In the pharmaceutical industry, safeguarding sensitive data isn’t just a technical necessity — it’s a regulatory imperative. From clinical trials to manufacturing and commercial operations, pharma organizations manage data that is subject to strict privacy, integrity, and quality requirements, including HIPAA and GxP standards.
At the core of meeting these obligations lies data classification. Data classification refers to the process of labeling data based on its sensitivity, regulatory implications, and criticality. It helps to quickly make sense of the data within your ecosystem so that you can fully understand your level of risks, security needs, and compliance mandates.
The challenge for pharma companies comes down to the massive volumes of sensitive data they hold and the complexity of their systems. How can they scale data classification across thousands of datasets in multi-cloud environments without anything slipping through the cracks? And how can they make these classifications actionable for access control, approvals, and auditing?
This is where Immuta’s classification service comes in. It evaluates existing column tags, neighboring column tags, and table-level metadata to categorize data based on context and risk level, setting the stage for dynamic governance. In this blog, we’ll look at why data classification is critical for pharma companies, and how to build a classification framework to control data throughout its lifecycle.
Why data classification matters in the pharma industry
Pharmaceutical companies manage diverse and highly sensitive datasets: everything from clinical trial records spanning 40 countries to manufacturing data from dozens of systems to patient and provider information governed by global privacy laws. They’re also subject to some of the strictest regulatory requirements of any industry, including the GDPR, HIPAA, and GxP standards. So for these companies, not having visibility into how data is classified and protected is simply not an option.
To add to the complexity, each type of data carries unique regulatory and business risks. For example:
- A trial subject’s
date_of_birth (GDPR special category data)
- A batch record’s
product_batch_id (GxP-critical for FDA audits)
- An provider email (PII under HIPAA and marketing laws)
To address these risks, leading organizations use multi-dimensional classification frameworks that evaluate data across key dimensions:
|
Dimension |
What It Means |
Example Tags |
|
Privacy |
Is it PHI/PII? GDPR special category data? |
PII, PHI |
|
GxP Criticality |
Does it impact product quality, patient safety, or submissions? |
GxP-High, GxP-Medium |
|
Confidentiality |
How broadly can this data be shared? |
Strictly Confidential, Public |
|
Crown Jewel |
Is this strategic IP or business-critical? |
Yes, No |
|
Integrity |
Required level of data validation and auditability |
Vital, Standard |
For example, a Phase III dataset containing large-scale patient data critical for regulatory approval could be tagged as “Strictly Confidential – GxP-High” with columns tagged as “PHI” – and those tags would trigger stricter controls. This multi-axis approach reflects global best practices, and aligns with regulatory expectations for risk-based controls and strong data governance.
How to classify and control pharma data
Managing how pharma data is classified and controlled via manual processes is not feasible in today’s data environments. The stakes are too high, the technology moves too fast, and the demand is too great to keep up – without slowing down or breaking anything.
