
Data is the backbone of the modern enterprise. Every business decision, every AI model, every competitive advantage depends on access to the right data at the right time — a process known as data provisioning.
But as GenAI and other advancements make it easier for more people, not just technical teams, to tap into enterprise data, governance teams face a surge in access demand they weren’t built to handle. They’re caught between the need for speed and the mandate for control.
That tension is growing. As highlighted in the latest State of Data Governance in the Age of AI report, organizations say the old ways of provisioning data are beginning to buckle under modern pressures. Ticket queues, manual approvals, and platform-by-platform controls can no longer keep pace with expanding data use and AI adoption.
Over the past decade, data access and provisioning have gone through multiple transformations, each one faster than the last. What began as manual IT approvals has evolved into automated, policy-driven workflows that deliver governed access in minutes instead of weeks. Yet as AI adoption accelerates, the sheer volume of access requests is scaling beyond human capacity. Traditional processes weren’t designed to handle this new reality, where:
- More people across the business are requesting access to data.
- Machines, like AI systems and agents, are starting to request it too.
The question is no longer simply who should have access, but what AI agents should be allowed to request, analyze, and act on data in real time. Traditional governance models are being stretched to their limits, and organizations that fail to adapt risk losing visibility and control over their most critical assets.
So how did we get here — and what comes next?
Era 1: The Age of Manual Governance
It wasn’t too long ago that enterprise data access followed one prevailing dynamic: central IT controlled everything, and governance teams acted more as consultants than enforcers. In some cases, access was locked down so tightly it slowed progress. In others, it was too open, with few guardrails in place. Either way, IT held the keys, but rarely had the bandwidth to implement governance policies effectively.
Back then, data wasn’t viewed as an asset to be unlocked; it was a liability to be contained. Usage was limited to small technical teams. Governance groups wrote policy memos, and IT enforced them by writing code, creating custom data views, or generating one-off copies for each use case.
Because governance teams couldn’t directly enforce policy, IT bore the burden of translating every rule into code — an inefficient process that quickly broke down as data needs scaled. Technical expertise became the gatekeeper to access. If a business unit needed a dataset, it often meant filing a ticket, waiting weeks (sometimes months) for approval, and navigating layers of manual reviews before getting what they needed. Innovation stalled under the weight of manual provisioning and endless custom workflows.
The burden of IT dependence
While this model was meant to protect data, it relied entirely on IT to implement and maintain every governance decision, creating massive inefficiencies. As organizations grew, adding more users, data, and platforms, IT teams became overwhelmed by constant requests and duplicative policies. Data consumers were forced to wait or work around governance altogether, leading to shadow IT, duplicate datasets, and greater security risk.
Governance followed a “push” model: central IT defined broad, up-front access rules and pushed those permissions across the organization. You either had access or you didn’t. There was no dynamic way to request data, and because use was still limited, exceptions were rare.
If an employee changed roles, switched teams, or needed temporary access for a project, IT had to manually update permissions, creating more bottlenecks and increasing the chance of error. This dependency on static roles to manage every scenario led to role explosion, where new roles were created for every edge case, further bloating the system.
How governance evolved in the manual era
As organizations realized the limits of static, role-based control (RBAC), attribute-based access control (ABAC) emerged as a more flexible, contextual approach. While most platforms still relied on RBAC, the need for scalable, policy-driven governance opened the door for automation and consistency. Early natural-language policy tools and automated approvals began to appear, reducing friction and speeding up access without sacrificing security.
Still, as data complexity and regulatory pressure grew, IT reached a breaking point. Governance needed to move closer to those who understood the data best: the business units.
The lockdown era built the foundation for today’s models, but manual, centralized control couldn’t scale. The next evolution would focus on balancing security with accessibility, and on transforming static policy enforcement into something far more dynamic: data provisioning.
Era 2: Self-Service and Policy-Driven
For data teams, the pain of the manual era wasn’t just inefficiency, it was scale. Central IT could no longer keep up with the sheer volume of access requests, regulatory demands, and platform complexity. As the value and sensitivity of data increased, traditional workflows buckled under the weight of bespoke, code-heavy requests.
