gap in traditional metadata catalogs by making sensitive data discoverable and governable within domain boundaries, which adds critical context to policy enforcement.
- This capability empowers domain governors to classify and control data at scale — without relying on central data teams or stitching together external tools.
- Once identifiers are defined at the domain level, Immuta handles inheritance, visibility, and enforcement.
From centralized metadata to federated governance
As organizations scale data access provisioning across business units, the cracks in centralized data governance models become harder to ignore. Data stewards and platform teams are increasingly asked to support decentralized teams and use cases — but the tools they rely on weren’t designed to do so.
Most traditional metadata catalogs and governance platforms take a top-down approach. They require manual column-level tagging, rely on static schemas, and – critically – live outside the context where policies are enforced. That’s a problem. Data teams are left stuck maintaining brittle mappings, while domain governors — who understand the data best — are left without a way to govern what they own.
Immuta’s domain-centric approach
Immuta introduced Domains as a way to enforce policy in a way that reflects real-world data ownership. Domains allow platform teams to delegate governance — including data identification, policy authoring, and monitoring — to the right people, without sacrificing consistency or control.
Now, with the launch of identifiers in domains, domain governors can define and manage sensitive data identifications natively within Immuta — and eliminate reliance on external tools or centralized bottlenecks.
What are identifiers in domains?
Identifiers are a way to classify sensitive data elements, such as names, emails, social security numbers, or employee IDs. They play a role in determining what protections, like masking, row-level filtering, and purpose-based access, should be applied to which data.
Within Immuta, there are two types of identifiers:
- Reference identifiers are a library of reusable identifiers that can be added to domains.
- Domain-specific identifiers only apply to the data sources in a given domain and can be managed by authorized domain users.
With identifiers in domains, you can tag columns containing sensitive attributes. Those attributes are:
- Defined and scoped within domains so that domain governors control how data is classified.
- Automatically identified in all tables across the domain, which reduces manual work.
- Protected by Immuta policies without the need for external catalogs or manual tagging.
This capability fills a gap that traditional metadata catalogs can’t solve. It ties identification directly to access provisioning in a decentralized model.
Why identifiers in domains matter
Let’s look at how this addresses common pain points in large data environments:
|
Challenge |
Traditional Approach |
Immuta with Identifiers in Domains |
|
Sensitive data tagging |
Manual, centralized, disconnected from policy enforcement |
Defined within domain, inherited by tables automatically |
|
Domain-based governance |
Difficult to support with global tags or static schemas |
Scoped identifiers empower local control |
|
Policy consistency |
Risk of drift between catalog and enforcement layer |
Immuta enforces directly where data access happens |
By aligning sensitive data identification with domain ownership, Immuta makes governance both scalable and context-aware.
How it works: Step-by-step implementation
Here’s how data platform teams and domain governors can start using identifiers in domains:
1. Create domains in the Immuta Platform
Start by defining domains that align with your data governance model (e.g., HR, Marketing, Finance).
- Navigate to the Domains tab in Immuta and click New Domain.
- Define your domains based on logical data governance boundaries.
- Choose between Manual or Dynamic assignment of data sources, and configure user permissions accordingly.
2. Create identifiers scoped to a domain
Now that domains are established, you can create identifiers within them.
- Go to the Identifiers tab in your domain.
- Click Get Started to add built‑in reference identifiers.
- Or click Create New to define a custom identifier:
– Provide a name (e.g., employee_id, ssn, customer_email) and description.
– Configure the matching criteria (regex, column‑name regex, or dictionary).
– Select tags to apply.
- Click “Create Identifier” to scope this identifier to the domain and make it available for downstream policies.