That’s why leading pharma customers are integrating tools to consistently classify data and enforce the right controls on it to make sure it remains sufficiently protected, but also accessible. Immuta makes this complex process scalable and automated by weaving classification into every stage of the data lifecycle. Let’s look at how:
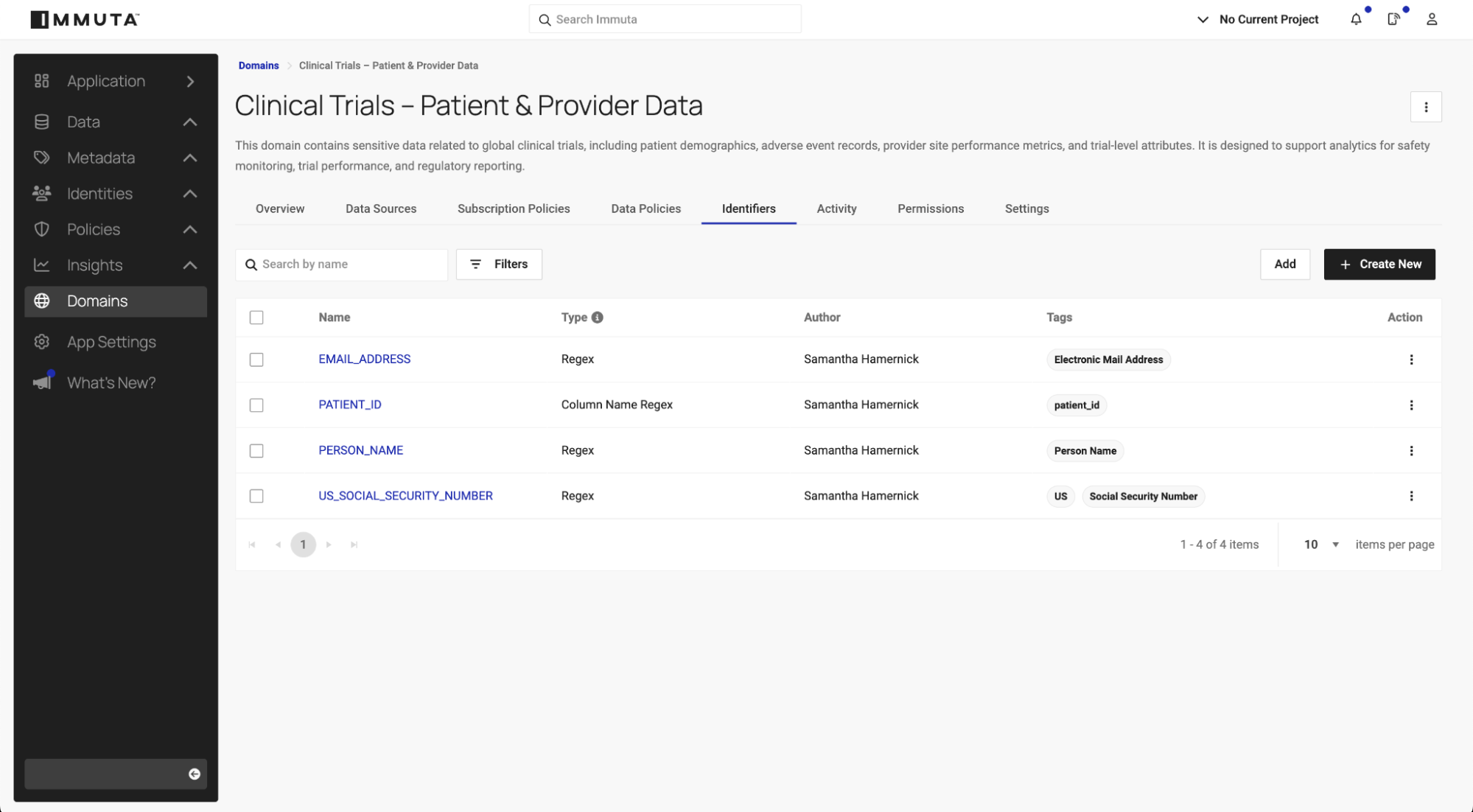
1. Discover and tag data
Before you can govern or protect sensitive data, you must first identify and label it accurately. Immuta offers a flexible tagging approach that forms the foundation for classification and policy automation.
- Automated identification: Immuta scans connected data sources to identify and tag sensitive fields based on configurable criteria. It includes built-in identifiers for common data types, which you can use as-is, modify, or extend with custom identifiers.
- External metadata integration: Immuta imports table and column tags from metadata catalogs like Atlan, Collibra, or Alation, aligning tagging with enterprise data governance frameworks.
- Connection-level tags: Immuta applies automated tags to all data sources within a registered connection using the format: Immuta Connections . Technology . Your Connection Name . Your Schema / Your Database.
- Manual stewardship: For edge cases where automation may not capture nuanced classifications, data stewards can manually tag datasets or columns directly within Immuta.
This hybrid approach blends automation and human oversight to create a comprehensive tagging layer. These tags feed into Immuta’s classification service, where they are evaluated in context to determine overall data sensitivity and risk.