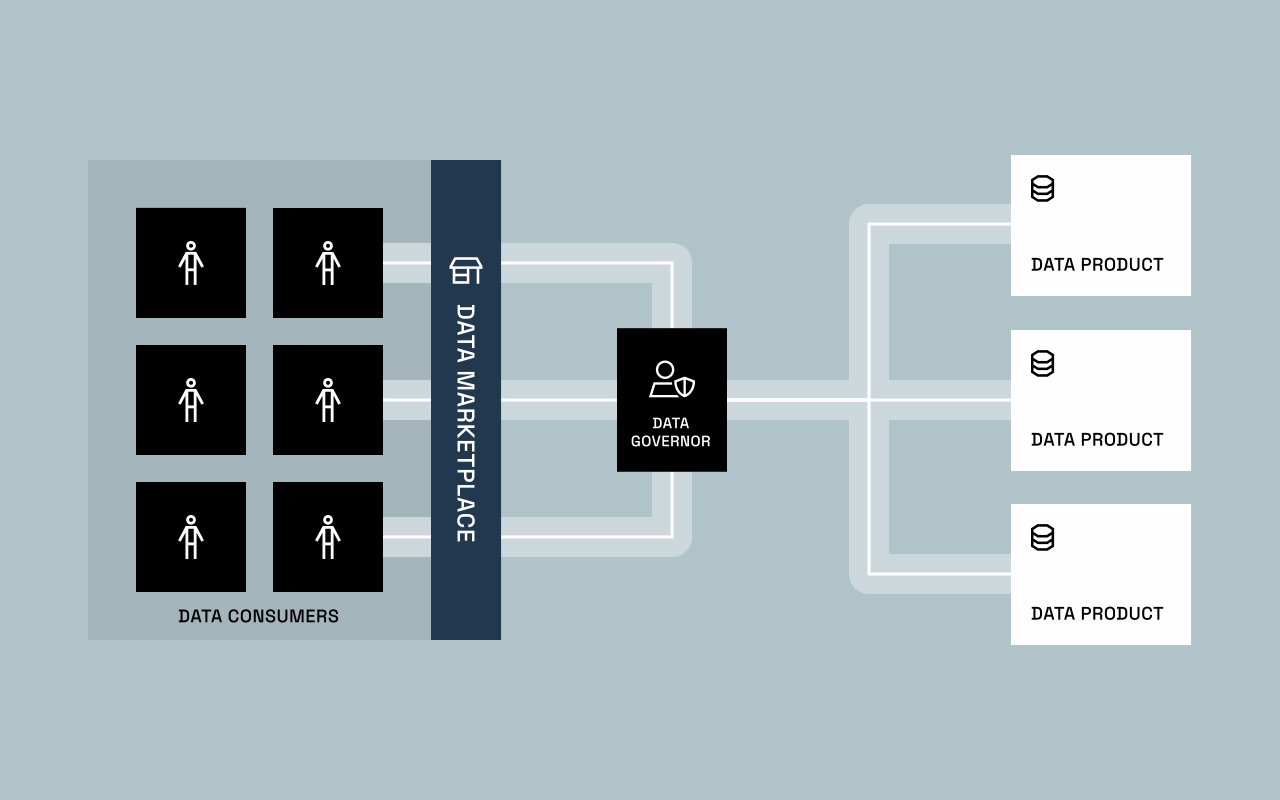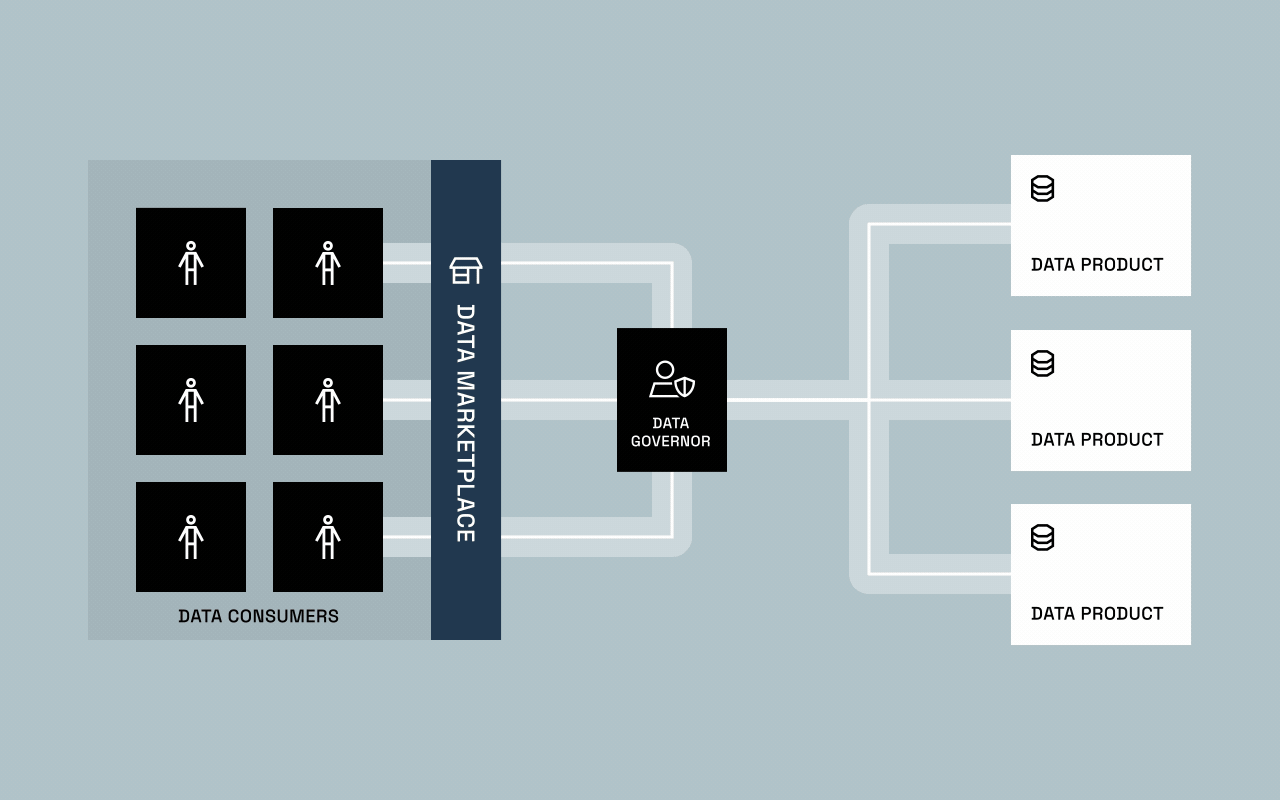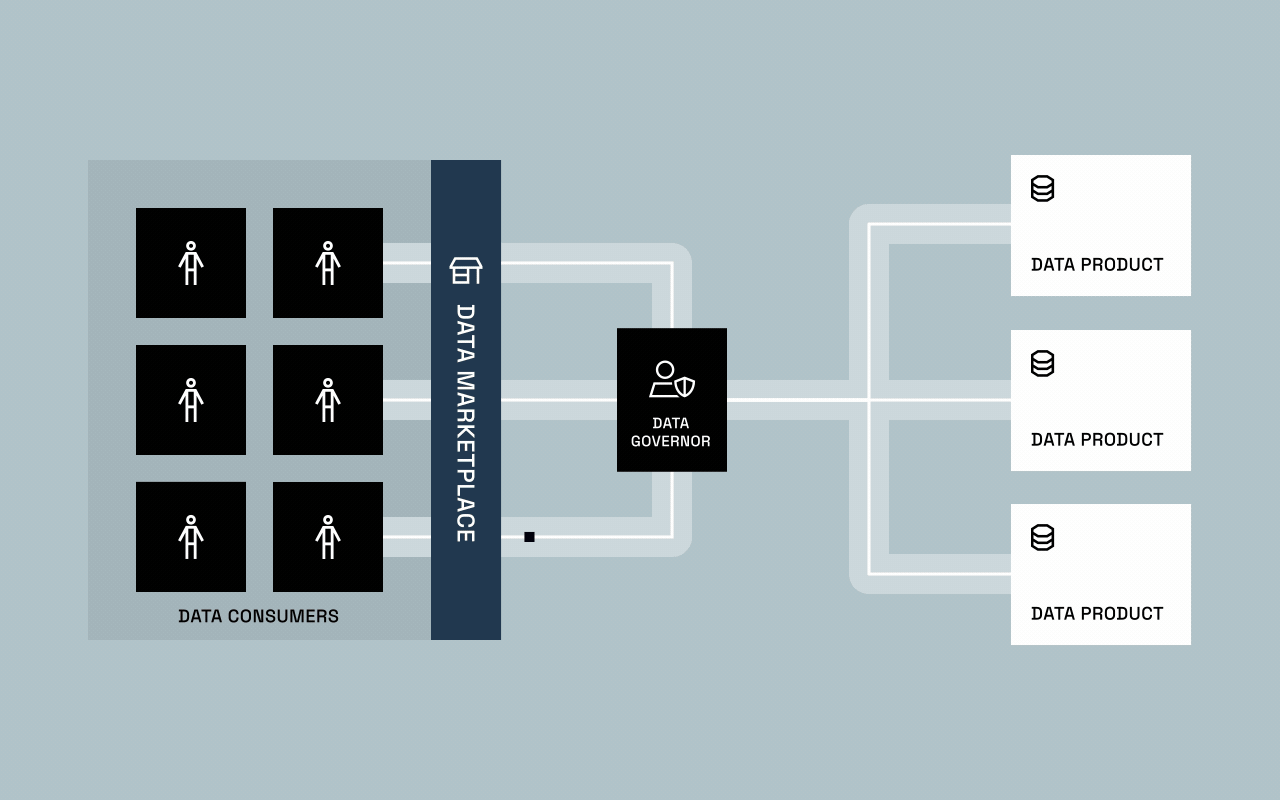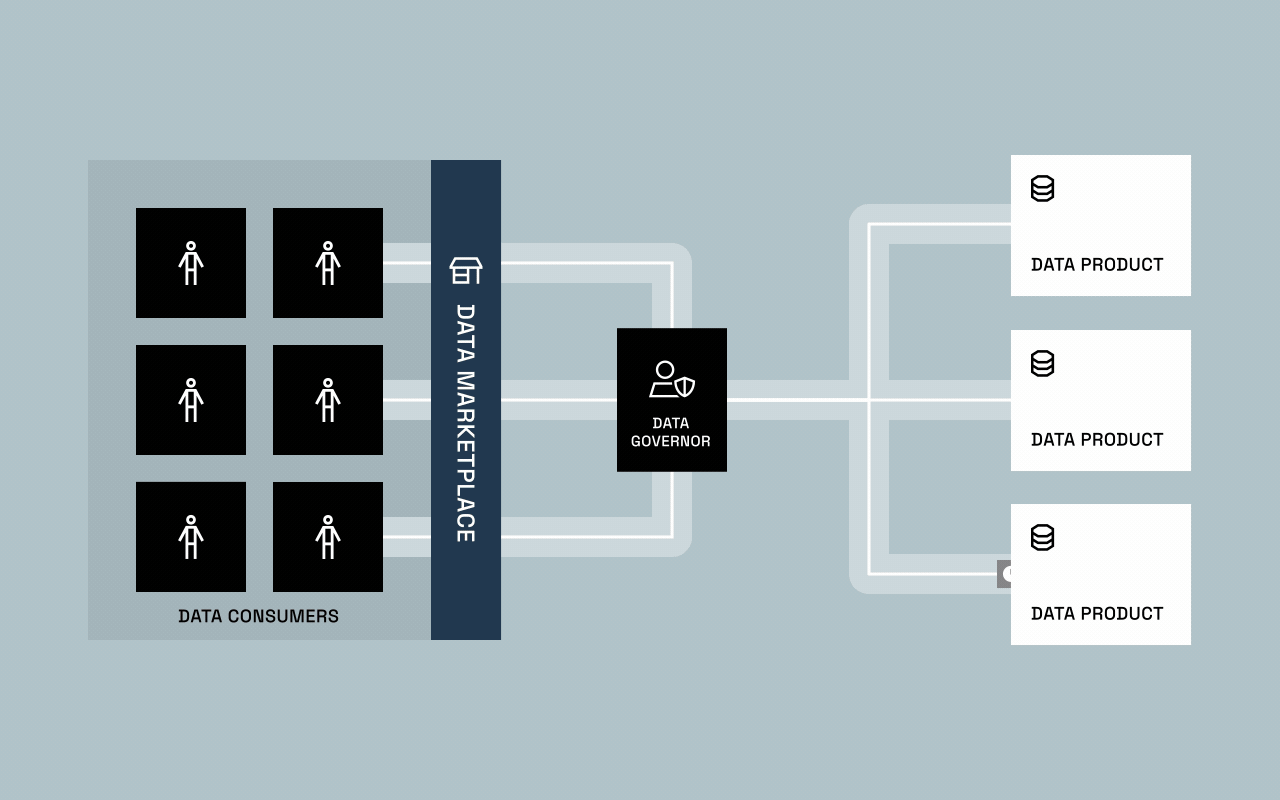
The result? A handoff. Not because governance fully matured, but because IT simply couldn’t keep up. Business units — the ones who understood the data best — took ownership and began shaping it into value-driving data products. This marked the start of decentralized data ownership and the first real glimpse of data provisioning as we know it today.
From Push to Pull: Governance Meets Provisioning
Business domains now owned their data, but they lacked the tools to manage access programmatically. So they turned to manual workarounds, which included ticket queues, spreadsheets, and basic approvals through legacy identity systems. Governance evolved from a push model, where access was predefined, to a pull model, where users had to request access one ticket, email, or form at a time.
To meet this growing demand, a new model began to take shape, one that most organizations are still only beginning to explore:
provisioning by policy and by request.
- Provision by policy automates access through centrally defined rules that grant permissions instantly when users meet the right conditions.
- Provision by request governs everything else — exceptions, edge cases, and temporary needs — through auditable, automated workflows.