3. Automatically scan all domain tables
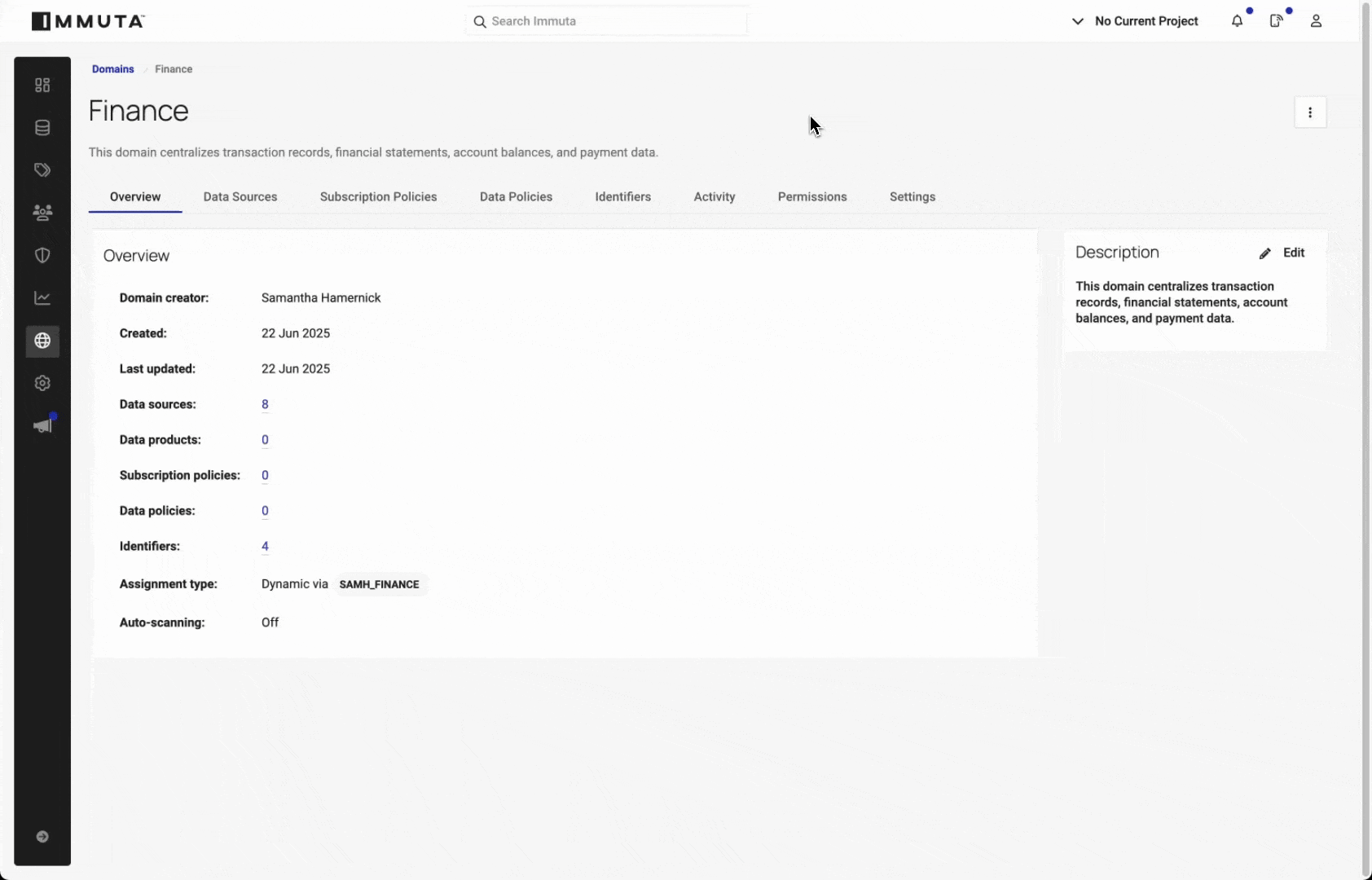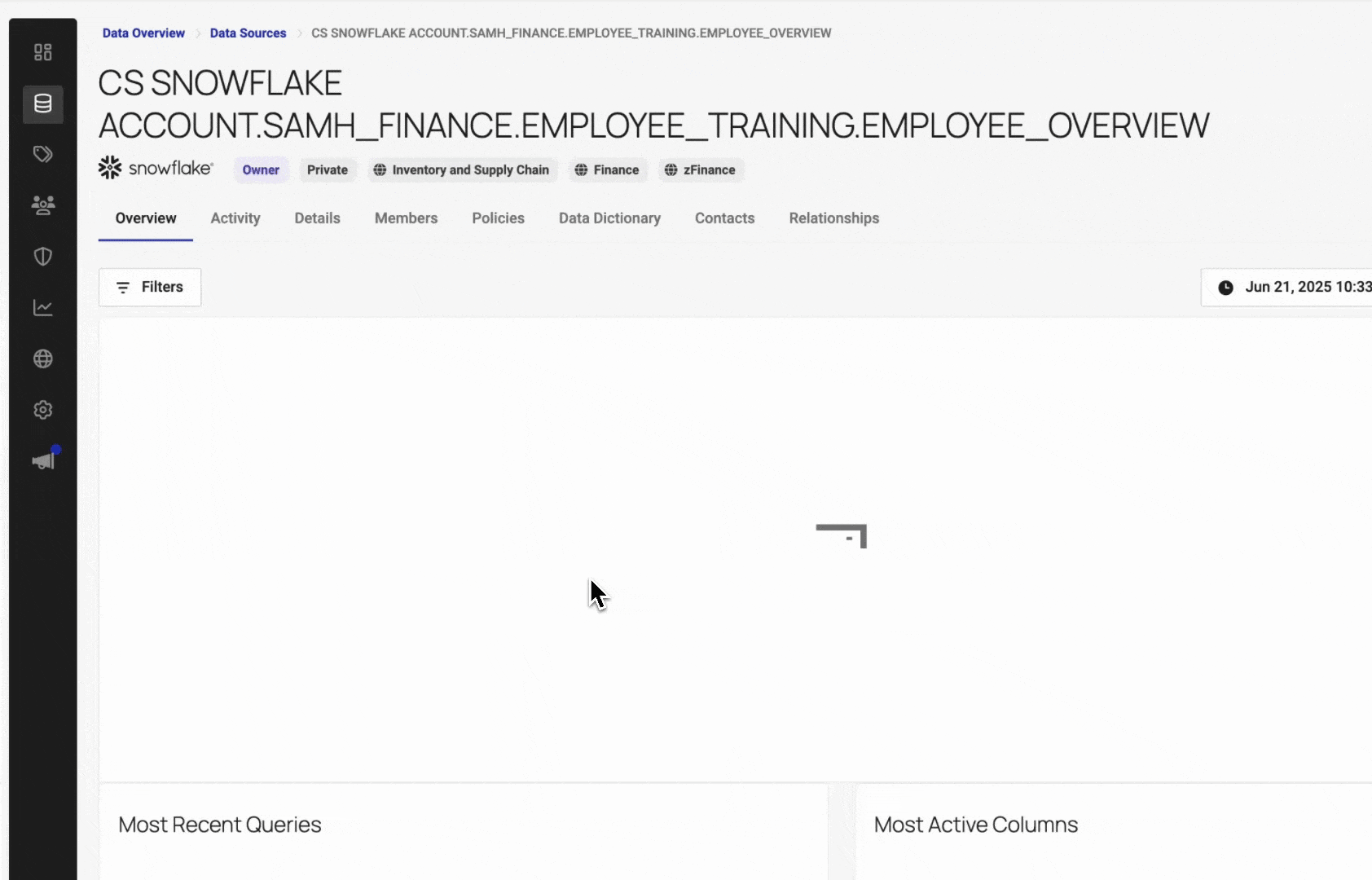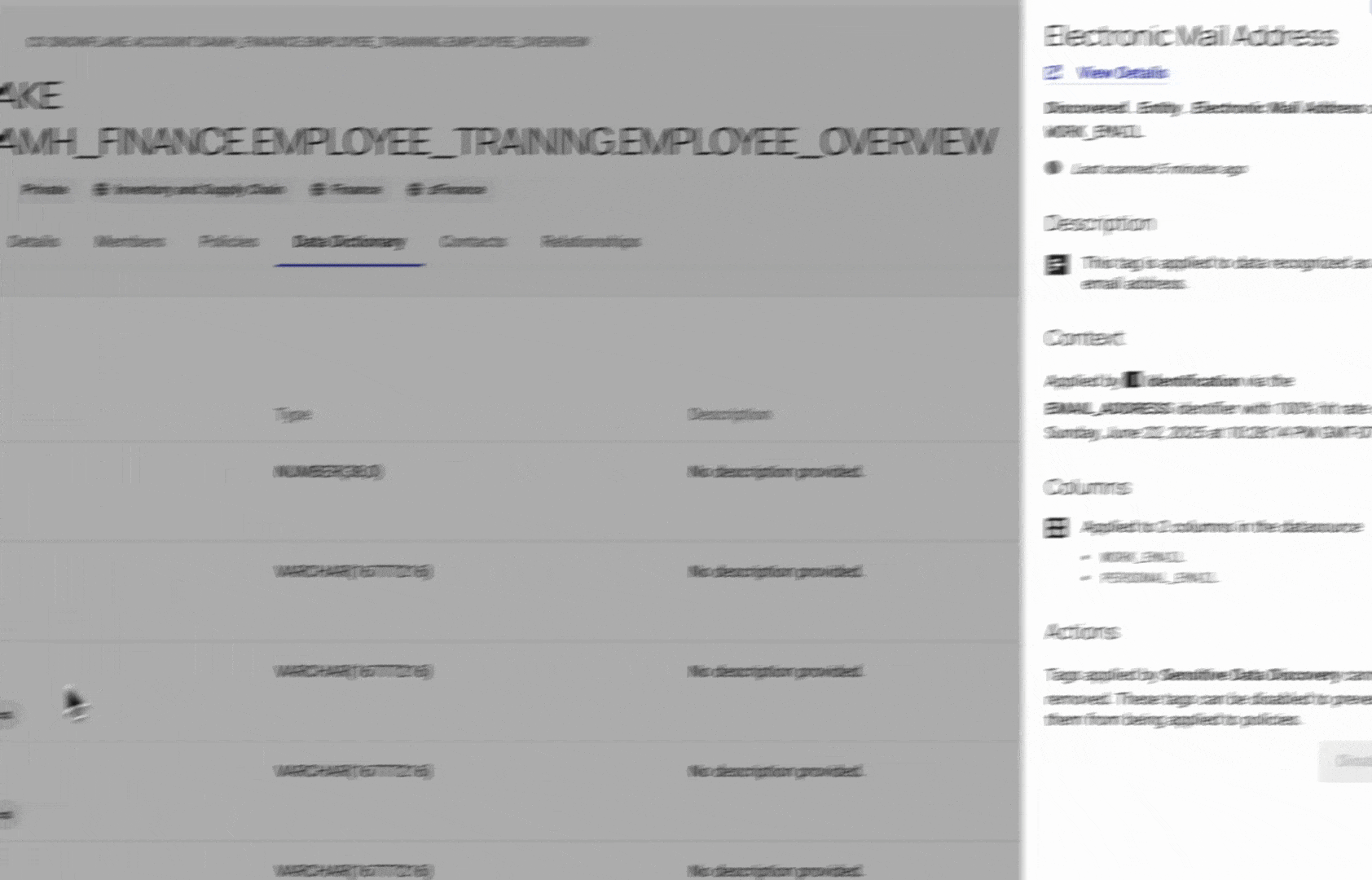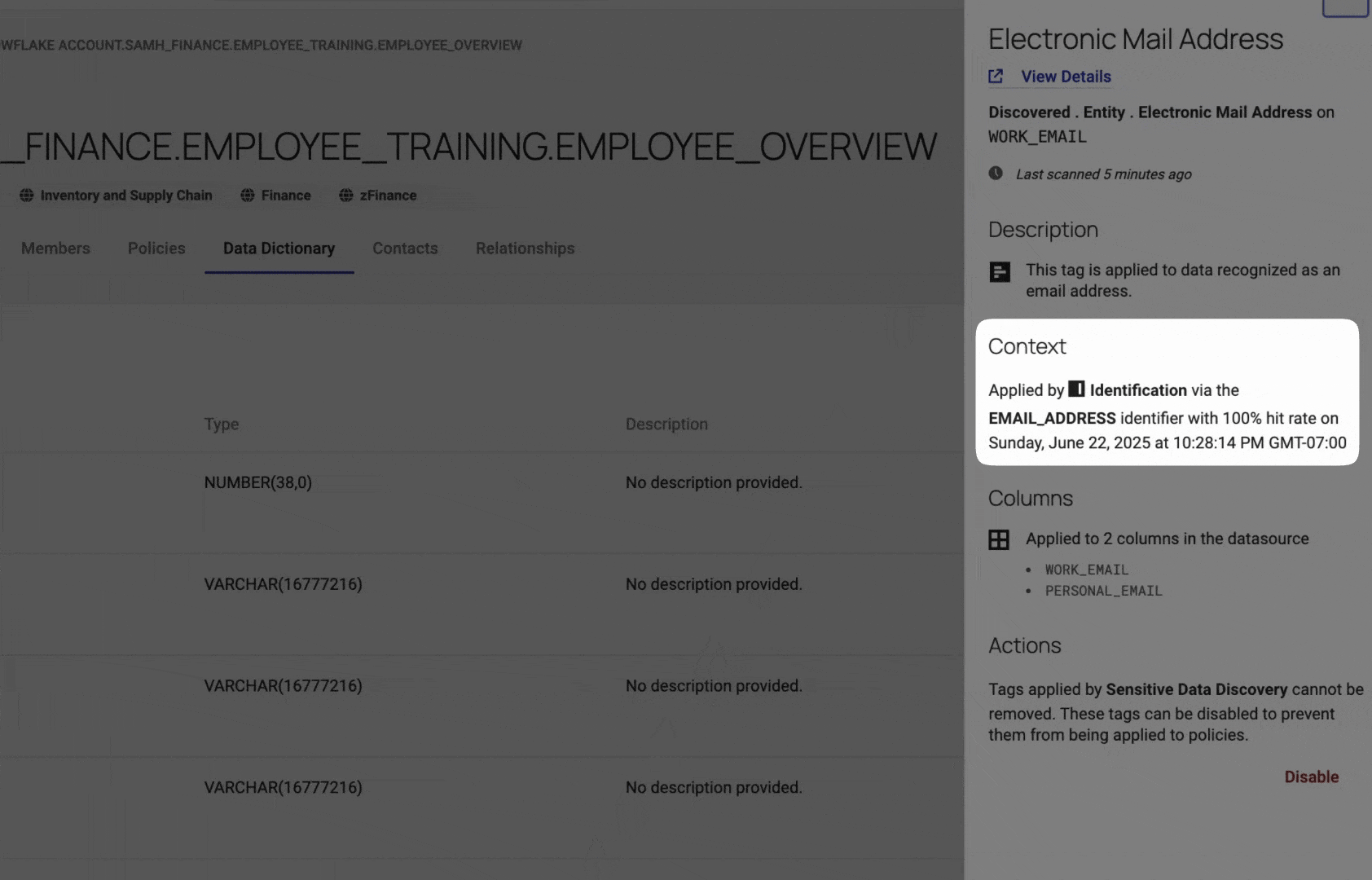
Once an identifier is defined, Immuta automatically scans all tables in the domain to detect and tag matching columns. For you, this means:
- No need to manually tag individual columns. Immuta applies tags wherever matches are found.
- Full transparency into results. Review and refine tags directly in the Data Dictionary for each table.
- Tags stay up to date. With autoscanning enabled, tags are automatically applied to new tables and columns within the domain.
4. Author policies using identification tags
Now domain governors can write policies that apply to their tables using tags placed by the scoped identifiers. Using Immuta’s plain-language policy builder or API, they can create:
- Masking policies (e.g., hash emails)
- Row-level filters (e.g., only see rows where region = user region)
- Purpose-based access controls (e.g., only access data for a specified, acknowledged purpose)
Policies reference the tags applied through domain-scoped identifiers, enabling consistent, scalable enforcement without needing to specify individual columns. This allows domain governors to manage access confidently and independently while staying aligned with organizational standards.
See how it works in practice here:
Future-proofing decentralized architectures
As organizations embrace decentralized data architectures, like data mesh, governance and provisioning tools must evolve. Immuta’s identifiers in domains capability is a practical step forward, offering decentralization without sacrificing policy consistency or operational efficiency.
By putting identification and control in the hands of domain governors, Immuta enables you to:
- Reduce the management burden on central data and IT teams
- Increase policy coverage and accuracy without increasing overhead
- Scale governed data provisioning across business units and data products
This is what governance looks like when it’s built into the platform, not bolted on.
See it in action.
Experience identifiers in domains.