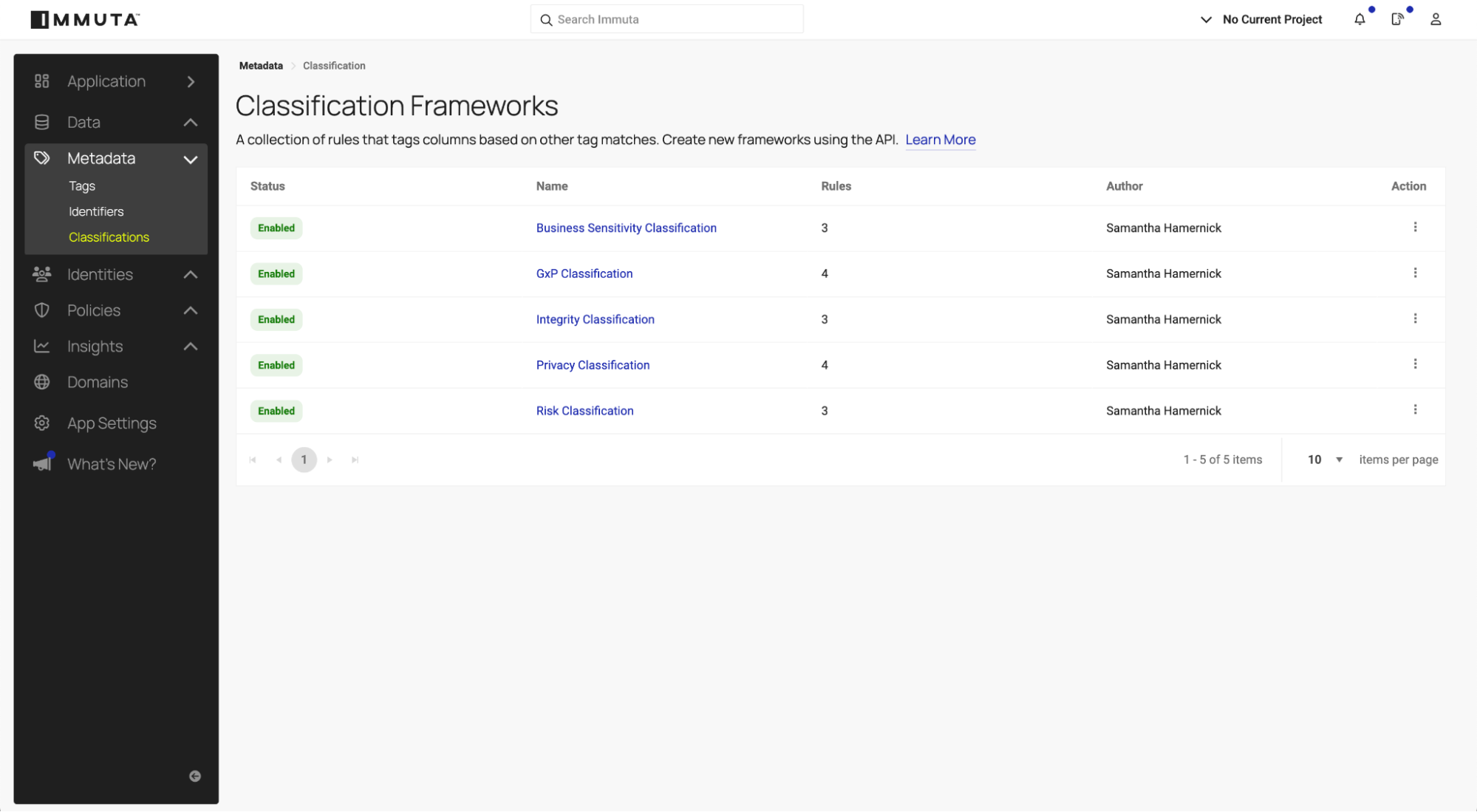
2. Define data classification frameworks
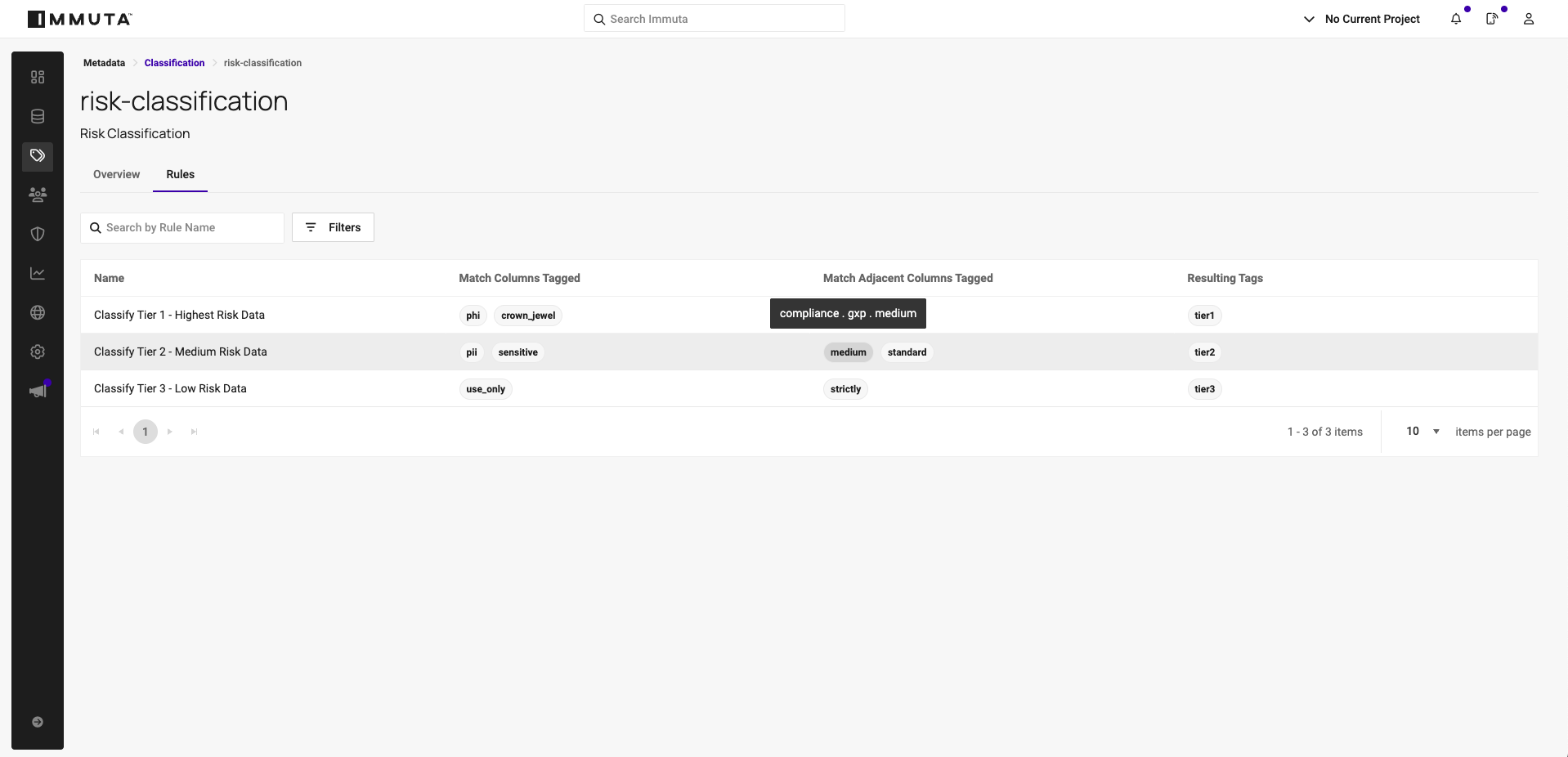
Once data is accurately tagged, Immuta’s classification service uses those tags to evaluate context and assign additional classifications that reflect the data’s overall sensitivity, risk, and regulatory requirements. This step builds on discovery and ensures policies respond dynamically to how data is used and combined.
- Context-aware evaluation: Immuta analyzes column-level tags, neighboring columns, and dataset-level tags together to assess risk. For example,
email alone may not require masking, but when paired with person_name in the same table, classification elevates the risk to PHI-High.