Few organizations have achieved this balance yet. The shift from defining policy to operationalizing it represents a fundamental change in how data governance works. For the first time, data owners can provision governed access through software instead of tickets — dramatically reducing friction while maintaining full control.
The Rise of Policy-Driven Automation
Policy-based access control became the engine of this new model. Automated rules evaluated requests based on context, identity, and data sensitivity — freeing governance teams to focus on higher-value oversight instead of routine approvals. When policies couldn’t cover every case, AI stepped in as an assistant, making recommendations based on sensitivity levels, user roles, and prior approvals.
This blend of automation and augmentation gave rise to governed self-service: a balance between freedom and control. Data marketplaces and catalogs became the new front doors for access, where users could discover, request, and receive governed data without waiting on IT.
The Strain of Decentralization
But success brought new tension. The ratio of data governors to data consumers grew exponentially, and the number of exceptions skyrocketed. Integration challenges, inconsistent enforcement, and governance burnout became common. Many organizations relied on IGA tools built for SaaS access, not data — tools that couldn’t handle the permutations of data-level provisioning.
Policy exceptions became the new bottleneck. Without automation for recertification or exception handling, governance teams were still forced into manual reviews. The result was a hybrid world: faster than before, but not yet scalable.
The Threshold Before Machine Speed
This policy-and-provisioning era solved many problems of the manual world. Access was faster. Policies were reusable. Governance finally had a foundation that could adapt. But the model still depended on human speed — and that wouldn’t last.
As AI systems began not just consuming but requesting data, governance faced its next great test. The organizations that could automate policy enforcement, manage AI-driven requests at scale, and continuously adapt would define the next frontier of data security and innovation.
Era 3: Governance Beyond Human Control
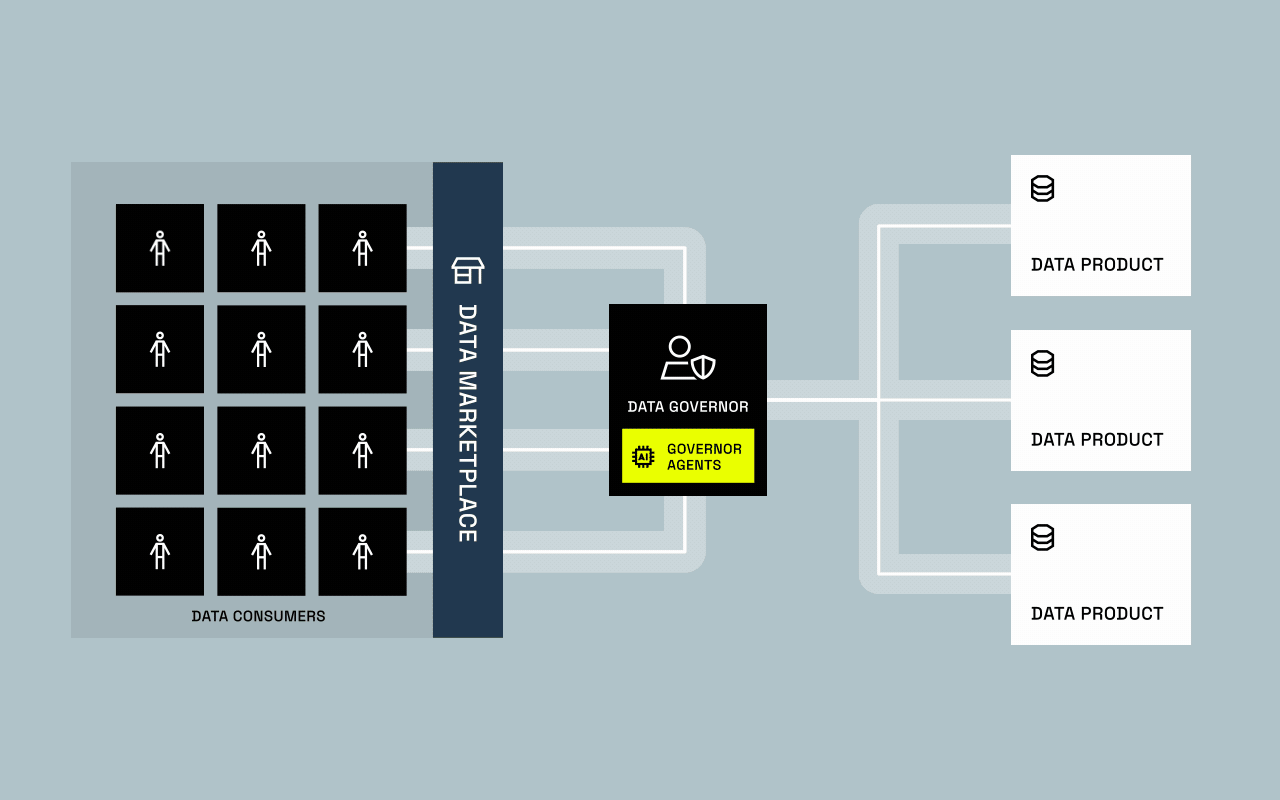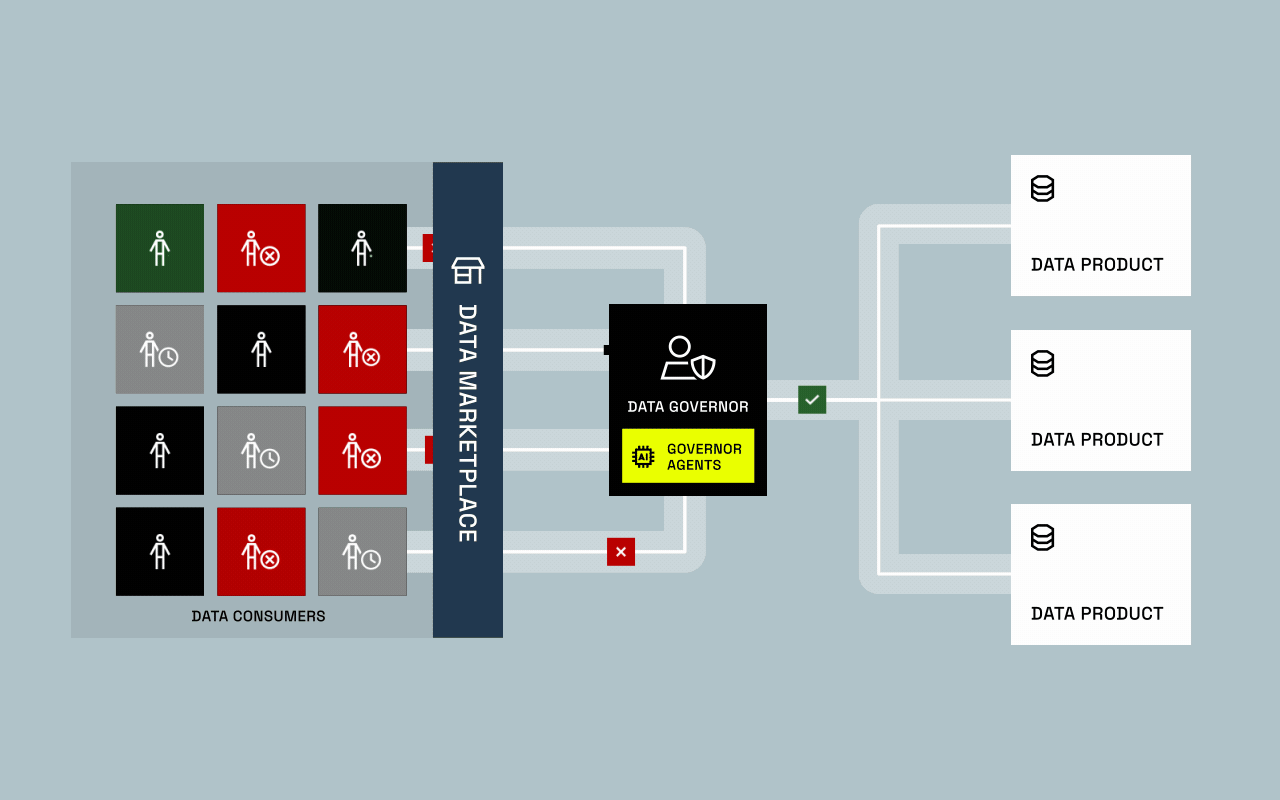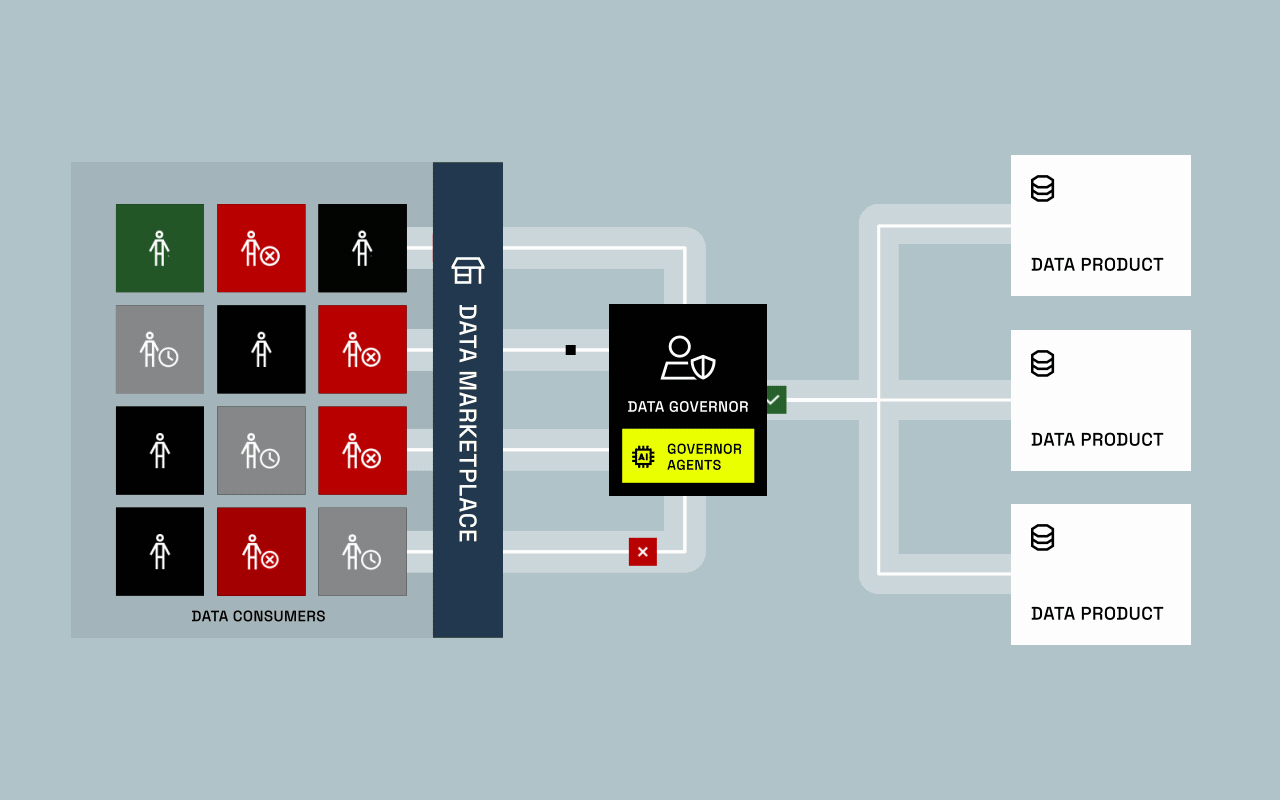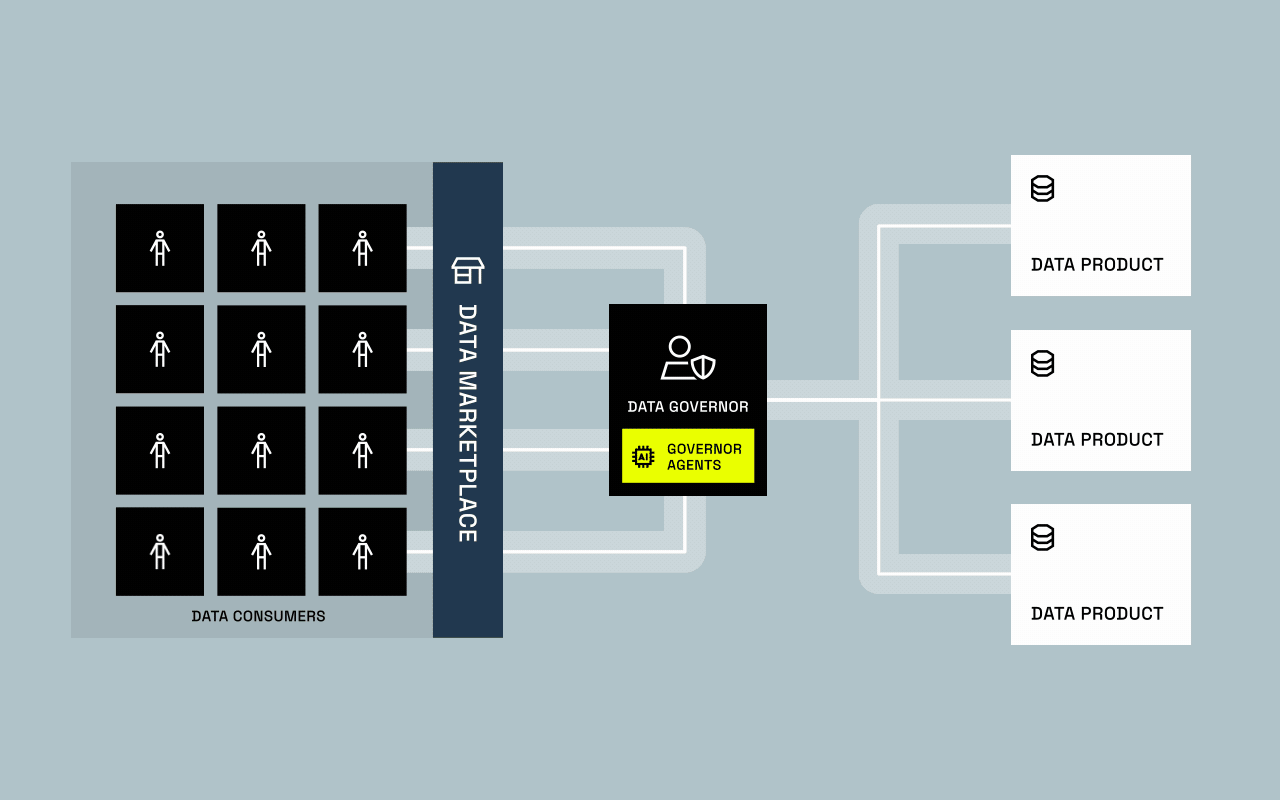
For years, data provisioning was built around one assumption: humans request access through tickets, and human-driven approvals decide whether they get it. That assumption is breaking.
AI systems are no longer just analyzing data, they’re beginning to request, process, and act on it at machine speed. This shift challenges everything governance teams have spent years optimizing. Who (or what) is accessing data? How do we control AI-driven decisions? And can today’s governance models keep up?
From Governing People to Governing Machines
Unlike humans, AI agents don’t follow ticket queues or approval meetings. They operate continuously, making traditional governance models obsolete:
- Identity is fluid. AI agents can act across teams and contexts, breaking the fixed-role logic most access models depend on.