- Custom classification logic: Organizations can tailor classification rules to reflect their regulatory and business needs. A pharmaceutical company may classify datasets with PHI and GxP tags as “Critical,” while a financial firm focuses on PCI-sensitive data. Immuta allows you to create rules that align with your specific governance standards and compliance needs.
- Scalable automation: As new datasets are registered, Immuta automatically applies classification rules, ensuring consistent and up-to-date sensitivity assessments without manual effort.
These classifications set the stage for dynamic policy enforcement in the next step of the governance process.
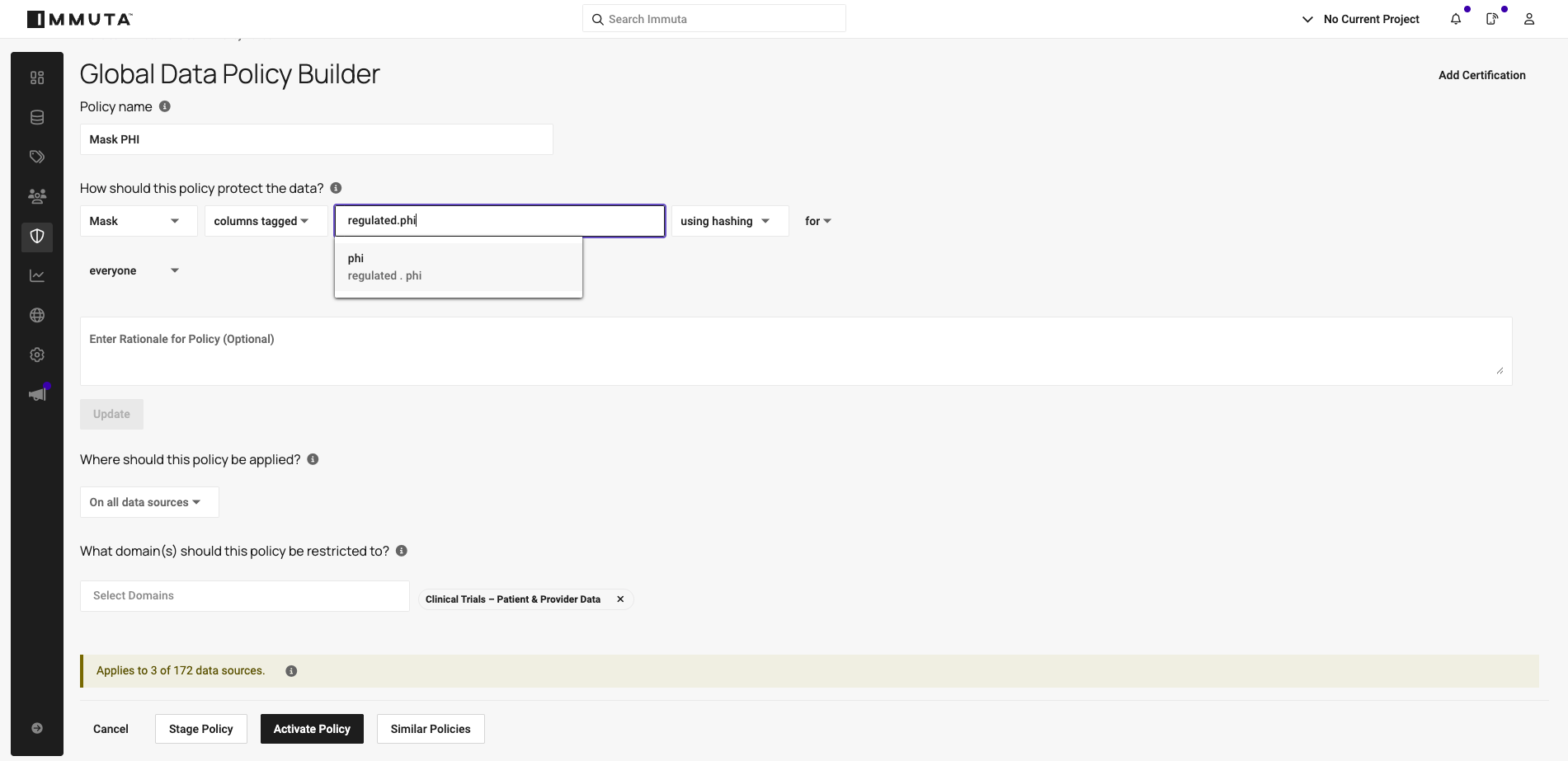
3. Automate policies based on tags
With classification in place, Immuta’s dynamic policy engine powers scalable data controls. Classifications drive data masking, filtering, and access workflows based on calculated sensitivity levels.