- Speed is absolute. Agents expect responses in milliseconds, not the days or weeks manual approvals take.
- Needs are dynamic. Agents learn and adapt, requiring provisioning systems that make intelligent, automated decisions in real time.
This evolution is forcing organizations to rethink the foundation of data governance. It’s no longer only about who can access data, but how AI models use it, and how those decisions remain compliant, explainable, and auditable.
As General Motors IT executive Shelly Washington Woodruff told Immuta:
“AI is part of everybody’s journey. When you look at data from a privacy, trust, reliability, and responsibility viewpoint, those are things we have to incorporate into our governance strategy.”
Laying the Groundwork for AI-Driven Provisioning
To govern at machine speed, organizations need a new provisioning approach — one that blends policy automation, intelligent exception handling, and continuous compliance into a single, adaptive system.
- Policy Layer: Define who and what can access which data, based on sensitivity, attributes, and purpose.
- Provisioning System: Automate classification, approvals, and exception handling so both humans and AI agents can gain governed access instantly.
- Continuous Audit and Recertification: Maintain constant visibility into every access decision, automatically revoking access when no longer justified.
Together, these layers form a self-reinforcing loop: policies guide provisioning; provisioning generates auditable records; audits refine policies.
The Path Forward
Governance is entering the AI-aware era, where access controls, risk detection, and compliance adapt dynamically as agents learn and request data.