For example, automated sensitive data discovery workflows may tag an email address as Entity.Email and a person’s name as Patient.Identifier. Alone, these fields may not require masking. But when combined in a clinical_subjects table, classification recognizes the potential for heightened sensitivity and dynamically applies masking — unless explicit approval is granted for regulatory use cases.
In these scenarios, guardrail policies provide an essential layer of protection by enforcing global restrictions that no request or approval workflow can bypass. For example, a dataset tagged as “Crown Jewel” and “GxP-High” might require users to have a specific research project attribute. Without it, access is denied even if the dataset is part of a data product they requested and for which they received approval.
This combination of contextual classification, dynamic masking, and guardrail enforcement ensures least-privilege access at scale. It protects sensitive data from misconfigured permissions, human error, and insider threats, keeping high-risk datasets fully locked down until all governance criteria are met.
4. Enable self-service access and approval workflows with risk tiers
Immuta’s Marketplace transforms how teams access data, delivering a self-service experience where automated classification policies assure data governance and security.
Here, data products are made available for request, and risk tiers provide critical context for determining what level of scrutiny access request reviews should have. Risk tiers generally indicate whether the data’s sensitivity makes it high, medium, or low risk, but companies can tailor them to be even more specific (e.g. highly critical, confidential, etc.).
Today, Immuta’s AI-driven Review Assist feature helps approvers make informed decisions by analyzing approval history. Looking forward, enhanced AI will evaluate classification-based risk tiers alongside historical patterns, automatically approving low-risk requests and routing higher-risk ones for human review.
For example, Tier 3 datasets containing internal, non-GxP data might warrant instant approval, while Tier 1 datasets with PHI and GxP-High tags would trigger multi-step workflows involving reviews by sub-domain and domain-level stewards.
This approach scales seamlessly for large organizations managing thousands of access requests without bottlenecks. Even with AI determinations, classification-driven guardrail policies remain a critical backstop to ensure no user—regardless of approval history or automated decisions—can access select datasets without meeting strict attribute requirements.
5. Audit and prove compliance
In a highly regulated industry like pharma, it’s not enough to enforce policies. You need to prove they worked.
Immuta makes this seamless by capturing a unified audit trail across the data lifecycle. Every tag assignment — whether applied via sensitive data discovery, imported from a catalog, or added manually by a steward — is recorded. Policy changes and their impact on datasets are logged in detail, as is every access request, approval decision, and unmasking action.
For data governance teams, Immuta’s sensitivity dashboards offer an at-a-glance view of where sensitive data resides and how it’s being used. These dashboards make it easy to spot trends in PHI access, flag anomalies, and prepare for inspections.
With Immuta’s audit records, teams can quickly answer critical compliance questions:
- Who accessed PHI in Phase III datasets in the last 30 days?
- What unmasking events occurred for
subject_id columns, and who approved them?
- Which policies affecting GxP-High data were updated, and when?
This proactive visibility supports audit readiness and gives organizations confidence to demonstrate compliance with regulatory requirements.
Why this approach to data classification frameworks works
By weaving data classification throughout Immuta’s ecosystem, pharma organizations gain a governance model that is both automated and auditable. This reduces manual overhead for data stewards, empowers self-service access for researchers, and strengthens compliance postures across GxP, HIPAA, GDPR, and SOX requirements.
Explore data classification for pharma.
Learn more from our team of experts.