Organizations that embrace this model will:
- Automate policy enforcement at machine speed.
- Detect and mitigate AI-driven risks in real time.
- Maintain trust and compliance without slowing innovation.
We’re still on the edge of this transformation, but its trajectory is clear: governance must evolve from managing people to managing intelligence. Teams that prepare now will keep control as AI reshapes the flow of data.
The Future of Data Governance: Scaling Access Through Intelligent Provisioning
Data provisioning has undergone a complete transformation — from manual control, to ticket-based approvals, to the beginning of AI-driven automation. Each shift has forced data teams to rethink how access requests are processed, who (or what) gets approved, and how to maintain security without creating bottlenecks.
The next era isn’t about keeping up with manual processes — it’s about governing at machine speed, automating provisioning faster than AI-driven demand, and ensuring organizations maintain complete control while enabling seamless, governed access.
Organizations that embrace this new model of AI-driven governance will be those that:
- Automate policy enforcement to eliminate roadblocks and reduce risk.
- Adapt governance dynamically as AI models request, process, and act on data.
- Maintain continuous compliance at scale without human intervention.
In the end, success won’t come from adding more controls — it will come from making control automatic. Governance teams that prepare now to operationalize intelligent, policy-based provisioning will set the standard for trusted, scalable data access in the age of AI.